
programa
Desarrollo de aplicaciones de IA
21 h
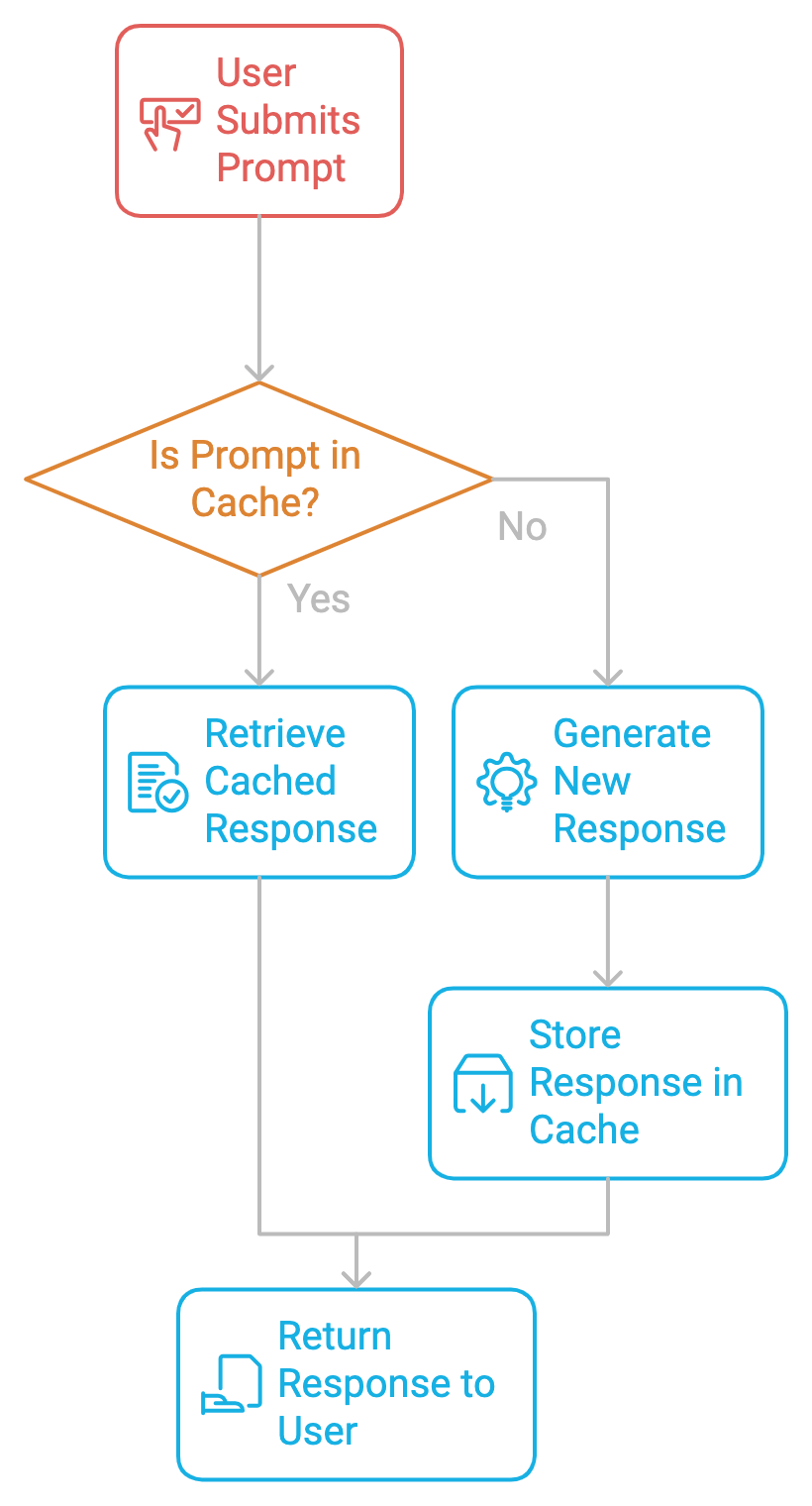
En esencia, la caché de peticiones funciona almacenando las peticiones y sus correspondientes respuestas en una caché. Cuando se vuelve a enviar la misma consulta o una similar, el sistema recupera la respuesta almacenada en caché en lugar de generar una nueva. Esto evita el cálculo repetitivo, acelera los tiempos de respuesta y reduce los costes.
El almacenamiento en caché tiene varias ventajas:
Antes de profundizar en la aplicación de la caché rápida, debemos tener en cuenta algunas consideraciones.
