Curso
Introdução ao Python
4 h
6.9M
O objetivo deste tutorial não é fazer com que você se torne um especialista na criação de modelos de sistemas de recomendação. Em vez disso, o objetivo é dar a você uma visão geral dos tipos de sistemas de recomendação que existem e como você pode criar um por conta própria.
Neste tutorial, você aprenderá a criar um modelo básico de sistemas de recomendação simples e baseados em conteúdo. Embora esses modelos não estejam nem perto do padrão do setor em termos de complexidade, qualidade ou precisão, eles ajudarão você a começar a criar modelos mais complexos que produzam resultados ainda melhores.
Os sistemas de recomendação estão entre os aplicativos mais populares da ciência de dados atualmente. Eles são usados para prever a "classificação" ou "preferência" que um usuário daria a um item. Quase todas as grandes empresas de tecnologia as aplicaram de alguma forma. A Amazon o utiliza para sugerir produtos aos clientes, o YouTube o utiliza para decidir qual vídeo será reproduzido em seguida na reprodução automática e o Facebook o utiliza para recomendar páginas para você curtir e pessoas para seguir.
Além disso, para algumas empresas como Netflix, Amazon Prime, Hulu e Hotstar, o modelo de negócios e seu sucesso giram em torno da potência de suas recomendações. A Netflix chegou a oferecer um milhão de dólares em 2009 para quem conseguisse melhorar seu sistema em 10%.
Há também sistemas de recomendação populares para domínios como restaurantes, filmes e encontros on-line. Os sistemas de recomendação também foram desenvolvidos para explorar artigos de pesquisa e especialistas, colaboradores e serviços financeiros. O YouTube usa o sistema de recomendação em grande escala para sugerir a você vídeos com base no seu histórico. Por exemplo, se você assiste a muitos vídeos educacionais, ele sugerirá esses tipos de vídeos.
Mas o que são esses sistemas de recomendação?
Em termos gerais, os sistemas de recomendação podem ser classificados em três tipos:
Conforme descrito na seção anterior, os recomendadores simples são sistemas básicos que recomendam os principais itens com base em uma determinada métrica ou pontuação. Nesta seção, você criará um clone simplificado do IMDB Top 250 Movies usando metadados coletados do IMDB.
A seguir, você verá as etapas envolvidas:
Decida a métrica ou a pontuação que você usará para classificar os filmes.
Calcule a pontuação de cada filme.
Classifique os filmes com base na pontuação e exiba os principais resultados.
Os arquivos do conjunto de dados contêm metadados para todos os 45.000 filmes listados no site Full MovieLens Dataset. O conjunto de dados consiste em filmes lançados em julho de 2017 ou antes. Esse conjunto de dados captura pontos de recursos como elenco, equipe, palavras-chave do enredo, orçamento, receita, pôsteres, datas de lançamento, idiomas, empresas de produção, países, contagens de votos do TMDB e médias de votos.
Esses pontos de recurso podem ser usados para treinar seus modelos de aprendizado de máquina para conteúdo e filtragem colaborativa.
Esse conjunto de dados consiste nos seguintes arquivos:
O conjunto de dados completo do MovieLens inclui 26 milhões de classificações e 750.000 aplicativos de tags, de 270.000 usuários em todos os 45.000 filmes desse conjunto de dados. Ele pode ser acessado no site oficial do GroupLens.
Observação: O conjunto de dados do subconjunto usado no tutorial de hoje pode ser baixado aqui.
Para carregar o conjunto de dados, você usará a biblioteca pandas DataFrame. A biblioteca pandas é usada principalmente para manipulação e análise de dados. Ele representa seus dados em um formato de linha-coluna. A biblioteca Pandas é apoiada pela matriz NumPy para a implementação de objetos de dados pandas. pandas oferece estruturas de dados e operações prontas para manipular tabelas numéricas, séries temporais, imagens e conjuntos de dados de processamento de linguagem natural. Basicamente, o site pandas é útil para os conjuntos de dados que podem ser facilmente representados de forma tabular.
