Curso
Python intermedio
4 h
1.4M
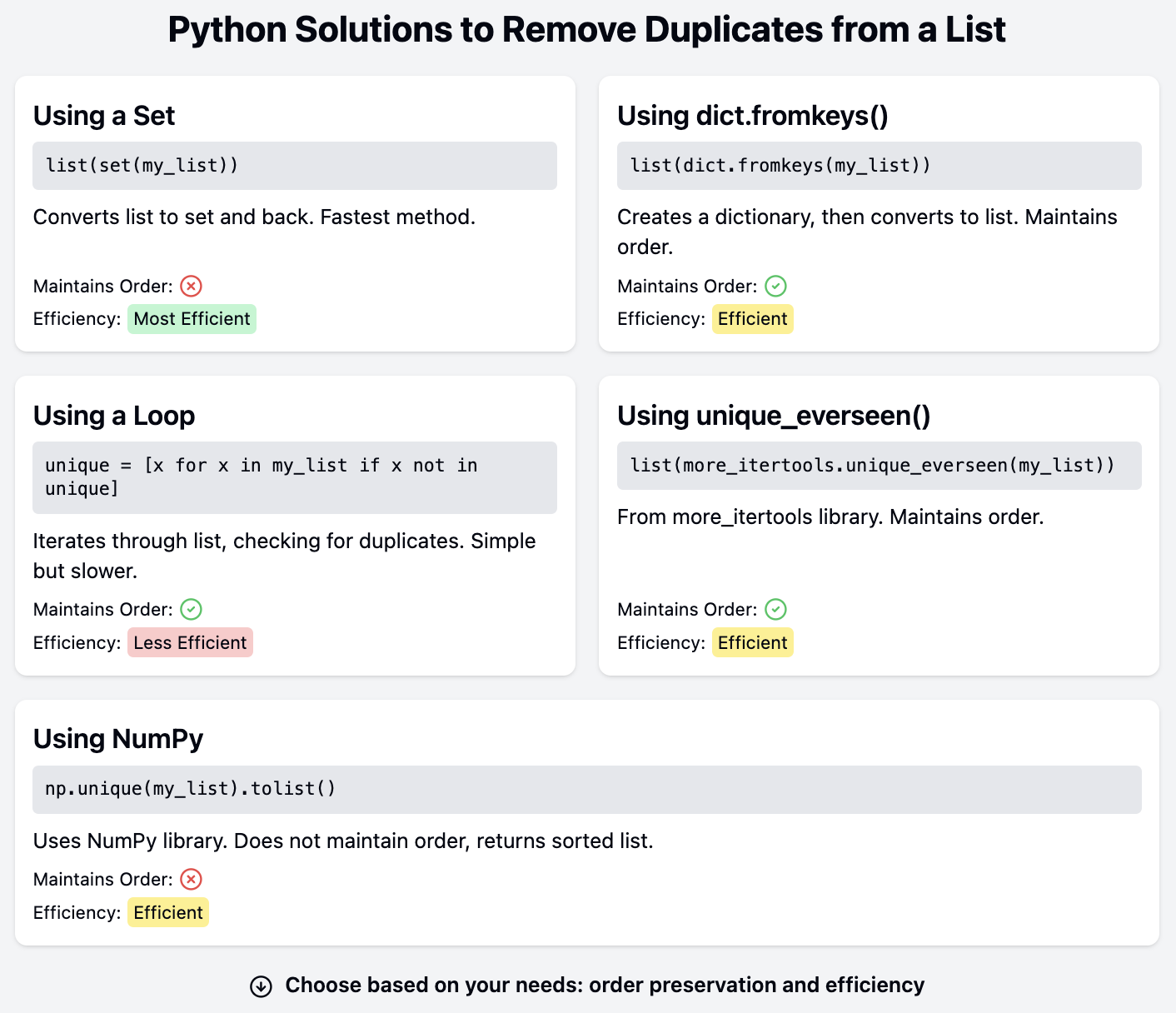
Un Python lista es una secuencia ordenada que puede contener valores duplicados. Algunas aplicaciones de Python pueden requerir una lista que sólo contenga elementos únicos. Existen varias técnicas para eliminar duplicados de una lista en Python.
La solución adecuada depende de si la aplicación necesita mantener el orden de los elementos de la lista una vez eliminados los duplicados. Las soluciones presentadas en este tutorial también varían en legibilidad y complejidad, y algunas dependen de funciones de módulos de terceros.
Conviene aclarar qué entendemos por valores duplicados antes de presentar soluciones para eliminarlos de una lista. En general, se considera que dos objetos están duplicados cuando sus valores son iguales. En Python, el operador de igualdad == devuelve True cuando dos objetos tienen el mismo valor. Los objetos de distintos tipos de datos pueden ser iguales:
print(10.0 == 10)
print(1 == True)True
TrueEl flotante 10.0 y el entero 10 son iguales, y el entero 1 y el booleano True también son iguales. En la mayoría de los casos, estos valores se consideran duplicados.
