
Programa
Desenvolvimento de aplicativos de IA
21 h
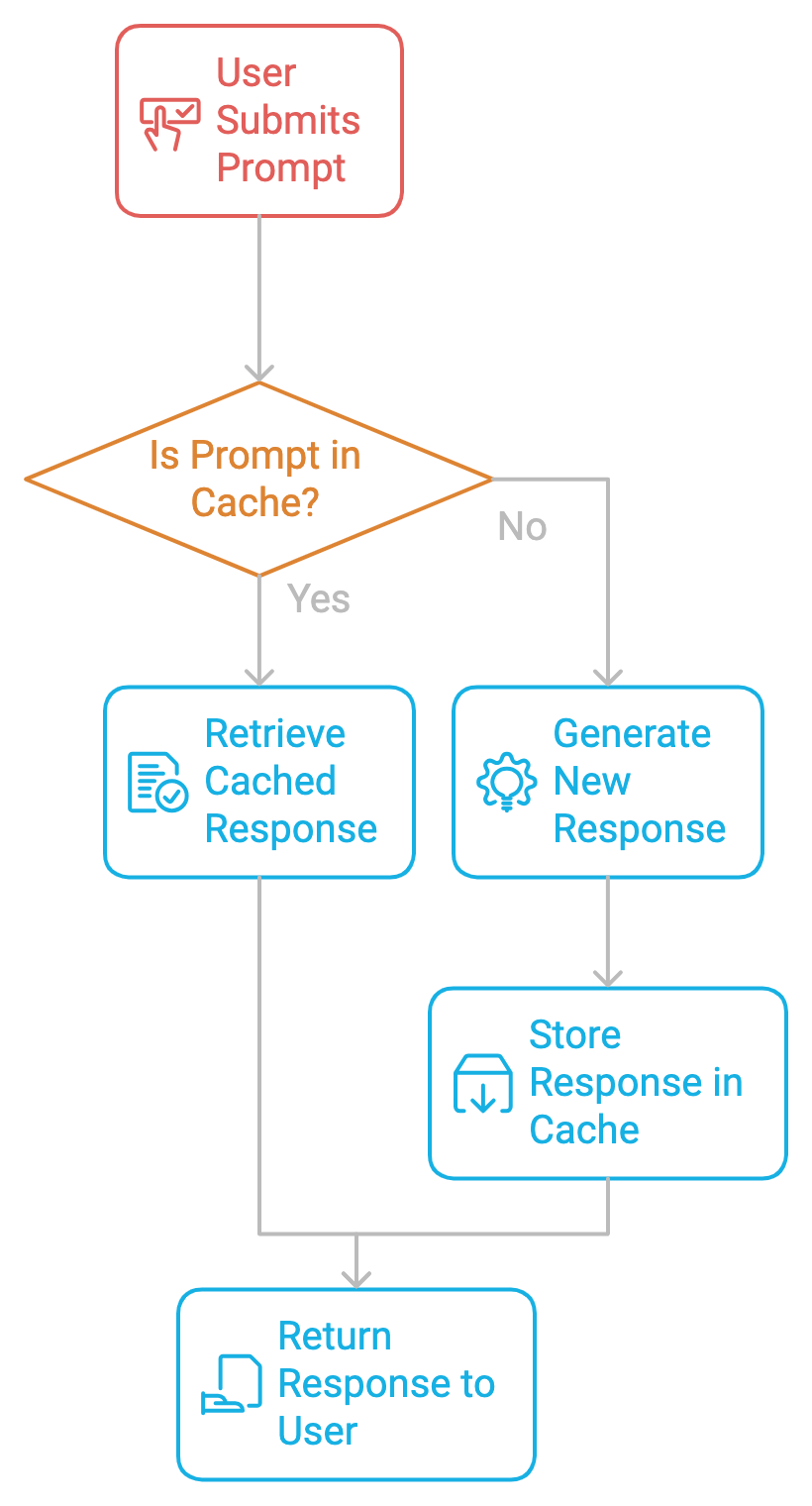
Em sua essência, o cache de prompts funciona armazenando prompts e suas respostas correspondentes em um cache. Quando o mesmo prompt ou um prompt semelhante é enviado novamente, o sistema recupera a resposta armazenada em cache em vez de gerar uma nova resposta. Isso evita a computação repetitiva, acelera os tempos de resposta e reduz os custos.
O cache imediato tem vários benefícios:
Antes de nos aprofundarmos na implementação do cache imediato, precisamos ter em mente algumas considerações.