Antes de você executar qualquer uma das etapas acima, vamos carregar o conjunto de dados de metadados dos filmes em um DataFrame pandas:
# Import Pandas
import pandas as pd
# Load Movies Metadata
metadata = pd.read_csv('movies_metadata.csv', low_memory=False)
# Print the first three rows
metadata.head(3)
| adulto | belongs_to_collection | orçamento | genres | página inicial | id | imdb_id | original_language | original_title | visão geral | ... | release_date | receita | tempo de execução | spoken_languages | status | slogan | título | vídeo | vote_average | vote_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Falso | {'id': 10194, 'name': 'Toy Story Collection', ... | 30000000 | [{'id': 16, 'name': 'Animation'}, {'id': 35, '... | http://toystory.disney.com/toy-story | 862 | tt0114709 | e | Toy Story | Liderados por Woody, os brinquedos de Andy vivem felizes em seu ... | ... | 1995-10-30 | 373554033.0 | 81.0 | [{'iso_639_1': 'en', 'name': 'English'}] | Liberado | NaN | Toy Story | Falso | 7.7 | 5415.0 |
| 1 | Falso | NaN | 65000000 | [{'id': 12, 'name': 'Adventure'}, {'id': 14, '... | NaN | 8844 | tt0113497 | e | Jumanji | Quando os irmãos Judy e Peter descobrem uma encha... | ... | 1995-12-15 | 262797249.0 | 104.0 | [{'iso_639_1': 'en', 'name': 'English'}, {'iso... | Liberado | Jogue os dados e libere a emoção! | Jumanji | Falso | 6.9 | 2413.0 |
| 2 | Falso | {'id': 119050, 'name': 'Coleção de velhos rabugentos... | 0 | [{'id': 10749, 'name': 'Romance'}, {'id': 35, ... | NaN | 15602 | tt0113228 | e | Velhos mais rabugentos | Um casamento de família reacende uma antiga rixa entre você e a família... | ... | 1995-12-22 | 0.0 | 101.0 | [{'iso_639_1': 'en', 'name': 'English'}] | Liberado | Você ainda está gritando. Ainda lutando. Você ainda está pronto para... | Velhos mais rabugentos | Falso | 6.5 | 92.0 |
3 linhas × 24 colunas
Uma das métricas mais básicas que você pode imaginar é a classificação para decidir quais são os 250 melhores filmes com base em suas respectivas classificações.
No entanto, o uso de uma classificação como métrica tem algumas ressalvas:
Por um lado, não leva em consideração a popularidade de um filme. Portanto, um filme com uma classificação de 9 de 10 votantes será considerado "melhor" do que um filme com uma classificação de 8,9 de 10.000 votantes.
Por exemplo, imagine que você queira pedir comida chinesa e tenha algumas opções, sendo que um restaurante tem uma classificação de 5 estrelas por apenas 5 pessoas, enquanto o outro restaurante tem 4,5 classificações por 1.000 pessoas. Qual restaurante você prefere? O segundo, certo?
É claro que pode haver uma exceção, pois o primeiro restaurante foi inaugurado há apenas alguns dias e, portanto, menos pessoas votaram nele, enquanto, ao contrário, o segundo restaurante está em funcionamento há um ano.
Levando essas deficiências em consideração, você deve criar uma classificação ponderada que leve em conta a classificação média e o número de votos que ela acumulou. Esse sistema garantirá que um filme com classificação 9 de 100.000 votantes receba uma pontuação (muito) mais alta do que um filme com a mesma classificação, mas com apenas algumas centenas de votantes.
Como você está tentando criar um clone do Top 250 do IMDB, vamos usar sua fórmula de classificação ponderada como métrica/pontuação. Matematicamente, ele é representado da seguinte forma:
\begin{equation} \text Weighted Rating (\bf WR) = \left({{\bf v} \over {\bf v} + {\bf m}} \cdot R\right) + \left({{\bf m} \over {\bf v} + {\bf m}} \cdot C\right) \end{equation}
Na equação acima,
v é o número de votos para o filme;
m é o número mínimo de votos necessários para que você seja listado no gráfico;
R é a classificação média do filme;
C é o voto médio em todo o relatório.
Você já tem os valores para v (vote_count) e R (vote_average) para cada filme no conjunto de dados. Também é possível calcular diretamente C a partir desses dados.
Determinar um valor apropriado para m é um hiperparâmetro que você pode escolher de acordo, pois não existe um valor correto para m. Você pode considerá-lo como um filtro negativo preliminar que simplesmente removerá os filmes que tiverem um número de votos inferior a um determinado limite m. A seletividade do seu filtro fica a seu critério.
