
Cours
Python intermédiaire
4 h
1.4M
Un Python liste est une séquence ordonnée qui peut contenir des valeurs en double. Certaines applications de Python peuvent nécessiter une liste qui ne contient que des éléments uniques. Il existe plusieurs techniques pour supprimer les doublons d'une liste en Python.
La bonne solution dépend de la nécessité pour l'application de maintenir l'ordre des éléments de la liste une fois les doublons supprimés. Les solutions présentées dans ce tutoriel varient également en termes de lisibilité et de complexité, et certaines reposent sur des fonctions de modules tiers.
Il est utile de préciser ce que l'on entend par valeurs en double avant de présenter des solutions pour les supprimer d'une liste. Deux objets sont généralement considérés comme des doublons lorsque leurs valeurs sont égales. En Python, l'opérateur d'égalité == renvoie True lorsque deux objets ont la même valeur. Des objets de types de données différents peuvent être égaux :
print(10.0 == 10)
print(1 == True)True
TrueLe flottant 10.0 et l'entier 10 sont égaux, et l'entier 1 et le booléen True sont également égaux. Dans la plupart des scénarios, ces valeurs sont considérées comme des doublons.
Certaines structures de données Python imposent des valeurs uniques. Un ensemble est une collection qui ne contient que des éléments uniques :
print({10, 10.0})
print({10.0, 10})
print({1, True, 1.0}){10}
{10.0}
{1}Ce code crée trois ensembles en utilisant la notation entre accolades {}. Chaque ensemble contient des objets égaux entre eux. Si des objets égaux de types de données différents sont ajoutés à un ensemble, seul le premier objet est inclus.
Python exige également que les clés du dictionnaire soient uniques :
print({10: "Integer 10", 10.0: "Float 10"})
print({True: "Boolean True", 1: "Integer 1"}){10: 'Float 10'}
{True: 'Integer 1'}Les dictionnaires de ce code contiennent des clés égales. Seule la première clé est conservée. Cependant, sa valeur est remplacée par la dernière valeur ajoutée au dictionnaire associée à une clé égale. Par conséquent, dans le premier exemple, la clé conservée est l'entier 10, mais sa valeur est la chaîne "Float 10". Dans le deuxième exemple, la clé True, qui est égale à 1, est associée à la valeur "Integer 1".
