Curso
Extreme Gradient Boosting con XGBoost
4 h
60.7K
XGBoost es uno de los marcos de machine learning más populares entre los científicos de datos. Según la encuesta State of Data Science 2021 de Kaggle, casi el 50 % de los encuestados dijeron que utilizaban XGBoost, que solo estaba por debajo de TensorFlow y Sklearn.
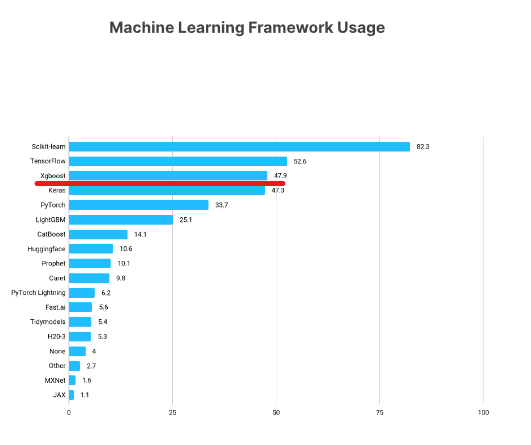
https://www.kaggle.com/kaggle-survey-2021
Este tutorial de XGBoost presentará los aspectos clave de este popular marco de Python, explorando cómo puedes utilizarlo para tus propios proyectos de machine learning.
Mira y aprende más sobre el uso de XGBoost en Python en este vídeo de nuestro curso.
A lo largo de este tutorial, cubriremos los aspectos clave de XGBoost, incluyendo:
¡Empecemos!
Ejecuta y edita el código de este tutorial en línea
Ejecutar códigoPuedes instalar XGBoost como cualquier otra biblioteca a través de pip. Este método de instalación también incluirá compatibilidad con la GPU NVIDIA de tu equipo. Si quieres instalar la versión solo para CPU, puedes utilizar conda-forge:
$ pip install --user xgboost
# CPU only
$ conda install -c conda-forge py-xgboost-cpu
# Use NVIDIA GPU
$ conda install -c conda-forge py-xgboost-gpuSe recomienda instalar XGBoost en un entorno virtual para no contaminar tu entorno base.
Recomendamos ejecutar los ejemplos del tutorial con un equipo con GPU. Si no tienes uno, puedes consultar alternativas como DataCamp Workspace o Google Colab.
Si te decides por Colab, tiene instalada la versión anterior de XGBoost, por lo que debes invocar pip install --upgrade xgboost para obtener la última versión.
Trabajaremos con el conjunto de datos Diamonds a lo largo de todo el tutorial. Está integrado en la biblioteca Seaborn, o también puedes descargarlo de Kaggle. Tiene una buena combinación de características numéricas y categóricas y más de 50 000 observaciones que nos permiten mostrar cómodamente todas las ventajas de XGBoost.
import seaborn as sns
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
diamonds = sns.load_dataset("diamonds")
diamonds.head()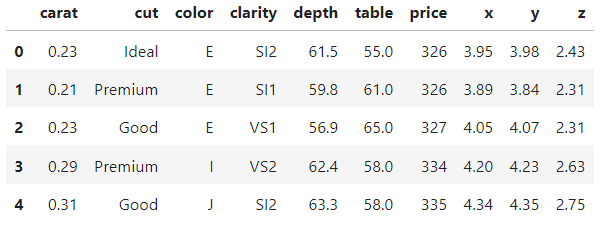
>>> diamonds.shape
(53940, 10)En un proyecto típico del mundo real, pasarías mucho más tiempo explorando el conjunto de datos y visualizando sus características. Sin embargo, como estos datos están integrados en Seaborn, están relativamente limpios.
