
Curso
Conceptos de grandes modelos lingüísticos (LLM)
2 h
99.8K
Para demostrar mejor qué es el GAR y cómo funciona la técnica, consideremos un escenario al que se enfrentan muchas empresas hoy en día.
Imagina que eres directivo de una empresa de electrónica que vende dispositivos como teléfonos inteligentes y ordenadores portátiles. Quieres crear un chatbot de atención al cliente para tu empresa que responda a las consultas de los usuarios relacionadas con las especificaciones de los productos, la resolución de problemas, la información sobre la garantía, etc.
Te gustaría utilizar las capacidades de LLMs como GPT-3 o GPT-4 para potenciar tu chatbot.
Sin embargo, los grandes modelos lingüísticos tienen las siguientes limitaciones, que conducen a una experiencia de cliente ineficaz:
Los modelos lingüísticos se limitan a dar respuestas genéricas basadas en sus datos de entrenamiento. Si los usuarios hicieran preguntas específicas sobre el software que vendes, o si tuvieran dudas sobre cómo solucionar problemas en profundidad, es posible que un LLM tradicional no pudiera dar respuestas precisas.
Esto se debe a que no han recibido formación sobre los datos específicos de tu organización. Además, los datos de entrenamiento de estos modelos tienen una fecha de corte, lo que limita su capacidad de proporcionar respuestas actualizadas.
Los LLM pueden "alucinar", lo que significa que tienden a generar con confianza respuestas falsas basadas en hechos imaginarios. Estos algoritmos también pueden dar respuestas fuera de tema si no tienen una respuesta precisa a la consulta del usuario, lo que conduce a una mala experiencia del cliente.
Los modelos lingüísticos suelen dar respuestas genéricas que no se adaptan a contextos específicos. Esto puede ser un gran inconveniente en un escenario de atención al cliente, ya que las preferencias individuales de los usuarios suelen ser necesarias para facilitar una experiencia personalizada al cliente.
RAG salva eficazmente estas lagunas proporcionándote una forma de integrar la base de conocimientos generales de los LLM con la capacidad de acceder a información específica, como los datos presentes en tu base de datos de productos y manuales de usuario. Esta metodología permite obtener respuestas muy precisas y fiables, adaptadas a las necesidades de tu organización.
Ahora que ya sabes qué es el GAR, veamos los pasos que hay que dar para establecer este marco:
Primero debes reunir todos los datos necesarios para tu solicitud. En el caso de un chatbot de atención al cliente para una empresa de electrónica, esto puede incluir manuales de usuario, una base de datos de productos y una lista de preguntas frecuentes.
La fragmentación de datos es el proceso de dividir tus datos en trozos más pequeños y manejables. Por ejemplo, si tienes un extenso manual de usuario de 100 páginas, podrías dividirlo en diferentes secciones, cada una de las cuales podría responder a diferentes preguntas de los clientes.
De este modo, cada trozo de datos se centra en un tema concreto. Cuando se recupera una información del conjunto de datos fuente, es más probable que sea directamente aplicable a la consulta del usuario, ya que evitamos incluir información irrelevante de documentos enteros.
Esto también mejora la eficacia, ya que el sistema puede obtener rápidamente las piezas de información más relevantes en lugar de procesar documentos enteros.
Ahora que los datos de origen se han descompuesto en partes más pequeñas, hay que convertirlos en una representación vectorial. Esto implica transformar los datos de texto en incrustaciones, que son representaciones numéricas que captan el significado semántico que hay detrás del texto.
En palabras sencillas, la incrustación de documentos permite al sistema entender las consultas de los usuarios y emparejarlas con la información relevante del conjunto de datos de origen basándose en el significado del texto, en lugar de una simple comparación palabra a palabra. Este método garantiza que las respuestas sean pertinentes y se ajusten a la consulta del usuario.
Si quieres saber más sobre cómo se convierten los datos de texto en representaciones vectoriales, te recomendamos que explores nuestro tutorial sobre incrustaciones de texto con la API OpenAI.
Cuando una consulta de usuario entra en el sistema, también debe convertirse en una representación incrustada o vectorial. Debe utilizarse el mismo modelo para la incrustación del documento y de la consulta, a fin de garantizar la uniformidad entre ambos.
Una vez convertida la consulta en una incrustación, el sistema compara la incrustación de la consulta con las incrustaciones del documento. Identifica y recupera los trozos cuyas incrustaciones son más similares a la incrustación de la consulta, utilizando medidas como la similitud del coseno y la distancia euclidiana.
Estos trozos se consideran los más relevantes para la consulta del usuario.
Los trozos de texto recuperados, junto con la consulta inicial del usuario, se introducen en un modelo lingüístico. El algoritmo utilizará esta información para generar una respuesta coherente a las preguntas del usuario a través de una interfaz de chat.
