
Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
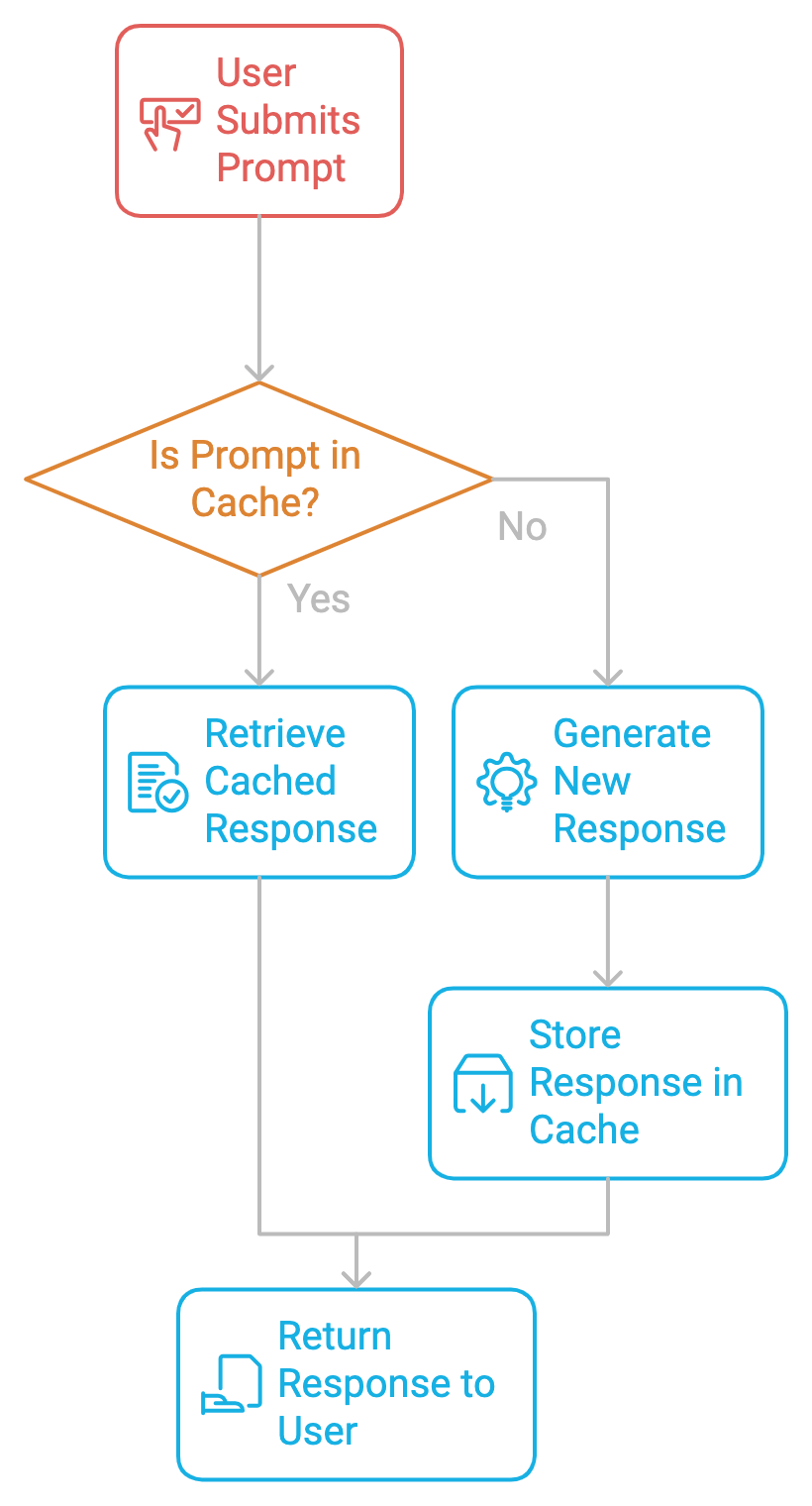
Im Kern funktioniert das Prompt-Caching so, dass Prompts und die dazugehörigen Antworten in einem Cache gespeichert werden. Wenn dieselbe oder eine ähnliche Anfrage erneut gestellt wird, ruft das System die zwischengespeicherte Antwort ab, anstatt eine neue zu generieren. Dadurch werden wiederholte Berechnungen vermieden, die Reaktionszeiten verkürzt und die Kosten gesenkt.
Promptes Caching hat mehrere Vorteile:
Bevor wir tiefer in die Implementierung von Prompt Caching eintauchen, müssen wir ein paar Dinge beachten.
Um die Aktualität der Daten zu gewährleisten, sollte jede gecachte Antwort eine Time-to-Live (TTL) im Speicher haben. Die TTL bestimmt, wie lange eine gecachte Antwort als gültig angesehen wird. Wenn die TTL abläuft, wird der Cache-Eintrag entweder entfernt oder aktualisiert und die entsprechende Eingabeaufforderung wird bei der nächsten Abfrage neu berechnet.
