
Course
Intermediate Python
4 hr
1.4M
A Python list is an ordered sequence that can contain duplicate values. Some Python applications may require a list that only contains unique elements. There are several techniques to remove duplicates from a list in Python.
The right solution depends on whether the application needs to maintain the order of the list's items once the duplicates are removed. The solutions presented in this tutorial also vary in readability and complexity, and some rely on functions in third-party modules.
It's useful to clarify what we mean by duplicate values before presenting solutions to remove them from a list. Two objects are generally considered to be duplicates when their values are equal. In Python, the equality operator == returns True when two objects have the same value. Objects of different data types may be equal:
print(10.0 == 10)
print(1 == True)True
TrueThe float 10.0 and the integer 10 are equal, and the integer 1 and the Boolean True are also equal. In most scenarios, these values are considered duplicates.
Some Python data structures enforce unique values. A set is a collection that contains only unique elements:
print({10, 10.0})
print({10.0, 10})
print({1, True, 1.0}){10}
{10.0}
{1}This code creates three sets using the braces notation {}. Each set contains objects that are equal to each other. If equal objects of different data types are added to a set, only the first object is included.
Python also requires dictionary keys to be unique:
print({10: "Integer 10", 10.0: "Float 10"})
print({True: "Boolean True", 1: "Integer 1"}){10: 'Float 10'}
{True: 'Integer 1'}The dictionaries in this code contain equal keys. Only the first key is retained. However, its value is replaced by the last value added to the dictionary associated with an equal key. Therefore, in the first example, the key retained is the integer 10, but its value is the string "Float 10". In the second example, the key True, which is equal to 1, is associated with the value "Integer 1".
Sets and dictionaries play a role in several of the solutions in this tutorial because of their requirements for unique elements or keys.
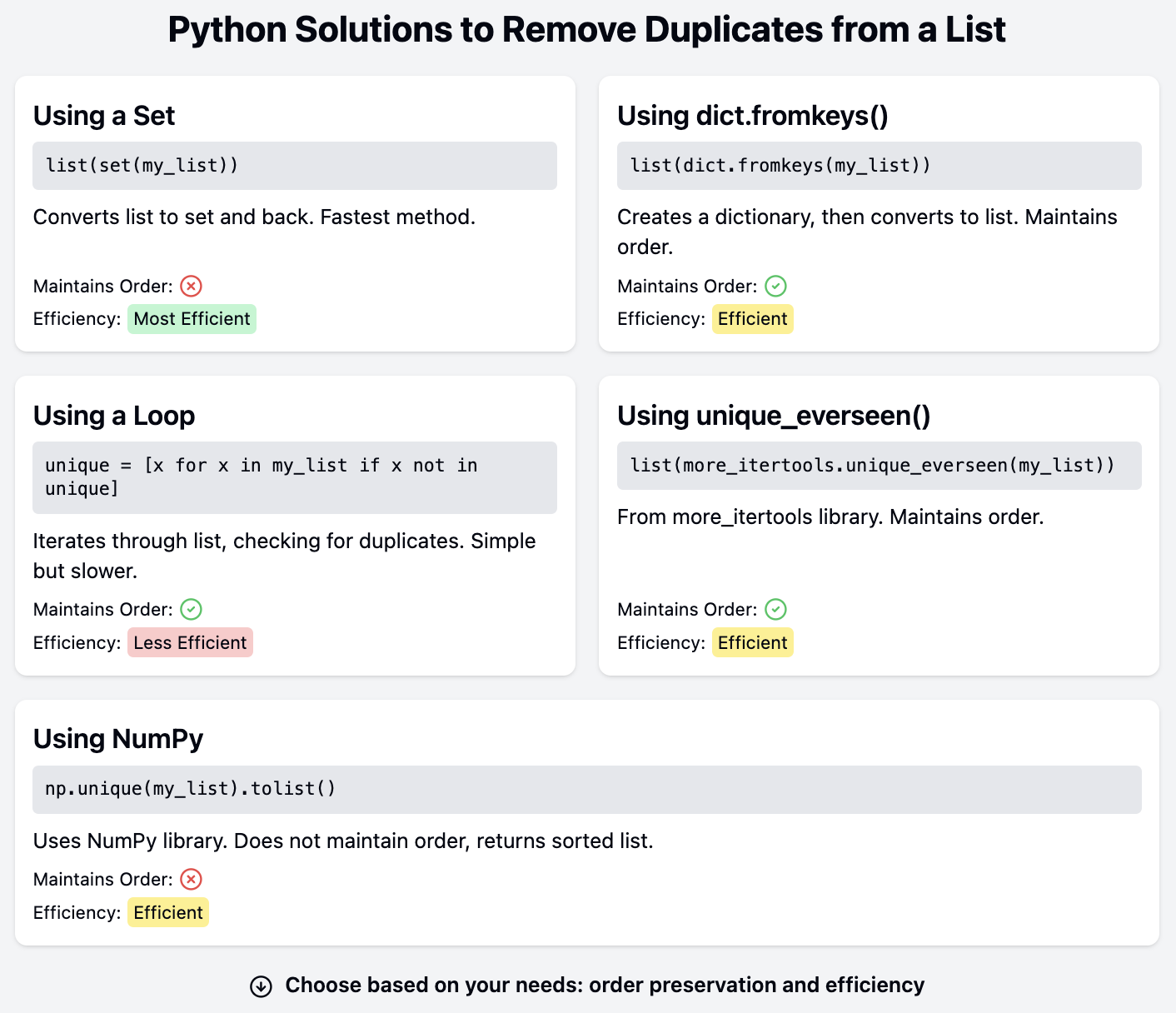
The simplest technique to remove duplicates from a list is to cast the list into a set and back to a list. A set can only contain unique values. Therefore, duplicates are discarded when added to the set:
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
print(list(set(names)))['Mark', 'Bob', 'Kate', 'James', 'Sarah']Let's look at the steps required to remove duplicates from a list using this technique:
James and Kate appear twice in the original list but only once in the final list.