Así que nos limitaremos a ver el resumen de 5 números de las características numéricas y categóricas y nos pondremos en marcha. Puedes dedicar unos momentos a familiarizarte con el conjunto de datos.
diamonds.describe()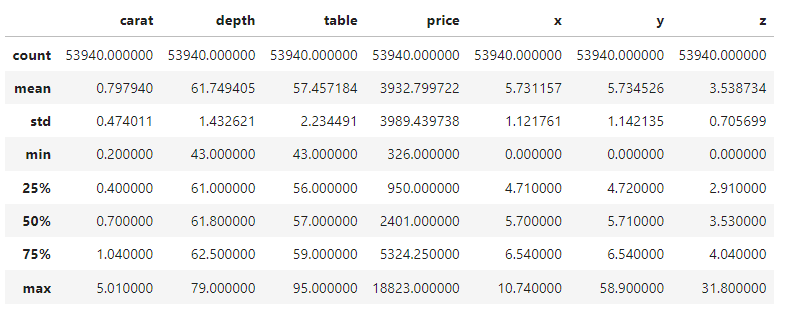
diamonds.describe(exclude=np.number)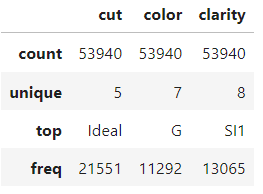
Una vez que hayas terminado con la exploración, el primer paso en cualquier proyecto es enmarcar el problema de machine learning y extraer las matrices de características y objetivos basándote en el conjunto de datos.
En este tutorial, primero intentaremos prever los precios de los diamantes utilizando sus mediciones físicas, por lo que nuestro objetivo será la columna de precios.
Por tanto, aislamos las características en x y el objetivo en y:
from sklearn.model_selection import train_test_split
# Extract feature and target arrays
X, y = diamonds.drop('price', axis=1), diamonds[['price']]El conjunto de datos tiene tres columnas categóricas. Normalmente, las codificarías con codificación ordinal o one-hot, pero XGBoost tiene la capacidad de tratar internamente con categóricos.
La forma de activar esta función es convertir las columnas categóricas al tipo de datos Pandas category (por defecto, se tratan como columnas de texto):
# Extract text features
cats = X.select_dtypes(exclude=np.number).columns.tolist()
# Convert to Pandas category
for col in cats:
X[col] = X[col].astype('category')Ahora, cuando imprimas el atributo dtypes, verás que tenemos tres características category:
>>> X.dtypes
carat float64
cut category
color category
clarity category
depth float64
table float64
x float64
y float64
z float64
dtype: objectDividamos los datos en conjuntos de entrenamiento y prueba (tamaño de la prueba 0,25):
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)Ahora, la parte importante: XGBoost incluye su propia clase para almacenar conjuntos de datos, llamada DMatrix. Es una clase muy optimizada en cuanto a memoria y velocidad. Por eso, convertir conjuntos de datos a este formato es un requisito para la API nativa de XGBoost:
import xgboost as xgb
# Create regression matrices
dtrain_reg = xgb.DMatrix(X_train, y_train, enable_categorical=True)
dtest_reg = xgb.DMatrix(X_test, y_test, enable_categorical=True)La clase acepta tanto las características de entrenamiento como las etiquetas. Para permitir la codificación automática de las columnas de categoría de Pandas, también establecemos enable_categorical como True.
Nota:
¿Por qué utilizamos la API nativa de XGBoost, en lugar de su API Scikit-learn? Aunque al principio te resulte más cómodo utilizar la API Sklearn, más adelante te darás cuenta de que la API nativa de XGBoost contiene algunas funciones excelentes que la otra no admite. Así que mejor acostumbrarse desde el principio. Sin embargo, hay una sección al final en la que mostramos cómo cambiar de API con una sola línea de código, incluso después de haber entrenado los modelos.
Después de construir las DMatrices, debes elegir un valor para el parámetro objective. Indica a XGBoost el problema de machine learning que intentas resolver y qué métricas o funciones de pérdida utilizar para resolverlo.
