programa
Ingeniero de datos en Python
40 h
El aprendizaje automático tradicional implica llevar los datos desde las bases de datos hasta donde están los modelos. Con el reciente auge de la IA y el enorme tamaño de los conjuntos de datos actuales, este enfoque es cada vez menos práctico.
Hay que transferir terabytes de datos de la base de datos a las aplicaciones del lado del cliente para su limpieza, análisis y entrenamiento del modelo. Este viaje de ida y vuelta, aparentemente inocente, desperdicia recursos valiosos. Por esta razón, cada vez más empresas eligen tecnologías en la base de datos para minimizar el movimiento de datos y realizar operaciones de datos sin problemas.
Una de las mejores tecnologías en bases de datos del mercado es Snowpark, ofrecida por Snowflake Cloud. Snowpark es un conjunto de bibliotecas y tiempos de ejecución que te permite ejecutar de forma segura lenguajes de programación en Snowflake Cloud para desarrollar canalizaciones de datos y modelos de aprendizaje automático en el mismo entorno que tus bases de datos Snowflake.
En este tutorial, hablaremos de los fundamentos de Snowpark y de cómo puedes utilizarlo en tus proyectos. Suponemos que ya estás familiarizado con SQL y Snowflake; si necesitas cubrirlos primero, puedes seguir nuestro Curso de Conocimientos Fundamentales de SQL o leer este Tutorial de Snowflake para principiantes.
¡Empecemos!
Snowflake Snowpark es un conjunto de bibliotecas y tiempos de ejecución que te permite utilizar de forma segura lenguajes de programación como Python, Java y Scala para procesar datos directamente dentro de la plataforma en la nube de Snowflake.
Esto elimina la necesidad de mover los datos fuera de Snowflake para su procesamiento, mejorando la eficacia y la seguridad. He aquí algunas de sus principales ventajas:
En pocas palabras, Snowpark es una forma potente y sencilla para que los desarrolladores construyan canalizaciones de datos, soluciones de aprendizaje automático y aplicaciones basadas en datos directamente en Snowflake Cloud.
Nuestro objetivo final en este tutorial es construir un modelo hiperparamétrico entrenado en una tabla de una base de datos Snowflake utilizando Snowpark. Para ello, empezaremos por:
Para este tutorial, utilizaremos un nuevo entorno conda:
$ conda create -n snowpark python==3.10 -y
$ conda activate snowparkComo nota al margen, si estás ejecutando en un entorno conda recién instalado, tendrás que ejecutar $conda init antes de activar el entorno snowpark.
Tras la activación, necesitamos instalar las siguientes bibliotecas:
$ pip install snowflake-snowpark-python #The Snowpark API
$ pip install pandas pyarrow numpy matplotlib seabornSi vas a utilizar Jupyter, instala también ipykernel y ejecuta el siguiente comando para que el entorno que estamos utilizando se añada como núcleo de Jupyter:
$ pip install ipykernel
$ ipython kernel install --user --name=snowparkAhora vamos a importar algunas bibliotecas generales que necesitaremos por el camino:
import warnings
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
warnings.filterwarnings("ignore")Para este tutorial, utilizaremos el conjunto de datos Diamonds de Seaborn; puedes descargar el archivo CSV directamente de mi GitHub.
Una vez que te conectes a la aplicación Snowflake, sigue el GIF que aparece a continuación para ingerir el conjunto de datos en una nueva tabla de la base de datos (crea una cuenta nueva si aún no tienes una):
En la práctica, raramente importarás archivos CSV como tablas en tus bases de datos Snowflake. La mayoría de las veces, trabajarás con bases de datos existentes con distintos niveles de acceso que te concederán los administradores de bases de datos de tu empresa.
Ahora, debemos establecer una conexión entre la API de Snowpark y la nube de Snowflake para consultar nuestra base de datos. Esta conexión requiere las siguientes credenciales de Snowflake: nombre de cuenta, nombre de usuario y contraseña.