Les ensembles et les dictionnaires jouent un rôle dans plusieurs des solutions présentées dans ce didacticiel en raison de leurs exigences en matière d'éléments ou de clés uniques.
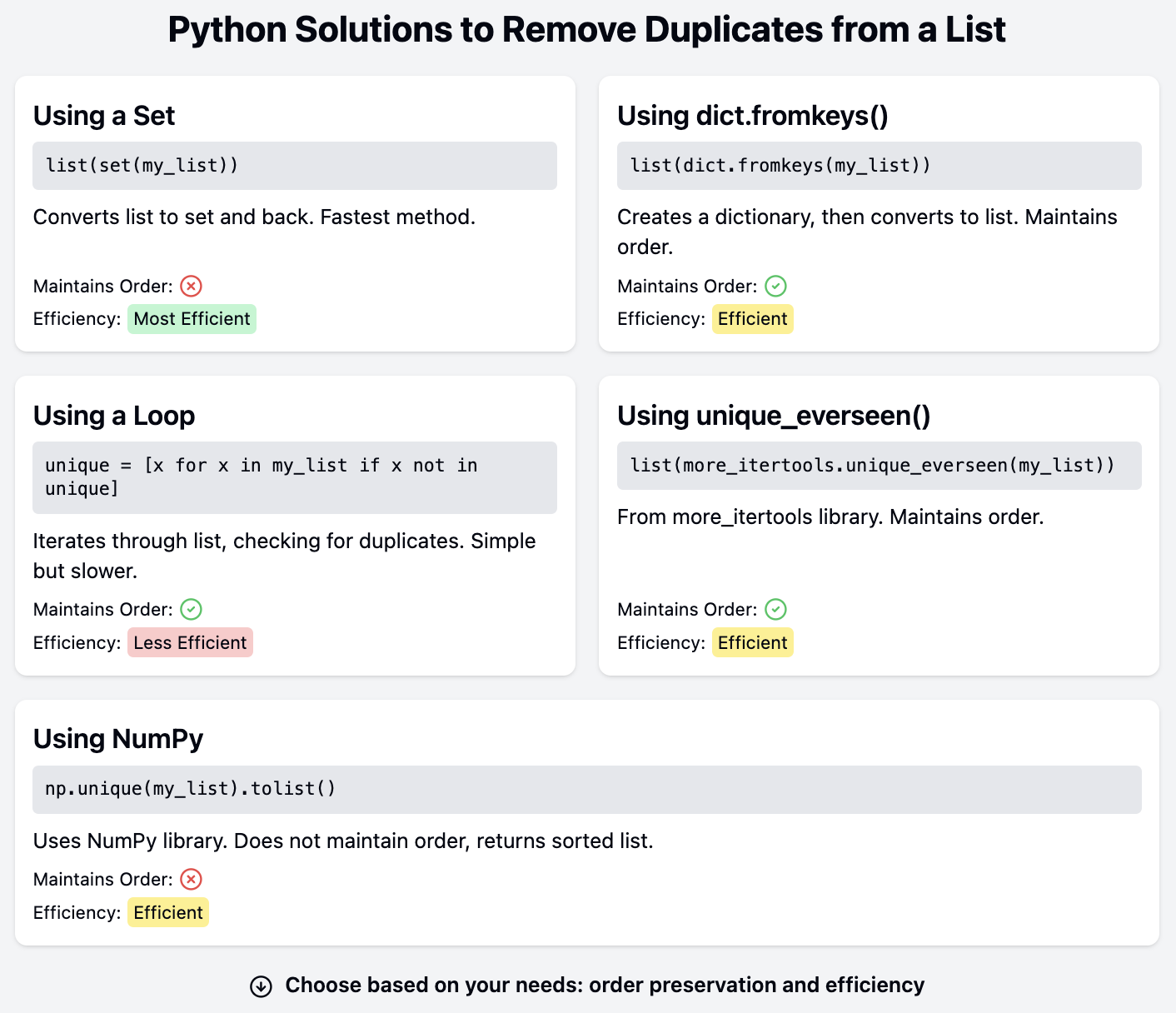
La technique la plus simple pour supprimer les doublons d'une liste consiste à transformer la liste en un ensemble, puis en une liste. Un ensemble ne peut contenir que des valeurs uniques. Par conséquent, les doublons sont éliminés lorsqu'ils sont ajoutés à l'ensemble :
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
print(list(set(names)))['Mark', 'Bob', 'Kate', 'James', 'Sarah']Examinons les étapes nécessaires pour supprimer les doublons d'une liste à l'aide de cette technique :
James et Kate apparaissent deux fois dans la liste initiale, mais seulement une fois dans la liste finale.
Cependant, les ensembles sont des collections non ordonnées. L'ordre des éléments d'un ensemble n'est pas respecté. Notez que les noms de la liste finale ne sont pas dans le même ordre que ceux de la liste originale. Le même code peut produire un ordre différent lorsqu'il est exécuté à nouveau ou lorsqu'on utilise un interpréteur Python différent, car il n'y a aucune garantie quant à l'ordre des éléments d'un ensemble.
Cette solution est idéale lorsqu'il est acceptable de perdre des informations sur l'ordre des éléments de la liste. Cependant, nous avons besoin d'autres solutions si l'ordre des éléments doit être conservé.
Les clés de dictionnaire sont similaires aux ensembles puisqu'elles doivent être uniques. Un dictionnaire peut avoir des valeurs dupliquées mais pas des clés dupliquées.
Avant Python 3.6, les dictionnaires ne conservaient pas l'ordre de leurs éléments. Cependant, suite aux modifications apportées à l'implémentation des dictionnaires dans Python 3.6, les dictionnaires conservent désormais l'ordre dans lequel les éléments sont ajoutés. Il s'agissait d'un simple détail d'implémentation dans Python 3.6, mais il est devenu un élément formel du langage dans Python 3.7.