Por ejemplo, para prever el precio de los diamantes, que es un problema de regresión, puedes utilizar el objetivo común reg:squarederror. Normalmente, el nombre del objetivo también contiene el nombre de la función de pérdida del problema. Para la regresión, es habitual utilizar la desviación de la raíz cuadrada media, que minimiza la raíz cuadrada de la suma cuadrática de las diferencias entre los valores real y previsto. Este es el aspecto que tendría la métrica implementada en NumPy:
import numpy as np
mse = np.mean((actual - predicted) ** 2)
rmse = np.sqrt(mse)Aprenderemos los objetivos de clasificación más adelante en el tutorial.
Nota sobre la diferencia entre una función de pérdida y una métrica de rendimiento: Los modelos de machine learning utilizan una función de pérdida para minimizar las diferencias entre los valores reales (verdad fundamental) y las previsiones del modelo. Por otra parte, el ingeniero de machine learning elige una métrica (o métricas) para medir la similitud entre la verdad fundamental y las previsiones del modelo.
En resumen: una función de pérdida debe minimizarse, mientras que una métrica debe maximizarse. Durante el entrenamiento se utiliza una función de pérdida para guiar al modelo sobre dónde mejorar. Durante la evaluación se utiliza una métrica para medir el rendimiento global.
La función objetivo elegida y cualquier otro hiperparámetro de XGBoost deben especificarse en un diccionario, que, por convención, se llamará params:
# Define hyperparameters
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}Dentro de este params inicial, también configuramos tree_method como gpu_hist, lo que activa la aceleración de la GPU. Si no tienes GPU, puedes omitir el parámetro o configurarlo como hist.
Ahora, establecemos otro parámetro llamado num_boost_round, que significa número de rondas de boosting. Internamente, XGBoost minimiza la función de pérdida RMSE en pequeñas rondas incrementales (explicaremos más sobre esto después). Este parámetro especifica la cantidad de esas rondas.
El número ideal de rondas se halla ajustando los hiperparámetros. De momento, lo estableceremos como 100:
# Define hyperparameters
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 100
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
)Cuando XGBoost se ejecuta en una GPU, es rapidísimo. Si no has recibido ningún error del código anterior, el entrenamiento se ha realizado correctamente.
Durante las rondas de boosting, el objeto modelo ha aprendido todos los patrones posibles del conjunto de entrenamiento. Ahora, debemos medir su rendimiento probándolo con datos no vistos. Ahí es donde entra en juego nuestra dtest_reg DMatrix:
from sklearn.metrics import mean_squared_error
preds = model.predict(dtest_reg)Este paso del proceso se denomina evaluación (o inferencia) del modelo. Una vez generadas las previsiones con predict, las pasas a la función mean_squared_error de Sklearn para compararlas con y_test:
rmse = mean_squared_error(y_test, preds, squared=False)
print(f"RMSE of the base model: {rmse:.3f}")
RMSE of the base model: 543.203Tenemos una puntuación base de ~543$, que era el rendimiento de un modelo base con parámetros por defecto. Hay dos formas de mejorarla: realizando una validación cruzada y ajustando los hiperparámetros. Sin embargo, antes de eso, veamos una forma más rápida de evaluar los modelos XGBoost.
Entrenar un modelo de machine learning es como lanzar un cohete al espacio. Puedes controlar todo sobre el modelo hasta el lanzamiento, pero, después del lanzamiento, lo único que puedes hacer es quedarte quieto y esperar a que termine.
Sin embargo, el problema de nuestro proceso de entrenamiento actual es que ni siquiera podemos observar hacia dónde se dirige el modelo. Para solucionarlo, utilizaremos matrices de evaluación que nos permitan ver el rendimiento del modelo a medida que mejora incrementalmente a lo largo de las rondas de boosting.