En la imagen siguiente, te muestro cómo puedes recuperar tu nombre de usuario y de cuenta del panel de Snowflake:
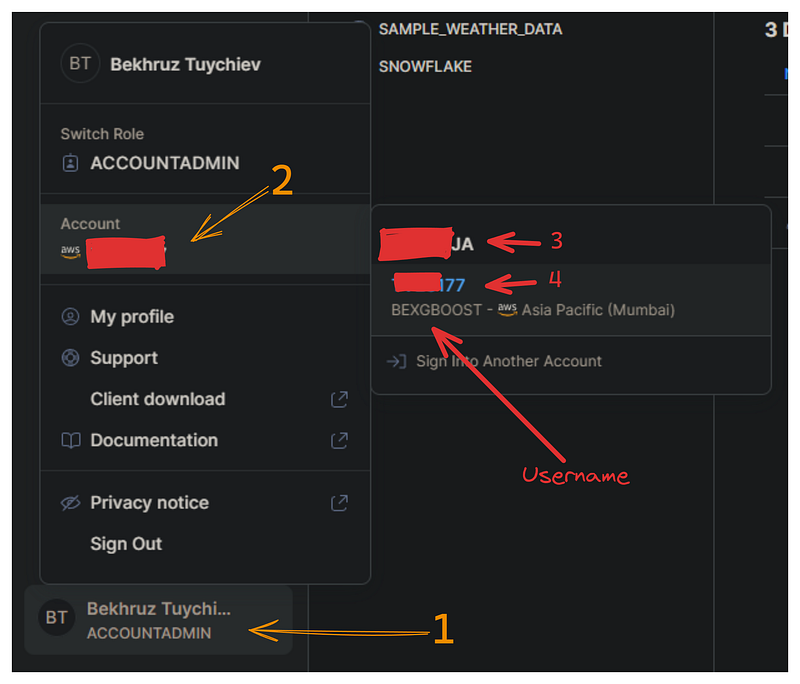
Crea un archivo independiente llamado config.py que contenga un único diccionario llamado credentials con el siguiente formato:
credentials = (
{
"account": "3-4", # Combine 3 and 4 with a hyphen
"username": "bexgboost", # Your username in lowercase
"password": "your_password", # Your Snowflake password
},
)Por razones de seguridad, almacenamos las credenciales en un archivo separado. Añadir este archivo a .gitignore garantiza que tus credenciales de Snowflake no se filtren accidentalmente.
Ahora, importamos el diccionario credentials y la clase Session de Snowpark:
from config import credentials
from snowflake.snowpark import SessionPara establecer una conexión, utilizaremos el método Session.builder.configs.create():
connection_parameters = {
"account": credentials["account"],
"user": credentials["username"],
"password": credentials["password"],
}
new_session = Session.builder.configs(connection_parameters).create()
new_session.get_current_user()'"bexgboost"'Si se imprime tu nombre de usuario, ¡tu primera sesión se ha creado correctamente!
El objeto new_session tiene acceso a todo lo que tu cuenta posee en Snowflake (y a lo que tienes permiso para acceder).
El primer paso que daremos antes de importar los datos es indicar a la sesión que estamos utilizando la base de datos test_db que hemos creado en el apartado anterior:
new_session.sql("USE DATABASE test_db;").collect()[Row(status='Statement executed successfully.')]Para ello utilizamos el método .sql, que nos permite ejecutar cualquier consulta compatible con SQL de Snowflake.
Ahora, podemos cargar la tabla diamonds de test_db utilizando el método table del objeto de sesión:
diamonds_df = new_session.table("diamonds")
diamonds_df.show(5)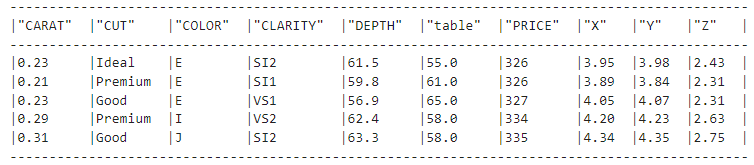
El método .show() es el equivalente al de Pandas DataFrame.describe(), y nos muestra que nos hemos conectado con éxito a la tabla.
Así es: sólo nos conectamos a la mesa de diamantes. El objeto diamonds_df no contiene ningún dato, como demuestra su tamaño:
import sys
sys.getsizeof(diamonds_df)48Sólo tiene 48 bytes, cuando debería tener más de 3 MB. Dediquemos un poco más de tiempo a comprender por qué ocurre esto.
Hasta ahora, hemos cubierto los siguientes pasos:
¡Hablemos ahora de los DataFrames de Snowpark!
Los DataFrames de Pandas utilizan tu RAM, lo que significa que viven en tu máquina. En comparación, los DataFrames de Snowpark viven dentro de la plataforma en la nube de Snowflake, aunque puedes ver su representación en tu entorno de codificación. Los datos permanecen en la nube y no es necesario descargarlos en tu máquina local para hacer operaciones con ellos.
Otro aspecto importante de los DataFrames de Snowpark es que funcionan de forma perezosa. Esto significa que no ejecutan ninguna operación sobre los datos hasta que tú se lo indiques específicamente.
