Curso
Introducción a Python
4 h
6.9M
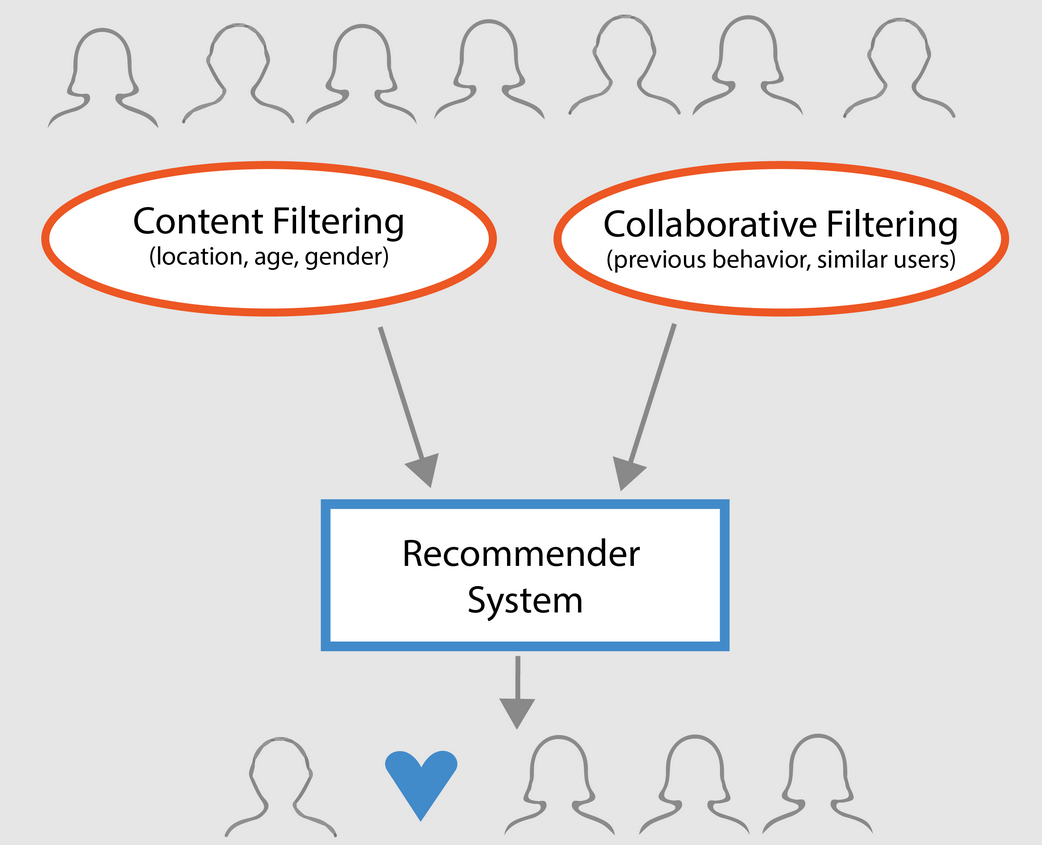
El objetivo de este tutorial no es convertirte en un experto en la construcción de modelos de sistemas de recomendación. En lugar de eso, el motivo es ponerte en marcha dándote una visión general del tipo de sistemas de recomendación que existen y cómo puedes construir uno tú mismo.
En este tutorial, aprenderás a construir un modelo básico de sistemas de recomendación simples y basados en el contenido. Aunque estos modelos no se acercarán ni de lejos a la norma del sector en cuanto a complejidad, calidad o precisión, te ayudarán a iniciarte en la construcción de modelos más complejos que produzcan resultados aún mejores.
Los sistemas de recomendación se encuentran entre las aplicaciones más populares de la ciencia de datos en la actualidad. Se utilizan para predecir la "valoración" o "preferencia" que un usuario daría a un artículo. Casi todas las grandes empresas tecnológicas las han aplicado de alguna forma. Amazon lo utiliza para sugerir productos a los clientes, YouTube lo utiliza para decidir qué vídeo reproducir a continuación en reproducción automática, y Facebook lo utiliza para recomendar páginas a las que dar "me gusta" y personas a las que seguir.
Es más, para algunas empresas como Netflix, Amazon Prime, Hulu y Hotstar, el modelo de negocio y su éxito giran en torno a la potencia de sus recomendaciones. Netflix incluso ofreció un millón de dólares en 2009 a quien pudiera mejorar su sistema en un 10%.
También hay sistemas de recomendación populares para dominios como restaurantes, películas y citas online. También se han desarrollado sistemas de recomendación para explorar artículos de investigación y expertos, colaboradores y servicios financieros. YouTube utiliza el sistema de recomendación a gran escala para sugerirte vídeos basándose en tu historial. Por ejemplo, si ves muchos vídeos educativos, te sugerirá ese tipo de vídeos.