En primer lugar, vamos a configurar de nuevo los parámetros:
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 100A continuación, creamos una lista de dos tuplas que contiene cada una dos elementos. El primer elemento es la matriz del modelo que se va a evaluar, y el segundo es el nombre de la matriz.
evals = [(dtrain_reg, "train"), (dtest_reg, "validation")]Cuando pasemos esta matriz al parámetro evals de xgb.train, veremos el rendimiento del modelo después de cada ronda de boosting:
evals = [(dtrain_reg, "train"), (dtest_reg, "validation")]
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
evals=evals,
)Deberías obtener una salida similar a la siguiente (acortada aquí a solo 10 filas). Puedes ver cómo el modelo minimiza la puntuación de ~3931$ a solo 543$.
Lo mejor es que podemos ver el rendimiento del modelo tanto en nuestro conjunto de entrenamiento como en el de validación. Normalmente, la pérdida de entrenamiento será menor que la de validación, puesto que el modelo ya ha visto la primera.
[0] train-rmse:3985.18329 validation-rmse:3930.52457
[1] train-rmse:2849.72257 validation-rmse:2813.20828
[2] train-rmse:2059.86648 validation-rmse:2036.66330
[3] train-rmse:1519.32314 validation-rmse:1510.02762
[4] train-rmse:1153.68171 validation-rmse:1153.91223
...
[95] train-rmse:381.93902 validation-rmse:543.56526
[96] train-rmse:380.97024 validation-rmse:543.51413
[97] train-rmse:380.75330 validation-rmse:543.36855
[98] train-rmse:379.65918 validation-rmse:543.42558
[99] train-rmse:378.30590 validation-rmse:543.20278En los proyectos del mundo real, sueles entrenar para miles de rondas de boosting, lo que significa que hay muchas filas de salida. Para reducirlas, puedes utilizar el parámetro verbose_eval, que obliga a XGBoost a imprimir las actualizaciones de rendimiento cada vebose_eval rondas:
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 100
evals = [(dtest_reg, "validation"), (dtrain_reg, "train")]
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
evals=evals,
verbose_eval=10 # Every ten rounds
)
[OUT]:
[0] train-rmse:3985.18329 validation-rmse:3930.52457
[10] train-rmse:550.08330 validation-rmse:590.15023
[20] train-rmse:488.51248 validation-rmse:551.73431
[30] train-rmse:463.13288 validation-rmse:547.87843
[40] train-rmse:447.69788 validation-rmse:546.57096
[50] train-rmse:432.91655 validation-rmse:546.22557
[60] train-rmse:421.24046 validation-rmse:546.28601
[70] train-rmse:408.64125 validation-rmse:546.78238
[80] train-rmse:396.41125 validation-rmse:544.69846
[90] train-rmse:386.87996 validation-rmse:543.82192
[99] train-rmse:378.30590 validation-rmse:543.20278A estas alturas, ya te habrás dado cuenta de lo importantes que son las rondas de boosting. En general, cuantas más rondas haya, más intentará XGBoost minimizar la pérdida. Sin embargo, esto no significa que la pérdida vaya a bajar siempre. Probemos con 5000 rondas de boosting con la prolijidad de 500:
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 5000
evals = [(dtest_reg, "validation"), (dtrain_reg, "train")]
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
evals=evals,
verbose_eval=250
)
[OUT]:
[0] train-rmse:3985.18329 validation-rmse:3930.52457
[500] train-rmse:195.89184 validation-rmse:555.90367
[1000] train-rmse:122.10746 validation-rmse:563.44888
[1500] train-rmse:84.18238 validation-rmse:567.16974
[2000] train-rmse:61.66682 validation-rmse:569.52584
[2500] train-rmse:46.34923 validation-rmse:571.07632
[3000] train-rmse:37.04591 validation-rmse:571.76912
[3500] train-rmse:29.43356 validation-rmse:572.43196
[4000] train-rmse:24.00607 validation-rmse:572.81287
[4500] train-rmse:20.45021 validation-rmse:572.89062
[4999] train-rmse:17.44305 validation-rmse:573.13200
Obtenemos la pérdida más baja antes de la ronda 500. Después, aunque la pérdida de entrenamiento siga bajando, la pérdida de validación (la que nos importa) sigue aumentando.