En su lugar, construyen una representación lógica de las operaciones deseadas que luego se traducen en consultas SQL optimizadas para que Snowflake las ejecute.
En comparación, Pandas ejecuta las operaciones inmediatamente, es decir, realiza una ejecución ansiosa.
Desde el punto de vista del rendimiento, la evaluación perezosa siempre es significativamente más rápida que la ejecución ansiosa. Como los lazy DataFrames utilizan los potentes recursos informáticos elásticos de Snowflake, pueden empujar las operaciones al nivel de la base de datos y ejecutarse mucho más rápido.
Para comprender mejor la diferencia entre la evaluación perezosa y la ejecución ansiosa, imagina que nuestros datos en Snowflake son una biblioteca gigante. Tenemos los dos supuestos siguientes:
Dado que Snowpark puede convertir a Pandas DataFrames, ¿cuándo debemos utilizar uno sobre el otro?
pandas_diamonds = diamonds_df.to_pandas()
pandas_diamonds.head()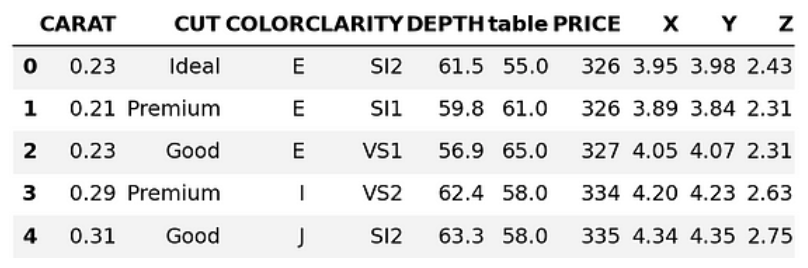
La respuesta depende en gran medida del tamaño del conjunto de datos.
Si tu conjunto de datos es pequeño (como el conjunto de datos Diamonds), puedes descargarlo localmente e introducirlo en Pandas sin problemas (que es lo que hace el método DataFrame.to_pandas() ).
Pero con los conjuntos de datos actuales, las cosas pueden irse rápidamente de las manos y puede que tengamos que esperar horas a que se descargue nuestra base de datos. Y recuerda que es un billete de ida y vuelta: cualquier dato nuevo que queramos conservar también debe ser enviado de vuelta. Y eso es lo que hace que aprender la API del DataFrame de Snowpark sea tan valioso.
Alternativamente, el método Session.sql() nos permite ejecutar cualquier expresión SQL compatible con Snowflake (véase el ejemplo siguiente). Sin embargo, recomiendo encarecidamente dominar la API de Snowpark DataFrame, porque tiene muchas funciones integradas para más de 100 funciones y expresiones SQL.
result = new_session.sql(
"""
SELECT PRICE, CUT FROM DIAMONDS LIMIT 10
"""
)
type(result)
snowflake.snowpark.dataframe.DataFrameresult.show()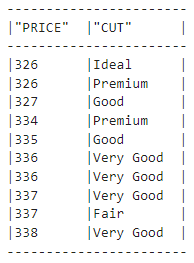
Gran parte de tu tiempo en Snowpark lo pasarás utilizando sus funciones de transformación. Están disponibles en el siguiente submódulo:
# The convention is to import it as F
import snowflake.snowpark.functions as FTodas las funciones bajo F (que puedes listar llamando a dir(F)) especifican cómo debe transformarse un Marco de datos. Veamos un ejemplo:
F.upper(F.col("CUT"))Aquí, la función col crea una referencia a la columna dada y devuelve un objeto Column. A continuación, .upper() convierte los valores de la columna CUT a mayúsculas:
diamonds_df.show(5)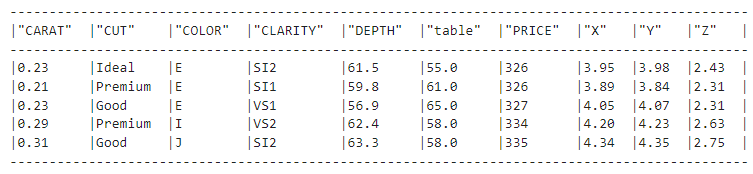
Pero si miramos el conjunto de datos de los diamantes, vemos que los valores de la columna CUT siguen teniendo letras minúsculas. ¿Por qué? Pues bien, la expresión F.upper(F.col("CUT")) equivale a la siguiente consulta SQL:
SELECT UPPER(CUT);¿Qué falta aquí?
Por supuesto, ¡la cláusula FROM que especifica el nombre de la tabla a la que debe aplicarse la transformación!