Pero, ¿qué son estos sistemas de recomendación?
A grandes rasgos, los sistemas de recomendación pueden clasificarse en 3 tipos:
Como se ha descrito en el apartado anterior, los recomendadores simples son sistemas básicos que recomiendan los mejores elementos en función de una determinada métrica o puntuación. En esta sección, construirás un clon simplificado de las 250 mejores películas de IMDB utilizando metadatos recopilados de IMDB.
A continuación se indican los pasos a seguir:
Decide la métrica o puntuación para valorar las películas.
Calcula la puntuación de cada película.
Ordena las películas en función de la puntuación y obtén los mejores resultados.
Los archivos del conjunto de datos contienen metadatos de las 45.000 películas que figuran en Full MovieLens Dataset. El conjunto de datos está formado por películas estrenadas en julio de 2017 o antes. Este conjunto de datos recoge características como el reparto, el equipo, las palabras clave del argumento, el presupuesto, los ingresos, los carteles, las fechas de estreno, los idiomas, las productoras, los países, los recuentos de votos de TMDB y las medias de votos.
Estos puntos de características podrían utilizarse potencialmente para entrenar tus modelos de aprendizaje automático para el filtrado de contenidos y colaborativo.
Este conjunto de datos consta de los siguientes archivos:
El conjunto de datos completo de MovieLens consta de 26 millones de valoraciones y 750.000 aplicaciones de etiquetas, de 270.000 usuarios sobre las 45.000 películas de este conjunto de datos. Se puede acceder a ella desde el sitio web oficial de GroupLens.
Nota: El subconjunto de datos utilizado en el tutorial de hoy puede descargarse desde aquí.
Para cargar tu conjunto de datos, utilizarás la biblioteca pandas DataFrame. La biblioteca pandas se utiliza principalmente para la manipulación y el análisis de datos. Representa tus datos en un formato fila-columna. La biblioteca Pandas está respaldada por la matriz NumPy para la implementación de objetos de datos pandas. pandas ofrece estructuras de datos y operaciones listas para usar para manipular tablas numéricas, series temporales, imágenes y conjuntos de datos de procesamiento del lenguaje natural. Básicamente, pandas es útil para aquellos conjuntos de datos que pueden representarse fácilmente de forma tabular.
Antes de realizar ninguno de los pasos anteriores, vamos a cargar tu conjunto de datos de metadatos de películas en un DataFrame pandas:
# Import Pandas
import pandas as pd
# Load Movies Metadata
metadata = pd.read_csv('movies_metadata.csv', low_memory=False)
# Print the first three rows
metadata.head(3)
| adulto | belongs_to_collection | presupuesto | géneros | página de inicio | id | imdb_id | original_language | original_title | visión general | ... | release_date | ingresos | tiempo de ejecución | spoken_languages | estado | eslogan | título | video | vote_average | vote_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Falso | {'id': 10194, 'nombre': Colección Toy Story", ... | 30000000 | [{'id': 16, 'nombre': Animación'}, {'id': 35, '... | http://toystory.disney.com/toy-story | 862 | tt0114709 | en | Toy Story | Liderados por Woody, los juguetes de Andy viven felices en su ... | ... | 1995-10-30 | 373554033.0 | 81.0 | [{'iso_639_1': 'es', 'name': 'Español'}] | Publicado en | NaN | Toy Story | Falso | 7.7 | 5415.0 |
| 1 | Falso | NaN | 65000000 | [{'id': 12, 'nombre': Aventura' }, {'id': 14, '... | NaN | 8844 | tt0113497 | en | Jumanji | Cuando los hermanos Judy y Peter descubren un encha... | ... | 1995-12-15 | 262797249.0 | 104.0 | [{'iso_639_1': 'es', 'name': Inglés'}, {'iso... | Publicado en | ¡Tira los dados y desata la emoción! | Jumanji | Falso | 6.9 | 2413.0 |
| 2 | Falso | {'id': 119050, 'nombre': Colección "Grumpy Old Men"... | 0 | [{'id': 10749, 'nombre': Romance'}, {'id': 35, ... | NaN | 15602 | tt0113228 | en | Viejos gruñones | Una boda familiar reaviva la antigua enemistad entre... | ... | 1995-12-22 | 0.0 | 101.0 | [{'iso_639_1': 'es', 'name': 'Español'}] | Publicado en | Sigue gritando. Sigue luchando. Aún listo para... | Viejos gruñones | Falso | 6.5 | 92.0 |
3 filas × 24 columnas
Una de las métricas más básicas en las que puedes pensar es la clasificación para decidir cuáles son las 250 mejores películas en función de sus respectivas puntuaciones.