Dieser Mechanismus stellt sicher, dass der Cache keine veralteten Informationen speichert. Bei statischen oder seltener aktualisierten Inhalten, wie z. B. juristischen Dokumenten oder Produkthandbüchern, kann eine längere TTL dazu beitragen, die Neuberechnung zu reduzieren, ohne zu riskieren, dass die Daten veralten. Die richtige Einstellung der TTL-Werte ist daher wichtig, um ein Gleichgewicht zwischen der Aktualität der Daten und der Effizienz der Berechnungen zu wahren.
Manchmal sind zwei Aufforderungen zwar ähnlich, aber nicht identisch. Die Feststellung, wie nah ein neuer Prompt an einem bereits gecachten Prompt liegt, ist entscheidend für ein effektives Caching. Die Umsetzung der Ähnlichkeit von Prompts erfordert Techniken wie Fuzzy Matching oder semantische Suche, bei denen das System Vektoreinbettungen verwendet, um Prompts darzustellen und ihre Ähnlichkeit zu vergleichen.
Durch das Zwischenspeichern von Antworten für ähnliche Aufforderungen können Systeme die Neuberechnung reduzieren und gleichzeitig eine hohe Antwortgenauigkeit beibehalten. Wenn du den Ähnlichkeitsschwellenwert zu locker festlegst, kann das zu Fehlanpassungen führen, während du bei einer zu strengen Festlegung möglicherweise Möglichkeiten zum Caching verpasst.
Strategien wie LRU (Least Recently Used) helfen bei der Verwaltung der Cache-Größe. Die LRU-Methode entfernt die Daten, auf die am wenigsten zugegriffen wurde, wenn der Cache seine Kapazität erreicht. Diese Strategie funktioniert gut in Szenarien, in denen bestimmte Abfragen beliebter sind und im Cache bleiben müssen, während weniger häufige Abfragen entfernt werden können, um Platz für neuere Anfragen zu schaffen.
Die Implementierung von Prompt Caching ist ein zweistufiger Prozess.
Der erste Schritt bei der Implementierung des Prompt-Cachings besteht darin, häufige, sich wiederholende Prompts im System zu identifizieren. Egal, ob wir einen Chatbot, einen Programmierassistenten oder einen Dokumentenverarbeiter bauen, wir müssen überwachen, welche Aufforderungen wiederholt werden. Sobald diese identifiziert sind, können sie zwischengespeichert werden, um redundante Berechnungen zu vermeiden.
Sobald ein Prompt identifiziert ist, wird seine Antwort im Cache gespeichert, zusammen mit Metadaten wie Time-to-Live (TTL), Cache Hit/Miss-Raten und mehr. Wenn ein Nutzer dieselbe Eingabeaufforderung erneut abschickt, ruft das System die Antwort aus dem Zwischenspeicher ab und überspringt so den teuren Generierungsprozess.
Nach all dem theoretischen Wissen wollen wir nun ein praktisches Beispiel mit Ollama ausprobieren, um die Auswirkungen von Caching und ohne Caching in einer lokalen Umgebung zu untersuchen. Hier verwenden wir Daten aus einem im Internet gehosteten Deep-Learning-Buch und lokale Modelle, um die ersten Seiten des Buches zusammenzufassen. Wir werden mit mehreren LLMs experimentieren, darunter Gemma2, Llama2 und Llama3um ihre Leistung zu vergleichen.
Für dieses praktische Beispiel werden wir die BeautifulSoupverwenden, ein Python-Paket, das HTML- und XML-Dokumente parst, auch solche mit fehlerhaftem Markup. Um BeautifulSoup zu installieren, führe Folgendes aus:
!pip install BeautifulSoupEin weiteres Tool, das wir verwenden werden, ist Ollama. Es vereinfacht die Installation und Verwaltung von großen Sprachmodellen auf lokalen Systemen.
Um loszulegen, lade Ollama herunter und installiere Ollama auf deinem Desktop. Wir können den Modellnamen je nach Bedarf variieren. Schau dir die Modell Bibliothek auf der offiziellen Website von Ollama, um nach verschiedenen von Ollama unterstützten Modellen zu suchen. Führe den folgenden Code im Terminal aus:
ollama run llama3.1 Wir sind alle bereit. Fangen wir an!
Wir beginnen mit den folgenden Importen:
time um die Inferenzzeit für Caching und keinen Caching-Code zu verfolgenrequests um HTTP-Anfragen zu stellen und Daten von Webseiten abzurufenBeautifulSoup zum Parsen und Bereinigen von HTML-InhaltenOllama für den Einsatz von LLMs vor Ortimport time
import requests
from bs4 import BeautifulSoup
import ollamaIm folgenden Code definieren wir eine Funktion fetch_article_content, die den Textinhalt von einer bestimmten URL abruft und bereinigt. Er versucht, den Inhalt der Webseite mit Hilfe der requests Bibliothek zu holen, mit bis zu drei Wiederholungsversuchen im Falle von Fehlern wie Netzwerk- oder Serverproblemen.
Die Funktion verwendet BeautifulSoup, um den HTML-Inhalt zu parsen und entfernt unnötige
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