Algunas estructuras de datos de Python imponen valores únicos. Un conjunto es una colección que sólo contiene elementos únicos:
print({10, 10.0})
print({10.0, 10})
print({1, True, 1.0}){10}
{10.0}
{1}Este código crea tres conjuntos utilizando la notación de llaves {}. Cada conjunto contiene objetos iguales entre sí. Si se añaden objetos iguales de distintos tipos de datos a un conjunto, sólo se incluye el primer objeto.
Python también exige que las claves del diccionario sean únicas:
print({10: "Integer 10", 10.0: "Float 10"})
print({True: "Boolean True", 1: "Integer 1"}){10: 'Float 10'}
{True: 'Integer 1'}Los diccionarios de este código contienen claves iguales. Sólo se conserva la primera llave. Sin embargo, su valor se sustituye por el último valor añadido al diccionario asociado a una clave igual. Por tanto, en el primer ejemplo, la clave conservada es el número entero 10, pero su valor es la cadena "Float 10". En el segundo ejemplo, la clave True, que es igual a 1, está asociada al valor "Integer 1".
Los conjuntos y diccionarios desempeñan un papel en varias de las soluciones de este tutorial debido a sus requisitos de elementos o claves únicos.
La técnica más sencilla para eliminar duplicados de una lista es convertir la lista en un conjunto y volver a convertirla en una lista. Un conjunto sólo puede contener valores únicos. Por tanto, los duplicados se descartan cuando se añaden al conjunto:
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
print(list(set(names)))['Mark', 'Bob', 'Kate', 'James', 'Sarah']Veamos los pasos necesarios para eliminar duplicados de una lista utilizando esta técnica:
James y Kate aparecen dos veces en la lista original, pero sólo una vez en la lista final.
Sin embargo, los conjuntos son colecciones desordenadas. No se mantiene el orden de los elementos de un conjunto. Observa cómo los nombres de la lista final no están en el mismo orden en que aparecen en la lista original. El mismo código puede producir un orden diferente cuando se ejecuta de nuevo o cuando se utiliza un intérprete de Python distinto, ya que no hay garantía del orden de los elementos de un conjunto.
Esta solución es ideal cuando es aceptable perder información sobre el orden de los elementos de la lista. Sin embargo, necesitamos otras soluciones si hay que conservar el orden de los elementos.
Las claves de diccionario son similares a los conjuntos, ya que tienen que ser únicas. Un diccionario puede tener valores duplicados, pero no claves duplicadas.
Antes de Python 3.6, los diccionarios no mantenían el orden de sus elementos. Sin embargo, como efecto secundario de los cambios introducidos en la implementación de los diccionarios en Python 3.6, ahora los diccionarios mantienen el orden en que se añaden los elementos. Esto era simplemente un detalle de implementación en Python 3.6, pero se convirtió en una parte formal del lenguaje en Python 3.7.
La función dict.fromkeys() crea un diccionario a partir de un iterable. Los elementos del iterable se convierten en las claves del nuevo diccionario:
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
print(dict.fromkeys(names)){'James': None, 'Bob': None, 'Mark': None, 'Kate': None, 'Sarah': None}Como las claves de un diccionario son únicas, los valores duplicados se eliminan al crear el diccionario. Se garantiza que las claves tienen el mismo orden que los elementos de la lista si utilizas Python 3.7 o posterior. Por defecto, todas las claves tienen el valor None. Sin embargo, los valores no son necesarios, ya que este diccionario puede volver a convertirse en una lista:
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
print(list(dict.fromkeys(names)))['James', 'Bob', 'Mark', 'Kate', 'Sarah']Al convertir un diccionario en una lista, sólo se utilizan las claves. Esta técnica convierte la lista original en una nueva lista sin duplicados y manteniendo el orden original de los elementos.
Las opciones presentadas en la primera parte de este tutorial cubren los dos escenarios en los que hay que eliminar duplicados de una lista:
dict.fromkeys() para mantener el orden de los elementos.Es probable que estas dos opciones sean las mejores soluciones en la mayoría de las situaciones. Sin embargo, existen otras técnicas para eliminar duplicados de una lista.
Una opción sencilla es iterar por la lista original y añadir nuevos elementos a una nueva lista:
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
unique_names = []
for name in names:
if name not in unique_names:
unique_names.append(name)
print(unique_names)['James', 'Bob', 'Mark', 'Kate', 'Sarah']La nueva lista unique_names se inicializa como una lista vacía antes del bucle for. Se añade un elemento a esta nueva lista si no está ya en ella. Esta versión conserva el orden de los elementos de la lista original, ya que el bucle for recorre la lista en orden.