Sin embargo, utilizar una clasificación como métrica tiene algunas advertencias:
Por un lado, no tiene en cuenta la popularidad de una película. Por lo tanto, una película con una puntuación de 9 de 10 votantes se considerará "mejor" que una película con una puntuación de 8,9 de 10.000 votantes.
Por ejemplo, imagina que quieres pedir comida china, tienes un par de opciones, un restaurante tiene una valoración de 5 estrellas por sólo 5 personas mientras que el otro restaurante tiene 4,5 valoraciones por 1000 personas. ¿Qué restaurante prefieres? El segundo, ¿verdad?
Por supuesto, podría darse la excepción de que el primer restaurante abriera hace sólo unos días; de ahí que le votara menos gente, mientras que, por el contrario, el segundo restaurante lleva funcionando un año.
Teniendo en cuenta estas deficiencias, debes elaborar una valoración ponderada que tenga en cuenta la valoración media y el número de votos que ha acumulado. Un sistema así se asegurará de que una película con una puntuación de 9 de 100.000 votantes obtenga una puntuación (muy) superior a la de una película con la misma puntuación pero con sólo unos cientos de votantes.
Puesto que estás intentando construir un clon del Top 250 de IMDB, utilicemos su fórmula de puntuación ponderada como métrica/puntuación. Matemáticamente, se representa del siguiente modo:
\Comienzo \Calificación ponderada del texto (WR) = izquierda (sobre {\bf v} + {\bf m} derecha) + izquierda (sobre {\bf m} + {\bf m} derecha) fin{ecuación}
En la ecuación anterior,
v es el número de votos de la película;
m es el mínimo de votos necesarios para figurar en la tabla;
R es la calificación media de la película;
C es el voto medio de todo el informe.
Ya tienes los valores a v (vote_count) y R (vote_average) para cada película del conjunto de datos. También es posible calcular directamente C a partir de estos datos.
Determinar un valor adecuado para m es un hiperparámetro que puedes elegir en consecuencia, ya que no existe un valor correcto para m. Puedes considerarlo como un filtro negativo preliminar que simplemente eliminará las películas que tengan un número de votos inferior a un determinado umbral m. La selectividad de tu filtro depende de tu criterio.
En este tutorial, utilizarás el corte m como percentil 90. En otras palabras, para que una película aparezca en las listas, debe tener más votos que al menos el 90% de las películas de la lista. (Por otra parte, si hubieras elegido el percentil 75, habrías considerado el 25% de las mejores películas en cuanto al número de votos obtenidos. A medida que disminuya el percentil, aumentará el número de películas consideradas).
Como primer paso, calculemos el valor de C, la puntuación media de todas las películas utilizando la función pandas .mean():
# Calculate mean of vote average column
C = metadata['vote_average'].mean()
print(C)
5.618207215133889
Del resultado anterior, puedes observar que la valoración media de una película en IMDB es de aproximadamente 5,6 en una escala de 10.
A continuación, calculemos el número de votos, m, que recibe una película en el percentil 90. La biblioteca pandas hace que esta tarea sea extremadamente trivial utilizando el método .quantile() de pandas:
# Calculate the minimum number of votes required to be in the chart, m
m = metadata['vote_count'].quantile(0.90)
print(m)
160.0
Como ahora tienes el m, puedes utilizar simplemente una condición mayor que igual a para filtrar las películas cuyo recuento de votos sea mayor que igual a 160:
Puedes utilizar el método .copy() para asegurarte de que el nuevo Marco de Datos q_movies creado es independiente de tu Marco de Datos de metadatos original. En otras palabras, cualquier cambio realizado en el marco de datos q_películas no afectará al marco de datos de metadatos original.
# Filter out all qualified movies into a new DataFrame
q_movies = metadata.copy().loc[metadata['vote_count'] >= m]
q_movies.shape
(4555, 24)
metadata.shape
(45466, 24)
Del resultado anterior se desprende que hay alrededor de un 10% de películas con un recuento de votos superior a 160 y que cumplen los requisitos para estar en esta lista.
El siguiente paso, y el más importante, es calcular la puntuación ponderada de cada película calificada. Para ello, deberás
weighted_rating();m y C, simplemente los pasarás como argumento a la función;vote_count(v) y vote_average(R) del marco de datos q_movies;Definirás una nueva función score, cuyo valor calcularás aplicando esta función a tu DataFrame de películas calificadas:
# Function that computes the weighted rating of each movie
def weighted_rating(x, m=m, C=C):
v = x['vote_count']
R = x['vote_average']
# Calculation based on the IMDB formula
return (v/(v+m) * R) + (m/(m+v) * C)
# Define a new feature 'score' and calculate its value with `weighted_rating()`
q_movies['score'] = q_movies.apply(weighted_rating, axis=1)
Por último, ordenemos el DataFrame en orden descendente según la columna de características score y obtengamos el título, el recuento de votos, la media de votos y la valoración ponderada (puntuación) de las 20 mejores películas.
