Curso
Python intermediário
4 h
1.4M
Uma lista Python lista é uma sequência ordenada que pode conter valores duplicados. Alguns aplicativos Python podem exigir uma lista que contenha apenas elementos exclusivos. Há várias técnicas para remover duplicatas de uma lista em Python.
A solução correta depende do fato de o aplicativo precisar manter a ordem dos itens da lista depois que as duplicatas forem removidas. As soluções apresentadas neste tutorial também variam em termos de legibilidade e complexidade, e algumas dependem de funções em módulos de terceiros.
É útil esclarecer o que queremos dizer com valores duplicados antes de apresentar soluções para removê-los de uma lista. Em geral, dois objetos são considerados duplicados quando seus valores são iguais. Em Python, o operador de igualdade == retorna True quando dois objetos têm o mesmo valor. Objetos de diferentes tipos de dados podem ser iguais:
print(10.0 == 10)
print(1 == True)True
TrueO float 10.0 e o inteiro 10 são iguais, e o inteiro 1 e o booleano True também são iguais. Na maioria dos cenários, esses valores são considerados duplicados.
Algumas estruturas de dados do Python impõem valores exclusivos. Um conjunto é uma coleção que contém apenas elementos exclusivos:
print({10, 10.0})
print({10.0, 10})
print({1, True, 1.0}){10}
{10.0}
{1}Este código cria três conjuntos usando a notação de chaves {}. Cada conjunto contém objetos que são iguais uns aos outros. Se objetos iguais de tipos de dados diferentes forem adicionados a um conjunto, somente o primeiro objeto será incluído.
O Python também exige que as chaves do dicionário sejam exclusivas:
print({10: "Integer 10", 10.0: "Float 10"})
print({True: "Boolean True", 1: "Integer 1"}){10: 'Float 10'}
{True: 'Integer 1'}Os dicionários desse código contêm chaves iguais. Somente a primeira chave é mantida. No entanto, seu valor é substituído pelo último valor adicionado ao dicionário associado a uma chave igual. Portanto, no primeiro exemplo, a chave retida é o número inteiro 10, mas seu valor é a cadeia de caracteres "Float 10". No segundo exemplo, a chave True, que é igual a 1, está associada ao valor "Integer 1".
Os conjuntos e dicionários desempenham um papel importante em várias das soluções deste tutorial devido a seus requisitos de elementos ou chaves exclusivos.
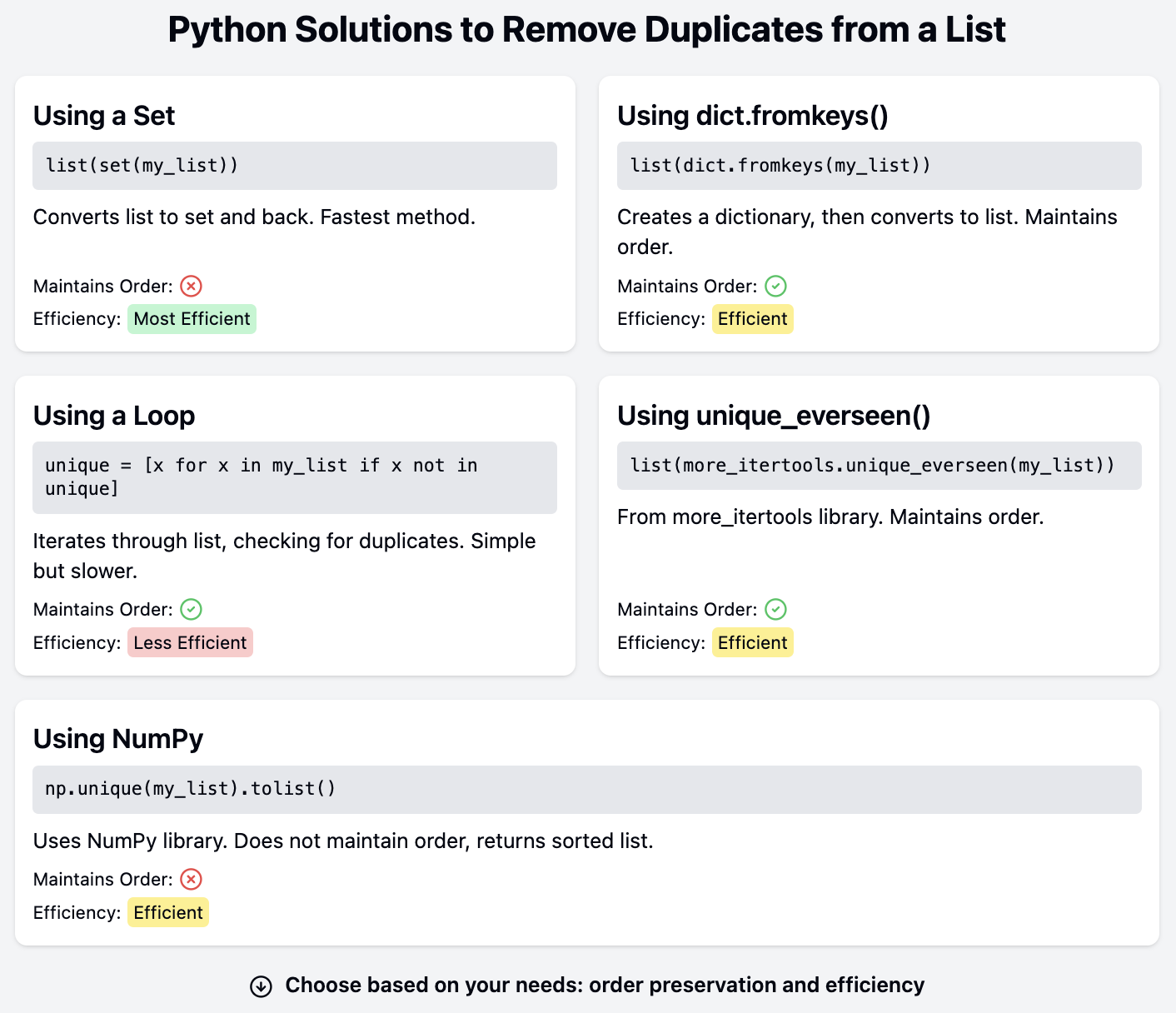
A técnica mais simples para remover duplicatas de uma lista é converter a lista em um conjunto e voltar para uma lista. Um conjunto só pode conter valores exclusivos. Portanto, as duplicatas são descartadas quando adicionadas ao conjunto:
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
print(list(set(names)))['Mark', 'Bob', 'Kate', 'James', 'Sarah']Vejamos as etapas necessárias para remover duplicatas de uma lista usando essa técnica:
James e Kate aparecem duas vezes na lista original, mas apenas uma vez na lista final.
