Curso
Importación y gestión de datos financieros en R
5 h
20.9K

Ejecuta y edita el código de este tutorial en línea
Ejecutar códigoR es una potente herramienta estadística. Comparado con otros programas como Microsoft Excel, R nos proporciona una carga de datos más rápida, una limpieza de datos automatizada y un análisis estadístico y predictivo en profundidad. Todo se hace utilizando paquetes R de código abierto, y vamos a aprender a utilizarlos para importar varios tipos de conjuntos de datos.
Utilizaremos el área de trabajo de R de DataCamp para ejecutar ejemplos de código. Viene con paquetes preinstalados y el entorno R. No tienes que configurar nada y empezar a codificar en cuestión de segundos. Es un servicio gratuito y viene con una gran selección de conjuntos de datos. También puedes integrar tu servidor SQL para empezar a realizar análisis exploratorios de datos.
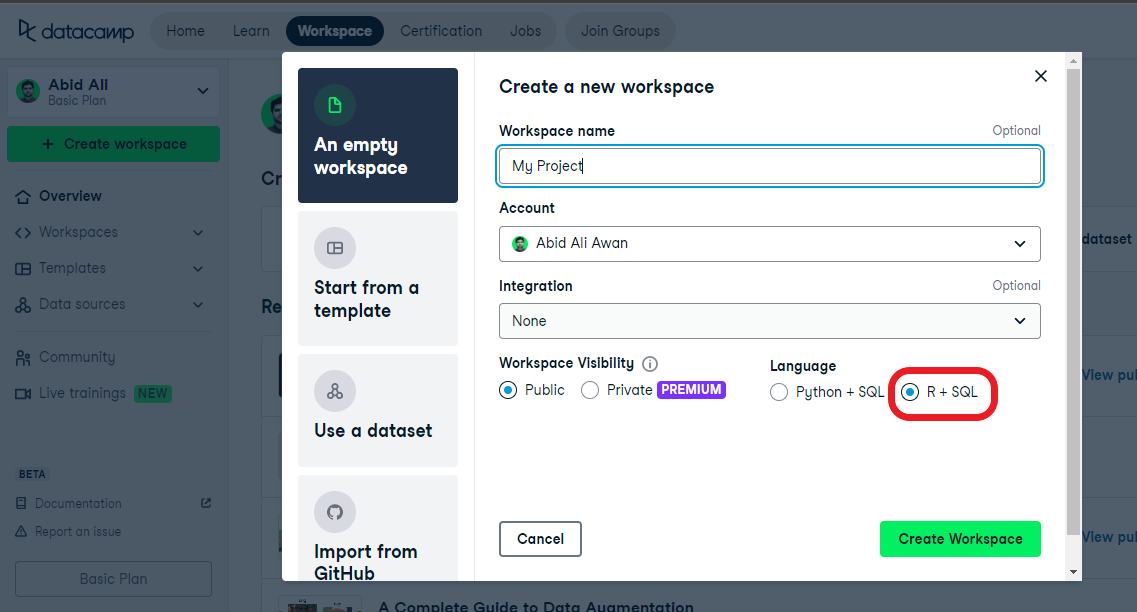
Imagen del autor | Área de trabajo de R
Después de cargar el área de trabajo, tienes que instalar unos cuantos paquetes que no son muy conocidos, pero que sí son necesarios para cargar archivos de SAS, SPSS, Stata y Matlab.
Nota: asegúrate de instalar las dependencias utilizando el parámetro `dependency=T` en la función `install.packages`.
El paquete Tidyverse incluye varios paquetes que te permiten leer archivos planos, limpiar datos, realizar manipulación y visualización de datos, y mucho más.
install.packages(c('quantmod','ff','foreign','R.matlab'),dependency=T)
suppressPackageStartupMessages(library(tidyverse))En este tutorial, aprenderemos a cargar en R archivos de datos CSV, TXT, Excel, JSON, de bases de datos y XML/HTML de uso común. Además, también veremos formatos de archivo de uso menos común, como SAS, SPSS, Stata, Matlab y Binario.
Conoceremos todos los formatos de datos más populares y los cargaremos utilizando varios paquetes de R. Además, utilizaremos URLs para raspar tablas HTML y datos XML del sitio web con pocas líneas de código.
En esta sección, leeremos datos en r cargando un archivo CSV de Demanda de reservas hoteleras. Este conjunto de datos está formado por datos de reservas de un hotel urbano y un hotel turístico. Para importar el archivo CSV, utilizaremos la función `read_csv` del paquete readr. Al igual que en Pandas, requiere que introduzcas la ubicación del archivo para procesarlo y cargarlo como dataframe.