#Sort movies based on score calculated above
q_movies = q_movies.sort_values('score', ascending=False)
#Print the top 15 movies
q_movies[['title', 'vote_count', 'vote_average', 'score']].head(20)
| título | vote_count | vote_average | puntuación | |
|---|---|---|---|---|
| 314 | La redención de Shawshank | 8358.0 | 8.5 | 8.445869 |
| 834 | El Padrino | 6024.0 | 8.5 | 8.425439 |
| 10309 | Dilwale Dulhania Le Jayenge | 661.0 | 9.1 | 8.421453 |
| 12481 | El Caballero Oscuro | 12269.0 | 8.3 | 8.265477 |
| 2843 | El club de la lucha | 9678.0 | 8.3 | 8.256385 |
| 292 | Pulp Fiction | 8670.0 | 8.3 | 8.251406 |
| 522 | La lista de Schindler | 4436.0 | 8.3 | 8.206639 |
| 23673 | Latigazo cervical | 4376.0 | 8.3 | 8.205404 |
| 5481 | El viaje de Chihiro | 3968.0 | 8.3 | 8.196055 |
| 2211 | La vida es bella | 3643.0 | 8.3 | 8.187171 |
| 1178 | El Padrino: Parte II | 3418.0 | 8.3 | 8.180076 |
| 1152 | Un vuelo sobre el nido del cuco | 3001.0 | 8.3 | 8.164256 |
| 351 | Forrest Gump | 8147.0 | 8.2 | 8.150272 |
| 1154 | El Imperio Contraataca | 5998.0 | 8.2 | 8.132919 |
| 1176 | Psycho | 2405.0 | 8.3 | 8.132715 |
| 18465 | Los Intocables | 5410.0 | 8.2 | 8.125837 |
| 40251 | Tu nombre. | 1030.0 | 8.5 | 8.112532 |
| 289 | León: El profesional | 4293.0 | 8.2 | 8.107234 |
| 3030 | La Milla Verde | 4166.0 | 8.2 | 8.104511 |
| 1170 | GoodFellas | 3211.0 | 8.2 | 8.077459 |
Pues bien, a partir del resultado anterior, puedes ver que el simple recommender ¡ha hecho un gran trabajo!
Puesto que la lista tiene muchas películas en común con la lista de las 250 mejores películas de IMDB: por ejemplo, sus dos películas principales, "Shawshank Redemption" y "El Padrino", son las mismas que las de IMDB y todos sabemos que son, en efecto, películas increíbles, de hecho, todas las 20 mejores películas merecen estar en esa lista, ¿no?
En esta sección del tutorial, aprenderás a construir un sistema que recomiende películas similares a una película concreta. Para conseguirlo, calcularás puntuaciones de similitud por pares cosine para todas las películas basándote en las descripciones de sus argumentos y recomendarás películas en función de ese umbral de puntuación de similitud.
La descripción de la parcela está disponible como la característica overview en tu conjunto de datos metadata. Inspeccionemos los argumentos de algunas películas:
#Print plot overviews of the first 5 movies.
metadata['overview'].head()
0 Led by Woody, Andy's toys live happily in his ...
1 When siblings Judy and Peter discover an encha...
2 A family wedding reignites the ancient feud be...
3 Cheated on, mistreated and stepped on, the wom...
4 Just when George Banks has recovered from his ...
Name: overview, dtype: object
Se trata de un problema de Procesamiento del Lenguaje Natural. Por tanto, necesitas extraer algún tipo de características de los datos de texto anteriores antes de poder calcular la similitud y/o disimilitud entre ellos. En pocas palabras, no es posible calcular la similitud entre dos resúmenes cualesquiera en sus formas brutas. Para ello, tienes que calcular los vectores de palabras de cada resumen o documento, como se llamará a partir de ahora.
Como su nombre indica, los vectores de palabras son una representación vectorizada de las palabras de un documento. Los vectores llevan consigo un significado semántico. Por ejemplo, el hombre y el rey tendrán representaciones vectoriales próximas entre sí, mientras que el hombre y la mujer tendrán representaciones alejadas entre sí.
Calcularás vectores Term Frequency-Inverse Document Frequency (TF-IDF) para cada documento. Esto te dará una matriz en la que cada columna representa una palabra del vocabulario general (todas las palabras que aparecen en al menos un documento), y cada columna representa una película, como antes.