No entanto, os conjuntos são coleções não ordenadas. A ordem dos itens em um conjunto não é mantida. Observe como os nomes na lista final não estão na mesma ordem em que aparecem na lista original. O mesmo código pode produzir uma ordem diferente quando executado novamente ou quando você usar um interpretador Python diferente, pois não há garantia da ordem dos elementos em um conjunto.
Essa solução é ideal quando é aceitável que você perca informações sobre a ordem dos itens na lista. No entanto, precisamos de outras soluções se a ordem dos elementos tiver que ser mantida.
As chaves de dicionário são semelhantes aos conjuntos, pois precisam ser exclusivas. Um dicionário pode ter valores duplicados, mas não chaves duplicadas.
Antes do Python 3.6, os dicionários não mantinham a ordem de seus elementos. No entanto, como um efeito colateral das alterações feitas na implementação de dicionários no Python 3.6, os dicionários agora mantêm a ordem em que os itens são adicionados. Isso era apenas um detalhe de implementação no Python 3.6, mas tornou-se uma parte formal da linguagem no Python 3.7.
A função dict.fromkeys() cria um dicionário a partir de um iterável. Os elementos do iterável se tornam as chaves do novo dicionário:
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
print(dict.fromkeys(names)){'James': None, 'Bob': None, 'Mark': None, 'Kate': None, 'Sarah': None}Como as chaves em um dicionário são exclusivas, os valores duplicados são descartados ao criar o dicionário. Se você estiver usando o Python 3.7 ou posterior, é garantido que as chaves tenham a mesma ordem dos itens da lista. Todas as chaves têm um valor de None por padrão. No entanto, os valores não são necessários, pois esse dicionário pode ser convertido novamente em uma lista:
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
print(list(dict.fromkeys(names)))['James', 'Bob', 'Mark', 'Kate', 'Sarah']Ao converter um dicionário em uma lista, somente as chaves são usadas. Essa técnica converte a lista original em uma nova lista sem duplicatas e com a ordem original dos itens mantida.
As opções apresentadas na primeira parte deste tutorial abrangem os dois cenários em que as duplicatas precisam ser removidas de uma lista:
dict.fromkeys() para manter a ordem dos itens.É provável que essas duas opções sejam as melhores soluções na maioria das situações. No entanto, há outras técnicas para remover duplicatas de uma lista.
Uma opção simples é iterar pela lista original e adicionar novos itens a uma nova lista:
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
unique_names = []
for name in names:
if name not in unique_names:
unique_names.append(name)
print(unique_names)['James', 'Bob', 'Mark', 'Kate', 'Sarah']A nova lista unique_names é inicializada como uma lista vazia antes do loop for. Um item é adicionado a essa nova lista se ainda não estiver nela. Essa versão mantém a ordem dos itens na lista original, pois o loop for itera pela lista em ordem.