Por tanto, debemos combinar la expresión F.upper(F.col("CUT")) con el objeto diamonds_df. Hay tres formas principales de hacerlo:
.select().filter().with_column()Como nuestra expresión transforma una columna, la pasaremos a .select():
our_expression = F.upper(F.col("CUT"))
diamonds_df.select(our_expression).show()
¡Hemos cambiado los valores con éxito!
Escribamos ahora una expresión que filtre las filas:
diamonds_df.filter(F.col("PRICE") > 10000).count()5222Descubrimos que hay más de 5.000 diamantes en nuestro conjunto de datos que cuestan más de 10.000 $. Intentemos crear también una columna:
(
diamonds_df.with_column("PRICE_SQUARED", F.col("PRICE") ** 2)
.select("PRICE", "PRICE_SQUARED")
.show(5)
)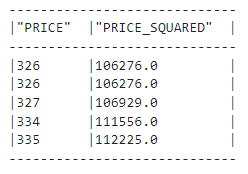
Arriba, mostramos que los métodos de encadenamiento también están permitidos: tenemos una nueva columna llamada "PRECIO_CUADRADO". Vemos que las funciones de Snowpark DataFrame son similares a las de Pandas.
En resumen, si buscas una alternativa de Snowpark a una función de Pandas, está en F o forma parte de los métodos de Snowpark DataFrames. Puedes comprobarlo llamando a dir(F) o dir(diamonds_df) o leyendo la referencia Snowpark Python.
Una parte importante de la realización del análisis exploratorio de datos (AED) es la creación de elementos visuales. Por suerte para nosotros, no necesitamos Snowpark para esto porque podemos seguir utilizando la pila de datos moderna.
Esta es la idea : Como en EDA se trata de descubrir tendencias y perspectivas generales, a menudo podemos utilizar una muestra en lugar de todo el conjunto de datos. Una vez que descarguemos una muestra representativa, podemos convertirla a Pandas DataFrame y utilizar los buenos y viejos Matplotlib o Seaborn.
Empecemos por la conversión:
sample = diamonds_df.sample(0.25).to_pandas()
sample.head()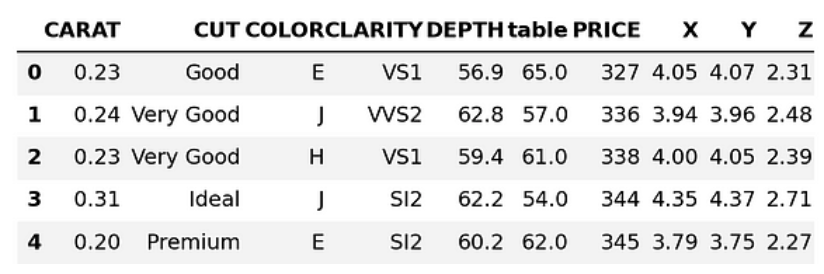
Arriba, estamos descargando el 25% del conjunto de datos como un Pandas DataFrame. Vamos a convertir los nombres de las columnas a minúsculas:
sample.columns = [col.lower() for col in sample.columns]