En esencia, la puntuación TF-IDF es la frecuencia de aparición de una palabra en un documento, ponderada a la baja por el número de documentos en los que aparece. Esto se hace para reducir la importancia de las palabras que aparecen con frecuencia en los resúmenes de las tramas y, por tanto, su importancia a la hora de calcular la puntuación final de similitud.
Afortunadamente, scikit-learn te proporciona una clase integrada TfIdfVectorizer que produce la matriz TF-IDF en un par de líneas.
#Import TfIdfVectorizer from scikit-learn
from sklearn.feature_extraction.text import TfidfVectorizer
#Define a TF-IDF Vectorizer Object. Remove all english stop words such as 'the', 'a'
tfidf = TfidfVectorizer(stop_words='english')
#Replace NaN with an empty string
metadata['overview'] = metadata['overview'].fillna('')
#Construct the required TF-IDF matrix by fitting and transforming the data
tfidf_matrix = tfidf.fit_transform(metadata['overview'])
#Output the shape of tfidf_matrix
tfidf_matrix.shape
(45466, 75827)
#Array mapping from feature integer indices to feature name.
tfidf.get_feature_names()[5000:5010]
['avails',
'avaks',
'avalanche',
'avalanches',
'avallone',
'avalon',
'avant',
'avanthika',
'avanti',
'avaracious']
A partir del resultado anterior, observas que 75.827 vocabularios o palabras diferentes de tu conjunto de datos tienen 45.000 películas.
Con esta matriz en la mano, ahora puedes calcular una puntuación de similitud. Hay varias métricas de similitud que puedes utilizar para ello, como las puntuaciones de similitud manhattan, euclídea, de Pearson y del coseno. De nuevo, no hay una respuesta correcta a qué puntuación es la mejor. Diferentes puntuaciones funcionan bien en diferentes escenarios, y a menudo es una buena idea experimentar con diferentes métricas y observar los resultados.
Utilizarás la página cosine similarity para calcular una cantidad numérica que denota la similitud entre dos películas. Utiliza la puntuación de similitud del coseno, ya que es independiente de la magnitud y es relativamente fácil y rápida de calcular (especialmente cuando se utiliza junto con las puntuaciones TF-IDF, que se explicarán más adelante). Matemáticamente, se define como sigue:
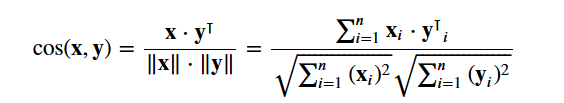
Como has utilizado el vectorizador TF-IDF, el cálculo del producto punto entre cada vector te dará directamente la puntuación de similitud del coseno. Por lo tanto, utilizarás sklearn's linear_kernel() en lugar de cosine_similarities(), ya que es más rápido.
Esto devolvería una matriz de forma 45466x45466, lo que significa que cada película overview puntuación de similitud coseno con cada otra película overview. Por tanto, cada película será un vector de 1x45466 columnas, donde cada columna será una puntuación de similitud con cada película.
# Import linear_kernel
from sklearn.metrics.pairwise import linear_kernel
# Compute the cosine similarity matrix
cosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)
cosine_sim.shape
(45466, 45466)
cosine_sim[1]
array([0.01504121, 1. , 0.04681953, ..., 0. , 0.02198641,
0.00929411])
Vas a definir una función que tome como entrada el título de una película y obtenga como salida una lista de las 10 películas más parecidas. En primer lugar, para ello necesitas un mapeo inverso de títulos de películas e índices DataFrame. En otras palabras, necesitas un mecanismo para identificar el índice de una película en tu metadata DataFrame, dado su título.
#Construct a reverse map of indices and movie titles
indices = pd.Series(metadata.index, index=metadata['title']).drop_duplicates()
indices[:10]
title
Toy Story 0
Jumanji 1
Grumpier Old Men 2
Waiting to Exhale 3
Father of the Bride Part II 4
Heat 5
Sabrina 6
Tom and Huck 7
Sudden Death 8
GoldenEye 9
dtype: int64
Ahora estás en buena forma para definir tu función de recomendación. Estos son los siguientes pasos que deberás seguir:
Obtén el índice de la película dado su título.
Obtén la lista de puntuaciones de similitud del coseno de esa película concreta con todas las películas. Conviértelo en una lista de tuplas donde el primer elemento es su posición, y el segundo es la puntuación de similitud.
Ordena la lista de tuplas mencionada en función de las puntuaciones de similitud; es decir, el segundo elemento.
Consigue los 10 elementos principales de esta lista. Ignora el primer elemento, ya que se refiere a uno mismo (la película más parecida a una película concreta es la propia película).
Devuelve los títulos correspondientes a los índices de los elementos superiores.
