Cours
Introduction à Python
4 h
6.9M
L'objectif de ce tutoriel n'est pas de faire de vous un expert en construction de modèles de systèmes de recommandation. L'objectif est plutôt de vous aider à démarrer en vous donnant un aperçu des types de systèmes de recommandation qui existent et de la manière dont vous pouvez en créer un vous-même.
Dans ce tutoriel, vous apprendrez à construire un modèle de base de systèmes de recommandation simples et basés sur le contenu. Bien que ces modèles soient loin d'atteindre la norme industrielle en termes de complexité, de qualité ou de précision, ils vous aideront à commencer à construire des modèles plus complexes qui produiront des résultats encore meilleurs.
Les systèmes de recommandation font partie des applications les plus populaires de la science des données aujourd'hui. Ils sont utilisés pour prédire la "note" ou la "préférence" qu'un utilisateur donnerait à un article. Presque toutes les grandes entreprises technologiques les ont appliquées sous une forme ou une autre. Amazon l'utilise pour suggérer des produits à ses clients, YouTube l'utilise pour choisir la vidéo à lire en lecture automatique et Facebook l'utilise pour recommander des pages à aimer et des personnes à suivre.
De plus, pour certaines entreprises comme Netflix, Amazon Prime, Hulu et Hotstar, le modèle d'entreprise et son succès dépendent de l'efficacité de leurs recommandations. Netflix a même offert en 2009 un million de dollars à toute personne capable d'améliorer son système de 10 %.
Il existe également des systèmes de recommandation populaires pour des domaines tels que les restaurants, les films et les rencontres en ligne. Des systèmes de recommandation ont également été développés pour explorer les articles de recherche et les experts, les collaborateurs et les services financiers. YouTube utilise le système de recommandation à grande échelle pour vous suggérer des vidéos en fonction de votre historique. Par exemple, si vous regardez beaucoup de vidéos éducatives, il vous suggérera ce type de vidéos.
Mais qu'est-ce que ces systèmes de recommandation ?
D'une manière générale, les systèmes de recommandation peuvent être classés en trois catégories :
Comme décrit dans la section précédente, les recommandeurs simples sont des systèmes de base qui recommandent les meilleurs éléments sur la base d'une certaine métrique ou d'un certain score. Dans cette section, vous allez construire un clone simplifié du Top 250 IMDB à l'aide des métadonnées collectées sur IMDB.
Voici les étapes à suivre :
Décidez de l'indicateur ou de la note à utiliser pour évaluer les films.
Calculez le score de chaque film.
Triez les films en fonction de leur score et affichez les meilleurs résultats.
Les fichiers de l'ensemble de données contiennent des métadonnées pour les 45 000 films répertoriés sur le site Full MovieLens Dataset. L'ensemble de données comprend les films sortis en juillet 2017 ou avant. Ce jeu de données contient des éléments tels que la distribution, l'équipe, les mots-clés de l'intrigue, le budget, les recettes, les affiches, les dates de sortie, les langues, les sociétés de production, les pays, le nombre de votes TMDB et les moyennes des votes.
Ces points caractéristiques pourraient être utilisés pour former vos modèles d'apprentissage automatique pour le filtrage de contenu et le filtrage collaboratif.
Cet ensemble de données se compose des fichiers suivants :
L'ensemble de données MovieLens comprend 26 millions d'évaluations et 750 000 applications de tags, provenant de 270 000 utilisateurs, sur les 45 000 films de cet ensemble de données. Vous pouvez y accéder à partir du site officiel de GroupLens.
Note : Le sous-ensemble de données utilisé dans le tutoriel d'aujourd'hui peut être téléchargé à partir d' ici.
Pour charger votre jeu de données, vous utiliserez la bibliothèque pandas DataFrame. La bibliothèque pandas est principalement utilisée pour la manipulation et l'analyse des données. Il représente vos données dans un format ligne-colonne. La bibliothèque Pandas s'appuie sur le tableau NumPy pour la mise en œuvre des objets de données pandas. pandas offre des structures de données et des opérations standard pour la manipulation de tableaux numériques, de séries chronologiques, d'images et d'ensembles de données de traitement du langage naturel. Fondamentalement, pandas est utile pour les ensembles de données qui peuvent être facilement représentés sous forme de tableaux.
Avant d'effectuer l'une des étapes ci-dessus, chargez votre ensemble de données de métadonnées de films dans un DataFrame pandas:
# Import Pandas
import pandas as pd
# Load Movies Metadata
metadata = pd.read_csv('movies_metadata.csv', low_memory=False)
# Print the first three rows
metadata.head(3)
| adulte | belongs_to_collection | budget | genres | page d'accueil | id | imdb_id | langue_originale | original_title | vue d'ensemble | ... | release_date | revenus | durée d'exécution | spoken_languages | status | slogan | title | video | vote_average | vote_count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Faux | {'id' : 10194, "nom" : Collection Toy Story", ... | 30000000 | [{'id' : 16, "nom" : Animation'}, {'id' : 35, '... | http://toystory.disney.com/toy-story | 862 | tt0114709 | fr | Histoire de jouets | Menés par Woody, les jouets d'Andy vivent heureux dans sa ... | ... | 1995-10-30 | 373554033.0 | 81.0 | [{'iso_639_1' : 'en', 'name' : English'}] | Libéré | NaN | Histoire de jouets | Faux | 7.7 | 5415.0 |
| 1 | Faux | NaN | 65000000 | [{'id' : 12, "nom" : 'Adventure'}, {'id' : 14, '... | NaN | 8844 | tt0113497 | fr | Jumanji | Lorsque les frères et sœurs Judy et Peter découvrent un encha... | ... | 1995-12-15 | 262797249.0 | 104.0 | [{'iso_639_1' : 'en', 'name' : 'English'}, {'iso... | Libéré | Lancez les dés et déchaînez les passions ! | Jumanji | Faux | 6.9 | 2413.0 |
| 2 | Faux | {'id' : 119050, "nom" : Les vieux grincheux collectionnent... | 0 | [{'id' : 10749, "nom" : Romance'}, {'id' : 35, ... | NaN | 15602 | tt0113228 | fr | Les vieux grincheux | Un mariage familial ravive l'ancienne querelle entre... | ... | 1995-12-22 | 0.0 | 101.0 | [{'iso_639_1' : 'en', 'name' : English'}] | Libéré | Toujours en train de crier. Toujours en lutte. Toujours prêt pour... | Les vieux grincheux | Faux | 6.5 | 92.0 |
3 lignes × 24 colonnes
L'une des mesures les plus élémentaires que vous puissiez imaginer est le classement qui permet de déterminer les 250 meilleurs films en fonction de leurs notes respectives.
Cependant, l'utilisation d'une note comme mesure comporte quelques mises en garde :
D'une part, il ne tient pas compte de la popularité d'un film. Par conséquent, un film noté 9 par 10 votants sera considéré comme "meilleur" qu'un film noté 8,9 par 10 000 votants.
Par exemple, imaginons que vous souhaitiez commander un repas chinois et que vous ayez le choix entre plusieurs restaurants. L'un d'entre eux est noté 5 étoiles par seulement 5 personnes, tandis que l'autre est noté 4,5 par 1 000 personnes. Quel restaurant préférez-vous ? Le deuxième, n'est-ce pas ?
Bien sûr, il peut y avoir une exception : le premier restaurant a ouvert ses portes il y a quelques jours à peine ; par conséquent, moins de personnes ont voté pour lui, alors qu'au contraire, le second restaurant est opérationnel depuis un an.
En tenant compte de ces lacunes, vous devez élaborer une note pondérée qui tient compte de la note moyenne et du nombre de votes qu'elle a accumulés. Un tel système garantira qu'un film ayant reçu une note de 9 de la part de 100 000 votants obtiendra une note (bien) plus élevée qu'un film ayant reçu la même note de la part de quelques centaines de votants seulement.
Puisque vous essayez de créer un clone du Top 250 d'IMDB, utilisons sa formule d'évaluation pondérée comme métrique/score. Mathématiquement, il est représenté comme suit :
\cbegin{equation} \bf WR = \left({{\bf v} \over {\bf v} + {\bf m} \cdot R\right) + \left({{\bf m} \over {\bf v} + {\bf m} \cdot C\right) \end{equation}
Dans l'équation ci-dessus,
v est le nombre de votes pour le film ;
m est le nombre minimum de votes requis pour figurer dans le tableau ;
R est la note moyenne du film ;
C est la moyenne des votes sur l'ensemble du rapport.
Vous disposez déjà des valeurs de v (vote_count) et de R (vote_average) pour chaque film de l'ensemble de données. Il est également possible de calculer directement C à partir de ces données.
La détermination d'une valeur appropriée pour m est un hyperparamètre que vous pouvez choisir en conséquence puisqu'il n'y a pas de valeur correcte pour m. Vous pouvez le considérer comme un filtre négatif préliminaire qui supprimera simplement les films dont le nombre de votes est inférieur à un certain seuil m. La sélectivité de votre filtre est laissée à votre discrétion.
Dans ce tutoriel, vous utiliserez le seuil m comme le 90e percentile. En d'autres termes, pour qu'un film figure dans le palmarès, il doit obtenir plus de votes qu'au moins 90 % des films de la liste. (En revanche, si vous aviez choisi le 75e percentile, vous auriez considéré les 25 % de films les plus populaires en termes de nombre de votes recueillis. Plus le percentile diminue, plus le nombre de films pris en compte augmente).
Dans un premier temps, calculons la valeur de C, la note moyenne de tous les films, à l'aide de la fonction pandas .mean():
# Calculate mean of vote average column
C = metadata['vote_average'].mean()
print(C)
5.618207215133889
D'après les résultats ci-dessus, vous pouvez observer que la note moyenne d'un film sur IMDB est d'environ 5,6 sur une échelle de 10.
Calculons ensuite le nombre de votes, m, reçus par un film dans le 90e percentile. La bibliothèque pandas rend cette tâche extrêmement triviale en utilisant la méthode .quantile() de pandas :
# Calculate the minimum number of votes required to be in the chart, m
m = metadata['vote_count'].quantile(0.90)
print(m)
160.0
Puisque vous disposez maintenant du site m, vous pouvez simplement utiliser une condition supérieure à égale à pour filtrer les films dont le nombre de votes est supérieur ou égal à 160 :
Vous pouvez utiliser la méthode .copy() pour vous assurer que le nouveau DataFrame q_movies créé est indépendant de votre DataFrame de métadonnées d'origine. En d'autres termes, toute modification apportée au DataFrame q_movies n'affectera pas le cadre de données de métadonnées d'origine.
# Filter out all qualified movies into a new DataFrame
q_movies = metadata.copy().loc[metadata['vote_count'] >= m]
q_movies.shape
(4555, 24)
metadata.shape
(45466, 24)
Les résultats ci-dessus montrent clairement qu'il y a environ 10 % de films dont le nombre de votes est supérieur à 160 et qui méritent de figurer sur cette liste.
L'étape suivante, et la plus importante, consiste à calculer la note pondérée pour chaque film qualifié. Pour ce faire, vous devrez
weighted_rating();m et C, il vous suffit de les passer en argument à la fonction ;vote_count(v) et vote_average(R) dans le cadre de données q_movies;Vous définirez une nouvelle caractéristique score, dont vous calculerez la valeur en appliquant cette fonction à votre DataFrame de films qualifiés :
# Function that computes the weighted rating of each movie
def weighted_rating(x, m=m, C=C):
v = x['vote_count']
R = x['vote_average']
# Calculation based on the IMDB formula
return (v/(v+m) * R) + (m/(m+v) * C)
# Define a new feature 'score' and calculate its value with `weighted_rating()`
q_movies['score'] = q_movies.apply(weighted_rating, axis=1)
Enfin, trions le DataFrame par ordre décroissant sur la base de la colonne score feature et obtenons le titre, le nombre de votes, la moyenne des votes et l'évaluation pondérée (score) des 20 meilleurs films.
#Sort movies based on score calculated above
q_movies = q_movies.sort_values('score', ascending=False)
#Print the top 15 movies
q_movies[['title', 'vote_count', 'vote_average', 'score']].head(20)
| title | vote_count | vote_average | score | |
|---|---|---|---|---|
| 314 | La rédemption de Shawshank | 8358.0 | 8.5 | 8.445869 |
| 834 | Le Parrain | 6024.0 | 8.5 | 8.425439 |
| 10309 | Dilwale Dulhania Le Jayenge | 661.0 | 9.1 | 8.421453 |
| 12481 | Le chevalier noir | 12269.0 | 8.3 | 8.265477 |
| 2843 | Fight Club | 9678.0 | 8.3 | 8.256385 |
| 292 | Pulp Fiction | 8670.0 | 8.3 | 8.251406 |
| 522 | La liste de Schindler | 4436.0 | 8.3 | 8.206639 |
| 23673 | Coup du lapin | 4376.0 | 8.3 | 8.205404 |
| 5481 | Spirited Away | 3968.0 | 8.3 | 8.196055 |
| 2211 | La vie est belle | 3643.0 | 8.3 | 8.187171 |
| 1178 | Le Parrain : Partie II | 3418.0 | 8.3 | 8.180076 |
| 1152 | Un vol au-dessus d'un nid de coucou | 3001.0 | 8.3 | 8.164256 |
| 351 | Forrest Gump | 8147.0 | 8.2 | 8.150272 |
| 1154 | L'Empire contre-attaque | 5998.0 | 8.2 | 8.132919 |
| 1176 | Psycho | 2405.0 | 8.3 | 8.132715 |
| 18465 | Les Intouchables | 5410.0 | 8.2 | 8.125837 |
| 40251 | Votre nom. | 1030.0 | 8.5 | 8.112532 |
| 289 | Léon : Le professionnel | 4293.0 | 8.2 | 8.107234 |
| 3030 | Le mille vert | 4166.0 | 8.2 | 8.104511 |
| 1170 | GoodFellas | 3211.0 | 8.2 | 8.077459 |
D'après les résultats ci-dessus, vous pouvez constater que le site simple recommender a fait du bon travail !
Ce classement a beaucoup de films en commun avec le Top 250 d'IMDB : par exemple, vos deux premiers films, "Shawshank Redemption" et "Le Parrain", sont les mêmes qu'IMDB et nous savons tous qu'il s'agit de films extraordinaires, en fait, tous les films du Top 20 méritent de figurer dans cette liste, n'est-ce pas ?
Dans cette section du didacticiel, vous apprendrez à construire un système qui recommande des films similaires à un film particulier. Pour ce faire, vous calculerez les scores de similarité cosine par paire pour tous les films sur la base de leur description de l'intrigue et vous recommanderez des films en fonction de ce seuil de score de similarité.
La description de la parcelle est disponible en tant que caractéristique overview dans votre jeu de données metadata. Examinons les intrigues de quelques films :
#Print plot overviews of the first 5 movies.
metadata['overview'].head()
0 Led by Woody, Andy's toys live happily in his ...
1 When siblings Judy and Peter discover an encha...
2 A family wedding reignites the ancient feud be...
3 Cheated on, mistreated and stepped on, the wom...
4 Just when George Banks has recovered from his ...
Name: overview, dtype: object
Il s'agit d'un problème de traitement du langage naturel. Vous devez donc extraire certaines caractéristiques des données textuelles ci-dessus avant de pouvoir calculer la similarité et/ou la dissimilarité entre elles. En d'autres termes, il n'est pas possible de calculer la similitude entre deux vues d'ensemble sous leur forme brute. Pour ce faire, vous devez calculer les vecteurs de mots de chaque aperçu ou document, comme nous l'appellerons dorénavant.
Comme leur nom l'indique, les vecteurs de mots sont des représentations vectorielles des mots contenus dans un document. Les vecteurs ont une signification sémantique. Par exemple, l'homme et le roi auront des représentations vectorielles proches l'une de l'autre, tandis que l'homme et la femme auront des représentations éloignées l'une de l'autre.
Vous calculerez les vecteurs Term Frequency-Inverse Document Frequency (TF-IDF) pour chaque document. Vous obtiendrez ainsi une matrice dans laquelle chaque colonne représente un mot du vocabulaire général (tous les mots qui apparaissent dans au moins un document), et chaque colonne représente un film, comme précédemment.
En substance, le score TF-IDF est la fréquence d'un mot apparaissant dans un document, pondérée par le nombre de documents dans lesquels il apparaît. Cela permet de réduire l'importance des mots qui apparaissent fréquemment dans les aperçus de l'intrigue et, par conséquent, leur importance dans le calcul de la note de similarité finale.
Heureusement, scikit-learn vous offre une classe intégrée TfIdfVectorizer qui produit la matrice TF-IDF en quelques lignes.
#Import TfIdfVectorizer from scikit-learn
from sklearn.feature_extraction.text import TfidfVectorizer
#Define a TF-IDF Vectorizer Object. Remove all english stop words such as 'the', 'a'
tfidf = TfidfVectorizer(stop_words='english')
#Replace NaN with an empty string
metadata['overview'] = metadata['overview'].fillna('')
#Construct the required TF-IDF matrix by fitting and transforming the data
tfidf_matrix = tfidf.fit_transform(metadata['overview'])
#Output the shape of tfidf_matrix
tfidf_matrix.shape
(45466, 75827)
#Array mapping from feature integer indices to feature name.
tfidf.get_feature_names()[5000:5010]
['avails',
'avaks',
'avalanche',
'avalanches',
'avallone',
'avalon',
'avant',
'avanthika',
'avanti',
'avaracious']
Le résultat ci-dessus montre que 75 827 vocabulaires ou mots différents de votre ensemble de données comportent 45 000 films.
Avec cette matrice en main, vous pouvez maintenant calculer un score de similarité. Il existe plusieurs mesures de similarité que vous pouvez utiliser à cette fin, telles que les scores de similarité de Manhattan, d'Euclide, de Pearson et de cosinus. Là encore, il n'y a pas de bonne réponse à la question de savoir quel est le meilleur score. Différents scores donnent de bons résultats dans différents scénarios, et il est souvent judicieux d'expérimenter différentes mesures et d'observer les résultats.
Vous utiliserez le site cosine similarity pour calculer une quantité numérique qui indique la similarité entre deux films. Vous utilisez le score de similarité cosinus car il est indépendant de la magnitude et est relativement facile et rapide à calculer (en particulier lorsqu'il est utilisé en conjonction avec les scores TF-IDF, qui seront expliqués plus loin). Mathématiquement, il est défini comme suit :
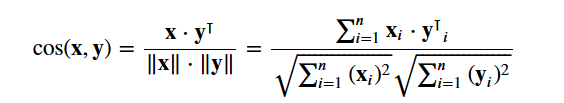
Comme vous avez utilisé le vecteur TF-IDF, le calcul du produit de points entre chaque vecteur vous donnera directement le score de similarité cosinus. Par conséquent, vous utiliserez sklearn's linear_kernel() au lieu de cosine_similarities(), car c'est plus rapide.
Vous obtiendrez une matrice de forme 45466x45466, ce qui signifie que chaque film overview a un score de similarité cosinusoïdale avec tous les autres films overview. Par conséquent, chaque film sera un vecteur de colonnes 1x45466 où chaque colonne sera un score de similarité avec chaque film.
# Import linear_kernel
from sklearn.metrics.pairwise import linear_kernel
# Compute the cosine similarity matrix
cosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)
cosine_sim.shape
(45466, 45466)
cosine_sim[1]
array([0.01504121, 1. , 0.04681953, ..., 0. , 0.02198641,
0.00929411])
Vous allez définir une fonction qui prend en entrée le titre d'un film et qui produit une liste des 10 films les plus similaires. Tout d'abord, vous avez besoin d'une correspondance inverse entre les titres de films et les indices DataFrame. En d'autres termes, vous avez besoin d'un mécanisme pour identifier l'index d'un film dans votre DataFrame metadata, en fonction de son titre.
#Construct a reverse map of indices and movie titles
indices = pd.Series(metadata.index, index=metadata['title']).drop_duplicates()
indices[:10]
title
Toy Story 0
Jumanji 1
Grumpier Old Men 2
Waiting to Exhale 3
Father of the Bride Part II 4
Heat 5
Sabrina 6
Tom and Huck 7
Sudden Death 8
GoldenEye 9
dtype: int64
Vous êtes maintenant en mesure de définir votre fonction de recommandation. Voici les étapes à suivre :
Obtenez l'index du film en fonction de son titre.
Obtenez la liste des scores de similarité cosinus pour ce film particulier avec tous les films. Convertissez-le en une liste de tuples dont le premier élément est la position et le second le score de similarité.
Triez la liste de tuples susmentionnée sur la base des scores de similarité, c'est-à-dire le deuxième élément.
Obtenez les 10 premiers éléments de cette liste. Ignorez le premier élément car il se réfère à vous-même (le film le plus similaire à un film particulier est le film lui-même).
Retourne les titres correspondant aux indices des éléments supérieurs.
# Function that takes in movie title as input and outputs most similar movies
def get_recommendations(title, cosine_sim=cosine_sim):
# Get the index of the movie that matches the title
idx = indices[title]
# Get the pairwsie similarity scores of all movies with that movie
sim_scores = list(enumerate(cosine_sim[idx]))
# Sort the movies based on the similarity scores
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# Get the scores of the 10 most similar movies
sim_scores = sim_scores[1:11]
# Get the movie indices
movie_indices = [i[0] for i in sim_scores]
# Return the top 10 most similar movies
return metadata['title'].iloc[movie_indices]
get_recommendations('The Dark Knight Rises')
12481 The Dark Knight
150 Batman Forever
1328 Batman Returns
15511 Batman: Under the Red Hood
585 Batman
21194 Batman Unmasked: The Psychology of the Dark Kn...
9230 Batman Beyond: Return of the Joker
18035 Batman: Year One
19792 Batman: The Dark Knight Returns, Part 1
3095 Batman: Mask of the Phantasm
Name: title, dtype: object
get_recommendations('The Godfather')
1178 The Godfather: Part II
44030 The Godfather Trilogy: 1972-1990
1914 The Godfather: Part III
23126 Blood Ties
11297 Household Saints
34717 Start Liquidation
10821 Election
38030 A Mother Should Be Loved
17729 Short Sharp Shock
26293 Beck 28 - Familjen
Name: title, dtype: object
Vous constatez que, bien que votre système ait fait un travail décent pour trouver des films avec des descriptions d'intrigues similaires, la qualité des recommandations n'est pas très bonne. "The Dark Knight Rises" renvoie tous les films de Batman, alors qu'il est plus probable que les personnes qui ont aimé ce film soient plus enclines à apprécier d'autres films de Christopher Nolan. C'est quelque chose qui ne peut pas être pris en compte par votre système actuel.
La qualité de votre système de recommandation sera améliorée grâce à l'utilisation de meilleures métadonnées et à la saisie de détails plus fins. C'est précisément ce que vous allez faire dans cette section. Vous allez construire un système de recommandation basé sur les métadonnées suivantes : les 3 acteurs principaux, le réalisateur, les genres apparentés et les mots-clés de l'intrigue du film.
Les mots-clés, les acteurs et les membres de l'équipe ne sont pas disponibles dans votre ensemble de données actuel. La première étape consiste donc à les charger et à les fusionner dans votre DataFrame principal metadata.
# Load keywords and credits
credits = pd.read_csv('credits.csv')
keywords = pd.read_csv('keywords.csv')
# Remove rows with bad IDs.
metadata = metadata.drop([19730, 29503, 35587])
# Convert IDs to int. Required for merging
keywords['id'] = keywords['id'].astype('int')
credits['id'] = credits['id'].astype('int')
metadata['id'] = metadata['id'].astype('int')
# Merge keywords and credits into your main metadata dataframe
metadata = metadata.merge(credits, on='id')
metadata = metadata.merge(keywords, on='id')
# Print the first two movies of your newly merged metadata
metadata.head(2)
| adulte | belongs_to_collection | budget | genres | page d'accueil | id | imdb_id | langue_originale | original_title | vue d'ensemble | ... | spoken_languages | status | slogan | title | video | vote_average | vote_count | moulage | équipage | keywords | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Faux | {'id' : 10194, "nom" : Collection Toy Story", ... | 30000000 | [{'id' : 16, "nom" : Animation'}, {'id' : 35, '... | http://toystory.disney.com/toy-story | 862 | tt0114709 | fr | Histoire de jouets | Menés par Woody, les jouets d'Andy vivent heureux dans sa ... | ... | [{'iso_639_1' : 'en', 'name' : English'}] | Libéré | NaN | Histoire de jouets | Faux | 7.7 | 5415.0 | [{'cast_id' : 14, "caractère" : 'Woody (voix)',... | [{'credit_id' : '52fe4284c3a36847f8024f49', 'de... | [{'id' : 931, 'name' : 'jealousy'}, {'id' : 4290,... |
| 1 | Faux | NaN | 65000000 | [{'id' : 12, "nom" : 'Adventure'}, {'id' : 14, '... | NaN | 8844 | tt0113497 | fr | Jumanji | Lorsque les frères et sœurs Judy et Peter découvrent un encha... | ... | [{'iso_639_1' : 'en', 'name' : 'English'}, {'iso... | Libéré | Lancez les dés et déchaînez les passions ! | Jumanji | Faux | 6.9 | 2413.0 | [{'cast_id' : 1, "caractère" : Alan Parrish", "... | [{'credit_id' : '52fe44bfc3a36847f80a7cd1', 'de... | [{'id' : 10090, 'name' : 'board game'}, {'id' : 1... |
2 lignes × 27 colonnes
À partir de vos nouvelles caractéristiques, la distribution, l'équipe et les mots-clés, vous devez extraire les trois acteurs les plus importants, le réalisateur et les mots-clés associés à ce film.
Mais tout d'abord, vos données sont présentes sous la forme de listes "stringifiées". Vous devez les convertir de manière à ce qu'ils soient utilisables pour vous.
# Parse the stringified features into their corresponding python objects
from ast import literal_eval
features = ['cast', 'crew', 'keywords', 'genres']
for feature in features:
metadata[feature] = metadata[feature].apply(literal_eval)
Ensuite, vous écrivez des fonctions qui vous aideront à extraire les informations requises de chaque caractéristique.
Tout d'abord, vous allez importer le paquetage NumPy pour accéder à sa constante NaN. Ensuite, vous pouvez l'utiliser pour écrire la fonction get_director():
# Import Numpy
import numpy as np
Obtenez le nom du réalisateur à partir de la liste des membres de l'équipe. Si le directeur ne figure pas sur la liste, renvoyez NaN
def get_director(x):
for i in x:
if i['job'] == 'Director':
return i['name']
return np.nan
Ensuite, vous écrirez une fonction qui renverra les 3 premiers éléments ou la liste entière, selon ce qui est le plus important. Ici, la liste fait référence aux sites cast, keywords, et genres.
def get_list(x):
if isinstance(x, list):
names = [i['name'] for i in x]
#Check if more than 3 elements exist. If yes, return only first three. If no, return entire list.
if len(names) > 3:
names = names[:3]
return names
#Return empty list in case of missing/malformed data
return []
# Define new director, cast, genres and keywords features that are in a suitable form.
metadata['director'] = metadata['crew'].apply(get_director)
features = ['cast', 'keywords', 'genres']
for feature in features:
metadata[feature] = metadata[feature].apply(get_list)
# Print the new features of the first 3 films
metadata[['title', 'cast', 'director', 'keywords', 'genres']].head(3)
| title | moulage | directeur | keywords | genres | |
|---|---|---|---|---|---|
| 0 | Histoire de jouets | [Tom Hanks, Tim Allen, Don Rickles] | John Lasseter | [jalousie, jouet, garçon] | [Animation, Comédie, Famille] |
| 1 | Jumanji | [Robin Williams, Jonathan Hyde, Kirsten Dunst] | Joe Johnston | [jeu de société, disparition, basé sur des... | [Aventure, Fantaisie, Famille] |
| 2 | Les vieux grincheux | [Walter Matthau, Jack Lemmon, Ann-Margret] | Howard Deutch | [pêche, meilleur ami, pendant le générique] | [Romance, Comedy] |
L'étape suivante consisterait à convertir les noms et les instances de mots-clés en minuscules et à supprimer tous les espaces entre eux.
La suppression des espaces entre les mots est une étape importante du prétraitement. Cela permet à votre vecteur de ne pas considérer les Johnny de "Johnny Depp" et de "Johnny Galecki" comme identiques. Après cette étape de traitement, les acteurs susmentionnés seront représentés par "johnnydepp" et "johnnygalecki" et seront distincts de votre vecteur.
Un autre bon exemple où le modèle peut produire la même représentation vectorielle est "embouteillage de pain" et "embouteillage de circulation". Il est donc préférable de supprimer tout espace présent.
La fonction ci-dessous le fera pour vous :
# Function to convert all strings to lower case and strip names of spaces
def clean_data(x):
if isinstance(x, list):
return [str.lower(i.replace(" ", "")) for i in x]
else:
#Check if director exists. If not, return empty string
if isinstance(x, str):
return str.lower(x.replace(" ", ""))
else:
return ''
# Apply clean_data function to your features.
features = ['cast', 'keywords', 'director', 'genres']
for feature in features:
metadata[feature] = metadata[feature].apply(clean_data)
Vous êtes maintenant en mesure de créer votre "soupe de métadonnées", qui est une chaîne contenant toutes les métadonnées que vous souhaitez transmettre à votre vectoriseur (à savoir les acteurs, le réalisateur et les mots-clés).
La fonction create_soup joindra simplement toutes les colonnes requises par un espace. Il s'agit de la dernière étape de prétraitement, et la sortie de cette fonction sera introduite dans le modèle de vecteur de mots.
def create_soup(x):
return ' '.join(x['keywords']) + ' ' + ' '.join(x['cast']) + ' ' + x['director'] + ' ' + ' '.join(x['genres'])
# Create a new soup feature
metadata['soup'] = metadata.apply(create_soup, axis=1)
metadata[['soup']].head(2)
| soupe | |
|---|---|
| 0 | jalousie toy boy tomhanks timallen donrickles ... |
| 1 | jeu de société disparition basé sur un livre pour enfants ... |
Les étapes suivantes sont les mêmes que celles que vous avez suivies pour votre plot description based recommender. La principale différence est que vous utilisez CountVectorizer() au lieu de TF-IDF. En effet, vous ne voulez pas minimiser la présence de l'acteur/réalisateur s'il a joué ou réalisé relativement plus de films. Il n'est pas très intuitif de les pondérer dans ce contexte.
La principale différence entre CountVectorizer() et TF-IDF est la composante de fréquence inverse des documents (IDF) qui est présente dans cette dernière et non dans la première.
# Import CountVectorizer and create the count matrix
from sklearn.feature_extraction.text import CountVectorizer
count = CountVectorizer(stop_words='english')
count_matrix = count.fit_transform(metadata['soup'])
count_matrix.shape
(46628, 73881)
Dans le résultat ci-dessus, vous pouvez voir qu'il y a 73 881 vocabulaires dans les métadonnées que vous avez introduites.
Ensuite, vous utiliserez le site cosine_similarity pour mesurer la distance entre les intégrations.
# Compute the Cosine Similarity matrix based on the count_matrix
from sklearn.metrics.pairwise import cosine_similarity
cosine_sim2 = cosine_similarity(count_matrix, count_matrix)
# Reset index of your main DataFrame and construct reverse mapping as before
metadata = metadata.reset_index()
indices = pd.Series(metadata.index, index=metadata['title'])
Vous pouvez maintenant réutiliser votre fonction get_recommendations() en passant la nouvelle matrice cosine_sim2 comme deuxième argument.
get_recommendations('The Dark Knight Rises', cosine_sim2)
12589 The Dark Knight
10210 Batman Begins
9311 Shiner
9874 Amongst Friends
7772 Mitchell
516 Romeo Is Bleeding
11463 The Prestige
24090 Quicksand
25038 Deadfall
41063 Sara
Name: title, dtype: object
get_recommendations('The Godfather', cosine_sim2)
1934 The Godfather: Part III
1199 The Godfather: Part II
15609 The Rain People
18940 Last Exit
34488 Rege
35802 Manuscripts Don't Burn
35803 Manuscripts Don't Burn
8001 The Night of the Following Day
18261 The Son of No One
28683 In the Name of the Law
Name: title, dtype: object
Excellent ! Vous constatez que votre système de recommandation a réussi à capturer plus d'informations grâce à davantage de métadonnées et qu'il vous a donné de meilleures recommandations. Il existe bien sûr de nombreuses façons d'expérimenter ce système pour améliorer les recommandations.
Quelques suggestions :
Introduisez un filtre de popularité : ce système de recommandation prendrait les 30 films les plus similaires, calculerait les notes pondérées (en utilisant la formule IMDB ci-dessus), trierait les films en fonction de ces notes et renverrait les 10 premiers films.
Autres membres de l'équipe : les noms des autres membres de l'équipe, tels que les scénaristes et les producteurs, peuvent également être inclus.
Le poids croissant du réalisateur : pour donner plus de poids au réalisateur, celui-ci peut être mentionné plusieurs fois dans la soupe afin d'augmenter les scores de similarité des films ayant le même réalisateur.
Dans ce tutoriel, vous avez appris à construire votre propre système de recommandation de films simple et basé sur le contenu. Il existe également un autre type de recommandation extrêmement populaire, connu sous le nom de filtres collaboratifs.
Les filtres collaboratifs peuvent être classés en deux catégories :
User-based FilteringCes systèmes recommandent à l'utilisateur des produits que des utilisateurs similaires ont aimés. Par exemple, supposons qu'Alice et Bob s'intéressent de la même manière aux livres (c'est-à-dire qu'ils aiment et n'aiment pas les mêmes livres). Supposons qu'un nouveau livre ait été lancé sur le marché et qu'Alice l'ait lu et aimé. Il est donc très probable que Bob l'apprécie également, et le système lui recommande donc ce livre.Item-based FilteringCes systèmes sont extrêmement similaires au moteur de recommandation de contenu que vous avez construit. Ces systèmes identifient des articles similaires sur la base de l'évaluation qu'en ont faite les internautes dans le passé. Par exemple, si Alice, Bob et Eve ont attribué 5 étoiles au Seigneur des anneaux et au Hobbit, le système identifie les articles comme similaires. Par conséquent, si quelqu'un achète Le Seigneur des Anneaux, le système lui recommande également Le Hobbit.
Vous ne construirez pas ces systèmes dans le cadre de ce tutoriel, mais vous êtes déjà familiarisé avec la plupart des idées nécessaires pour le faire. Un bon point de départ pour les filtres collaboratifs est l'examen de l'ensemble de données MovieLens, que vous trouverez ici.
Félicitations pour avoir terminé ce tutoriel !
Vous avez parcouru avec succès notre tutoriel qui vous a tout appris sur les systèmes de recommandation en Python. Vous avez appris à créer des outils de recommandation simples et basés sur le contenu.
Un bon exercice pour vous tous serait de mettre en œuvre le filtrage collaboratif en Python en utilisant le sous-ensemble de données MovieLens que vous avez utilisé pour construire des recommandeurs simples et basés sur le contenu.
Si vous débutez en Python et souhaitez en savoir plus, suivez la formation Introduction à la science des données en Python de DataCamp.
Cours de Python
Cours
Cours
Cours
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min