Essa solução pode ser ineficiente para listas grandes. Considere uma lista mais longa composta de números aleatórios. Podemos comparar o desempenho dessa solução com a versão que usa dict.fromkeys():
import random
import timeit
data = [random.randint(0, 100) for _ in range(100)]
use_fromkeys = "unique_data = list(dict.fromkeys(data))"
use_for_loop = """unique_data = []
for item in data:
if item not in unique_data:
unique_data.append(item)"""
from_keys_time = timeit.timeit(use_fromkeys, globals=globals())
for_loop_time = timeit.timeit(use_for_loop, globals=globals())
print(f"Time for 'dict.fromkeys()' version: {from_keys_time:0.2f}s")
print(f"Time for loop version: {for_loop_time:0.2f}s")Time for 'dict.fromkeys()' version: 2.26s
Time for loop version: 17.88sA função timeit() no módulo com o mesmo nome cronometra a execução de uma declaração. As instruções são passadas para timeit.timeit() como strings. O resultado mostra que a versão do loop for é significativamente mais lenta do que o uso do dict.fromkeys(). Os tempos de execução variam em diferentes computadores e configurações, mas a opção dict.fromkeys() sempre será significativamente mais rápida.
O loop for da seção anterior não pode ser convertido em uma compreensão de lista, pois a instrução if verifica se um item já foi adicionado à nova lista. Você precisa de uma estrutura de dados separada para usar uma compreensão de lista. Um conjunto pode ser usado para manter o controle dos itens que já foram adicionados à lista:
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
items = set()
unique_names = [name for name in names if not (name in items or items.add(name))]
print(unique_names)['James', 'Bob', 'Mark', 'Kate', 'Sarah']Este tutorial mostra essa solução para que você fique completo, mas essa opção não é legível e não oferece melhorias de desempenho em comparação com o uso de dict.fromkeys().
Se o nome já estiver no conjunto items, a expressão entre parênteses na compreensão de lista será avaliada como True. A expressão após a palavra-chave or não é avaliada quando o primeiro operando é True, pois or causa um curto-circuito na avaliação. Como a expressão entre parênteses é True, a cláusula if é False, e o nome não é adicionado a unique_names.
Quando o nome não está no conjunto items, a expressão após a palavra-chave or é avaliada e adiciona o nome ao conjunto. No entanto, o método .add() retorna None, o que é falso. A cláusula if agora é True, e o nome também é adicionado à lista unique_names.
Vários módulos de terceiros têm ferramentas para remover duplicatas. A biblioteca de terceiros more_itertools A biblioteca de terceiros inclui unique_everseen(), que retorna um iterador que produz elementos exclusivos, preservando a ordem deles.
A biblioteca more_itertools pode ser instalada no terminal usando o pip ou outros gerenciadores de pacotes:
$ pip install more_itertoolsAgora podemos usar o site more_itertools.unique_everseen() para remover duplicatas de uma lista:
import more_itertools
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
unique_names = list(more_itertools.unique_everseen(names))
print(unique_names)['James', 'Bob', 'Mark', 'Kate', 'Sarah']Como o unique_everseen() retorna um iterador, sua saída é convertida em uma lista.
Outra biblioteca popular de terceiros é o NumPyque também oferece uma solução para remover duplicatas. Você pode instalar o NumPy usando o site pip ou outros gerenciadores de pacotes:
$ pip install numpyA função unique() do NumPy retorna uma matriz NumPy com os elementos exclusivos de seu argumento. Essa matriz do NumPy pode ser convertida em uma lista usando o .tolist() do NumPy:
import numpy as np
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
unique_names = np.unique(names).tolist()
print(unique_names)['Bob', 'James', 'Kate', 'Mark', 'Sarah']No entanto, observe que o site unique() do NumPy não preserva a ordem dos itens. Em vez disso, ele retorna itens classificados. Outra biblioteca popular de terceiros, Pandastambém tem uma função unique() que funciona de forma semelhante, mas preserva a ordem dos itens. As soluções NumPy e Pandas são ideais quando essas bibliotecas já estão em uso na base de código e não precisam ser instaladas e importadas simplesmente para remover duplicatas de uma lista.
dict.fromkeys() É melhor do que usar um conjunto?Na maioria dos casos, as melhores opções são as duas primeiras apresentadas neste tutorial:
dict.fromkeys() e converta-o novamente em uma lista.O uso de um dicionário preserva a ordem dos itens. No entanto, o uso de um conjunto é mais eficiente e pode proporcionar melhorias no desempenho se a ordem dos itens não for necessária.
A melhoria do desempenho pode ser quantificada usando timeit:
import random
import timeit
data = [random.randint(0, 100) for _ in range(100)]
use_fromkeys = "unique_data = list(dict.fromkeys(data))"
use_set = "unique_data = list(set(data))"
from_keys_time = timeit.timeit(use_fromkeys, globals=globals())
set_time = timeit.timeit(use_set, globals=globals())
print(f"Time for 'dict.fromkeys()' version: {from_keys_time:0.2f}s")
print(f"Time for set version: {set_time:0.2f}s")Time for 'dict.fromkeys()' version: 2.08s
Time for set version: 1.05sA remoção de duplicatas de uma lista usando um conjunto é aproximadamente duas vezes mais rápida do que usando um dicionário.
O Python e suas bibliotecas de terceiros oferecem várias opções para você remover duplicatas de uma lista.
Você pode continuar aprendendo Python com estas publicações do blog:
Aprenda Python com estes cursos!
Curso
Curso
Curso
blog
DataCamp Team
5 min
blog
Javier Canales Luna
13 min
Tutorial
Allan Ouko
Tutorial
Sejal Jaiswal