# Function that takes in movie title as input and outputs most similar movies
def get_recommendations(title, cosine_sim=cosine_sim):
# Get the index of the movie that matches the title
idx = indices[title]
# Get the pairwsie similarity scores of all movies with that movie
sim_scores = list(enumerate(cosine_sim[idx]))
# Sort the movies based on the similarity scores
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# Get the scores of the 10 most similar movies
sim_scores = sim_scores[1:11]
# Get the movie indices
movie_indices = [i[0] for i in sim_scores]
# Return the top 10 most similar movies
return metadata['title'].iloc[movie_indices]
get_recommendations('The Dark Knight Rises')
12481 The Dark Knight
150 Batman Forever
1328 Batman Returns
15511 Batman: Under the Red Hood
585 Batman
21194 Batman Unmasked: The Psychology of the Dark Kn...
9230 Batman Beyond: Return of the Joker
18035 Batman: Year One
19792 Batman: The Dark Knight Returns, Part 1
3095 Batman: Mask of the Phantasm
Name: title, dtype: object
get_recommendations('The Godfather')
1178 The Godfather: Part II
44030 The Godfather Trilogy: 1972-1990
1914 The Godfather: Part III
23126 Blood Ties
11297 Household Saints
34717 Start Liquidation
10821 Election
38030 A Mother Should Be Loved
17729 Short Sharp Shock
26293 Beck 28 - Familjen
Name: title, dtype: object
Ves que, aunque tu sistema ha hecho un trabajo decente a la hora de encontrar películas con descripciones argumentales similares, la calidad de las recomendaciones no es tan buena. "The Dark Knight Rises" devuelve a todas las películas de Batman, mientras que es más probable que las personas a las que les gustó esa película estén más inclinadas a disfrutar de otras películas de Christopher Nolan. Esto es algo que no puede captar tu sistema actual.
La calidad de tu recomendador aumentaría con el uso de mejores metadatos y captando más detalles. Eso es precisamente lo que vas a hacer en esta sección. Construirás un sistema de recomendación basado en los siguientes metadatos: los 3 actores principales, el director, los géneros relacionados y las palabras clave del argumento de la película.
Los datos de las palabras clave, el reparto y la tripulación no están disponibles en tu conjunto de datos actual, por lo que el primer paso sería cargarlos y fusionarlos en tu DataFrame principal metadata.
# Load keywords and credits
credits = pd.read_csv('credits.csv')
keywords = pd.read_csv('keywords.csv')
# Remove rows with bad IDs.
metadata = metadata.drop([19730, 29503, 35587])
# Convert IDs to int. Required for merging
keywords['id'] = keywords['id'].astype('int')
credits['id'] = credits['id'].astype('int')
metadata['id'] = metadata['id'].astype('int')
# Merge keywords and credits into your main metadata dataframe
metadata = metadata.merge(credits, on='id')
metadata = metadata.merge(keywords, on='id')
# Print the first two movies of your newly merged metadata
metadata.head(2)
| adulto | belongs_to_collection | presupuesto | géneros | página de inicio | id | imdb_id | original_language | original_title | visión general | ... | spoken_languages | estado | eslogan | título | video | vote_average | vote_count | escayola | tripulación | keywords | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Falso | {'id': 10194, 'nombre': Colección Toy Story", ... | 30000000 | [{'id': 16, 'nombre': Animación'}, {'id': 35, '... | http://toystory.disney.com/toy-story | 862 | tt0114709 | en | Toy Story | Liderados por Woody, los juguetes de Andy viven felices en su ... | ... | [{'iso_639_1': 'es', 'name': 'Español'}] | Publicado en | NaN | Toy Story | Falso | 7.7 | 5415.0 | [{'cast_id': 14, 'carácter': 'Woody (voz)',... | [{'credit_id': '52fe4284c3a36847f8024f49', 'de... | [{'id': 931, 'name': 'jealousy'}, {'id': 4290,... |
| 1 | Falso | NaN | 65000000 | [{'id': 12, 'nombre': Aventura' }, {'id': 14, '... | NaN | 8844 | tt0113497 | en | Jumanji | Cuando los hermanos Judy y Peter descubren un encha... | ... | [{'iso_639_1': 'es', 'name': Inglés'}, {'iso... | Publicado en | ¡Tira los dados y desata la emoción! | Jumanji | Falso | 6.9 | 2413.0 | [{'cast_id': 1, 'carácter': Alan Parrish', '... | [{'credit_id': '52fe44bfc3a36847f80a7cd1', 'de... | [{'id': 10090, 'name': 'juego de mesa'}, {'id': 1... |
2 filas × 27 columnas
De tus nuevas características, reparto, equipo y palabras clave, tienes que extraer los tres actores más importantes, el director y las palabras clave asociadas a esa película.