sample.columnsIndex(['carat', 'cut', 'color', 'clarity', 'depth', 'table', 'price', 'x', 'y', 'z'], dtype='object')Ahora, puedes hacer EDA como lo harías con cualquier conjunto de datos. A continuación, exploramos algunas ideas posibles y empezamos generando un diagrama de dispersión para visualizar la relación entre precio y quilate:
#Remember we imported seaborn as sns
sns.scatterplot(data=sample, x="price", y="carat", s=1)
plt.title("Diamond prices vs. carat")
plt.show()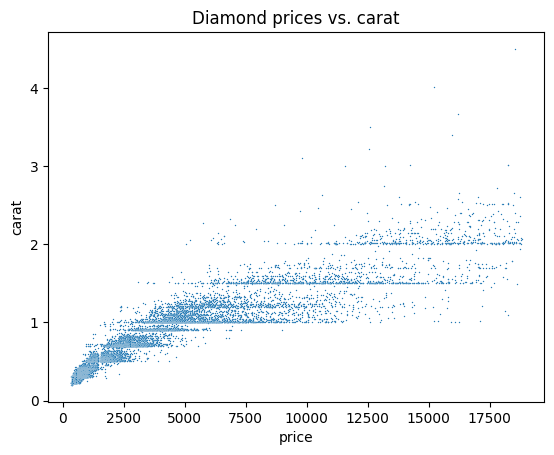
Vamos a trazar ahora una matriz de correlaciones para ver la correlación entre cada par de características numéricas:
corr_matrix = sample.corr(numeric_only=True)
sns.heatmap(corr_matrix, center=0, square=True, annot=True
plt.title("The correlation matrix of Diamond numeric features")
plt.show()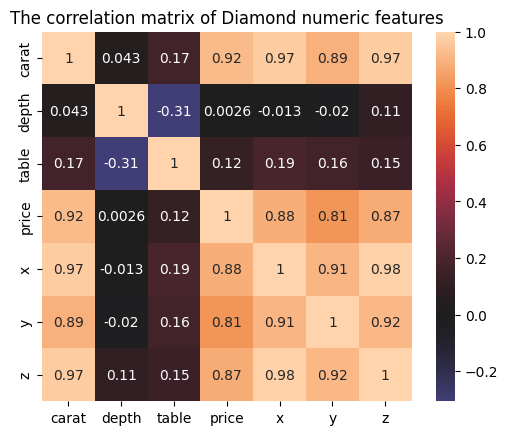
También podríamos crear un diagrama de barras de las categorías de talla de diamante:
cut_counts = sample.groupby("cut")["cut"].count()
cut_counts.plot(kind="bar")
plt.title("Category counts of diamond cuts")
plt.xlabel("Diamond cut")
plt.show()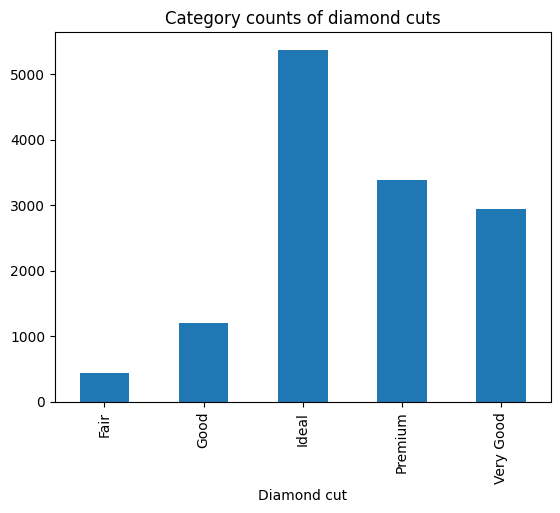
Para confirmar que estos gráficos serán aproximadamente iguales en todo el conjunto de datos, ejecutaremos la versión SQL del gráfico de barras anterior.
En primer lugar, escribiremos una expresión SQL para agrupar el conjunto de datos de diamantes por CUT:
result = new_session.sql(
"""
SELECT cut, COUNT(*) AS count
FROM diamonds
GROUP BY cut;
"""
)
Ahora vamos a convertir y descargar el resultado como un DataFrame Pandas:
result_pd = result.to_pandas()
result_pd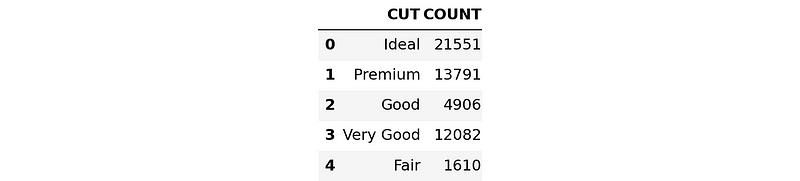
Esta vez, utilizaremos la función plt.bar() para crear el gráfico:
plt.bar(x=result_pd["CUT"], height=result_pd["COUNT"])
plt.show()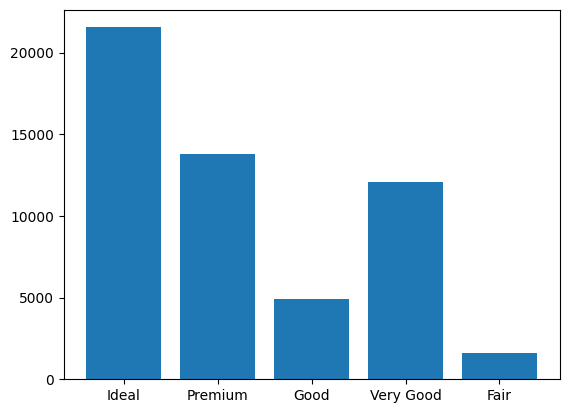
El orden de las barras es diferente, pero al mirarlas una al lado de la otra se observa que transmiten la misma información.
¡Ya estamos listos para aprender a entrenar modelos de aprendizaje automático en Snowpark!
Empezaremos por limpiar el conjunto de datos.