Para garantir a atualização dos dados, cada resposta armazenada em cache deve ter um tempo de vida (TTL) na memória. O TTL determina por quanto tempo uma resposta em cache será considerada válida. Quando o TTL expira, a entrada do cache é removida ou atualizada, e o prompt correspondente é recalculado na próxima vez em que for solicitado.
Esse mecanismo garante que o cache não armazene informações desatualizadas. No caso de conteúdo estático ou atualizado com menos frequência, como documentos jurídicos ou manuais de produtos, um TTL mais longo pode ajudar a reduzir a recomputação sem correr o risco de perda de dados. Portanto, o ajuste adequado dos valores de TTL é essencial para manter um equilíbrio entre a atualização dos dados e a eficiência computacional.
Às vezes, dois prompts são semelhantes, mas não idênticos. Determinar a proximidade de um novo prompt em relação a um prompt em cache existente é fundamental para um armazenamento em cache eficaz. A implementação da similaridade de prompts requer técnicas como correspondência difusa ou pesquisa semântica, em que o sistema usa incorporação de vetores para representar prompts e comparar sua similaridade.
Ao armazenar em cache as respostas para solicitações semelhantes, os sistemas podem reduzir a recomputação e, ao mesmo tempo, manter a alta precisão das respostas. No entanto, definir o limite de similaridade de forma muito vaga pode levar a incompatibilidades, enquanto defini-lo de forma muito rígida pode perder oportunidades de armazenamento em cache.
Estratégias como LRU (Least Recently Used) ajudam a gerenciar o tamanho do cache. O método LRU remove os dados menos acessados quando o cache atinge sua capacidade. Essa estratégia funciona bem em cenários em que determinados prompts são mais populares e precisam permanecer em cache, enquanto as consultas menos comuns podem ser removidas para abrir espaço para solicitações mais recentes.
A implementação do cache imediato é um processo de duas etapas.
A primeira etapa da implementação do cache de prompts é identificar prompts frequentes e repetitivos no sistema. Seja para criar um chatbot, um assistente de codificação ou um processador de documentos, precisamos monitorar quais prompts estão sendo repetidos. Uma vez identificados, eles podem ser armazenados em cache para evitar cálculos redundantes.
Quando um prompt é identificado, sua resposta é armazenada no cache junto com metadados como tempo de vida (TTL), taxas de acerto/erro do cache e muito mais. Sempre que um usuário envia o mesmo prompt novamente, o sistema recupera a resposta armazenada em cache, ignorando o dispendioso processo de geração.
Com todo o conhecimento teórico, vamos mergulhar em um exemplo prático usando o Ollama para explorar o impacto do armazenamento em cache versus a ausência de armazenamento em cache em um ambiente local. Aqui, usamos dados de um livro de aprendizagem profunda hospedado na Web e modelos locais para resumir as primeiras páginas do livro. Faremos experimentos com vários LLMs, incluindo Gemma2, Llama2 e Llama3para comparar seu desempenho.
Para este exemplo prático, usaremos o BeautifulSoupum pacote Python que analisa documentos HTML e XML, inclusive aqueles com marcação malformada. Para instalar o BeautifulSoup, execute o seguinte:
!pip install BeautifulSoupOutra ferramenta que usaremos é o Ollama. Ele simplifica a instalação e o gerenciamento de grandes modelos de idiomas em sistemas locais.
Para começar, faça o download do Ollama e instale-o em sua área de trabalho. Podemos variar o nome do modelo de acordo com nossas necessidades. Confira o modelo biblioteca no site oficial do Ollama para que você possa procurar os diferentes modelos compatíveis com o Ollama. Execute o código a seguir no terminal:
ollama run llama3.1 Está tudo pronto. Vamos começar!
Começamos com as seguintes importações:
time para rastrear o tempo de inferência para o código de armazenamento em cache e sem armazenamento em cacherequests para fazer solicitações HTTP e obter dados de páginas da WebBeautifulSoup para analisar e limpar o conteúdo HTMLOllama para usar LLMs localmenteimport time
import requests
from bs4 import BeautifulSoup
import ollamaNo código abaixo, definimos uma função fetch_article_content que recupera e limpa o conteúdo de texto de um determinado URL. Ele tenta buscar o conteúdo da página da Web usando a biblioteca requests, com até três novas tentativas em caso de falhas, como erros de rede ou problemas no servidor.
A função usa BeautifulSoup para analisar o conteúdo HTML e remove as tags
Aprenda IA com estes cursos!
Programa
Curso
Curso
Tutorial
Matt Crabtree
Tutorial
Zoumana Keita
Tutorial
Tutorial
Ryan Ong
Tutorial
Kurtis Pykes