Pero lo primero es lo primero: tus datos están presentes en forma de listas "encadenadas". Tienes que convertirlos de forma que te resulten útiles.
# Parse the stringified features into their corresponding python objects
from ast import literal_eval
features = ['cast', 'crew', 'keywords', 'genres']
for feature in features:
metadata[feature] = metadata[feature].apply(literal_eval)
A continuación, escribe funciones que te ayuden a extraer la información necesaria de cada característica.
En primer lugar, importarás el paquete NumPy para acceder a su constante NaN. A continuación, puedes utilizarla para escribir la función get_director():
# Import Numpy
import numpy as np
Obtén el nombre del director de la función de equipo. Si el director no figura en la lista, devuelve NaN
def get_director(x):
for i in x:
if i['job'] == 'Director':
return i['name']
return np.nan
A continuación, escribirás una función que devuelva los 3 primeros elementos o toda la lista, lo que sea más. Aquí la lista se refiere a los sitios cast, keywords, y genres.
def get_list(x):
if isinstance(x, list):
names = [i['name'] for i in x]
#Check if more than 3 elements exist. If yes, return only first three. If no, return entire list.
if len(names) > 3:
names = names[:3]
return names
#Return empty list in case of missing/malformed data
return []
# Define new director, cast, genres and keywords features that are in a suitable form.
metadata['director'] = metadata['crew'].apply(get_director)
features = ['cast', 'keywords', 'genres']
for feature in features:
metadata[feature] = metadata[feature].apply(get_list)
# Print the new features of the first 3 films
metadata[['title', 'cast', 'director', 'keywords', 'genres']].head(3)
| título | escayola | director | keywords | géneros | |
|---|---|---|---|---|---|
| 0 | Toy Story | [Tom Hanks, Tim Allen, Don Rickles] | John Lasseter | [celos, juguete, chico] | [Animación, Comedia, Familia] |
| 1 | Jumanji | [Robin Williams, Jonathan Hyde, Kirsten Dunst] | Joe Johnston | [juego de mesa, desaparición, basado en la... | [Aventura, Fantasía, Familia] |
| 2 | Viejos gruñones | [Walter Matthau, Jack Lemmon, Ann-Margret] | Howard Deutch | [pesca, mejor amigo, durante los créditos] | [Romance, Comedia] |
El siguiente paso sería convertir los nombres y las instancias de las palabras clave en minúsculas y eliminar todos los espacios entre ellos.
Eliminar los espacios entre palabras es un paso importante del preprocesamiento. Se hace para que tu vectorizador no cuente al Johnny de "Johnny Depp" y al de "Johnny Galecki" como el mismo. Tras este paso de procesamiento, los actores mencionados se representarán como "johnnydepp" y "johnnygalecki" y serán distintos para tu vectorizador.
Otro buen ejemplo en el que el modelo puede dar como resultado la misma representación vectorial es "atasco de pan" y "atasco de tráfico". Por tanto, es mejor eliminar cualquier espacio que haya.
La siguiente función lo hará exactamente por ti:
# Function to convert all strings to lower case and strip names of spaces
def clean_data(x):
if isinstance(x, list):
return [str.lower(i.replace(" ", "")) for i in x]
else:
#Check if director exists. If not, return empty string
if isinstance(x, str):
return str.lower(x.replace(" ", ""))
else:
return ''
# Apply clean_data function to your features.
features = ['cast', 'keywords', 'director', 'genres']
for feature in features:
metadata[feature] = metadata[feature].apply(clean_data)
Ahora estás en condiciones de crear tu "sopa de metadatos", que es una cadena que contiene todos los metadatos que quieres introducir en tu vectorizador (es decir, actores, director y palabras clave).
La función create_soup simplemente unirá todas las columnas necesarias mediante un espacio. Éste es el último paso del preprocesamiento, y la salida de esta función se introducirá en el modelo de vectores de palabras.
def create_soup(x):
return ' '.join(x['keywords']) + ' ' + ' '.join(x['cast']) + ' ' + x['director'] + ' ' + ' '.join(x['genres'])
# Create a new soup feature
metadata['soup'] = metadata.apply(create_soup, axis=1)
metadata[['soup']].head(2)
| sopa | |
|---|---|
| 0 | celos toy boy tomhanks timallen donrickles ... |
| 1 | juego de mesa desaparición basado en un libro infantil ... |
Los siguientes pasos son los mismos que hiciste con tu plot description based recommender. Una diferencia clave es que utilizas CountVectorizer() en lugar de TF-IDF. Esto se debe a que no quieres restar importancia a la presencia del actor/director si ha actuado o dirigido en relativamente más películas. No tiene mucho sentido intuitivo ponderarlos a la baja en este contexto.
