
Kurs
Python für Fortgeschrittene
4 Std.
1.4M
Eine Python Liste ist eine geordnete Folge, die doppelte Werte enthalten kann. Einige Python-Anwendungen benötigen möglicherweise eine Liste, die nur eindeutige Elemente enthält. Es gibt verschiedene Techniken, um Duplikate aus einer Liste in Python zu entfernen.
Die richtige Lösung hängt davon ab, ob die Anwendung die Reihenfolge der Einträge in der Liste beibehalten muss, nachdem die Duplikate entfernt wurden. Die in diesem Lernprogramm vorgestellten Lösungen unterscheiden sich auch in ihrer Lesbarkeit und Komplexität, und einige beruhen auf Funktionen in Modulen von Drittanbietern.
Es ist sinnvoll zu klären, was wir mit doppelten Wertenmeinen , bevor wir Lösungen vorstellen, um sie aus einer Liste zu entfernen. Zwei Objekte werden im Allgemeinen als Duplikate betrachtet, wenn ihre Werte gleich sind. In Python gibt der Gleichheitsoperator == True zurück, wenn zwei Objekte den gleichen Wert haben. Objekte mit unterschiedlichen Datentypen können gleich sein:
print(10.0 == 10)
print(1 == True)True
TrueDie Fließkommazahl 10.0 und die Ganzzahl 10 sind gleich, und die Ganzzahl 1 und die boolesche Zahl True sind ebenfalls gleich. In den meisten Szenarien werden diese Werte als Duplikate betrachtet.
Einige Python-Datenstrukturen erzwingen eindeutige Werte. Eine Menge ist eine Sammlung, die nur eindeutige Elemente enthält:
print({10, 10.0})
print({10.0, 10})
print({1, True, 1.0}){10}
{10.0}
{1}In diesem Code werden drei Sätze mit der Klammerschreibweise {} erstellt. Jede Menge enthält Objekte, die einander gleich sind. Wenn gleiche Objekte mit unterschiedlichen Datentypen zu einer Menge hinzugefügt werden, wird nur das erste Objekt einbezogen.
Python verlangt auch, dass Wörterbuchschlüssel eindeutig sind:
print({10: "Integer 10", 10.0: "Float 10"})
print({True: "Boolean True", 1: "Integer 1"}){10: 'Float 10'}
{True: 'Integer 1'}Die Wörterbücher in diesem Code enthalten gleiche Schlüssel. Nur der erste Schlüssel wird beibehalten. Sein Wert wird jedoch durch den letzten Wert ersetzt, der dem Wörterbuch mit dem gleichen Schlüssel hinzugefügt wurde. Im ersten Beispiel ist der Schlüssel also die ganze Zahl 10, der Wert aber die Zeichenkette "Float 10". Im zweiten Beispiel wird der Schlüssel True, der gleich 1 ist, mit dem Wert "Integer 1" verknüpft.