Primero, asegurémonos de que todas las columnas tienen el tipo de datos correcto:
list(diamonds_df.schema)[StructField('CARAT', DecimalType(38, 2), nullable=True),
StructField('CUT', StringType(16777216), nullable=True),
StructField('COLOR', StringType(16777216), nullable=True),
StructField('CLARITY', StringType(16777216), nullable=True),
StructField('DEPTH', DecimalType(38, 1), nullable=True),
StructField('"table"', DecimalType(38, 1), nullable=True),
StructField('PRICE', LongType(), nullable=True),
StructField('X', DecimalType(38, 2), nullable=True),
StructField('Y', DecimalType(38, 2), nullable=True),
StructField('Z', DecimalType(38, 2), nullable=True)]La columna table tiene un nombre raro, así que la convertiremos a mayúsculas TABLE_ (con un guión bajo al final para que no choque con una palabra clave SQL incorporada):
diamonds_df = diamonds_df.with_column_renamed('"table"', "TABLE_")
diamonds_df.columns['CARAT', 'CUT', 'COLOR', 'CLARITY', 'DEPTH', 'TABLE_', 'PRICE', 'X', 'Y', 'Z']Tendremos que cambiar el tipo de datos de las características numéricas de DecimalType a DoubleType porque Snowpark aún no admite decimales.
from snowflake.snowpark.types import DoubleType
numeric_features = ["CARAT", "X", "Y", "Z", "DEPTH", "TABLE_"]
for col in numeric_features:
diamonds_df = diamonds_df.with_column(col, diamonds_df[col].cast(DoubleType()))
list(diamonds_df.select(*numeric_features))[Column("CARAT"),
Column("X"),
Column("Y"),
Column("Z"),
Column("DEPTH"),
Column("TABLE_")]En el fragmento anterior, volvemos a utilizar el método .with_column(). Otro método nuevo es .cast(), que forma parte de los métodos de Snowpark DataFrames.
Snowpark también exige que todas las características del texto estén en mayúsculas y no tengan espacios entre las palabras antes de codificarlas. Actualmente, los valores de la función CUT incumplen este requisito, así que lo arreglaremos con transformaciones de funciones:
import snowflake.snowpark.functions as F
def remove_space_and_upper(df):
df = df.with_column("CUT", F.upper(F.replace(F.col("CUT"), " ", "_")))
return df
diamonds_df = remove_space_and_upper(diamonds_df)
Ahora nuestros datos están libres de problemas de limpieza. Podemos volver a guardarla como una nueva tabla en Copo de Nieve:
diamonds_df.write.mode("overwrite").save_as_table("diamonds_cleaned")Asegúrate de añadir el modo overwrite, ya que puede que tengas que volver atrás y cambiar algunas operaciones de limpieza y volver a guardar.
En esta sección, abordaremos cualquier problema de preprocesamiento que pueda impedir el entrenamiento de los modelos. Carguemos la tabla depurada del apartado anterior:
clean_df = new_session.table("diamonds_cleaned")
clean_df.show()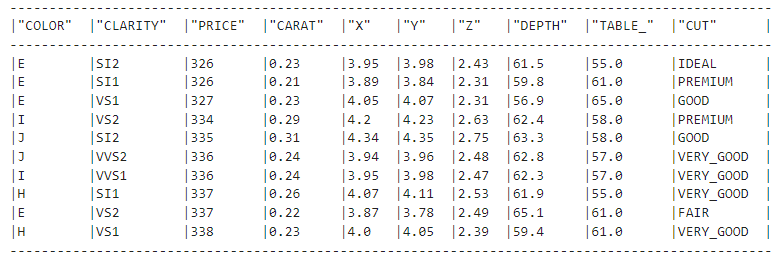
¡Muy bien!
A continuación, importaremos los submódulos preprocessing y pipeline del espacio de nombres snowflake.ml.
import snowflake.ml.modeling.preprocessing as snowml
from snowflake.ml.modeling.pipeline import PipelineMientras que la API DataFrame de Snowpark está disponible en snowflake.snowpark, los módulos ML de Snowpark están presentes en snowflake.ml. Al principio puede resultar confuso, así que tómate tu tiempo para acostumbrarte.