Cuando se le dan un número innecesario de rondas de boosting, XGBoost empieza a sobreajustarse y a memorizar el conjunto de datos. Esto, a su vez, provoca una caída del rendimiento de la validación porque el modelo está memorizando en lugar de generalizando.
Recuerda que queremos el término medio: un modelo que haya aprendido suficientes patrones en el entrenamiento como para ofrecer el mayor rendimiento en el conjunto de validación. Entonces, ¿cómo hallamos el número perfecto de rondas de boosting?
Utilizaremos una técnica llamada parada anticipada. La parada anticipada obliga a XGBoost a vigilar la pérdida de validación y, si deja de mejorar durante un número especificado de rondas, deja de entrenar automáticamente.
Esto significa que podemos establecer un número elevado de rondas de boosting siempre que establezcamos un número razonable de rondas de parada anticipada.
Por ejemplo, utilicemos 10 000 rondas de boosting y establezcamos el parámetro early_stopping_rounds como 50. De este modo, XGBoost detendrá automáticamente el entrenamiento si la pérdida de validación no mejora durante 50 rondas consecutivas.
n = 10000
model = xgb.train(
params=params,
dtrain=dtrain_reg,
num_boost_round=n,
evals=evals,
verbose_eval=50,
# Activate early stopping
early_stopping_rounds=50
)
[OUT]:
[0] train-rmse:3985.18329 validation-rmse:3930.52457
[50] train-rmse:432.91655 validation-rmse:546.22557
[100] train-rmse:377.66173 validation-rmse:542.92457
[150] train-rmse:334.27548 validation-rmse:542.79733
[167] train-rmse:321.04059 validation-rmse:543.35679Como puedes ver, el entrenamiento se detuvo después de la 167.ª ronda porque la pérdida dejó de mejorar durante 50 rondas.
Al principio del tutorial, reservamos el 25 % del conjunto de datos para las pruebas. El conjunto de prueba nos permitiría simular las condiciones de un modelo en producción, donde debe generar previsiones para datos no vistos.
Sin embargo, un único conjunto de prueba no bastaría para medir con precisión cómo se comportaría un modelo en la producción. Por ejemplo, si realizamos el ajuste de hiperparámetros utilizando un único conjunto de entrenamiento y un único conjunto de prueba, los conocimientos sobre el conjunto de prueba seguirían "filtrándose". ¿Cómo?
Como intentamos hallar el mejor valor de un hiperparámetro comparando el rendimiento de validación del modelo en el conjunto de prueba, acabaremos con un modelo configurado para rendir bien solo en ese conjunto de prueba concreto. En lugar de eso, queremos un modelo que funcione bien en todos los ámbitos, en cualquier conjunto de prueba que le propongamos.
Una posible solución consiste en dividir los datos en tres conjuntos. El modelo se entrena con el primer conjunto, el segundo se utiliza para la evaluación y el ajuste de hiperparámetros y el tercero es el último, en el que probamos el modelo antes de la producción.
Sin embargo, cuando los datos son limitados, dividirlos en tres conjuntos hará que el conjunto de entrenamiento sea escaso, lo que perjudica al rendimiento del modelo.
La solución a todos estos problemas es la validación cruzada. En la validación cruzada, seguimos teniendo dos conjuntos: de entrenamiento y de prueba.
Mientras el conjunto de prueba espera en la esquina, dividimos el de entrenamiento en 3, 5, 7 o k divisiones o pliegues. A continuación, entrenamos el modelo k veces. Cada vez, utilizamos k-1 partes para el entrenamiento y la k-ésimaparte final para la validación. Este proceso se denomina validación cruzada de k pliegues:
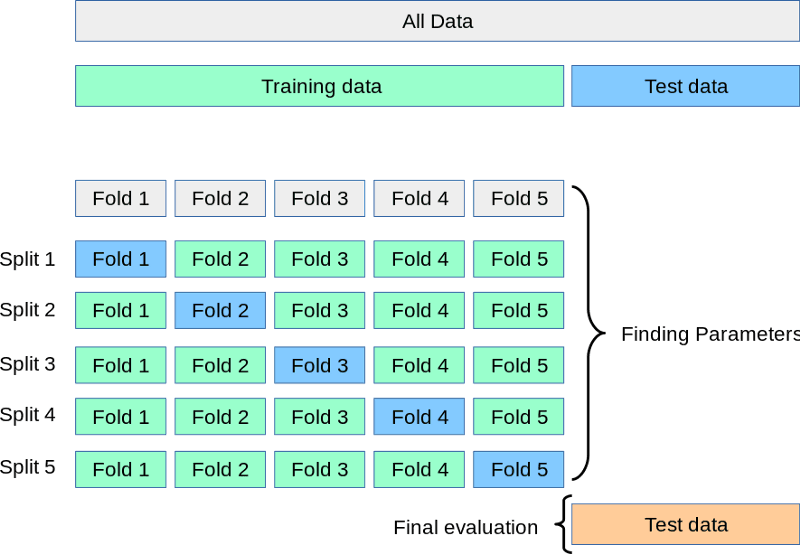
Fuente: https://scikit-learn.org/stable/modules/cross_validation.html
Arriba tienes una representación visual de una validación cruzada de 5 pliegues. Una vez realizados todos los pliegues, podemos tomar la media de las puntuaciones como el rendimiento final más realista del modelo.
Vamos a realizar este proceso en código utilizando la función cv de XGB:
params = {"objective": "reg:squarederror", "tree_method": "gpu_hist"}
n = 1000
results = xgb.cv(
params, dtrain_reg,
num_boost_round=n,
nfold=5,
early_stopping_rounds=20
)La única diferencia con la función de entrenamiento es añadir el parámetro nfold para especificar el número de divisiones. El objeto de resultados es ahora un DataFrame que contiene los resultados de cada pliegue:
results.head()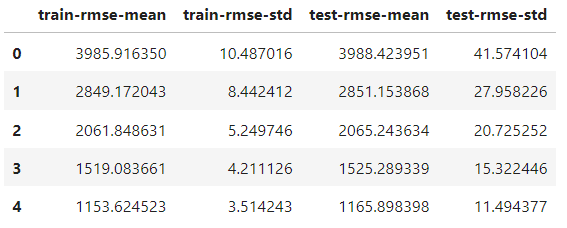
Tiene el mismo número de filas que el número de rondas de boosting. Cada fila es la media de todas las divisiones de esa ronda. Por tanto, para hallar la mejor puntuación, tomamos el mínimo de la columna test-rmse-mean:
best_rmse = results['test-rmse-mean'].min()
best_rmse
550.8959336674216Ten en cuenta que este método de validación cruzada se utiliza para ver el verdadero rendimiento del modelo. Una vez satisfecho con su puntuación, debes volver a entrenarlo con todos los datos antes de implementarlo.
Construir un clasificador XGBoost es tan fácil como cambiar la función objetivo; el resto puede permanecer igual.
Los dos objetivos de clasificación más populares son:
binary:logistic: clasificación binaria (el objetivo solo contiene dos clases, es decir, gato o perro)multi:softprob: clasificación multiclase (más de dos clases en el objetivo, es decir, manzana/naranja/plátano)Realizar una clasificación binaria y multiclase en XGBoost es casi igual, por lo que optaremos por esta última. Preparemos primero los datos para la tarea.