Sets und Wörterbücher spielen in mehreren Lösungen dieses Tutorials eine Rolle, da sie eindeutige Elemente oder Schlüssel erfordern.
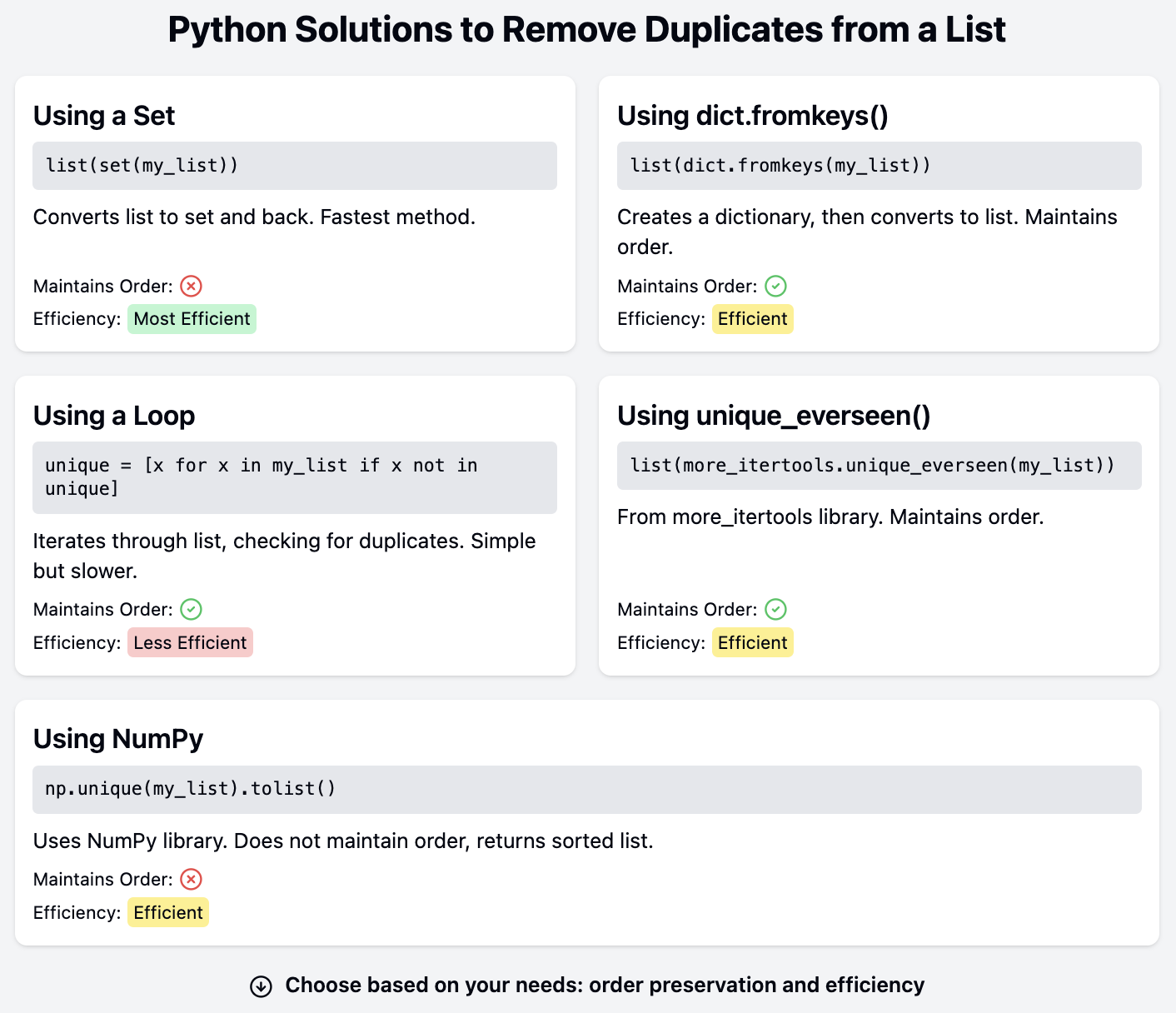
Die einfachste Methode, um Duplikate aus einer Liste zu entfernen, ist, die Liste in eine Menge und wieder zurück in eine Liste zu verwandeln. Ein Set kann nur eindeutige Werte enthalten. Daher werden Duplikate verworfen, wenn sie der Menge hinzugefügt werden:
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
print(list(set(names)))['Mark', 'Bob', 'Kate', 'James', 'Sarah']Schauen wir uns die Schritte an, die erforderlich sind, um mit dieser Technik Duplikate aus einer Liste zu entfernen:
James und Kate erscheinen zweimal in der ursprünglichen Liste, aber nur einmal in der endgültigen Liste.
Mengen sind jedoch ungeordnete Sammlungen. Die Reihenfolge der Elemente in einem Set wird nicht beibehalten. Beachte, dass die Namen in der endgültigen Liste nicht in der gleichen Reihenfolge stehen wie in der ursprünglichen Liste. Derselbe Code kann bei einer erneuten Ausführung oder bei Verwendung eines anderen Python-Interpreters eine andere Reihenfolge ergeben, da es keine Garantie für die Reihenfolge der Elemente in einer Menge gibt.
Diese Lösung ist ideal, wenn es akzeptabel ist, Informationen über die Reihenfolge der Elemente in der Liste zu verlieren. Wir brauchen jedoch andere Lösungen, wenn die Reihenfolge der Elemente beibehalten werden soll.
Wörterbuchschlüssel sind ähnlich wie Mengen, da sie eindeutig sein müssen. Ein Wörterbuch kann doppelte Werte haben, aber keine doppelten Schlüssel.
Vor Python 3.6 behielten die Wörterbücher die Reihenfolge ihrer Elemente nicht bei. Ein Nebeneffekt der Änderungen, die in Python 3.6 an der Implementierung von Wörterbüchern vorgenommen wurden, ist jedoch, dass Wörterbücher nun die Reihenfolge beibehalten, in der Elemente hinzugefügt werden. In Python 3.6 war dies nur ein Implementierungsdetail, aber in Python 3.7 wurde es formaler Bestandteil der Sprache.