En el código siguiente
# List all the features for processing
cat_cols = ["CUT", "COLOR", "CLARITY"]
cat_cols_encoded = ["CUT_OE", "COLOR_OE", "CLARITY_OE"]
# We already have numeric_features
# List the correct ordering of categorical features
categories = {
"CUT": np.array(["IDEAL", "PREMIUM", "VERY_GOOD", "GOOD", "FAIR"]),
"CLARITY": np.array(
["IF", "VVS1", "VVS2", "VS1", "VS2", "SI1", "SI2", "I1", "I2", "I3"]
),
"COLOR": np.array(["D", "E", "F", "G", "H", "I", "J"]),
}Ahora estamos preparados para construir un pipeline similar a un pipeline Scikit-learn:
# Build the pipeline
preprocessing_pipeline = Pipeline(
steps=[
(
"OE",
snowml.OrdinalEncoder(
input_cols=cat_cols, output_cols=cat_cols_encoded, categories=categories
),
),
(
"SS",
snowml.StandardScaler(
input_cols=numeric_features, output_cols=numeric_features
),
),
]
)
La clase Pipeline acepta una lista de pasos, cada uno de los cuales es una clase de preprocesamiento. Aquí, estamos utilizando OrdinalEncoder para codificar los categóricos como 0, 1, 3, etc. y StandardScaler para normalizar los rasgos numéricos.
Al final, guardaremos el pipeline localmente con joblib y lo probaremos en todo el conjunto de datos:
import joblib
PIPELINE_FILE = "pipeline.joblib"
# Pickle locally first
joblib.dump(preprocessing_pipeline, PIPELINE_FILE)
transformed_diamonds_df = preprocessing_pipeline.fit(clean_df).transform(clean_df)
# transformed_diamonds_df.show() - commented because of long outputEl fragmento se ejecuta sin errores, por lo que nuestra canalización funciona, lo que indica que por fin podemos entrenar un modelo.
Para entrenar un modelo, volveremos a enumerar los nombres de las características y los nombres de los objetivos:
# Define the columns again
cat_cols_encoded = ["CUT_OE", "COLOR_OE", "CLARITY_OE"]
numeric_features = ["CARAT", "X", "Y", "Z", "DEPTH", "TABLE_"]
label_cols = ["PRICE"] # Must be a list
output_cols = ["PRICE_PREDICTED"] # Required in snowparkAhora dividiremos los datos utilizando DataFrame.random_split() y daremos pesos para representar la fracción de conjuntos de entrenamiento y de prueba:
# Split the data
train_df, test_df = diamonds_df.random_split(weights=[0.8, 0.2], seed=42)A continuación, cargaremos la canalización y ajustaremos la transformación de los conjuntos de entrenamiento y de prueba.
# Load the pre-processing pipeline locally
pipeline = joblib.load("pipeline.joblib")
# Apply it to both dataframes
train_df_transformed = pipeline.fit(train_df).transform(train_df)
test_df_transformed = pipeline.transform(test_df)Por encima, asegúrate de que sólo llamas a .transform() en el conjunto de pruebas para evitar la fuga de datos.
A continuación, inicializamos un modelo regresor XGBoost a partir de ml.modeling.xgboost sub-module:
# Snowpark has models from scikit-learn and lightgbm too
from snowflake.ml.modeling.xgboost import XGBRegressor
# Initialize
regressor = XGBRegressor(
input_cols=cat_cols_encoded + numeric_features,
label_cols=label_cols,
output_cols=output_cols,
)La clase XGBRegressor requiere todos los nombres de entrada, todos los nombres de destino y los nombres de las columnas de salida. Una vez introducidos, llamamos a .fit() para iniciar el proceso de entrenamiento:
# Train
regressor.fit(train_df_transformed)El entrenamiento puede funcionar lentamente si tienes una cuenta gratuita de Snowflake con recursos informáticos limitados y sin GPU.
Una vez finalizado el entrenamiento, podemos generar predicciones:
# Predecir
train_preds = regressor.predict(train_df_transformed)
test_preds = regressor.predict(test_df_transformed)Echemos un vistazo a las predicciones:
train_preds.select("PRICE", "PRICE_PREDICTED").show(5)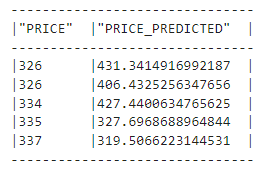
Ahora tenemos que medir lo bien que funcionó nuestro modelo inicial. Snowpark incluye docenas de métricas de Scikit-learn en su submódulo ml.modeling.metrics que importamos como M:
import snowflake.ml.modeling.metrics as MA continuación, ejecutamos mean_squared_error dos veces para medir el error cuadrático medio (RMSE) en los conjuntos de entrenamiento y de prueba (a continuación, squared=False devuelve RMSE en lugar de MSE):
rmse_train = M.mean_squared_error(
df=train_preds,
y_true_col_names=label_cols,
y_pred_col_names=output_cols,
squared=False,
)
rmse_test = M.mean_squared_error(
df=test_preds,
y_true_col_names=label_cols,
y_pred_col_names=output_cols,
squared=False,
)
print(f"Train RMSE score for XGBRegressor: {rmse_train:.4f}")
print(f"Test RMSE score for XGBRegressor: {rmse_test:.4f}")Train RMSE score for XGBRegressor: 371.9664
Test RMSE score for XGBRegressor: 542.1566Nuestro modelo tiene un error medio de 542 $, y también podría estar sobreajustándose un poco, porque la diferencia entre los RMSE de entrenamiento y de prueba es grande.
