
Cursus
Développer des applications d'IA
21 h
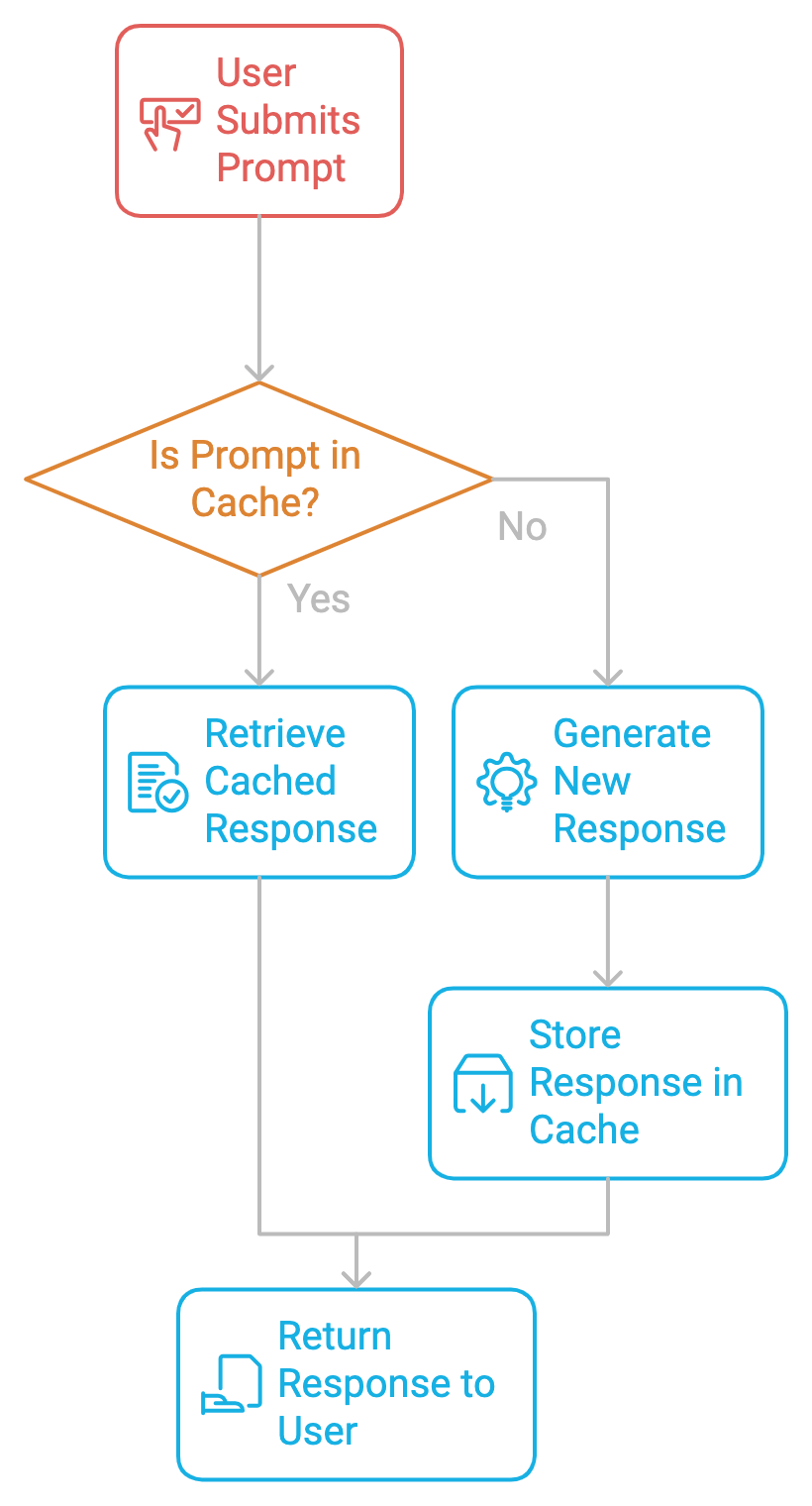
Le principe de la mise en cache des invites consiste à stocker les invites et les réponses correspondantes dans un cache. Lorsque la même demande ou une demande similaire est à nouveau soumise, le système récupère la réponse mise en cache plutôt que d'en générer une nouvelle. Cela permet d'éviter les calculs répétitifs, d'accélérer les temps de réponse et de réduire les coûts.
La mise en cache rapide présente plusieurs avantages :
Avant de nous plonger plus avant dans la mise en œuvre de la mise en cache rapide, nous devons garder à l'esprit quelques considérations.