Neste tutorial, você usará o ponto de corte m como o 90º percentil. Em outras palavras, para que um filme apareça nas paradas, ele deve ter mais votos do que pelo menos 90% dos filmes da lista. (Por outro lado, se você tivesse escolhido o 75º percentil, teria considerado os 25% melhores filmes em termos do número de votos obtidos. À medida que o percentil diminui, o número de filmes considerados aumenta).
Como primeira etapa, vamos calcular o valor de C, a classificação média de todos os filmes, usando a função pandas .mean():
# Calculate mean of vote average column
C = metadata['vote_average'].mean()
print(C)
5.618207215133889
A partir do resultado acima, você pode observar que a classificação média de um filme no IMDB é de cerca de 5,6 em uma escala de 10.
Em seguida, vamos calcular o número de votos, m, recebidos por um filme no 90º percentil. A biblioteca pandas torna essa tarefa extremamente trivial usando o método .quantile() do pandas:
# Calculate the minimum number of votes required to be in the chart, m
m = metadata['vote_count'].quantile(0.90)
print(m)
160.0
Como agora você tem o m, pode simplesmente usar uma condição maior que igual a para filtrar os filmes com contagem de votos maior que igual a 160:
Você pode usar o método .copy() para garantir que o novo q_movies DataFrame criado seja independente do seu DataFrame de metadados original. Em outras palavras, qualquer alteração feita no DataFrame q_movies não afetará o quadro de dados de metadados original.
# Filter out all qualified movies into a new DataFrame
q_movies = metadata.copy().loc[metadata['vote_count'] >= m]
q_movies.shape
(4555, 24)
metadata.shape
(45466, 24)
Com base no resultado acima, fica claro que há cerca de 10% de filmes com contagem de votos superior a 160 e que se qualificam para fazer parte dessa lista.
A próxima etapa, e a mais importante, é calcular a classificação ponderada de cada filme qualificado. Para fazer isso, você deverá:
weighted_rating();m e C, basta passá-los como argumento para a função;vote_count(v) e vote_average(R) do quadro de dados q_movies;Você definirá um novo recurso score, do qual calculará o valor aplicando essa função ao seu DataFrame de filmes qualificados:
# Function that computes the weighted rating of each movie
def weighted_rating(x, m=m, C=C):
v = x['vote_count']
R = x['vote_average']
# Calculation based on the IMDB formula
return (v/(v+m) * R) + (m/(m+v) * C)
# Define a new feature 'score' and calculate its value with `weighted_rating()`
q_movies['score'] = q_movies.apply(weighted_rating, axis=1)
Por fim, vamos classificar o DataFrame em ordem decrescente com base na coluna score feature e gerar o título, a contagem de votos, a média de votos e a classificação ponderada (pontuação) dos 20 melhores filmes.
#Sort movies based on score calculated above
q_movies = q_movies.sort_values('score', ascending=False)
#Print the top 15 movies
q_movies[['title', 'vote_count', 'vote_average', 'score']].head(20)
| título | vote_count | vote_average | pontuação | |
|---|---|---|---|---|
| 314 | O resgate de Shawshank | 8358.0 | 8.5 | 8.445869 |
| 834 | O Poderoso Chefão | 6024.0 | 8.5 | 8.425439 |
| 10309 | Dilwale Dulhania Le Jayenge | 661.0 | 9.1 | 8.421453 |
| 12481 | O Cavaleiro das Trevas | 12269.0 | 8.3 | 8.265477 |
| 2843 | Clube da Luta | 9678.0 | 8.3 | 8.256385 |
| 292 | Pulp Fiction | 8670.0 | 8.3 | 8.251406 |
| 522 | Lista de Schindler | 4436.0 | 8.3 | 8.206639 |
| 23673 | Whiplash | 4376.0 | 8.3 | 8.205404 |
| 5481 | A Viagem de Chihiro | 3968.0 | 8.3 | 8.196055 |
| 2211 | A vida é bela | 3643.0 | 8.3 | 8.187171 |
| 1178 | O Poderoso Chefão: Parte II | 3418.0 | 8.3 | 8.180076 |
| 1152 | Um voo sobre o ninho de cucos | 3001.0 | 8.3 | 8.164256 |
| 351 | Forrest Gump | 8147.0 | 8.2 | 8.150272 |
| 1154 | O Império Contra-Ataca | 5998.0 | 8.2 | 8.132919 |
| 1176 | Psicótico | 2405.0 | 8.3 | 8.132715 |
| 18465 | Os Intocáveis | 5410.0 | 8.2 | 8.125837 |
| 40251 | Seu nome. | 1030.0 | 8.5 | 8.112532 |
| 289 | Leon: O profissional | 4293.0 | 8.2 | 8.107234 |
| 3030 | A milha verde | 4166.0 | 8.2 | 8.104511 |
| 1170 | GoodFellas | 3211.0 | 8.2 | 8.077459 |
Bem, com base no resultado acima, você pode ver que o simple recommender fez um ótimo trabalho!
Como a tabela tem muitos filmes em comum com a tabela Top 250 do IMDB, por exemplo, os dois principais filmes de vocês, "Shawshank Redemption" e "O Poderoso Chefão", são os mesmos do IMDB, e todos sabemos que são filmes realmente incríveis; na verdade, todos os 20 principais filmes merecem estar nessa lista, não é?
Nesta seção do tutorial, você aprenderá a criar um sistema que recomenda filmes semelhantes a um filme específico. Para isso, você calculará as pontuações de similaridade cosine para todos os filmes com base em suas descrições de enredo e recomendará filmes com base nesse limite de pontuação de similaridade.
A descrição do gráfico está disponível para você como o recurso overview no seu conjunto de dados metadata. Vamos examinar os enredos de alguns filmes:
#Print plot overviews of the first 5 movies.
metadata['overview'].head()
0 Led by Woody, Andy's toys live happily in his ...
1 When siblings Judy and Peter discover an encha...
2 A family wedding reignites the ancient feud be...
3 Cheated on, mistreated and stepped on, the wom...
4 Just when George Banks has recovered from his ...
Name: overview, dtype: object
O problema em questão é um problema de processamento de linguagem natural. Portanto, você precisa extrair algum tipo de recurso dos dados de texto acima antes de calcular a similaridade e/ou a dissimilaridade entre eles. Para simplificar, não é possível calcular a semelhança entre duas visões gerais em suas formas brutas. Para fazer isso, você precisa calcular os vetores de palavras de cada visão geral ou documento, como será chamado daqui em diante.
Como o nome sugere, os vetores de palavras são representações vetorizadas de palavras em um documento. Os vetores carregam consigo um significado semântico. Por exemplo, homem e rei terão representações vetoriais próximas uma da outra, enquanto homem e mulher terão representações distantes uma da outra.
Você calculará os vetores Term Frequency-Inverse Document Frequency (TF-IDF) para cada documento. Isso dará a você uma matriz em que cada coluna representa uma palavra no vocabulário de visão geral (todas as palavras que aparecem em pelo menos um documento) e cada coluna representa um filme, como antes.
Em sua essência, a pontuação TF-IDF é a frequência de uma palavra que ocorre em um documento, ponderada para baixo pelo número de documentos em que ela ocorre. Isso é feito para reduzir a importância das palavras que ocorrem com frequência nas visões gerais do enredo e, portanto, sua importância no cálculo da pontuação final de similaridade.
Felizmente, o scikit-learn oferece a você uma classe TfIdfVectorizer integrada que produz a matriz TF-IDF em algumas linhas.
#Import TfIdfVectorizer from scikit-learn
from sklearn.feature_extraction.text import TfidfVectorizer
#Define a TF-IDF Vectorizer Object. Remove all english stop words such as 'the', 'a'
tfidf = TfidfVectorizer(stop_words='english')
#Replace NaN with an empty string
metadata['overview'] = metadata['overview'].fillna('')
#Construct the required TF-IDF matrix by fitting and transforming the data
tfidf_matrix = tfidf.fit_transform(metadata['overview'])
#Output the shape of tfidf_matrix
tfidf_matrix.shape
(45466, 75827)
#Array mapping from feature integer indices to feature name.
tfidf.get_feature_names()[5000:5010]
['avails',
'avaks',
'avalanche',
'avalanches',
'avallone',
'avalon',
'avant',
'avanthika',
'avanti',
'avaracious']
Na saída acima, você observa que 75.827 vocabulários ou palavras diferentes no seu conjunto de dados têm 45.000 filmes.
Com essa matriz em mãos, você pode calcular uma pontuação de similaridade. Há várias métricas de similaridade que você pode usar para isso, como as pontuações de similaridade manhattan, euclidiana, Pearson e cosseno. Mais uma vez, não há uma resposta certa para saber qual é a melhor pontuação. Pontuações diferentes funcionam bem em cenários diferentes, e geralmente é uma boa ideia experimentar métricas diferentes e observar os resultados.
Você usará o site cosine similarity para calcular uma quantidade numérica que denota a similaridade entre dois filmes. Você usa a pontuação de similaridade de cosseno, pois ela é independente da magnitude e é relativamente fácil e rápida de calcular (especialmente quando usada em conjunto com as pontuações TF-IDF, que serão explicadas posteriormente). Matematicamente, ele é definido da seguinte forma:
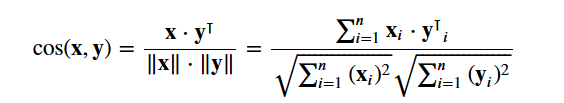
Como você usou o vetorizador TF-IDF, o cálculo do produto escalar entre cada vetor fornecerá diretamente a pontuação de similaridade de cosseno. Portanto, você usará sklearn's linear_kernel() em vez de cosine_similarities(), pois é mais rápido.
Isso retornaria uma matriz de formato 45466x45466, o que significa que cada filme overview tem uma pontuação de similaridade de cosseno com todos os outros filmes overview. Assim, cada filme será um vetor de coluna 1x45466, em que cada coluna será uma pontuação de similaridade com cada filme.
# Import linear_kernel
from sklearn.metrics.pairwise import linear_kernel
# Compute the cosine similarity matrix
cosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)
cosine_sim.shape
(45466, 45466)
cosine_sim[1]
array([0.01504121, 1. , 0.04681953, ..., 0. , 0.02198641,
0.00929411])
Você definirá uma função que recebe um título de filme como entrada e gera uma lista dos 10 filmes mais semelhantes. Em primeiro lugar, para isso, você precisa de um mapeamento reverso dos títulos dos filmes e dos índices DataFrame. Em outras palavras, você precisa de um mecanismo para identificar o índice de um filme no seu metadata DataFrame, com base em seu título.
#Construct a reverse map of indices and movie titles
indices = pd.Series(metadata.index, index=metadata['title']).drop_duplicates()
indices[:10]
title
Toy Story 0
Jumanji 1
Grumpier Old Men 2
Waiting to Exhale 3
Father of the Bride Part II 4
Heat 5
Sabrina 6
Tom and Huck 7
Sudden Death 8
GoldenEye 9
dtype: int64
Agora você está em boas condições para definir sua função de recomendação. Estas são as etapas a seguir que você deverá seguir:
Obtém o índice do filme com seu título.
Obtenha a lista de pontuações de similaridade de cosseno para esse filme específico com todos os filmes. Converta-o em uma lista de tuplas em que o primeiro elemento é sua posição e o segundo é a pontuação de similaridade.
Classifique a lista de tuplas mencionada anteriormente com base nas pontuações de similaridade, ou seja, o segundo elemento.
Obtenha os 10 principais elementos dessa lista. Ignore o primeiro elemento, pois ele se refere a você mesmo (o filme mais semelhante a um determinado filme é o próprio filme).
Retorna os títulos correspondentes aos índices dos elementos superiores.
# Function that takes in movie title as input and outputs most similar movies
def get_recommendations(title, cosine_sim=cosine_sim):
# Get the index of the movie that matches the title
idx = indices[title]
# Get the pairwsie similarity scores of all movies with that movie
sim_scores = list(enumerate(cosine_sim[idx]))
# Sort the movies based on the similarity scores
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# Get the scores of the 10 most similar movies
sim_scores = sim_scores[1:11]
# Get the movie indices
movie_indices = [i[0] for i in sim_scores]
# Return the top 10 most similar movies
return metadata['title'].iloc[movie_indices]
get_recommendations('The Dark Knight Rises')
12481 The Dark Knight
150 Batman Forever
1328 Batman Returns
15511 Batman: Under the Red Hood
585 Batman
21194 Batman Unmasked: The Psychology of the Dark Kn...
9230 Batman Beyond: Return of the Joker
18035 Batman: Year One
19792 Batman: The Dark Knight Returns, Part 1
3095 Batman: Mask of the Phantasm
Name: title, dtype: object
get_recommendations('The Godfather')
1178 The Godfather: Part II
44030 The Godfather Trilogy: 1972-1990
1914 The Godfather: Part III
23126 Blood Ties
11297 Household Saints
34717 Start Liquidation
10821 Election
38030 A Mother Should Be Loved
17729 Short Sharp Shock
26293 Beck 28 - Familjen
Name: title, dtype: object
Você percebe que, embora seu sistema tenha feito um bom trabalho ao encontrar filmes com descrições de enredo semelhantes, a qualidade das recomendações não é tão boa. "O Cavaleiro das Trevas Ressurge" retorna todos os filmes do Batman, enquanto é mais provável que as pessoas que gostaram desse filme estejam mais inclinadas a gostar de outros filmes de Christopher Nolan. Isso é algo que não pode ser capturado pelo seu sistema atual.
A qualidade do seu recomendador aumentaria com o uso de metadados melhores e com a captura de mais detalhes minuciosos. É exatamente isso que você fará nesta seção. Você criará um sistema de recomendação com base nos seguintes metadados: os três principais atores, o diretor, os gêneros relacionados e as palavras-chave do enredo do filme.
Os dados de palavras-chave, elenco e equipe não estão disponíveis no seu conjunto de dados atual, portanto, a primeira etapa seria carregá-los e mesclá-los ao seu DataFrame principal metadata.
# Load keywords and credits
credits = pd.read_csv('credits.csv')
keywords = pd.read_csv('keywords.csv')
# Remove rows with bad IDs.
metadata = metadata.drop([19730, 29503, 35587])
# Convert IDs to int. Required for merging
keywords['id'] = keywords['id'].astype('int')
credits['id'] = credits['id'].astype('int')
metadata['id'] = metadata['id'].astype('int')
# Merge keywords and credits into your main metadata dataframe
metadata = metadata.merge(credits, on='id')
metadata = metadata.merge(keywords, on='id')
# Print the first two movies of your newly merged metadata
metadata.head(2)
| adulto | belongs_to_collection | orçamento | genres | página inicial | id | imdb_id | original_language | original_title | visão geral | ... | spoken_languages | status | slogan | título | vídeo | vote_average | vote_count | elenco | equipe | keywords | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Falso | {'id': 10194, 'name': 'Toy Story Collection', ... | 30000000 | [{'id': 16, 'name': 'Animation'}, {'id': 35, '... | http://toystory.disney.com/toy-story | 862 | tt0114709 | e | Toy Story | Liderados por Woody, os brinquedos de Andy vivem felizes em seu ... | ... | [{'iso_639_1': 'en', 'name': 'English'}] | Liberado | NaN | Toy Story | Falso | 7.7 | 5415.0 | [{'cast_id': 14, 'character': Woody (voz)",... | [{'credit_id': '52fe4284c3a36847f8024f49', 'de... | [{'id': 931, 'name': 'jealousy'}, {'id': 4290,... |
| 1 | Falso | NaN | 65000000 | [{'id': 12, 'name': 'Adventure'}, {'id': 14, '... | NaN | 8844 | tt0113497 | e | Jumanji | Quando os irmãos Judy e Peter descobrem uma encha... | ... | [{'iso_639_1': 'en', 'name': 'English'}, {'iso... | Liberado | Jogue os dados e libere a emoção! | Jumanji | Falso | 6.9 | 2413.0 | [{'cast_id': 1, 'character': 'Alan Parrish', '... | [{'credit_id': '52fe44bfc3a36847f80a7cd1', 'de... | [{'id': 10090, 'name': 'board game'}, {'id': 1... |
2 linhas × 27 colunas
Dos seus novos recursos, elenco, equipe e palavras-chave, você precisa extrair os três atores mais importantes, o diretor e as palavras-chave associadas a esse filme.
Mas, antes de mais nada, seus dados estão presentes na forma de listas "encadeadas". Você precisa convertê-los em uma forma que seja útil para você.
# Parse the stringified features into their corresponding python objects
from ast import literal_eval
features = ['cast', 'crew', 'keywords', 'genres']
for feature in features:
metadata[feature] = metadata[feature].apply(literal_eval)
Em seguida, você escreve funções que o ajudarão a extrair as informações necessárias de cada recurso.