Esta solución puede ser ineficaz para listas grandes. Considera una lista más larga formada por números aleatorios. Podemos comparar el rendimiento de esta solución con la versión que utiliza dict.fromkeys():
import random
import timeit
data = [random.randint(0, 100) for _ in range(100)]
use_fromkeys = "unique_data = list(dict.fromkeys(data))"
use_for_loop = """unique_data = []
for item in data:
if item not in unique_data:
unique_data.append(item)"""
from_keys_time = timeit.timeit(use_fromkeys, globals=globals())
for_loop_time = timeit.timeit(use_for_loop, globals=globals())
print(f"Time for 'dict.fromkeys()' version: {from_keys_time:0.2f}s")
print(f"Time for loop version: {for_loop_time:0.2f}s")Time for 'dict.fromkeys()' version: 2.26s
Time for loop version: 17.88sLa función timeit() del módulo del mismo nombre temporiza la ejecución de una sentencia. Las declaraciones se pasan a timeit.timeit() como cadenas. La salida muestra que la versión del bucle for es significativamente más lenta que utilizando dict.fromkeys(). Los tiempos de ejecución variarán en distintos ordenadores y configuraciones, pero la opción dict.fromkeys() siempre será significativamente más rápida.
El bucle for de la sección anterior no puede convertirse en una comprensión de lista, ya que la sentencia if comprueba si ya se ha añadido un elemento a la nueva lista. Se necesita una estructura de datos independiente para utilizar una comprensión de lista. Se puede utilizar un conjunto para llevar la cuenta de los elementos que ya se han añadido a la lista:
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
items = set()
unique_names = [name for name in names if not (name in items or items.add(name))]
print(unique_names)['James', 'Bob', 'Mark', 'Kate', 'Sarah']Este tutorial muestra esta solución para completarlo, pero esta opción carece de legibilidad y no ofrece mejoras de rendimiento en comparación con el uso de dict.fromkeys().
Si el nombre ya está en el conjunto items, la expresión entre paréntesis en la comprensión de la lista se evalúa como True. La expresión que sigue a la palabra clave or no se evalúa cuando el primer operando es True, ya que or cortocircuita la evaluación. Como la expresión entre paréntesis es True, la cláusula if es False, y el nombre no se añade a unique_names.
Cuando el nombre no está en el conjunto items, la expresión que sigue a la palabra clave or se evalúa, y añade el nombre al conjunto. Sin embargo, el método .add() devuelve None, que es falso. La cláusula if es ahora True, y el nombre también se añade a la lista unique_names.
Varios módulos de terceros tienen herramientas para eliminar duplicados. La biblioteca de terceros more_itertools incluye unique_everseen(), que devuelve un iterador que devuelve elementos únicos conservando su orden.
La biblioteca more_itertools puede instalarse en el terminal utilizando pip u otros gestores de paquetes:
$ pip install more_itertoolsAhora podemos utilizar more_itertools.unique_everseen() para eliminar duplicados de una lista:
import more_itertools
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
unique_names = list(more_itertools.unique_everseen(names))
print(unique_names)['James', 'Bob', 'Mark', 'Kate', 'Sarah']Como unique_everseen() devuelve un iterador, su salida se convierte en una lista.
Otra biblioteca de terceros muy popular es NumPyque también ofrece una solución para eliminar duplicados. NumPy puede instalarse mediante pip u otros gestores de paquetes:
$ pip install numpyLa función unique() de NumPy devuelve una matriz NumPy con los elementos únicos de su argumento. Esta matriz de NumPy puede convertirse en una lista utilizando la función .tolist() de NumPy:
import numpy as np
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
unique_names = np.unique(names).tolist()
print(unique_names)['Bob', 'James', 'Kate', 'Mark', 'Sarah']Sin embargo, ten en cuenta que unique() de NumPy no conserva el orden de los elementos. En su lugar, devuelve elementos ordenados. Otra popular biblioteca de terceros, Pandastambién tiene una función unique() que funciona de forma similar pero conserva el orden de los elementos. Las soluciones NumPy y Pandas son ideales cuando estas bibliotecas ya se utilizan en la base de código y no es necesario instalarlas e importarlas simplemente para eliminar duplicados de una lista.
dict.fromkeys() ¿Mejor que utilizar un Set?En la mayoría de los casos, las mejores opciones son las dos primeras presentadas en este tutorial:
dict.fromkeys() y vuélvelo a convertir en una lista.Utilizar un diccionario conserva el orden de los elementos. Sin embargo, utilizar un conjunto es más eficaz y puede proporcionar mejoras de rendimiento si no se necesita el orden de los elementos.
La mejora del rendimiento puede cuantificarse utilizando timeit:
import random
import timeit
data = [random.randint(0, 100) for _ in range(100)]
use_fromkeys = "unique_data = list(dict.fromkeys(data))"
use_set = "unique_data = list(set(data))"
from_keys_time = timeit.timeit(use_fromkeys, globals=globals())
set_time = timeit.timeit(use_set, globals=globals())
print(f"Time for 'dict.fromkeys()' version: {from_keys_time:0.2f}s")
print(f"Time for set version: {set_time:0.2f}s")Time for 'dict.fromkeys()' version: 2.08s
Time for set version: 1.05sEliminar duplicados de una lista utilizando un conjunto es aproximadamente el doble de rápido que utilizando un diccionario.
Python y sus bibliotecas de terceros ofrecen varias opciones para eliminar duplicados de una lista.
Puedes seguir aprendiendo Python con estas entradas del blog:
Aprende Python con estos cursos
Curso
Curso
Curso
Tutorial
Allan Ouko
Tutorial
Sejal Jaiswal
Tutorial
Adel Nehme
Tutorial
DataCamp Team