Queremos prever la calidad de corte de los diamantes dado su precio y sus medidas físicas. Por tanto, construiremos las matrices característica/objetivo en consecuencia:
from sklearn.preprocessing import OrdinalEncoder
X, y = diamonds.drop("cut", axis=1), diamonds[['cut']]
# Encode y to numeric
y_encoded = OrdinalEncoder().fit_transform(y)
# Extract text features
cats = X.select_dtypes(exclude=np.number).columns.tolist()
# Convert to pd.Categorical
for col in cats:
X[col] = X[col].astype('category')
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y_encoded, random_state=1, stratify=y_encoded)La única diferencia es que, como XGBoost solo acepta números en el objetivo, codificamos las clases de texto en el objetivo con OrdinalEncoder de Sklearn.
Ahora, construimos las DMatrices...
# Create classification matrices
dtrain_clf = xgb.DMatrix(X_train, y_train, enable_categorical=True)
dtest_clf = xgb.DMatrix(X_test, y_test, enable_categorical=True)... y establecemos el objetivo como multi:softprob. Este objetivo también requiere que establezcamos el número de clases:
params = {"objective": "multi:softprob", "tree_method": "gpu_hist", "num_class": 5}
n = 1000
results = xgb.cv(
params, dtrain_clf,
num_boost_round=n,
nfold=5,
metrics=["mlogloss", "auc", "merror"],
)Durante la validación cruzada, pedimos a XGBoost que observe tres métricas de clasificación que informan del rendimiento del modelo desde tres ángulos diferentes. He aquí el resultado:
results.keys()
Index(['train-mlogloss-mean', 'train-mlogloss-std', 'train-auc-mean',
'train-auc-std', 'train-merror-mean', 'train-merror-std',
'test-mlogloss-mean', 'test-mlogloss-std', 'test-auc-mean',
'test-auc-std', 'test-merror-mean', 'test-merror-std'],
dtype='object')Para ver la mejor puntuación AUC, tomamos el máximo de la columna test-auc-mean:
>>> results['test-auc-mean'].max()
0.9402233623451636Incluso la configuración por defecto nos dio un 94 % de rendimiento, lo cual es estupendo.
Hasta ahora, hemos utilizado la API nativa de XGBoost, pero su API Sklearn también es bastante popular.
Sklearn es un vasto marco con muchas utilidades y algoritmos de machine learning y tiene una sintaxis de API que le encanta a casi todo el mundo. Por lo tanto, XGBoost también ofrece las clases XGBClassifier y XGBRegressor para que puedan integrarse en el ecosistema Sklearn (a costa de perder parte de la funcionalidad).
Si quieres utilizar únicamente la API Scikit-learn siempre que sea posible y cambiar a la nativa solo cuando tengas que acceder a funciones adicionales, hay una forma de hacerlo.
Después de entrenar el clasificador o regresor XGBoost, puedes convertirlos utilizando el método get_booster:
import xgboost as xgb
# Train a model using the scikit-learn API
xgb_classifier = xgb.XGBClassifier(n_estimators=100, objective='binary:logistic', tree_method='hist', eta=0.1, max_depth=3, enable_categorical=True)
xgb_classifier.fit(X_train, y_train)
# Convert the model to a native API model
model = xgb_classifier.get_booster()El objeto modelo se comportará exactamente como hemos visto a lo largo de este tutorial.
Hemos tratado muchos temas importantes en este tutorial sobre XGBoost, pero aún quedan muchas cosas por aprender.
Puedes consultar la página de parámetros XGBoost, que te enseña a configurar los parámetros para aprovechar al máximo el rendimiento de tus modelos.
Si buscas un recurso completo todo en uno para aprender la biblioteca, consulta nuestro curso Extreme Gradient Boosting con XGBoost.
Más información sobre Python y XGBoost
Curso
Curso
Curso
Tutorial
Avinash Navlani
Tutorial
Avinash Navlani
Tutorial
Moez Ali
Tutorial
Avinash Navlani
Tutorial
DataCamp Team
Tutorial
Joleen Bothma