Pour garantir la fraîcheur des données, chaque réponse mise en cache doit avoir une durée de vie (TTL) dans la mémoire. Le TTL détermine la durée pendant laquelle une réponse mise en cache sera considérée comme valide. Une fois que le TTL a expiré, l'entrée du cache est soit supprimée, soit mise à jour, et l'invite correspondante est recalculée lors de la prochaine demande.
Ce mécanisme garantit que le cache ne stocke pas d'informations obsolètes. Dans le cas d'un contenu statique ou moins fréquemment mis à jour, tel que des documents juridiques ou des manuels de produits, un TTL plus long peut contribuer à réduire les recalculs sans risquer de rendre les données obsolètes. Il est donc essentiel de régler correctement les valeurs TTL pour maintenir un équilibre entre la fraîcheur des données et l'efficacité des calculs.
Il arrive que deux messages soient similaires mais pas identiques. Pour que la mise en cache soit efficace, il est essentiel de déterminer à quel point une nouvelle invite est proche d'une invite déjà mise en cache. La mise en œuvre de la similarité des invites nécessite des techniques telles que la correspondance floue ou la recherche sémantique, où le système utilise des vecteurs intégrés pour représenter les invites et comparer leur similarité.
En mettant en cache les réponses à des questions similaires, les systèmes peuvent réduire le nombre de calculs tout en conservant une grande précision de réponse. Cependant, un seuil de similarité trop lâche peut entraîner des disparités, tandis qu'un seuil trop strict peut faire rater des opportunités de mise en cache.
Des stratégies telles que la méthode LRU (Least Recently Used) permettent de gérer la taille de la mémoire cache. La méthode LRU supprime les données les moins consultées lorsque le cache atteint sa capacité. Cette stratégie fonctionne bien dans les scénarios où certaines invites sont plus populaires et doivent rester en cache, tandis que les requêtes moins courantes peuvent être supprimées pour faire de la place aux requêtes plus récentes.
La mise en place d'une mise en cache rapide se fait en deux étapes.
La première étape de la mise en cache des invites consiste à identifier les invites répétitives fréquentes dans le système. Qu'il s'agisse d'un chatbot, d'un assistant de codage ou d'un processeur de documents, nous devons surveiller les invites qui sont répétées. Une fois identifiés, ils peuvent être mis en cache pour éviter les calculs redondants.
Une fois l'invite identifiée, sa réponse est stockée dans le cache avec des métadonnées telles que le temps de vie (TTL), les taux de réussite et d'échec du cache, etc. Chaque fois qu'un utilisateur soumet à nouveau la même demande, le système récupère la réponse mise en cache, ce qui permet d'éviter le processus de génération coûteux.
Avec toutes ces connaissances théoriques, plongeons dans un exemple pratique utilisant Ollama pour explorer l'impact de la mise en cache par rapport à l'absence de mise en cache dans un environnement local. Ici, nous utilisons les données d'un livre de deep learning hébergé sur le web et des modèles locaux pour résumer les premières pages du livre. Nous expérimenterons plusieurs LLM, dont Gemma2, Llama2 et Llama3afin de comparer leurs performances.
Pour cet exemple pratique, nous utiliserons BeautifulSoupun paquetage Python qui analyse les documents HTML et XML, y compris ceux dont le balisage est malformé. Pour installer BeautifulSoup, exécutez ce qui suit :
!pip install BeautifulSoupUn autre outil que nous utiliserons est Ollama. Il simplifie l'installation et la gestion de grands modèles linguistiques sur les systèmes locaux.
Pour commencer, téléchargez Ollama et installez Ollama sur votre bureau. Nous pouvons modifier le nom du modèle en fonction de nos besoins. Consultez le modèle bibliothèque de modèles sur le site officiel d'Ollama pour découvrir les différents modèles pris en charge par Ollama. Exécutez le code suivant dans le terminal :
ollama run llama3.1 Nous sommes prêts. Commençons !
Nous commençons par les importations suivantes :
time pour curer le temps d'inférence pour le code de mise en cache et le code sans mise en cacherequests pour effectuer des requêtes HTTP et extraire des données de pages webBeautifulSoup pour l'analyse et le nettoyage du contenu HTMLOllama pour l'utilisation des MLD au niveau localimport time
import requests
from bs4 import BeautifulSoup
import ollamaDans le code ci-dessous, nous définissons une fonction fetch_article_content qui récupère et nettoie le contenu textuel d'une URL donnée. Il tente de récupérer le contenu de la page web à l'aide de la bibliothèque requests, avec jusqu'à trois tentatives en cas d'échecs tels que des erreurs de réseau ou des problèmes de serveur.
La fonction utilise BeautifulSoup pour analyser le contenu HTML et supprime les balises inutiles
Apprenez l'IA avec ces cours !
Cursus
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach