Curso
Diseño de flujos de trabajo de Machine Learning en Python
4 h
12.6K
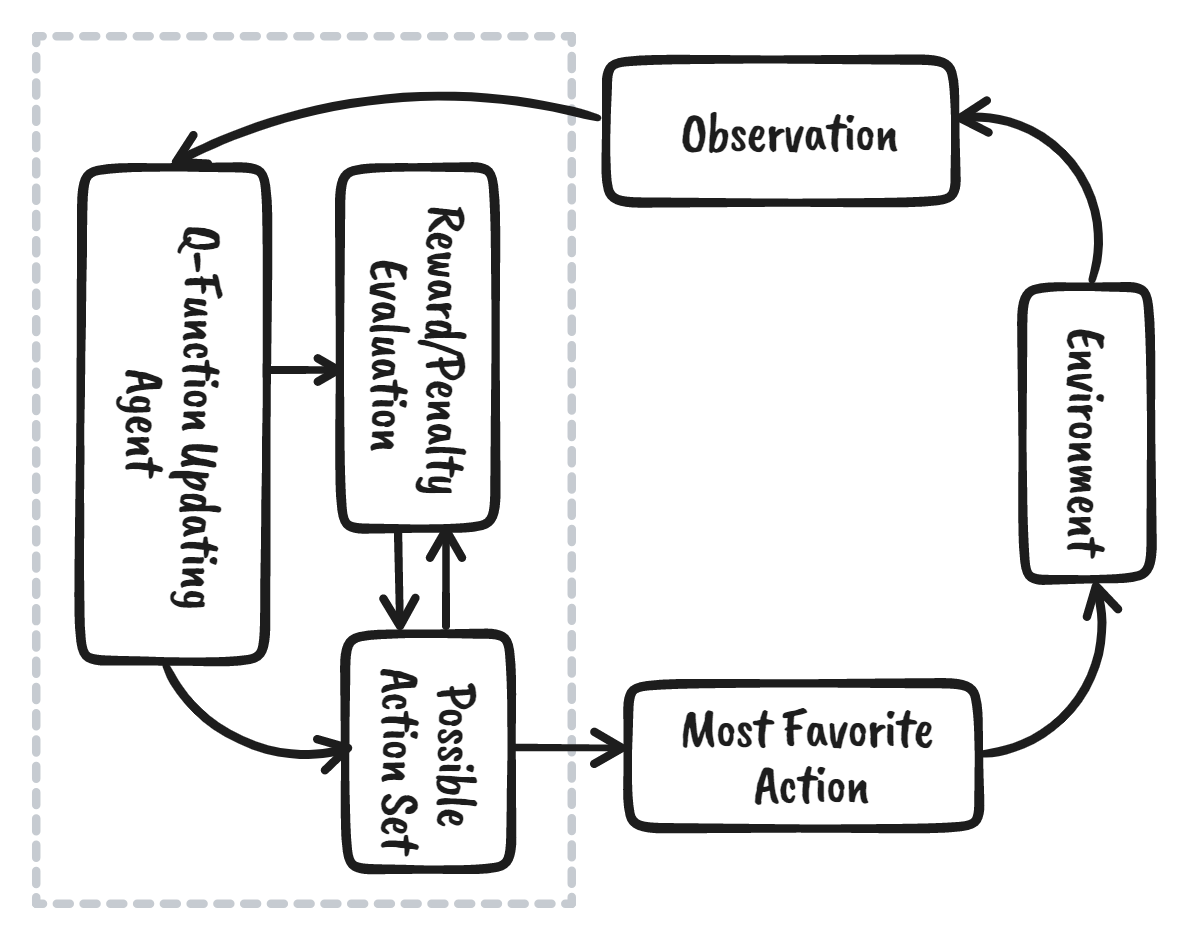
El aprendizaje por refuerzo (RL) es la parte del ecosistema del aprendizaje automático en la que el agente aprende interactuando con el entorno para obtener la estrategia óptima para alcanzar los objetivos. Es muy diferente de los algoritmos de aprendizaje automático supervisado, en los que tenemos que ingerir y procesar esos datos. El aprendizaje por refuerzo no requiere datos. En su lugar, aprende del entorno y del sistema de recompensas para tomar mejores decisiones.
Por ejemplo, en el videojuego Mario, si un personaje realiza una acción aleatoria (por ejemplo, moverse a la izquierda), en función de esa acción puede recibir una recompensa. Tras realizar la acción, el agente (Mario) se encuentra en un nuevo estado, y el proceso se repite hasta que el personaje del juego llega al final de la fase o muere.
Este episodio se repetirá varias veces hasta que Mario aprenda a navegar por el entorno maximizando las recompensas.

Imagen del autor
Podemos dividir el aprendizaje por refuerzo en cinco sencillos pasos:
Obtenga más información leyendo nuestro tutorial Introducción al aprendizaje por refuerzo. Explorará más a fondo cómo funciona el aprendizaje por refuerzo con ejemplos de código.
En este tutorial, aprenderemos sobre Q-learning y entenderemos por qué necesitamos Deep Q-learning. Además, aprenderemos a crear y entrenar algoritmos de Q-learning desde cero utilizando Numpy y OpenAI Gym.
Nota: Si es nuevo en el aprendizaje automático, le recomendamos que realice nuestro itinerario profesional de Científico de aprendizaje automático con Python para comprender mejor el Aprendizaje por refuerzo y Q-Learning.
Q-learning es un algoritmo sin modelo, basado en valores y fuera de política que encontrará la mejor serie de acciones basándose en el estado actual del agente. La "Q" significa calidad. La calidad representa el valor de la acción para maximizar las recompensas futuras.
Los algoritmos basados en modelos utilizan funciones de transición y recompensa para estimar la política óptima y crear el modelo. En cambio, los algoritmos sin modelo aprenden las consecuencias de sus acciones a través de la experiencia sin función de transición y recompensa.
El método basado en el valor entrena la función de valor para aprender qué estado es más valioso y actuar. Por otro lado, los métodos basados en políticas entrenan directamente la política para aprender qué acción tomar en un estado determinado.
En la política desactivada, el algoritmo evalúa y actualiza una política que difiere de la política utilizada para realizar una acción. Por el contrario, el algoritmo on-policy evalúa y mejora la misma política utilizada para realizar una acción.
Antes de entrar de lleno en cómo funciona el Q-learning, necesitamos aprender algunas terminologías útiles para entender los fundamentos del Q-learning.
Aprenderemos en detalle cómo funciona el aprendizaje Q utilizando el ejemplo de un lago helado. En este entorno, el agente debe cruzar el lago helado desde el inicio hasta la meta, sin caer en los agujeros. La mejor estrategia es alcanzar los objetivos por el camino más corto.

Gif por autor
El agente utilizará una tabla Q para tomar la mejor acción posible en función de la recompensa esperada para cada estado del entorno. En palabras sencillas, una tabla Q es una estructura de datos de conjuntos de acciones y estados, y utilizamos el algoritmo de aprendizaje Q para actualizar los valores de la tabla.
La función Q utiliza la ecuación de Bellman y toma como entrada el estado(s) y la acción(a). La ecuación simplifica el cálculo de los valores de estado y de estado-acción. 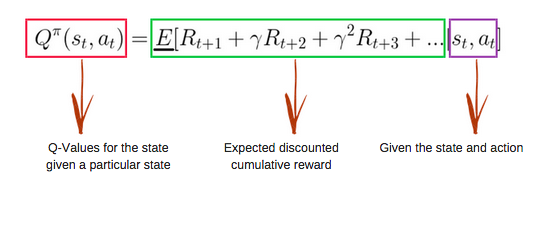
Imagen de freecodecamp.org
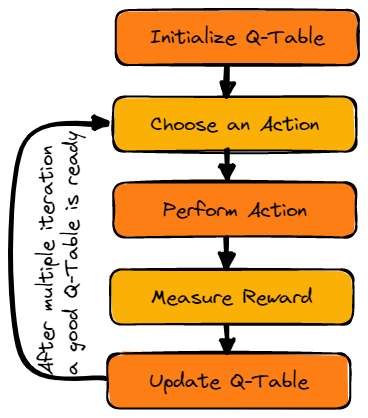
Imagen del autor
Primero inicializaremos la tabla Q. Construiremos la tabla con columnas basadas en el número de acciones y filas basadas en el número de estados.
En nuestro ejemplo, el personaje puede moverse hacia arriba, abajo, izquierda y derecha. Tenemos cuatro acciones posibles y cuatro estados (inicio, inactivo, camino equivocado y fin). También puede considerar el camino equivocado para caer en el agujero. Inicializaremos la tabla Q con valores a 0.
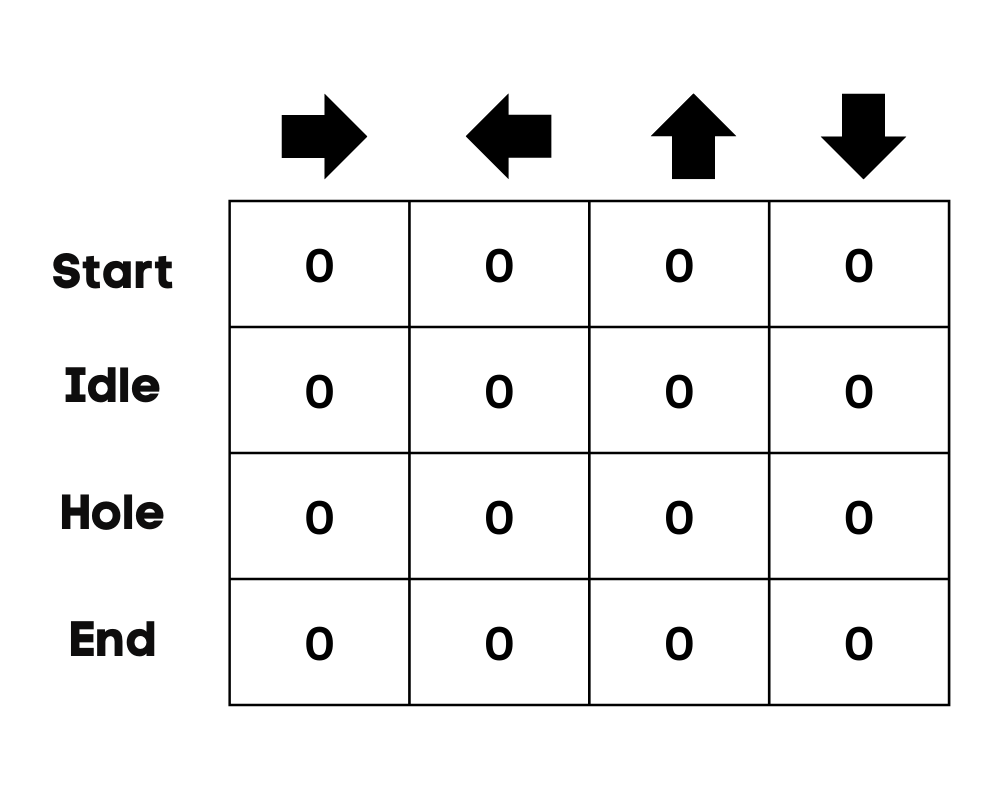
Imagen del autor
El segundo paso es bastante sencillo. Al principio, el agente elegirá tomar la acción aleatoria (hacia abajo o hacia la derecha), y en la segunda ejecución, utilizará una tabla Q actualizada para seleccionar la acción.
La elección de una acción y su ejecución se repetirán varias veces hasta que se detenga el bucle de entrenamiento. La primera acción y el primer estado se seleccionan mediante la tabla Q. En nuestro caso, todos los valores de la tabla Q son cero.
A continuación, el agente se moverá hacia abajo y actualizará la tabla Q mediante la ecuación de Bellman. Con cada movimiento, actualizaremos los valores en la Tabla Q y también la utilizaremos para determinar el mejor curso de acción.
Inicialmente, el agente se encuentra en modo de exploración y elige una acción aleatoria para explorar el entorno. La Estrategia Epsilon Greedy es un método sencillo para equilibrar la exploración y la explotación. La épsilon representa la probabilidad de elegir explorar y explotar cuando hay menos posibilidades de explorar.
Al principio, la tasa épsilon es más alta, lo que significa que el agente está en modo de exploración. Al explorar el entorno, el épsilon disminuye y los agentes empiezan a explotarlo. Durante la exploración, con cada iteración, el agente adquiere más confianza en la estimación de los valores Q
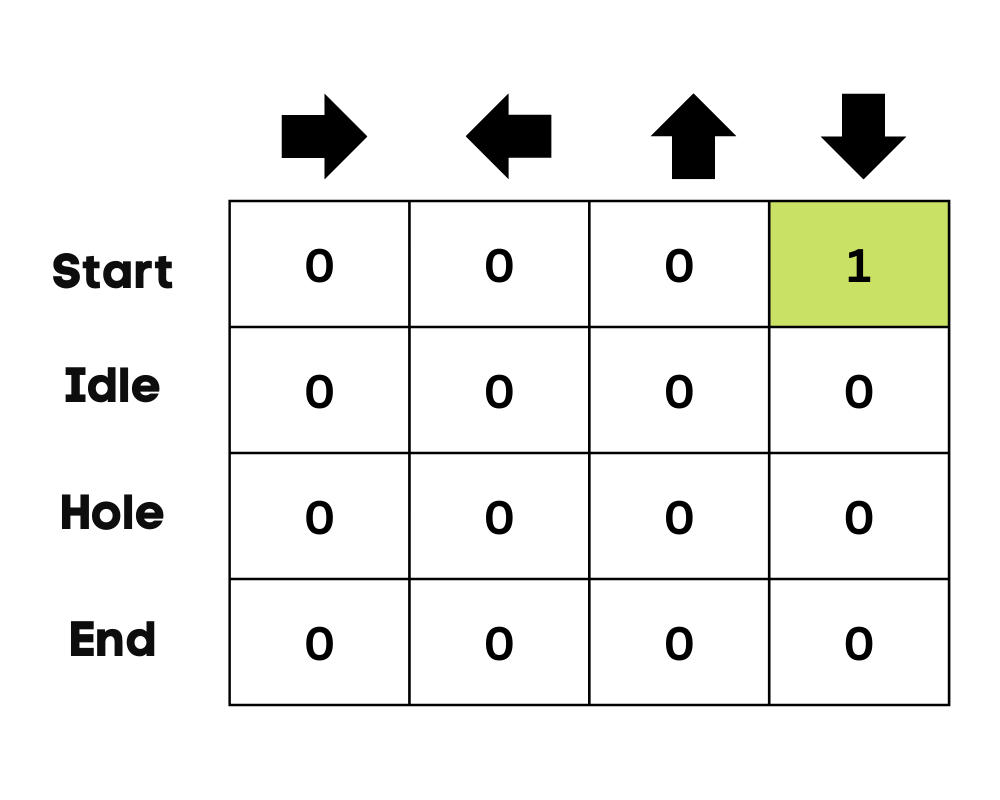
Imagen del autor
En el ejemplo del lago helado, el agente desconoce el entorno, por lo que realiza una acción aleatoria (moverse hacia abajo) para empezar. Como podemos ver en la imagen anterior, la tabla Q se actualiza utilizando la ecuación de Bellman.
Después de emprender la acción, mediremos el resultado y la recompensa.
Actualizaremos la función Q(St,At) mediante la ecuación. Utiliza los valores Q estimados del episodio anterior, la tasa de aprendizaje y el error de Diferencias Temporales. El error de diferencias temporales se calcula utilizando la recompensa inmediata, la recompensa futura máxima esperada descontada y el valor Q de la estimación anterior.
El proceso se repite varias veces hasta que se actualiza la tabla Q y se maximiza la función de valor Q.
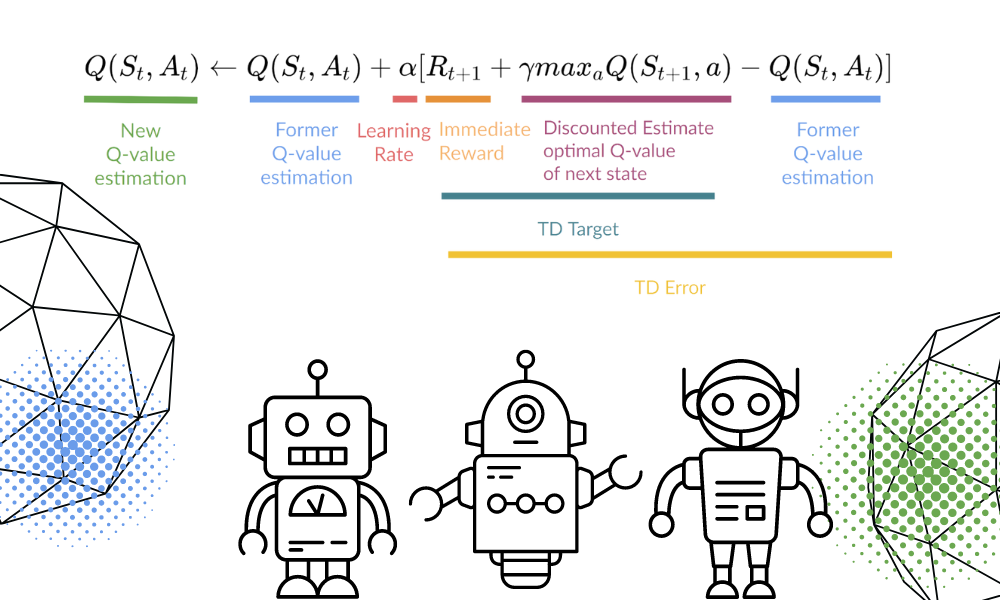
Imagen del autor | Equation Visuals de Thomas Simonini
Al principio, el agente está explorando el entorno para actualizar la tabla Q. Y cuando la Q-Table esté lista, el agente empezará a explotar y a tomar mejores decisiones. 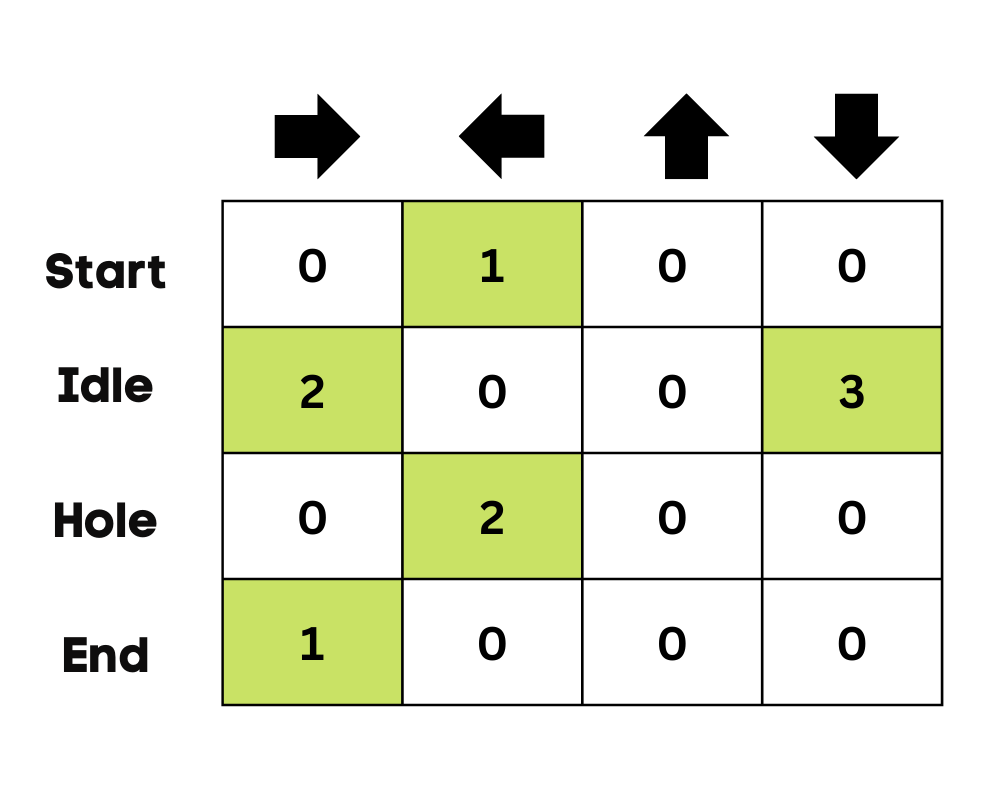
Imagen del autor
En el caso de un lago helado, el agente aprenderá a tomar el camino más corto para llegar a la meta y evitar saltar a los agujeros.
En esta sección, construiremos nuestro modelo Q-learning desde cero utilizando el entorno Gym, Pygame y Numpy. El tutorial de Python es una versión modificada del Cuaderno de Thomas Simonini. Incluye la inicialización del entorno y la tabla Q, la definición de la política codiciosa, la configuración de los hiperparámetros, la creación y ejecución del bucle de entrenamiento y la evaluación, y la visualización de los resultados.
Si tiene problemas para crear y ejecutar su bucle de entrenamiento, puede consultar el código fuente con el resultado.
Primero instalaremos todas las dependencias para generar un vídeo de reproducción (Gif). Necesitaremos una pantalla virtual (pyvirtualdisplay) para renderizar el entorno y grabar los fotogramas.
Nota: al utilizar `%%capture` estamos suprimiendo la salida de la celda Jupyter.
%%capture
!pip install pyglet==1.5.1
!apt install python-opengl
!apt install ffmpeg
!apt install xvfb
!pip3 install pyvirtualdisplay
# Virtual display
from pyvirtualdisplay import Display
virtual_display = Display(visible=0, size=(1400, 900))
virtual_display.start()Ahora instalaremos las dependencias que nos ayudarán a crear, ejecutar y evaluar el bucle de entrenamiento.
%%capture
!pip install gym==0.24
!pip install pygame
!pip install numpy
!pip install imageio imageio_ffmpegAhora importaremos las bibliotecas necesarias.
import numpy as np
import gym
import random
import imageio
from tqdm.notebook import trangeVamos a crear un entorno 4x4 antideslizante utilizando la biblioteca de gimnasia Frozen Lake.
Tras inicializar el entorno, realizaremos un análisis medioambiental.
env = gym.make("FrozenLake-v1",map_name="4x4",is_slippery=False)
print("Observation Space", env.observation_space)
print("Sample observation", env.observation_space.sample()) # display a random observationHay 16 espacios únicos en el entorno que se muestran en posiciones aleatorias.
Observation Space Discrete(16)
Sample observation 15Descubramos el número de acciones y mostremos la acción aleatoria.
El espacio de acción:
Función de recompensa:
print("Action Space Shape", env.action_space.n)
print("Action Space Sample", env.action_space.sample())Action Space Shape 4
Action Space Sample 1La tabla Q tiene columnas como acciones y filas como estados. Podemos utilizar OpenAI Gym para encontrar el espacio de acción y el espacio de estado. A continuación, utilizaremos esta información para crear la tabla Q.
state_space = env.observation_space.n
print("There are ", state_space, " possible states")
action_space = env.action_space.n
print("There are ", action_space, " possible actions")There are 16 possible states
There are 4 possible actionsPara inicializar la Q-Table, crearemos un array Numpy de state_space y actions space. Crearemos una matriz de 16 X 4.
def initialize_q_table(state_space, action_space):
Qtable = np.zeros((state_space, action_space))
return Qtable
Qtable_frozenlake = initialize_q_table(state_space, action_space)En la sección anterior, hemos aprendido acerca de la estrategia codiciosa épsilon que maneja los compromisos de exploración y explotación. Con una probabilidad de 1 - ɛ, hacemos explotación, y con la probabilidad ɛ, hacemos exploración.
En la epsilon_greedy_policy lo haremos:
def epsilon_greedy_policy(Qtable, state, epsilon):
random_int = random.uniform(0,1)
if random_int > epsilon:
action = np.argmax(Qtable[state])
else:
action = env.action_space.sample()
return actionComo sabemos, Q-learning es un algoritmo off-policy, lo que significa que la política de acción y la función de actualización son diferentes.
En este ejemplo, la política Epsilon Greedy es la política de actuación, y la política Greedy es la política de actualización.
La política Greedy también será la política final cuando se entrene al agente. Se utiliza para seleccionar el valor de estado y acción más alto de la tabla Q.
def greedy_policy(Qtable, state):
action = np.argmax(Qtable[state])
return actionEstos hiperparámetros se utilizan en el bucle de entrenamiento, y afinarlos te dará mejores resultados.
El Agente necesita explorar suficiente espacio de estados para aprender una buena aproximación de valores; necesitamos tener un decaimiento progresivo de épsilon. Si la tasa de decaimiento es alta, el agente puede quedarse atascado, ya que no ha explorado suficiente espacio de estados.
# Training parameters
n_training_episodes = 10000
learning_rate = 0.7
# Evaluation parameters
n_eval_episodes = 100
# Environment parameters
env_id = "FrozenLake-v1"
max_steps = 99
gamma = 0.95
eval_seed = []
# Exploration parameters
max_epsilon = 1.0
min_epsilon = 0.05
decay_rate = 0.0005 En el bucle de entrenamiento:
def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable):
for episode in trange(n_training_episodes):
epsilon = min_epsilon + (max_epsilon - min_epsilon)*np.exp(-decay_rate*episode)
# Reset the environment
state = env.reset()
step = 0
done = False
# repeat
for step in range(max_steps):
action = epsilon_greedy_policy(Qtable, state, epsilon)
new_state, reward, done, info = env.step(action)
Qtable[state][action] = Qtable[state][action] + learning_rate * (reward + gamma * np.max(Qtable[new_state]) - Qtable[state][action])
# If done, finish the episode
if done:
break
# Our state is the new state
state = new_state
return QtableTardamos 3 segundos en terminar 10.000 episodios de entrenamiento.
Qtable_frozenlake = train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable_frozenlake)
Como podemos ver, la Q-Table entrenada tiene valores, y el agente ahora utilizará estos valores para navegar por el entorno y alcanzar el objetivo.
Qtable_frozenlakearray([[0.73509189, 0.77378094, 0.77378094, 0.73509189],
[0.73509189, 0. , 0.81450625, 0.77378094],
[0.77378094, 0.857375 , 0.77378094, 0.81450625],
[0.81450625, 0. , 0.77378094, 0.77378094],
[0.77378094, 0.81450625, 0. , 0.73509189],
[0. , 0. , 0. , 0. ],
[0. , 0.9025 , 0. , 0.81450625],
[0. , 0. , 0. , 0. ],
[0.81450625, 0. , 0.857375 , 0.77378094],
[0.81450625, 0.9025 , 0.9025 , 0. ],
[0.857375 , 0.95 , 0. , 0.857375 ],
[0. , 0. , 0. , 0. ],
[0. , 0. , 0. , 0. ],
[0. , 0.9025 , 0.95 , 0.857375 ],
[0.9025 , 0.95 , 1. , 0.9025 ],
[0. , 0. , 0. , 0. ]])El agente_de_evaluación se ejecuta durante `n_episodios_de_evaluación` y devuelve la media y la desviación estándar de la recompensa.
def evaluate_agent(env, max_steps, n_eval_episodes, Q, seed):
episode_rewards = []
for episode in range(n_eval_episodes):
if seed:
state = env.reset(seed=seed[episode])
else:
state = env.reset()
step = 0
done = False
total_rewards_ep = 0
for step in range(max_steps):
# Take the action (index) that have the maximum reward
action = np.argmax(Q[state][:])
new_state, reward, done, info = env.step(action)
total_rewards_ep += reward
if done:
break
state = new_state
episode_rewards.append(total_rewards_ep)
mean_reward = np.mean(episode_rewards)
std_reward = np.std(episode_rewards)
return mean_reward, std_rewardComo puede ver, obtuvimos la puntuación perfecta con desviación típica cero. Significa que nuestro agente ha alcanzado el objetivo en los 100 episodios.
# Evaluate our Agent
mean_reward, std_reward = evaluate_agent(env, max_steps, n_eval_episodes, Qtable_frozenlake, eval_seed)
print(f"Mean_reward={mean_reward:.2f} +/- {std_reward:.2f}")Mean_reward=1.00 +/- 0.00Hasta ahora, hemos estado jugando con números, y para dar la demo, necesitamos crear un Gif animado del agente desde que empieza hasta que llega a la meta.
def record_video(env, Qtable, out_directory, fps=1):
images = []
done = False
state = env.reset(seed=random.randint(0,500))
img = env.render(mode='rgb_array')
images.append(img)
while not done:
# Take the action (index) that have the maximum expected future reward given that state
action = np.argmax(Qtable[state][:])
state, reward, done, info = env.step(action) # We directly put next_state = state for recording logic
img = env.render(mode='rgb_array')
images.append(img)
imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)Si estás en un cuaderno Jupyter, puedes mostrar el Gif utilizando la función `IPython.display` Image.
video_path="/content/replay.gif"
video_fps=1
record_video(env, Qtable_frozenlake, video_path, video_fps)
from IPython.display import Image
Image('./replay.gif')Ahora puedes compartir estos resultados con tus colegas y compañeros de clase o publicarlos en las redes sociales.
Cursos de aprendizaje automático
Curso
blog
Zoumana Keita
14 min
Tutorial
Moez Ali
Tutorial
Bex Tuychiev
Tutorial
Bekhruz Tuychiev
Tutorial
Avinash Navlani
Tutorial
Kevin Babitz