También puedes utilizar las funciones `read.csv` o `read.delim` del paquete utils para cargar archivos CSV.
data1 <- read_csv('data/hotel_bookings_clean.csv',show_col_types = FALSE)
head(data1, 5)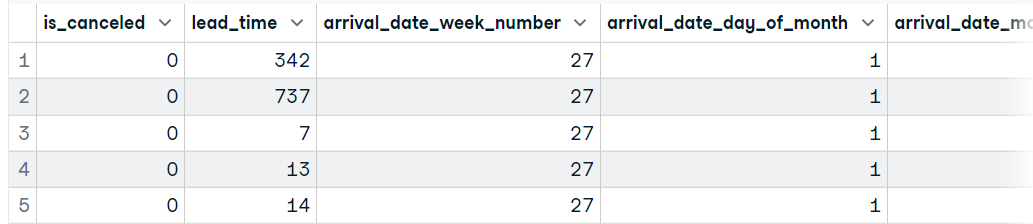
De forma similar a `read_csv`, también puedes utilizar la función read.table para cargar el archivo. Asegúrate de que añades el delimitador "," y que header = 1. Establecerá la primera fila como nombres de columna en lugar de "V1", "V2",...
data2 <- read.table('data/hotel_bookings_clean.csv', sep=",", header = 1)
head(data2, 5)En esta parte, utilizaremos el conjunto de datos Letras de Drake para cargar un archivo de texto. El archivo contiene letras del cantante Drake. Podemos utilizar la función `readLines` para cargar el archivo simple, pero tenemos que realizar tareas adicionales para convertirlo en un marco de datos.

Imagen del autor | Archivo de texto
Utilizaremos la función alternativa de read.table, `read.delim` para cargar el archivo de texto como un marco de datos de R. Otras funciones alternativas de read.table son read.csv, read.csv2 y read.delim2.
Nota: por defecto, está separando los valores en Tabulador (sep = "\t")
El archivo de texto está formado por letras y no tiene una fila de encabezamiento. Para mostrar todas las letras seguidas, tenemos que poner `header = F`.
También puedes utilizar otros parámetros para personalizar tu marco de datos, por ejemplo, el parámetro fill, que establece el campo en blanco que se añadirá a las filas de longitud desigual.
Lee la documentación para conocer cada parámetro de las funciones alternativas de read.table.
data3 <- read.delim('data/drake_lyrics.txt',header = F)
head(data3, 5)
En esta sección, utilizaremos el conjunto de datos Defunciones en Tesla de Kaggle para importarlo de Excel a R. El conjunto de datos trata sobre accidentes trágicos de vehículos Tesla que han provocado la muerte de un conductor, ocupante, ciclista o peatón.
El conjunto de datos contiene un archivo CSV, y utilizaremos MS excel para convertirlo en un archivo Excel, como se muestra a continuación.
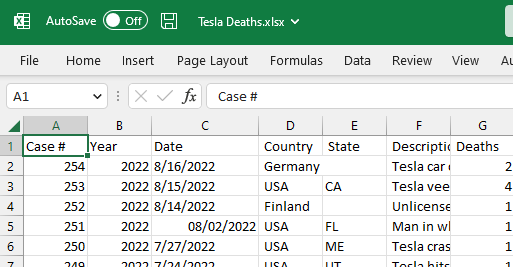
Imagen del autor
Utilizaremos la función `read_excel` del paquete readxl para leer una sola hoja de un archivo Excel. El paquete viene con tiddyvers, pero no es la parte principal, por lo que tenemos que cargar el paquete antes de utilizar la función.
La función requiere la ubicación de los datos y el número de hoja. También podemos modificar el aspecto de nuestro marco de datos leyendo la descripción de otros parámetros en la documentación de read_excel.
library(readxl)
data4 <- read_excel("data/Tesla Deaths.xlsx", sheet = 1)
head(data4, 5)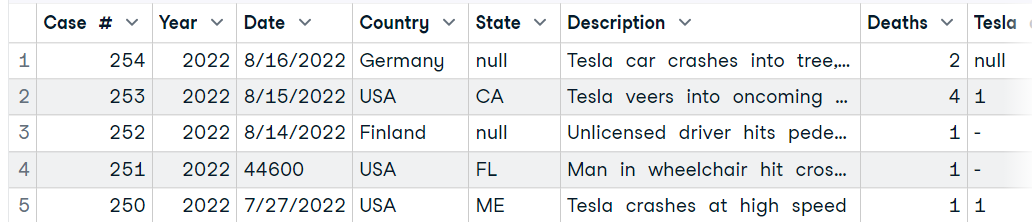
En esta parte, cargaremos JSON en R utilizando un archivo del conjunto de datos Letras de Drake. Contiene letras, título de la canción, título del álbum, URL y número de visitas de las canciones de Drake.

Imagen del autor
Para cargar un archivo JSON, cargaremos el paquete rjson y utilizaremos `fromJSON` para analizar el archivo JSON.
library(rjson)
JsonData <- fromJSON(file = 'data/drake_data.json')
print(JsonData[1])Salida:
[[1]]
[[1]]$album
[1] "Certified Lover Boy"
[[1]]$lyrics_title
[1] "Certified Lover Boy* Lyrics"
[[1]]$lyrics_url
[1] "https://genius.com/Drake-certified-lover-boy-lyrics"
[[1]]$lyrics
[1] "Lyrics from CLB Merch\n\n[Verse]\nPut my feelings on ice\nAlways been a gem\nCertified lover boy, somehow still heartless\nHeart is only gettin' colder"
[[1]]$track_views
[1] "8.7K"Para convertir los datos JSON en un marco de datos R, utilizaremos la función `as.data.frame` del paquete data.table.
data5 = as.data.frame(JsonData[1])
data5
En esta parte, vamos a utilizar el conjunto de datos Salud mental en el sector tecnológico de Kaggle para cargar bases de datos SQLite utilizando R. Para extraer los datos de las bases de datos mediante consultas SQL, utilizaremos el paquete DBI y la función SQLite y crearemos la conexión. También puedes utilizar una sintaxis similar para cargar datos de otros servidores SQL.
Cargaremos el paquete RSQLite y cargaremos la base de datos utilizando la función dbConnect.
Nota: puedes utilizar dbConnect para cargar datos de MySQL, PostgreSQL y otros servidores SQL populares.
Después de cargar la base de datos, mostraremos los nombres de las tablas.
library(RSQLite)
conn <- dbConnect(RSQLite::SQLite(), "data/mental_health.sqlite")
dbListTables(conn)
# 'Answer''Question''Survey'Para ejecutar una consulta y mostrar los resultados, utilizaremos la función `dbGetQuery`. Sólo tienes que añadir un objeto de conexión SQLite y una consulta SQL como cadena.
dbGetQuery(conn, "SELECT * FROM Survey")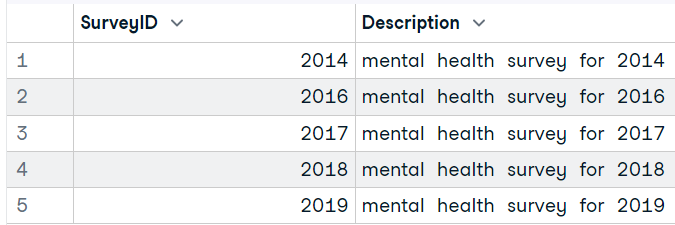
Utilizar SQL dentro de R te proporciona un mayor control de la ingesta y el análisis de datos.
data6 = dbGetQuery(conn, "SELECT * FROM Question LIMIT 3")
data6
Aprende más sobre la ejecución de consultas SQL en R siguiendo el tutorial Cómo ejecutar consultas SQL en Python y R. Te enseñará a cargar bases de datos y a utilizar SQL con dplyr y ggplot.
En esta sección, cargaremos los datos XML de plant_catalog desde w3schools utilizando el paquete xml2.
Nota: también puedes utilizar la función `xmlTreeParse` del paquete XML para cargar los datos.
Al igual que la función `read_csv`, podemos cargar los datos XML proporcionando un enlace URL al sitio XML. Cargará la página y analizará los datos XML.
library(xml2)
plant_xml <- read_xml('https://www.w3schools.com/xml/plant_catalog.xml')
plant_xml_parse <- xmlParse(plant_xml)Después, puedes convertir los datos XML en un marco de datos R utilizando la función `xmlToDataFrame`.
1. Extraer conjunto de nodos de datos XML.
2. Añade el `nodo_planta` a la función `xmlToDataFrame` y muestra las cinco primeras filas del marco de datos de R.
plant_nodes= getNodeSet(plant_xml_parse, "//PLANT")
data9 <- xmlToDataFrame(nodes=plant_nodes)
head(data9,5)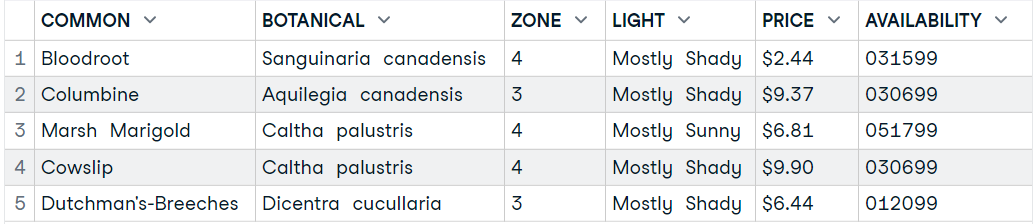
Esta sección es divertida, ya que vamos a scrapear la página de Wikipedia de la selección argentina de fútbol para extraer la tabla HTML y convertirla en un marco de datos con unas pocas líneas de código.
Imagen de Wikipedia
Para cargar una tabla HTML, utilizaremos los paquetes XML y RCurl. Proporcionaremos la URL de Wikipedia a la función `getURL` y luego añadiremos el objeto a la función `readHTMLTable`, como se muestra a continuación.
La función extraerá todas las tablas HTML del sitio web, y sólo tendremos que explorarlas individualmente para seleccionar la que queramos.
library(XML)
library(RCurl)
url <- getURL("https://en.wikipedia.org/wiki/Brazil_national_football_team")
tables <- readHTMLTable(url)
data7 <- tables[31]
data7$`NULL`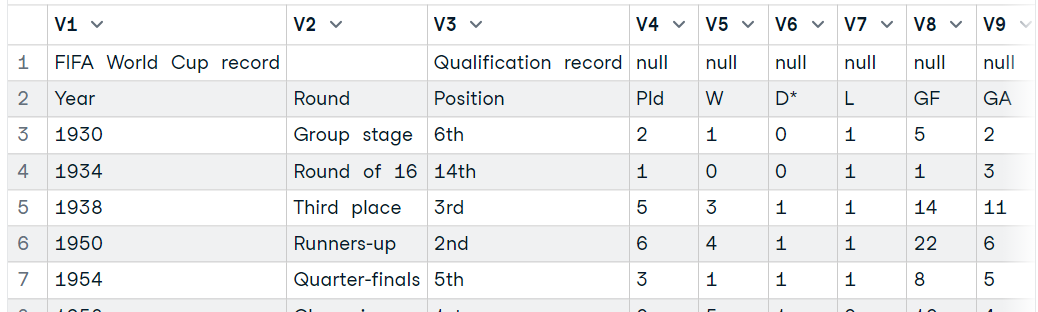
Además, puedes utilizar el paquete rvest para leer HTML mediante URL, extraer todas las tablas y mostrarlo como un marco de datos.
library(rvest)
url <- "https://en.wikipedia.org/wiki/Argentina_national_football_team"
file<-read_html(url)
tables<-html_nodes(file, "table")
data8 <- html_table(tables[25])
View(data8)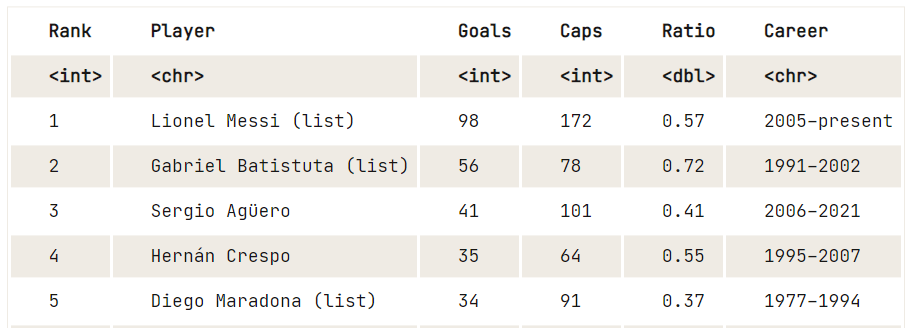
Si tienes problemas al seguir el tutorial, siempre puedes consultar Importar datos al área de trabajo de R. El área de trabajo tiene fuente de código, salida y conjunto de datos. Sólo tienes que duplicar el cuaderno y empezar a practicar.
Los otros tipos de datos menos populares pero esenciales son los del software estadístico, Matlab y los datos binarios.
En esta sección, utilizaremos el paquete haven para importar archivos SAS. Puedes descargar los datos del blog GeeksforGeeks. El paquete haven te permite cargar archivos SAS, SPSS y Stata en R con un código mínimo.
Proporciona el directorio del archivo a la función `read_sas` para cargar el archivo `.sas7bdat` como un marco de datos. Lee la documentación de la función para saber más sobre ella.
library(haven)
data10 <- read_sas('data/lond_small.sas7bdat')
# display data
head(data10,5)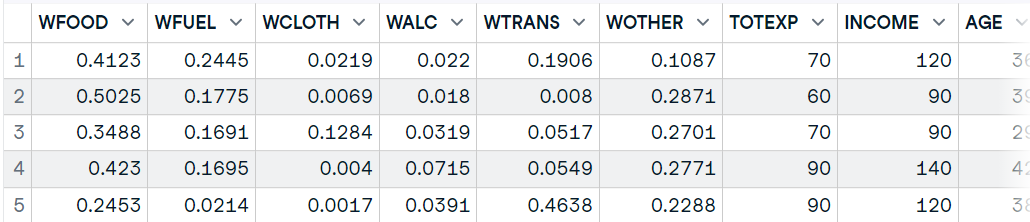
Como ya sabemos, también podemos utilizar el paquete haven para cargar archivos SPSS en R. Puedes descargar los datos del blog GeeksforGeeks y utilizar la función `read_sav` sólo para cargar el archivo sav de SPSS.
Requiere el directorio del archivo como cadena y puedes modificar tu marco de datos utilizando argumentos adicionales como codificación, col_select y comprimir.
library(haven)
data11 <- read_sav("data/airline_passengers.sav")
head(data11,5)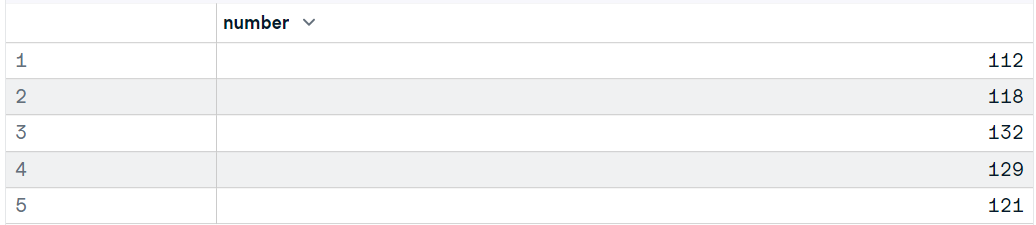
También puedes utilizar un paquete foreign para cargar un archivo `.sav` como un marco de datos utilizando la función `read.spss`. La función sólo necesita dos argumentos file y to.data.frame. Obtén más información sobre otros argumentos leyendo la documentación de la función.
Nota: el paquete externo también te permite cargar formatos de archivo Minitab, S, SAS, SPSS, Stata, Systat, Weka y Octave.
library("foreign")
data12 <- read.spss("data/airline_passengers.sav", to.data.frame = TRUE)
head(data12,5)
En esta parte, utilizaremos el paquete externo para cargar el archivo Stata de ucla.edu.
El programa read.dta lee un archivo en formato binario de la versión 5-12 de Stata y lo convierte en un marco de datos.
"Es así de sencillo".
library("foreign")
data13 <- read.dta("data/friendly.dta")
head(data13,5)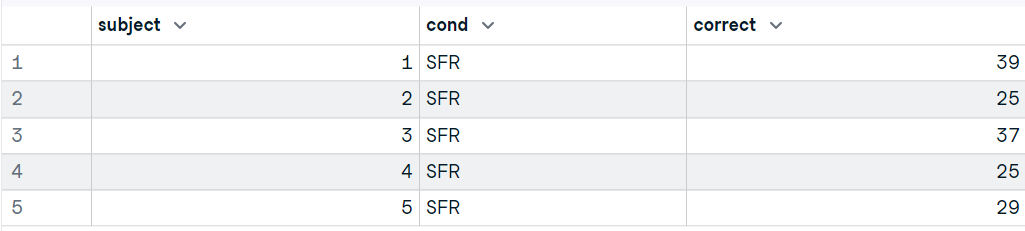
Matlab es bastante famoso entre estudiantes e investigadores. R.matlab nos permite cargar el archivo `.mat`, para que podamos realizar análisis de datos y ejecutar simulaciones en R.
Descarga los archivos Matlab de Kaggle para intentarlo por tu cuenta.
library(R.matlab)
data14 <- readMat("data/cross_dsads.mat")
head(data14$data.dsads)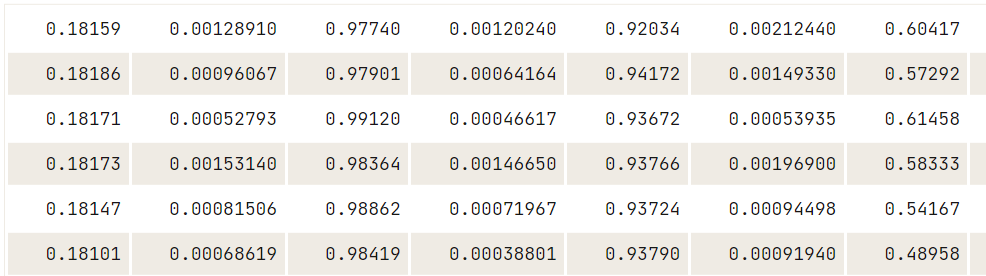
En esta parte, primero crearemos un archivo binario y luego lo leeremos utilizando la función `readBin`.
Nota: el ejemplo de código es una versión modificada del blog Trabajar con archivos binarios en programación R.
En primer lugar, tenemos que crear un marco de datos con cuatro columnas y cuatro filas.
df = data.frame(
"ID" = c(1, 2, 3, 4),
"Name" = c("Abid", "Matt", "Sara", "Dean"),
"Age" = c(34, 25, 27, 50),
"Pin" = c(234512, 765345, 345678, 098567)
)Después, crea un objeto de conexión utilizando una función `file`.
con = file("data/binary_data.dat", "wb")Escribe los nombres de las columnas en el archivo utilizando la función `writeBin`.
writeBin(colnames(df), con)Escribe el valor de cada columna en el archivo.
writeBin(c(df$ID, df$Name, df$Age, df$Pin), con)Cierra la conexión después de escribir los datos en el archivo.
close(con)Para leer el archivo binario, tenemos que crear una conexión con el archivo y utilizar la función `readBin` para mostrar los datos como un número entero.
Argumentos utilizados en la función:
con = file("data/binary_data.dat", "rb")
data15_1 = readBin(con, integer(), n = 25)
print(data15_1)Resultado:
[1] 1308640329 6647137 6645569 7235920 3276849 3407923
[7] 1684628033 1952533760 1632829556 1140875634 7233893 838874163
[13] 926023733 3159296 892613426 922759729 875771190 875757621
[19] 943142453 892877056También puedes convertir los datos de binario a cadena sustituyendo "integer()" por "character()" en el argumento `what`.
Lee la documentación de la función readBin para obtener más información.
con = file("data/binary_data.dat", "rb")
data15_2 = readBin(con, character(), n = 25)
print(data15_2)Resultado:
[1] "ID" "Name" "Age" "Pin" "1" "2" "3" "4"
[9] "Abid" "Matt" "Sara" "Dean" "34" "25" "27" "50"
[17] "234512" "765345" "345678" "98567" Aprende a importar archivos planos, software estadístico, bases de datos o datos directamente desde la web realizando el curso Intermedio de Importación de Datos en R.
El quantmod es un marco de modelización y negociación financiera para R. Lo utilizaremos para descargar y cargar los últimos datos de negociación en forma de marco de datos.
Utilizaremos la función `getSymbols` de quantmod para cargar los datos históricos de las acciones de Google proporcionando la fecha "from" y "to", y "frequency". Obtén más información sobre el paquete quantmod leyendo la documentación.
library(quantmod)
getSymbols("GOOGL",
from = "2022/12/1",
to = "2023/1/15",
periodicity = "daily")
# 'GOOGL'Los datos se cargan en un objeto `GOOGL`, y podemos ver las cinco primeras filas utilizando la función `head()`.
head(GOOGL,5)Resultado:
GOOGL.Open GOOGL.High GOOGL.Low GOOGL.Close GOOGL.Volume
2022-12-01 101.02 102.25 100.25 100.99 28687100
2022-12-02 99.05 100.77 98.90 100.44 21480700
2022-12-05 99.40 101.38 99.00 99.48 24405100
2022-12-06 99.30 99.78 96.42 96.98 24910700
2022-12-07 96.41 96.88 94.72 94.94 31045400
GOOGL.Adjusted
2022-12-01 100.99
2022-12-02 100.44
2022-12-05 99.48
2022-12-06 96.98
2022-12-07 94.94Importar un archivo grande es complicado. Debes asegurarte de que la función está optimizada para un almacenamiento eficiente en memoria y un acceso rápido.