However, sets are unordered collections. The order of items in a set is not maintained. Note how the names in the final list are not in the same order as they appear in the original list. The same code may produce a different order when run again or when using a different Python interpreter since there's no guarantee of the order of elements in a set.
This solution is ideal when it's acceptable to lose information about the order of the items in the list. However, we need other solutions if the order of the elements must be retained.
Dictionary keys are similar to sets since they have to be unique. A dictionary can have duplicated values but not duplicated keys.
Prior to Python 3.6, dictionaries didn't maintain the order of their elements. However, as a side effect of changes made to the implementation of dictionaries in Python 3.6, dictionaries now maintain the order in which items are added. This was merely an implementation detail in Python 3.6 but became a formal part of the language in Python 3.7.
The function dict.fromkeys() creates a dictionary from an iterable. The elements of the iterable become the keys of the new dictionary:
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
print(dict.fromkeys(names)){'James': None, 'Bob': None, 'Mark': None, 'Kate': None, 'Sarah': None}Since the keys in a dictionary are unique, the duplicate values are dropped when creating the dictionary. The keys are guaranteed to have the same order as the items in the list if using Python 3.7 or later. All keys have a value of None by default. However, the values aren't required since this dictionary can be cast back into a list:
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
print(list(dict.fromkeys(names)))['James', 'Bob', 'Mark', 'Kate', 'Sarah']When casting a dictionary into a list, only the keys are used. This technique converts the original list into a new list without duplicates and with the original order of the items maintained.
The options presented in the first part of this tutorial cover the two scenarios when duplicates need to be removed from a list:
dict.fromkeys() to maintain the order of the items.These two options are likely to be the best solutions in most situations. However, there are other techniques to remove duplicates from a list.
A straightforward option is to iterate through the original list and add new items to a new list:
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
unique_names = []
for name in names:
if name not in unique_names:
unique_names.append(name)
print(unique_names)['James', 'Bob', 'Mark', 'Kate', 'Sarah']The new list unique_names is initialized as an empty list before the for loop. An item is added to this new list if it's not already in it. This version retains the order of the items in the original list since the for loop iterates through the list in order.