Primeiro, você importará o pacote NumPy para ter acesso à sua constante NaN. Em seguida, você pode usá-lo para escrever a função get_director():
# Import Numpy
import numpy as np
Obtenha o nome do diretor no recurso de equipe. Se o diretor não estiver listado, devolva NaN
def get_director(x):
for i in x:
if i['job'] == 'Director':
return i['name']
return np.nan
Em seguida, você escreverá uma função que retornará os 3 principais elementos ou a lista inteira, o que for maior. Aqui a lista se refere a cast, keywords e genres.
def get_list(x):
if isinstance(x, list):
names = [i['name'] for i in x]
#Check if more than 3 elements exist. If yes, return only first three. If no, return entire list.
if len(names) > 3:
names = names[:3]
return names
#Return empty list in case of missing/malformed data
return []
# Define new director, cast, genres and keywords features that are in a suitable form.
metadata['director'] = metadata['crew'].apply(get_director)
features = ['cast', 'keywords', 'genres']
for feature in features:
metadata[feature] = metadata[feature].apply(get_list)
# Print the new features of the first 3 films
metadata[['title', 'cast', 'director', 'keywords', 'genres']].head(3)
| título | elenco | diretor | keywords | genres | |
|---|---|---|---|---|---|
| 0 | Toy Story | [Tom Hanks, Tim Allen, Don Rickles] | John Lasseter | [ciúme, brinquedo, menino] | [Animação, Comédia, Família]. |
| 1 | Jumanji | [Robin Williams, Jonathan Hyde, Kirsten Dunst] | Joe Johnston | [Jogo de tabuleiro, desaparecimento, baseado em um jogo infantil... | [Aventura, Fantasia, Família] |
| 2 | Velhos mais rabugentos | [Walter Matthau, Jack Lemmon, Ann-Margret] | Howard Deutch | [pescando, melhor amigo, durante os créditos] | [Romance, Comédia]. |
A próxima etapa seria converter os nomes e as instâncias de palavras-chave em letras minúsculas e remover todos os espaços entre eles.
A remoção dos espaços entre as palavras é uma etapa importante do pré-processamento. Isso é feito para que seu vetorizador não conte o Johnny de "Johnny Depp" e "Johnny Galecki" como o mesmo. Após essa etapa de processamento, os atores mencionados acima serão representados como "johnnydepp" e "johnnygalecki" e serão distintos para o seu vetorizador.
Outro bom exemplo em que o modelo pode gerar a mesma representação vetorial é "congestionamento de pão" e "congestionamento de trânsito". Por isso, é melhor eliminar qualquer espaço presente.
A função abaixo fará exatamente isso para você:
# Function to convert all strings to lower case and strip names of spaces
def clean_data(x):
if isinstance(x, list):
return [str.lower(i.replace(" ", "")) for i in x]
else:
#Check if director exists. If not, return empty string
if isinstance(x, str):
return str.lower(x.replace(" ", ""))
else:
return ''
# Apply clean_data function to your features.
features = ['cast', 'keywords', 'director', 'genres']
for feature in features:
metadata[feature] = metadata[feature].apply(clean_data)
Agora você está em condições de criar a sua "sopa de metadados", que é uma cadeia de caracteres que contém todos os metadados que você deseja alimentar o seu vetorizador (ou seja, atores, diretor e palavras-chave).
A função create_soup simplesmente unirá todas as colunas necessárias com um espaço. Essa é a etapa final do pré-processamento, e a saída dessa função será inserida no modelo de vetor de palavras.
def create_soup(x):
return ' '.join(x['keywords']) + ' ' + ' '.join(x['cast']) + ' ' + x['director'] + ' ' + ' '.join(x['genres'])
# Create a new soup feature
metadata['soup'] = metadata.apply(create_soup, axis=1)
metadata[['soup']].head(2)
| sopa | |
|---|---|
| 0 | ciúme toy boy tomhanks timallen donrickles ... |
| 1 | jogo de tabuleiro disappearance baseado em um livro infantil ... |
As próximas etapas são as mesmas que você fez com o seu plot description based recommender. Uma diferença importante é que você usa CountVectorizer() em vez de TF-IDF. Isso ocorre porque você não quer diminuir a presença do ator/diretor se ele tiver atuado ou dirigido em relativamente mais filmes. Não faz muito sentido intuitivamente reduzi-los nesse contexto.
A principal diferença entre CountVectorizer() e TF-IDF é o componente de frequência inversa de documentos (IDF), que está presente no último e não no primeiro.
# Import CountVectorizer and create the count matrix
from sklearn.feature_extraction.text import CountVectorizer
count = CountVectorizer(stop_words='english')
count_matrix = count.fit_transform(metadata['soup'])
count_matrix.shape
(46628, 73881)
Na saída acima, você pode ver que há 73.881 vocabulários nos metadados que você forneceu a ele.