Para garantizar la frescura de los datos, cada respuesta almacenada en caché debe tener un Tiempo de Vida (TTL) en la memoria. El TTL determina cuánto tiempo se considerará válida una respuesta almacenada en caché. Una vez que expira el TTL, la entrada de la caché se elimina o se actualiza, y el indicador correspondiente se vuelve a calcular la próxima vez que se solicite.
Este mecanismo garantiza que la caché no almacene información obsoleta. En el caso de contenidos estáticos o que se actualizan con menos frecuencia, como documentos legales o manuales de productos, un TTL más largo puede ayudar a reducir el recálculo sin arriesgarse al anquilosamiento de los datos. Por tanto, ajustar adecuadamente los valores TTL es esencial para mantener un equilibrio entre la frescura de los datos y la eficiencia computacional.
A veces, dos peticiones son similares pero no idénticas. Determinar lo cerca que está una nueva petición de otra ya almacenada en caché es crucial para que el almacenamiento en caché sea eficaz. Implementar la similitud de las indicaciones requiere técnicas como la concordancia difusa o la búsqueda semántica, en las que el sistema utiliza incrustaciones vectoriales para representar las indicaciones y comparar su similitud.
Al almacenar en caché las respuestas a peticiones similares, los sistemas pueden reducir el recálculo, manteniendo al mismo tiempo una alta precisión en las respuestas. Sin embargo, fijar el umbral de similitud de forma demasiado laxa puede dar lugar a desajustes, mientras que fijarlo de forma demasiado estricta puede hacer que se pierdan oportunidades de almacenamiento en caché.
Estrategias como la de Uso Menos Reciente (LRU) ayudan a gestionar el tamaño de la caché. El método LRU elimina los datos menos accedidos cuando la caché alcanza su capacidad. Esta estrategia funciona bien en situaciones en las que determinadas consultas son más populares y deben permanecer en la caché, mientras que las consultas menos comunes pueden eliminarse para dejar espacio a las solicitudes más recientes.
Implementar la caché rápida es un proceso de dos pasos.
El primer paso para implantar la caché de avisos es identificar los avisos repetitivos frecuentes en el sistema. Tanto si construimos un chatbot, un asistente de codificación o un procesador de documentos, necesitamos controlar qué indicaciones se repiten. Una vez identificados, pueden almacenarse en caché para evitar cálculos redundantes.
Una vez identificada una solicitud, su respuesta se almacena en la caché junto con metadatos como el tiempo de vida (TTL), el índice de aciertos y errores de la caché, etc. Cada vez que un usuario vuelve a enviar la misma consulta, el sistema recupera la respuesta almacenada en caché, saltándose el costoso proceso de generación.
Con todos los conocimientos teóricos, vamos a sumergirnos en un ejemplo práctico utilizando Ollama para explorar el impacto del almacenamiento en caché frente al no almacenamiento en caché en un entorno local. Aquí, utilizamos datos de un libro de aprendizaje profundo alojado en la web y modelos locales para resumir las primeras páginas del libro. Experimentaremos con varios LLM, incluidos Gemma2, Llama2 y Llama3para comparar su rendimiento.
Para este ejemplo práctico, utilizaremos BeautifulSoupun paquete de Python que analiza documentos HTML y XML, incluidos los que contienen marcas malformadas. Para instalar BeautifulSoup, ejecuta lo siguiente:
!pip install BeautifulSoupOtra herramienta que utilizaremos es Ollama. Simplifica la instalación y gestión de grandes modelos lingüísticos en sistemas locales.
Para empezar, descarga Ollama e instala Ollama en tu escritorio. Podemos variar el nombre del modelo según nuestras necesidades. Consulta el modelo biblioteca en el sitio web oficial de Ollama para buscar los distintos modelos compatibles con Ollama. Ejecuta el siguiente código en el terminal:
ollama run llama3.1 Ya estamos listos. ¡Empecemos!
Comenzamos con las siguientes importaciones:
time para seguir el tiempo de inferencia del código de caché y sin cachérequests para hacer peticiones HTTP y obtener datos de páginas webBeautifulSoup para analizar y limpiar el contenido HTMLOllama para utilizar localmente los LLMimport time
import requests
from bs4 import BeautifulSoup
import ollamaEn el código siguiente, definimos una función fetch_article_content que recupera y limpia el contenido del texto de una URL dada. Intenta obtener el contenido de la página web utilizando la biblioteca requests, con hasta tres reintentos en caso de fallos como errores de red o problemas con el servidor.
La función utiliza BeautifulSoup para analizar el contenido HTML y elimina las etiquetas
Aprende IA con estos cursos
programa
Curso
Curso