La fonction dict.fromkeys() crée un dictionnaire à partir d'une table itérative. Les éléments de la table itérative deviennent les clés du nouveau dictionnaire :
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
print(dict.fromkeys(names)){'James': None, 'Bob': None, 'Mark': None, 'Kate': None, 'Sarah': None}Les clés d'un dictionnaire étant uniques, les valeurs en double sont supprimées lors de la création du dictionnaire. Les clés sont garanties d'avoir le même ordre que les éléments de la liste si vous utilisez Python 3.7 ou une version ultérieure. Toutes les clés ont une valeur de None par défaut. Cependant, les valeurs ne sont pas nécessaires puisque ce dictionnaire peut être converti en liste :
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
print(list(dict.fromkeys(names)))['James', 'Bob', 'Mark', 'Kate', 'Sarah']Lorsque vous transformez un dictionnaire en liste, seules les clés sont utilisées. Cette technique convertit la liste d'origine en une nouvelle liste sans doublons et en conservant l'ordre initial des éléments.
Les options présentées dans la première partie de ce tutoriel couvrent les deux scénarios dans lesquels les doublons doivent être supprimés d'une liste :
dict.fromkeys() pour maintenir l'ordre des éléments.Ces deux options sont probablement les meilleures solutions dans la plupart des situations. Il existe cependant d'autres techniques pour supprimer les doublons d'une liste.
Une option simple consiste à parcourir la liste d'origine et à ajouter les nouveaux éléments à une nouvelle liste :
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
unique_names = []
for name in names:
if name not in unique_names:
unique_names.append(name)
print(unique_names)['James', 'Bob', 'Mark', 'Kate', 'Sarah']La nouvelle liste unique_names est initialisée comme une liste vide avant la boucle for. Un élément est ajouté à cette nouvelle liste s'il n'y figure pas déjà. Cette version conserve l'ordre des éléments de la liste originale puisque la boucle for parcourt la liste dans l'ordre.
Cette solution peut s'avérer inefficace pour les grandes listes. Considérez une liste plus longue composée de nombres aléatoires. Nous pouvons comparer les performances de cette solution avec la version utilisant dict.fromkeys():
import random
import timeit
data = [random.randint(0, 100) for _ in range(100)]
use_fromkeys = "unique_data = list(dict.fromkeys(data))"
use_for_loop = """unique_data = []
for item in data:
if item not in unique_data:
unique_data.append(item)"""
from_keys_time = timeit.timeit(use_fromkeys, globals=globals())
for_loop_time = timeit.timeit(use_for_loop, globals=globals())
print(f"Time for 'dict.fromkeys()' version: {from_keys_time:0.2f}s")
print(f"Time for loop version: {for_loop_time:0.2f}s")Time for 'dict.fromkeys()' version: 2.26s
Time for loop version: 17.88sLa fonction timeit() du module du même nom chronomètre l'exécution d'une instruction. Les déclarations sont transmises à timeit.timeit() sous forme de chaînes de caractères. Le résultat montre que la version de la boucle for est nettement plus lente que la version dict.fromkeys(). Les temps d'exécution varient selon les ordinateurs et les configurations, mais l'option dict.fromkeys() sera toujours nettement plus rapide.
La boucle for de la section précédente ne peut pas être convertie en une compréhension de liste puisque l'instruction if vérifie si un élément a déjà été ajouté à la nouvelle liste. Une structure de données distincte est nécessaire pour utiliser une compréhension de liste. Un cursus peut être utilisé pour garder une trace des éléments qui ont déjà été ajoutés à la liste :
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
items = set()
unique_names = [name for name in names if not (name in items or items.add(name))]
print(unique_names)['James', 'Bob', 'Mark', 'Kate', 'Sarah']Ce tutoriel présente cette solution par souci d'exhaustivité, mais cette option manque de lisibilité et n'offre aucune amélioration des performances par rapport à l'utilisation de dict.fromkeys().