Em seguida, você usará o site cosine_similarity para medir a distância entre os embeddings.
# Compute the Cosine Similarity matrix based on the count_matrix
from sklearn.metrics.pairwise import cosine_similarity
cosine_sim2 = cosine_similarity(count_matrix, count_matrix)
# Reset index of your main DataFrame and construct reverse mapping as before
metadata = metadata.reset_index()
indices = pd.Series(metadata.index, index=metadata['title'])
Agora você pode reutilizar a função get_recommendations() passando a nova matriz cosine_sim2 como segundo argumento.
get_recommendations('The Dark Knight Rises', cosine_sim2)
12589 The Dark Knight
10210 Batman Begins
9311 Shiner
9874 Amongst Friends
7772 Mitchell
516 Romeo Is Bleeding
11463 The Prestige
24090 Quicksand
25038 Deadfall
41063 Sara
Name: title, dtype: object
get_recommendations('The Godfather', cosine_sim2)
1934 The Godfather: Part III
1199 The Godfather: Part II
15609 The Rain People
18940 Last Exit
34488 Rege
35802 Manuscripts Don't Burn
35803 Manuscripts Don't Burn
8001 The Night of the Following Day
18261 The Son of No One
28683 In the Name of the Law
Name: title, dtype: object
Ótimo! Você vê que o seu recomendador conseguiu capturar mais informações devido ao maior número de metadados e forneceu recomendações melhores. Obviamente, há várias maneiras de experimentar esse sistema para aprimorar as recomendações.
Algumas sugestões:
Introduzir um filtro de popularidade: esse recomendador pegaria os 30 filmes mais semelhantes, calcularia as classificações ponderadas (usando a fórmula do IMDB acima), classificaria os filmes com base nessa classificação e retornaria os 10 melhores filmes.
Outros membros da equipe: outros nomes de membros da equipe, como roteiristas e produtores, também podem ser incluídos.
O peso crescente do diretor: para dar mais peso ao diretor, ele pode ser mencionado várias vezes na sopa para aumentar as pontuações de similaridade dos filmes com o mesmo diretor.
Neste tutorial, você aprendeu a criar seus próprios sistemas de recomendação de filmes simples e baseados em conteúdo. Há também outro tipo de recomendação extremamente popular conhecido como filtros colaborativos.
Os filtros colaborativos podem ainda ser classificados em dois tipos:
User-based Filtering: esses sistemas recomendam a um usuário produtos de que usuários semelhantes gostaram. Por exemplo, digamos que Alice e Bob tenham um interesse semelhante por livros (ou seja, eles gostam e não gostam dos mesmos livros). Agora, digamos que um novo livro tenha sido lançado no mercado, e Alice o tenha lido e adorado. Portanto, é muito provável que Bob também goste dele e, por isso, o sistema recomenda esse livro a Bob.Item-based FilteringEsses sistemas são extremamente semelhantes ao mecanismo de recomendação de conteúdo que você criou. Esses sistemas identificam itens semelhantes com base em como as pessoas os classificaram no passado. Por exemplo, se Alice, Bob e Eve deram 5 estrelas para O Senhor dos Anéis e O Hobbit, o sistema identifica os itens como semelhantes. Portanto, se alguém comprar O Senhor dos Anéis, o sistema também recomendará O Hobbit para essa pessoa.
Você não criará esses sistemas neste tutorial, mas já está familiarizado com a maioria das ideias necessárias para isso. Um bom ponto de partida para você começar a usar filtros colaborativos é examinar o conjunto de dados do MovieLens, que pode ser encontrado aqui.
Parabéns por você ter concluído este tutorial!
Você passou com sucesso pelo nosso tutorial que ensinou tudo sobre sistemas de recomendação em Python. Você aprendeu a criar recomendadores simples e baseados em conteúdo.
Um bom exercício para todos vocês seria implementar a filtragem colaborativa em Python usando o subconjunto do conjunto de dados do MovieLens que você usou para criar recomendadores simples e baseados em conteúdo.
Se você está apenas começando a usar Python e gostaria de saber mais, faça o curso Introdução à ciência de dados em Python do DataCamp.
Cursos de Python
Curso
Curso
Curso
blog
Javier Canales Luna
13 min
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