Die Funktion dict.fromkeys() erstellt ein Wörterbuch aus einer Iterable. Die Elemente der Iterable werden zu den Schlüsseln des neuen Wörterbuchs:
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
print(dict.fromkeys(names)){'James': None, 'Bob': None, 'Mark': None, 'Kate': None, 'Sarah': None}Da die Schlüssel in einem Wörterbuch eindeutig sind, werden die doppelten Werte bei der Erstellung des Wörterbuchs gelöscht. Die Schlüssel haben garantiert die gleiche Reihenfolge wie die Elemente in der Liste, wenn du Python 3.7 oder höher verwendest. Alle Schlüssel haben standardmäßig einen Wert von None. Die Werte sind jedoch nicht erforderlich, da dieses Wörterbuch in eine Liste zurückgewandelt werden kann:
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
print(list(dict.fromkeys(names)))['James', 'Bob', 'Mark', 'Kate', 'Sarah']Wenn du ein Wörterbuch in eine Liste umwandelst, werden nur die Schlüssel verwendet. Mit dieser Technik wird die ursprüngliche Liste in eine neue Liste ohne Duplikate umgewandelt, wobei die ursprüngliche Reihenfolge der Einträge beibehalten wird.
Die im ersten Teil dieses Tutorials vorgestellten Optionen decken die beiden Szenarien ab, in denen Duplikate aus einer Liste entfernt werden müssen:
dict.fromkeys(), um die Reihenfolge der Artikel beizubehalten.Diese beiden Optionen sind wahrscheinlich in den meisten Situationen die beste Lösung. Es gibt aber auch andere Techniken, um Duplikate aus einer Liste zu entfernen.
Eine einfache Möglichkeit ist es, die ursprüngliche Liste zu durchlaufen und neue Elemente zu einer neuen Liste hinzuzufügen:
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
unique_names = []
for name in names:
if name not in unique_names:
unique_names.append(name)
print(unique_names)['James', 'Bob', 'Mark', 'Kate', 'Sarah']Die neue Liste unique_names wird vor der for Schleife als leere Liste initialisiert. Ein Element wird zu dieser neuen Liste hinzugefügt, wenn es noch nicht in ihr enthalten ist. Diese Version behält die Reihenfolge der Elemente in der ursprünglichen Liste bei, da die for Schleife die Liste der Reihe nach durchläuft.
Diese Lösung kann bei großen Listen ineffizient sein. Betrachte eine längere Liste, die aus Zufallszahlen besteht. Wir können die Leistung dieser Lösung mit der Version vergleichen, die dict.fromkeys() verwendet:
import random
import timeit
data = [random.randint(0, 100) for _ in range(100)]
use_fromkeys = "unique_data = list(dict.fromkeys(data))"
use_for_loop = """unique_data = []
for item in data:
if item not in unique_data:
unique_data.append(item)"""
from_keys_time = timeit.timeit(use_fromkeys, globals=globals())
for_loop_time = timeit.timeit(use_for_loop, globals=globals())
print(f"Time for 'dict.fromkeys()' version: {from_keys_time:0.2f}s")
print(f"Time for loop version: {for_loop_time:0.2f}s")Time for 'dict.fromkeys()' version: 2.26s
Time for loop version: 17.88sDie Funktion timeit() in dem gleichnamigen Modul verzögert die Ausführung einer Anweisung. Die Anweisungen werden als Strings an timeit.timeit() übergeben. Die Ausgabe zeigt, dass die Version mit der for Schleife deutlich langsamer ist als die mit dict.fromkeys(). Die Ausführungszeiten variieren auf verschiedenen Computern und Konfigurationen, aber die Option dict.fromkeys() wird immer deutlich schneller sein.
Die Schleife for im vorherigen Abschnitt kann nicht in ein Listenverständnis umgewandelt werden, da die Anweisung if prüft, ob der neuen Liste bereits ein Element hinzugefügt wurde. Für die Verwendung eines Listenverständnisses ist eine eigene Datenstruktur erforderlich. Ein Lernpfad kann verwendet werden, um den Überblick über die Gegenstände zu behalten, die bereits zur Liste hinzugefügt wurden:
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
items = set()
unique_names = [name for name in names if not (name in items or items.add(name))]
print(unique_names)['James', 'Bob', 'Mark', 'Kate', 'Sarah']Dieses Tutorial zeigt diese Lösung nur der Vollständigkeit halber, aber diese Option ist unübersichtlich und bietet keine Leistungsverbesserung im Vergleich zur Verwendung von dict.fromkeys().