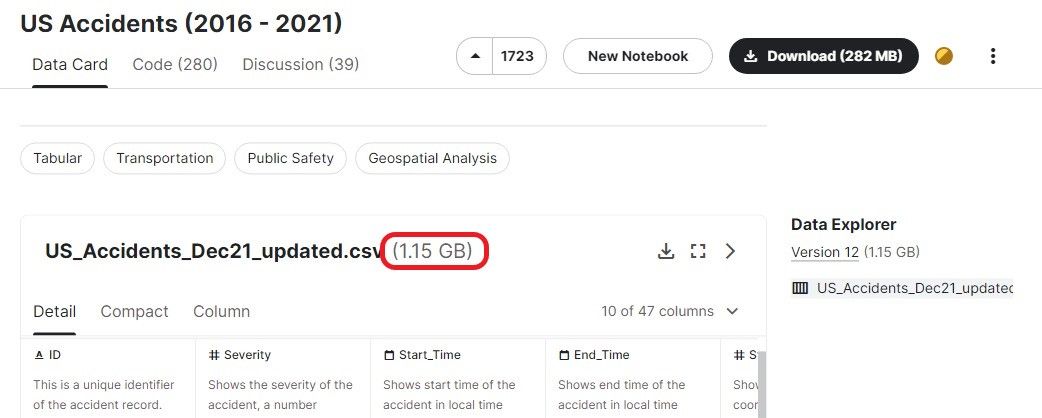
En esta sección, veremos las funciones más utilizadas para cargar archivos CSV de más de 1 GB. Estamos utilizando el conjunto de datos Accidentes en EE.UU. (2016 - 2021) de Kaggle, que tiene un tamaño aproximado de 1,15 GB y 2 845 342 registros.
Podemos cargar el archivo zip directamente en la función read.table de utilsutilizando la función `unz`. Te ahorrará tiempo al extraer y luego cargar el archivo CSV.
file <- unz("data/US Accidents.zip", "US_Accidents_Dec21_updated.csv")
data16 <- read.table(file, header=T, sep=",",nrow=10000)
data16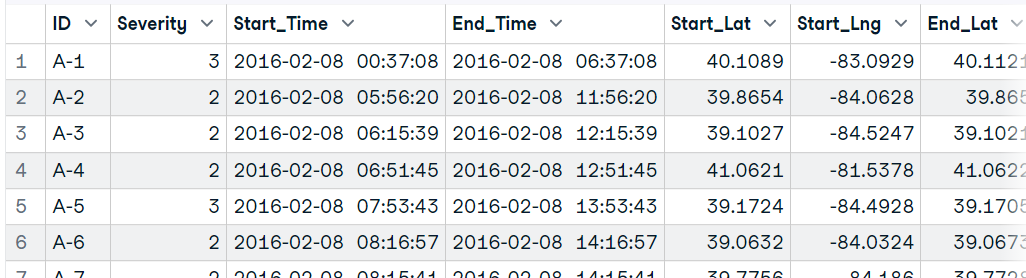
De forma similar a `read.table`, podemos utilizar la función `read_csv` de readr para cargar el archivo CSV. En lugar de nrow, utilizaremos n_max para leer un número limitado de registros.
En nuestro caso, no restringimos ningún dato y permitimos que la función cargue los datos completos.
Nota: se ha tardado casi un minuto en cargar los datos completos. Puedes cambiar el número de hilos para reducir el tiempo de carga. Obtén más información leyendo la documentación de la función.
data17 <- read_csv('data/US_Accidents_Dec21_updated.csv')
data17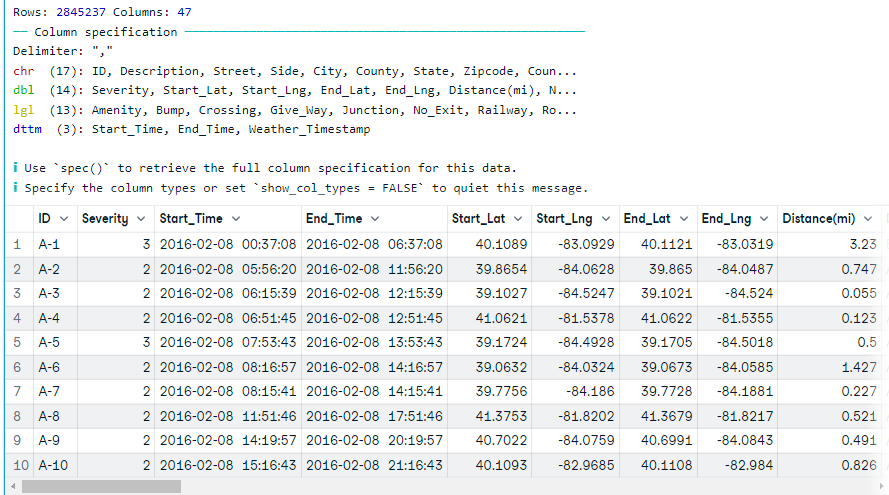
También podemos utilizar el paquete ff para optimizar el tiempo de carga y almacenamiento. La función read.table.ffdf carga los datos en trozos reduciendo el tiempo de carga.