Si le nom figure déjà dans l'ensemble items, l'expression entre parenthèses dans la liste de compréhension est évaluée à True. L'expression après le mot-clé or n'est pas évaluée lorsque le premier opérande est True puisque or court-circuite l'évaluation. Comme l'expression entre parenthèses est True, la clause if est False, et le nom n'est pas ajouté à unique_names.
Lorsque le nom n'est pas dans l'ensemble items, l'expression après le mot-clé or est évaluée et le nom est ajouté à l'ensemble. Cependant, la méthode .add() renvoie None, ce qui est une erreur. La clause if devient True, et le nom est également ajouté à la liste unique_names.
Un certain nombre de modules tiers disposent d'outils permettant de supprimer les doublons. La bibliothèque more_itertools comprend unique_everseen(), qui renvoie un itérateur qui renvoie des éléments uniques tout en préservant leur ordre.
La bibliothèque more_itertools peut être installée dans le terminal à l'aide de pip ou d'autres gestionnaires de paquets :
$ pip install more_itertoolsNous pouvons maintenant utiliser more_itertools.unique_everseen() pour supprimer les doublons d'une liste :
import more_itertools
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
unique_names = list(more_itertools.unique_everseen(names))
print(unique_names)['James', 'Bob', 'Mark', 'Kate', 'Sarah']Comme unique_everseen() renvoie un itérateur, sa sortie est transformée en liste.
Une autre bibliothèque tierce populaire est NumPyqui propose également une solution pour supprimer les doublons. NumPy peut être installé à l'aide de pip ou d'autres gestionnaires de paquets :
$ pip install numpyLa fonction unique() de NumPy renvoie un tableau NumPy contenant les éléments uniques de son argument. Ce tableau NumPy peut être converti en liste à l'aide de la fonction NumPy .tolist():
import numpy as np
names = ["James", "Bob", "James", "Mark", "Kate", "Sarah", "Kate"]
unique_names = np.unique(names).tolist()
print(unique_names)['Bob', 'James', 'Kate', 'Mark', 'Sarah']Notez cependant que la fonction unique() de NumPy ne préserve pas l'ordre des éléments. Au lieu de cela, il renvoie des éléments triés. Une autre bibliothèque tierce populaire, Pandasdispose également d'une fonction unique() qui fonctionne de manière similaire, mais qui préserve l'ordre des éléments. Les solutions NumPy et Pandas sont idéales lorsque ces bibliothèques sont déjà utilisées dans la base de code et n'ont pas besoin d'être installées et importées simplement pour supprimer les doublons d'une liste.
dict.fromkeys() Mieux que l'utilisation d'un coffret ?Dans la plupart des cas, les meilleures options sont les deux premières présentées dans ce tutoriel :
dict.fromkeys() et retransformez-le en liste.L'utilisation d'un dictionnaire permet de conserver l'ordre des éléments. Toutefois, l'utilisation d'un ensemble est plus efficace et peut améliorer les performances si l'ordre des éléments n'est pas nécessaire.
L'amélioration des performances peut être quantifiée à l'aide de timeit:
import random
import timeit
data = [random.randint(0, 100) for _ in range(100)]
use_fromkeys = "unique_data = list(dict.fromkeys(data))"
use_set = "unique_data = list(set(data))"
from_keys_time = timeit.timeit(use_fromkeys, globals=globals())
set_time = timeit.timeit(use_set, globals=globals())
print(f"Time for 'dict.fromkeys()' version: {from_keys_time:0.2f}s")
print(f"Time for set version: {set_time:0.2f}s")Time for 'dict.fromkeys()' version: 2.08s
Time for set version: 1.05sL'élimination des doublons d'une liste à l'aide d'un ensemble est environ deux fois plus rapide qu'à l'aide d'un dictionnaire.
Python et ses bibliothèques tierces proposent plusieurs options pour supprimer les doublons d'une liste.
Vous pouvez continuer à apprendre Python grâce à ces articles de blog :
Apprenez Python avec ces cours !
Cours
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min