Wenn der Name bereits in der Menge items enthalten ist, wird der Ausdruck in Klammern im Listenverständnis zu True ausgewertet. Der Ausdruck nach dem Schlüsselwort or wird nicht ausgewertet, wenn der erste Operand True ist, da or die Auswertung kurzschließt. Da der Ausdruck in Klammern True ist, ist die if Klausel False und der Name wird nicht zu unique_names hinzugefügt.
Wenn der Name nicht in der Menge items enthalten ist, wird der Ausdruck nach dem Schlüsselwort or ausgewertet und der Name zur Menge hinzugefügt. Die Methode .add() gibt jedoch None zurück, was fehlerhaft ist. Die Klausel if heißt jetzt True, und der Name wird auch in die Liste unique_names aufgenommen.
Eine Reihe von Modulen von Drittanbietern haben Werkzeuge, um Duplikate zu entfernen. Die more_itertools Drittanbieter-Bibliothek enthält unique_everseen(), die einen Iterator zurückgibt, der eindeutige Elemente liefert und dabei ihre Reihenfolge beibehält.
Die Bibliothek more_itertools kann mit pip oder anderen Paketmanagern im Terminal installiert werden:
$ pip install more_itertoolsWir können jetzt more_itertools.unique_everseen() verwenden, um Duplikate aus einer Liste zu entfernen:
import more_itertools
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
unique_names = list(more_itertools.unique_everseen(names))
print(unique_names)['James', 'Bob', 'Mark', 'Kate', 'Sarah']Da unique_everseen() einen Iterator zurückgibt, wird seine Ausgabe in eine Liste umgewandelt.
Eine weitere beliebte Drittanbieter-Bibliothek ist NumPydie ebenfalls eine Lösung zum Entfernen von Duplikaten bietet. NumPy kann mit pip oder anderen Paketmanagern installiert werden:
$ pip install numpyDie Funktion unique() von NumPy gibt ein NumPy-Array mit den eindeutigen Elementen aus ihrem Argument zurück. Dieses NumPy-Array kann mit NumPy .tolist() in eine Liste umgewandelt werden:
import numpy as np
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
unique_names = np.unique(names).tolist()
print(unique_names)['Bob', 'James', 'Kate', 'Mark', 'Sarah']Beachte jedoch, dass NumPy's unique() die Reihenfolge der Elemente nicht beibehält. Stattdessen gibt es sortierte Artikel zurück. Eine weitere beliebte Drittanbieter-Bibliothek, Pandashat auch eine unique() Funktion, die ähnlich funktioniert, aber die Reihenfolge der Elemente beibehält. Die Lösungen mit NumPy und Pandas sind ideal, wenn diese Bibliotheken bereits in der Codebasis verwendet werden und nicht erst installiert und importiert werden müssen, um Duplikate aus einer Liste zu entfernen.
dict.fromkeys() Besser als ein Set zu benutzen?In den meisten Fällen sind die ersten beiden Optionen, die in diesem Tutorial vorgestellt werden, die besten:
dict.fromkeys() ein Wörterbuch aus der Liste und wandle es wieder in eine Liste um.Bei der Verwendung eines Wörterbuchs bleibt die Reihenfolge der Elemente erhalten. Die Verwendung einer Menge ist jedoch effizienter und kann zu Leistungsverbesserungen führen, wenn die Reihenfolge der Elemente nicht erforderlich ist.
Die Leistungsverbesserung kann mit timeit quantifiziert werden:
import random
import timeit
data = [random.randint(0, 100) for _ in range(100)]
use_fromkeys = "unique_data = list(dict.fromkeys(data))"
use_set = "unique_data = list(set(data))"
from_keys_time = timeit.timeit(use_fromkeys, globals=globals())
set_time = timeit.timeit(use_set, globals=globals())
print(f"Time for 'dict.fromkeys()' version: {from_keys_time:0.2f}s")
print(f"Time for set version: {set_time:0.2f}s")Time for 'dict.fromkeys()' version: 2.08s
Time for set version: 1.05sDas Entfernen von Duplikaten aus einer Liste mit einer Menge ist etwa doppelt so schnell wie mit einem Wörterbuch.
Python und seine Bibliotheken von Drittanbietern bieten mehrere Möglichkeiten, um Duplikate aus einer Liste zu entfernen.
Du kannst Python mit diesen Blogbeiträgen weiter lernen:
Lerne Python mit diesen Kursen!
Kurs
Kurs
Kurs