La principal diferencia entre CountVectorizer() y TF-IDF es el componente de frecuencia inversa de documentos (FID), que está presente en este último y no en el primero.
# Import CountVectorizer and create the count matrix
from sklearn.feature_extraction.text import CountVectorizer
count = CountVectorizer(stop_words='english')
count_matrix = count.fit_transform(metadata['soup'])
count_matrix.shape
(46628, 73881)
En el resultado anterior, puedes ver que hay 73.881 vocabularios en los metadatos que le has introducido.
A continuación, utilizarás el cosine_similarity para medir la distancia entre las incrustaciones.
# Compute the Cosine Similarity matrix based on the count_matrix
from sklearn.metrics.pairwise import cosine_similarity
cosine_sim2 = cosine_similarity(count_matrix, count_matrix)
# Reset index of your main DataFrame and construct reverse mapping as before
metadata = metadata.reset_index()
indices = pd.Series(metadata.index, index=metadata['title'])
Ahora puedes reutilizar tu función get_recommendations() pasando la nueva matriz cosine_sim2 como segundo argumento.
get_recommendations('The Dark Knight Rises', cosine_sim2)
12589 The Dark Knight
10210 Batman Begins
9311 Shiner
9874 Amongst Friends
7772 Mitchell
516 Romeo Is Bleeding
11463 The Prestige
24090 Quicksand
25038 Deadfall
41063 Sara
Name: title, dtype: object
get_recommendations('The Godfather', cosine_sim2)
1934 The Godfather: Part III
1199 The Godfather: Part II
15609 The Rain People
18940 Last Exit
34488 Rege
35802 Manuscripts Don't Burn
35803 Manuscripts Don't Burn
8001 The Night of the Following Day
18261 The Son of No One
28683 In the Name of the Law
Name: title, dtype: object
¡Estupendo! Ves que tu recomendador ha conseguido captar más información gracias a más metadatos y te ha dado mejores recomendaciones. Por supuesto, hay numerosas formas de experimentar con este sistema para mejorar las recomendaciones.
Algunas sugerencias:
Introduce un filtro de popularidad: este recomendador tomaría las 30 películas más parecidas, calcularía las valoraciones ponderadas (utilizando la fórmula IMDB de arriba), ordenaría las películas en función de esta valoración y devolvería las 10 mejores películas.
Otros miembros del equipo: también podrían incluirse otros nombres de miembros del equipo, como guionistas y productores.
El peso creciente del director: para dar más peso al director, se le puede mencionar varias veces en la sopa para aumentar las puntuaciones de similitud de las películas con el mismo director.
En este tutorial, has aprendido a construir tu propio Sistema de Recomendación de Películas Simple y Basado en el Contenido. También existe otro tipo de recomendador muy popular conocido como filtros colaborativos.
Los filtros colaborativos pueden clasificarse a su vez en dos tipos:
User-based Filteringestos sistemas recomiendan a un usuario productos que han gustado a usuarios similares. Por ejemplo, supongamos que Alicia y Bob tienen un interés similar por los libros (es decir, que en gran medida les gustan y no les gustan los mismos libros). Supongamos que se ha lanzado un nuevo libro al mercado, y Alicia lo ha leído y le ha encantado. Por tanto, es muy probable que a Bob también le guste y, por lo tanto, el sistema recomienda este libro a Bob.Item-based Filtering: estos sistemas son muy parecidos al motor de recomendación de contenidos que tú construiste. Estos sistemas identifican elementos similares basándose en cómo lo han valorado las personas en el pasado. Por ejemplo, si Alicia, Bob y Eva han dado 5 estrellas a El Señor de los Anillos y a El Hobbit, el sistema identifica los artículos como similares. Por tanto, si alguien compra El Señor de los Anillos, el sistema también le recomienda El Hobbit.
No construirás estos sistemas en este tutorial, pero ya estás familiarizado con la mayoría de las ideas necesarias para hacerlo. Un buen punto de partida para empezar con los filtros colaborativos es examinar el conjunto de datos MovieLens, que puedes encontrar aquí.
¡Enhorabuena por terminar este tutorial!
Has superado con éxito nuestro tutorial que te ha enseñado todo sobre los sistemas de recomendación en Python. Aprendiste a construir recomendadores sencillos y basados en el contenido.
Un buen ejercicio para todos vosotros sería implementar el filtrado colaborativo en Python utilizando el subconjunto del conjunto de datos MovieLens que utilizasteis para construir recomendadores simples y basados en el contenido.
Si te estás iniciando en Python y quieres aprender más, sigue el curso Introducción a la Ciencia de Datos en Python de DataCamp.
Cursos de Python
Curso
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Bekhruz Tuychiev