This solution can be inefficient for large lists. Consider a longer list made up of random numbers. We can compare the performance of this solution with the version using dict.fromkeys():
import random
import timeit
data = [random.randint(0, 100) for _ in range(100)]
use_fromkeys = "unique_data = list(dict.fromkeys(data))"
use_for_loop = """unique_data = []
for item in data:
if item not in unique_data:
unique_data.append(item)"""
from_keys_time = timeit.timeit(use_fromkeys, globals=globals())
for_loop_time = timeit.timeit(use_for_loop, globals=globals())
print(f"Time for 'dict.fromkeys()' version: {from_keys_time:0.2f}s")
print(f"Time for loop version: {for_loop_time:0.2f}s")Time for 'dict.fromkeys()' version: 2.26s
Time for loop version: 17.88sThe timeit() function in the module of the same name times the execution of a statement. The statements are passed to timeit.timeit() as strings. The output shows that the for loop version is significantly slower than using dict.fromkeys(). The execution times will vary on different computers and setups, but the dict.fromkeys() option will always be significantly faster.
The for loop in the previous section cannot be converted into a list comprehension since the if statement checks whether an item has already been added to the new list. A separate data structure is required to use a list comprehension. A set can be used to keep track of the items that have already been added to the list:
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
items = set()
unique_names = [name for name in names if not (name in items or items.add(name))]
print(unique_names)['James', 'Bob', 'Mark', 'Kate', 'Sarah']This tutorial shows this solution for completeness, but this option lacks readability and offers no performance improvements compared to using dict.fromkeys().
If the name is already in the set items, the expression in parentheses in the list comprehension evaluates to True. The expression after the or keyword is not evaluated when the first operand is True since or short-circuits the evaluation. Since the expression in parentheses is True, the if clause is False, and the name is not added to unique_names.
When the name is not in the set items, the expression after the or keyword evaluates, and it adds the name to the set. However, the .add() method returns None, which is falsy. The if clause is now True, and the name is also added to the list unique_names.
A number of third-party modules have tools to remove duplicates. The more_itertools third-party library includes unique_everseen(), which returns an iterator that yields unique elements while preserving their order.
The more_itertools library can be installed in the terminal using pip or other package managers:
$ pip install more_itertoolsWe can now use more_itertools.unique_everseen() to remove duplicates from a list:
import more_itertools
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
unique_names = list(more_itertools.unique_everseen(names))
print(unique_names)['James', 'Bob', 'Mark', 'Kate', 'Sarah']Since unique_everseen() returns an iterator, its output is cast into a list.
Another popular third-party library is NumPy, which also offers a solution to remove duplicates. NumPy can be installed using pip or other package managers:
$ pip install numpyNumPy's unique() function returns a NumPy array with the unique elements from its argument. This NumPy array can be converted to a list using NumPy's .tolist():
import numpy as np
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
unique_names = np.unique(names).tolist()
print(unique_names)['Bob', 'James', 'Kate', 'Mark', 'Sarah']However, note that NumPy's unique() doesn't preserve the order of the items. Instead, it returns sorted items. Another popular third-party library, Pandas, also has a unique() function that works similarly but preserves the order of the items. The NumPy and Pandas solutions are ideal when these libraries are already in use in the codebase and don't need to be installed and imported simply to remove duplicates from a list.
dict.fromkeys() Better Than Using a Set?In most cases, the best options are the first two presented in this tutorial:
dict.fromkeys() and cast it back into a list.Using a dictionary preserves the order of the items. However, using a set is more efficient and can provide performance improvements if the order of the items is not needed.
The performance improvement can be quantified using timeit:
import random
import timeit
data = [random.randint(0, 100) for _ in range(100)]
use_fromkeys = "unique_data = list(dict.fromkeys(data))"
use_set = "unique_data = list(set(data))"
from_keys_time = timeit.timeit(use_fromkeys, globals=globals())
set_time = timeit.timeit(use_set, globals=globals())
print(f"Time for 'dict.fromkeys()' version: {from_keys_time:0.2f}s")
print(f"Time for set version: {set_time:0.2f}s")Time for 'dict.fromkeys()' version: 2.08s
Time for set version: 1.05sRemoving duplicates from a list using a set is roughly twice as fast as using a dictionary.
Python and its third-party libraries offer several options for removing duplicates from a list.
You can continue learning Python with these blog posts:
Learn Python with these courses!
Course
Course
Course
Tutorial
Oluseye Jeremiah
Tutorial
Allan Ouko
Tutorial
Neetika Khandelwal
Tutorial
Karlijn Willems
Tutorial
DataCamp Team
Tutorial
Abid Ali Awan