Primero descomprimiremos el archivo y leeremos los datos utilizando la función `read.table.ffdf`.
unzip('data/US Accidents.zip',exdir='data')
library(ff)
data18 <- read.table.ffdf(file="data/US_Accidents_Dec21_updated.csv",
nrows=10000,
header = TRUE,
sep = ',')
data18[1:5,1:25]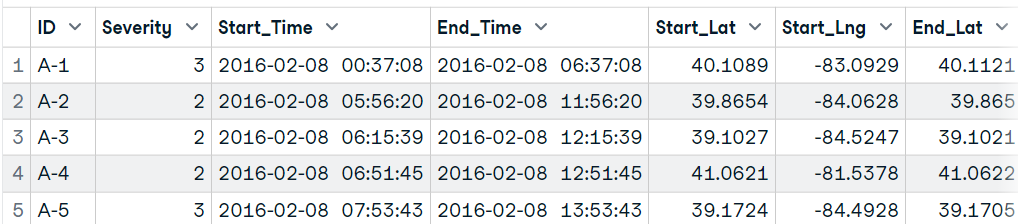
Al final, veremos la función más utilizada `fread` del paquete data.table para leer las 10 000 primeras filas. La función puede entender automáticamente el formato del archivo, pero en casos raros, tienes que proporcionar un argumento sep.
library(data.table)
data19 <- fread("data/US_Accidents_Dec21_updated.csv",
sep=',',
nrows = 10000,
na.strings = c("NA","N/A",""),
stringsAsFactors=FALSE
)
data19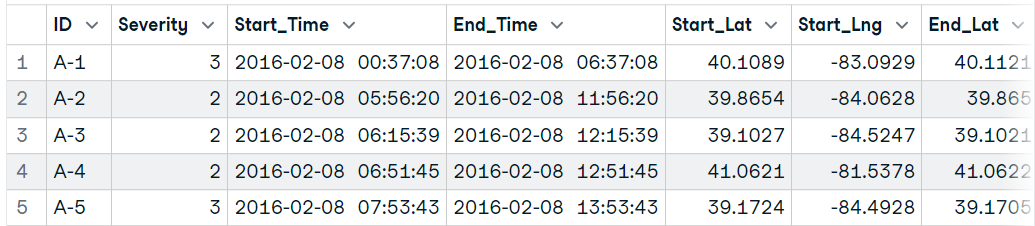
Si quieres probar los ejemplos de código por tu cuenta, aquí tienes la lista de todos los conjuntos de datos utilizados en el tutorial.
R es un lenguaje increíble, y viene con todo tipo de integraciones. Puedes cargar cualquier tipo de conjunto de datos, limpiarlo y manipularlo, realizar análisis de datos exploratorios y predictivos, y publicar informes de alta calidad.
En este tutorial, hemos aprendido a cargar todo tipo de conjuntos de datos utilizando los populares paquetes de R para mejorar el almacenamiento y el rendimiento. Si quieres empezar tu carrera de ciencia de datos con R, consulta el programa de la carrera de científico de datos con R . Consta de 24 cursos interactivos que te enseñarán todo sobre programación en R, análisis estadístico, gestión de datos y análisis predictivo. Además, puedes presentarte a un examen de certificación tras completar el programa para acceder al mercado laboral.
Consulta también Importar datos al área de trabajo de R, que incluye el código fuente, los resultados y un repositorio de datos. Puedes duplicar el área de trabajo y empezar a aprender por tu cuenta.
Imagen del Autor | Importar datos al área de trabajo de R
Más información sobre R
Curso
Curso
Curso
Tutorial
Vidhi Chugh
Tutorial
Francisco Javier Carrera Arias
Tutorial
DataCamp Team
Tutorial
Abid Ali Awan
Tutorial
Eladio Montero Porras
Tutorial
Elena Kosourova