Aquí tienes un diagrama de flujo simplificado que resume cómo funciona el GAR:
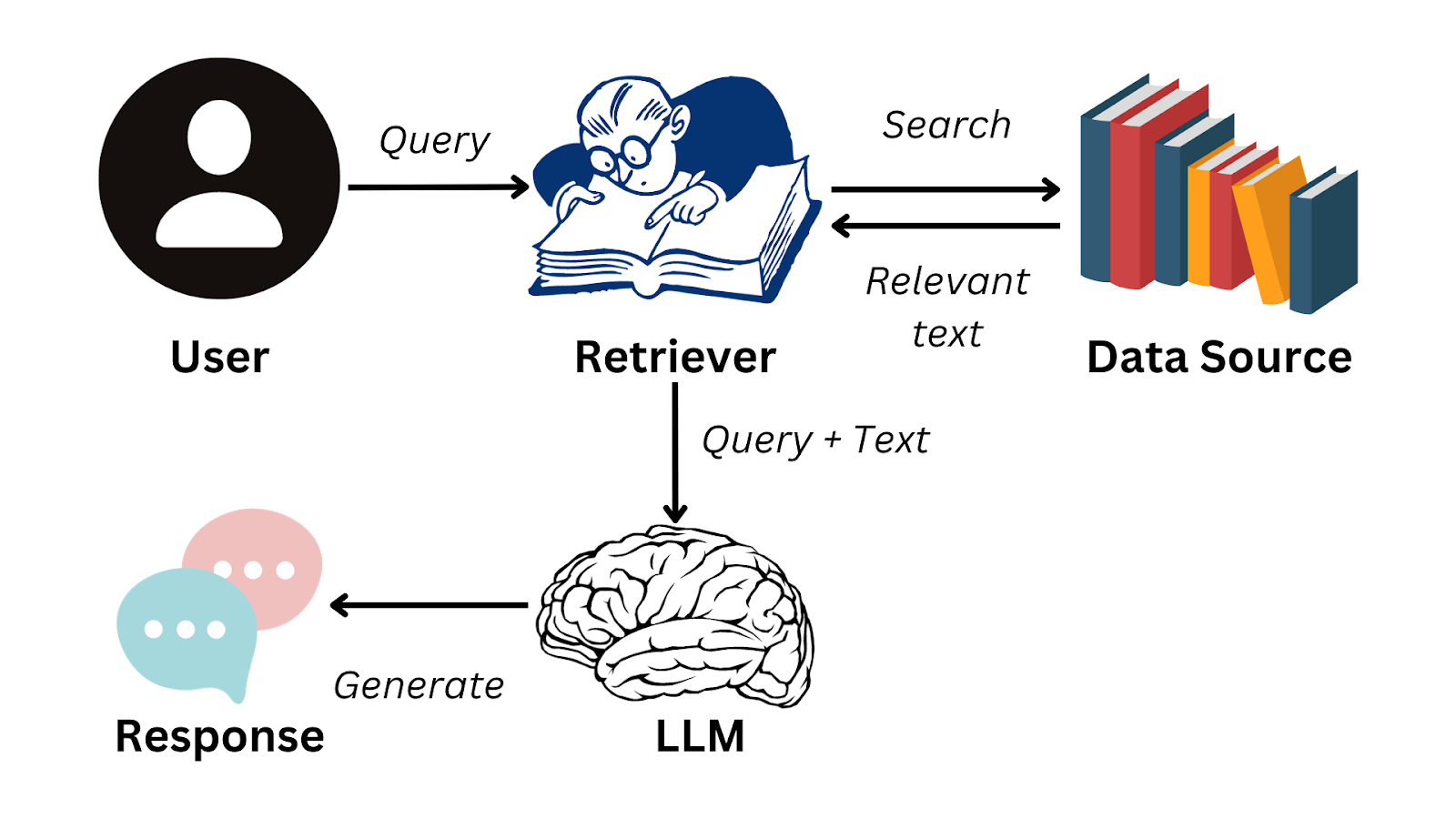
Imagen del autor
Para realizar sin problemas los pasos necesarios para generar respuestas con LLMs, puedes utilizar un marco de datos como LlamaIndex.
Esta solución te permite desarrollar tus propias aplicaciones LLM gestionando eficazmente el flujo de información desde fuentes de datos externas a modelos lingüísticos como el GPT-3. Para saber más sobre este marco y cómo puedes utilizarlo para crear aplicaciones basadas en LLM, lee nuestro tutorial sobre LlamaIndex.
Ahora sabemos que el GAR permite a los LLM formar respuestas coherentes basándose en información ajena a sus datos de entrenamiento. Un sistema como éste tiene una variedad de casos de uso empresarial que mejorarán la eficacia organizativa y la experiencia del usuario. Aparte del ejemplo del chatbot de cliente que vimos antes en el artículo, he aquí algunas aplicaciones prácticas de la GAR:
El GAR puede utilizar contenidos de fuentes externas para elaborar resúmenes precisos, lo que supone un ahorro de tiempo considerable. Por ejemplo, los directivos y ejecutivos de alto nivel son personas ocupadas que no tienen tiempo de examinar informes exhaustivos.
Con una aplicación potenciada por RAG, pueden acceder rápidamente a los hallazgos más críticos de los datos textuales y tomar decisiones de forma más eficiente, en lugar de tener que leer largos documentos.
Los sistemas RAG pueden utilizarse para analizar los datos de los clientes, como compras anteriores y opiniones, para generar recomendaciones de productos. Esto aumentará la experiencia general del usuario y, en última instancia, generará más ingresos para la organización.
Por ejemplo, las aplicaciones RAG pueden utilizarse para recomendar mejores películas en plataformas de streaming basándose en el historial de visionado y las valoraciones del usuario. También pueden utilizarse para analizar reseñas escritas en plataformas de comercio electrónico.
Dado que los LLM destacan en la comprensión de la semántica que subyace a los datos textuales, los sistemas RAG pueden proporcionar a los usuarios sugerencias personalizadas más matizadas que las de un sistema de recomendación tradicional.
Las organizaciones suelen tomar decisiones empresariales vigilando el comportamiento de la competencia y analizando las tendencias del mercado. Esto se hace analizando meticulosamente los datos presentes en informes empresariales, estados financieros y documentos de investigación de mercado.
Con una aplicación RAG, las organizaciones ya no tienen que analizar manualmente e identificar tendencias en estos documentos. En cambio, se puede emplear un LLM para obtener de forma eficaz una visión significativa y mejorar el proceso de investigación de mercado.
Aunque las aplicaciones RAG nos permiten tender un puente entre la recuperación de información y el procesamiento del lenguaje natural, su aplicación plantea algunos retos únicos. En esta sección, examinaremos las complejidades a las que se enfrenta la creación de aplicaciones GAR y debatiremos cómo se pueden mitigar.
Puede ser difícil integrar un sistema de recuperación con un LLM. Esta complejidad aumenta cuando hay múltiples fuentes de datos externas en distintos formatos. Los datos que se introducen en un sistema GAR deben ser coherentes, y las incrustaciones generadas deben ser uniformes en todas las fuentes de datos.
Para superar este reto, se pueden diseñar módulos separados para manejar distintas fuentes de datos de forma independiente. Los datos de cada módulo se pueden preprocesar para que sean uniformes, y se puede utilizar un modelo normalizado para garantizar que las incrustaciones tengan un formato coherente.
A medida que aumenta la cantidad de datos, resulta más difícil mantener la eficacia del sistema GAR. Hay que realizar muchas operaciones complejas, como generar incrustaciones, comparar el significado entre distintos fragmentos de texto y recuperar datos en tiempo real.
Estas tareas son computacionalmente intensivas y pueden ralentizar el sistema a medida que aumenta el tamaño de los datos de origen.
Para afrontar este reto, puedes distribuir la carga computacional entre distintos servidores e invertir en una infraestructura de hardware robusta. Para mejorar el tiempo de respuesta, también puede ser beneficioso almacenar en caché las consultas que se hacen con frecuencia.
La implementación de bases de datos vectoriales también puede mitigar el reto de la escalabilidad en los sistemas GAR. Estas bases de datos te permiten manejar incrustaciones con facilidad, y pueden recuperar rápidamente los vectores más alineados con cada consulta.
Si quieres saber más sobre la implementación de bases de datos vectoriales en una aplicación RAG, puedes ver nuestra sesión de código en directo, titulada Generación Aumentada de Recuperación con GPT y Milvus. Este tutorial ofrece una guía paso a paso para combinar Milvus, una base de datos vectorial de código abierto, con modelos GPT.
La eficacia de un sistema GAR depende en gran medida de la calidad de los datos que se introducen en él. Si el contenido fuente al que accede la aplicación es deficiente, las respuestas generadas serán imprecisas.
Las organizaciones deben invertir en un proceso diligente de curación y ajuste de contenidos. Es necesario perfeccionar las fuentes de datos para mejorar su calidad. Para las aplicaciones comerciales, puede ser beneficioso implicar a un experto en la materia para que revise y rellene las lagunas de información antes de utilizar el conjunto de datos en un sistema GAR.
La RAG es actualmente la técnica más conocida para aprovechar las capacidades lingüísticas de los LLM junto con una base de datos especializada. Estos sistemas abordan algunos de los retos más acuciantes que se plantean al trabajar con modelos lingüísticos, y presentan una solución innovadora en el campo del procesamiento del lenguaje natural.
Sin embargo, como cualquier otra tecnología, las aplicaciones GAR tienen sus limitaciones, sobre todo su dependencia de la calidad de los datos de entrada. Para sacar el máximo partido de los sistemas GAR, es crucial incluir la supervisión humana en el proceso.
La curación meticulosa de las fuentes de datos, junto con el conocimiento experto, es imprescindible para garantizar la fiabilidad de estas soluciones.
Si quieres profundizar en el mundo de la RAG y comprender cómo se puede utilizar para crear aplicaciones de IA eficaces, puedes ver nuestra formación en directo sobre la creación de aplicaciones de IA con LangChain. Este tutorial te proporcionará experiencia práctica con LangChain, una biblioteca diseñada para permitir la implementación de sistemas RAG en escenarios del mundo real.
Empieza hoy mismo con los LLM
Curso
Curso
Curso
blog
Abid Ali Awan
11 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
9 min
blog
Matt Crabtree
13 min
Tutorial
Ryan Ong
Tutorial
Ryan Ong