Afinemos los hiperparámetros del modelo para abordar estas cuestiones.
Actualmente, Snowpark ofrece dos clases de ajuste de hiperparámetros:
GridSearchCV: búsqueda exhaustiva de todas las combinaciones de hiperparámetros con validación cruzada.RandomizedSearchCVBúsqueda aleatoria de distribuciones de hiperparámetros dadas con validación cruzada.XGBoost dispone de una docena de hiperparámetros que pueden mejorar su rendimiento (puedes obtener más información en este tutorial sobre el uso de XGBoost en Python). Esto nos empuja a hacer una búsqueda aleatoria. Personalmente, preferiría utilizar Optuna, que utiliza la búsqueda bayesiana, pero en Snowpark aún no nos podemos permitir ese lujo.
Definamos ahora la búsqueda:
from snowflake.ml.modeling.model_selection import RandomizedSearchCV
rscv = RandomizedSearchCV(
estimator=XGBRegressor(),
param_distributions={
"n_estimators": [2000],
"max_depth": list(range(3, 13)),
"learning_rate": np.linspace(0.1, 0.5, num=10),
},
n_jobs=-1,
scoring="neg_mean_squared_error",
input_cols=numeric_features + cat_cols_encoded,
label_cols=label_cols,
output_cols=output_cols,
n_iter=10,
)
rscv.fit(train_df_transformed)
Fijamos el número de estimadores en 2000 y sólo ajustamos los parámetros max_depth y learning_rate. El rscv tiene un parámetro por defecto de n_iter=10, lo que significa que la búsqueda se realizará 10 veces, eligiendo cada vez una combinación aleatoria de parámetros. Para obtener resultados más precisos, es mejor elegir un número mayor para este parámetro.
Ahora, vamos a medir el rendimiento del mejor modelo encontrado. El código es el mismo que antes, pero en lugar de regressor, utilizaremos el objeto rscv:
# Predict
train_preds = rscv.predict(train_df_transformed)
test_preds = rscv.predict(test_df_transformed)
rmse_train = M.mean_squared_error(
df=train_preds,
y_true_col_names=label_cols,
y_pred_col_names=output_cols,
squared=False,
)
optimal_rmse_test = M.mean_squared_error(
df=test_preds,
y_true_col_names=label_cols,
y_pred_col_names=output_cols,
squared=False,
)
print(f"Train RMSE score for optimal model: {rmse_train:.4f}")
print(f"Test RMSE score for optimal model: {rmse_test:.4f}")Train RMSE score for optimal model: 224.2405
Test RMSE score for optimal model: 572.0517El RMSE de entrenamiento disminuyó, pero el RMSE de prueba es aún mayor. Esto indica que aún estamos sobreajustando y que necesitamos ampliar nuestra búsqueda e incluir otros parámetros para podar los árboles de decisión que XGBoost utiliza bajo el capó.
Te dejaré esa parte a ti.
Si cerramos la sesión ahora, perderemos nuestro modelo sintonizado. Para guardarlo, utilizaremos el registro de modelos nativo de Snowpark, que es un almacenamiento virtual que puedes utilizar para guardar cualquier modelo y sus metadatos.
El registro está disponible en la clase Registry, y requiere los nombres de la base de datos y del esquema de la sesión actual. También requiere que demos un nombre al proyecto para que no tengamos conflictos con modelos de otros proyectos:
# Set up for Registry
from snowflake.ml.registry import Registry
# Get the current db and schema name
db_name = new_session.get_current_database()
schema_name = new_session.get_current_schema()
# Define global model name for the project
model_name = "diamond_prices_regression"
# Initialize a registry to log models
registry = Registry(session=new_session, database_name=db_name, schema_name=schema_name)Utilizaremos el método Registry.log_model() para guardar nuestros modelos:
# Get sample data to pass into registry for schema
sample = train_df.select(cat_cols_encoded + numeric_features).limit(50)
# Log the first model
v0 = registry.log_model(
model_name=model_name,
version_name="v0",
model=regressor,
sample_input_data=sample,
)Podemos registrar una métrica para el modelo con el método .set_metric() (podemos registrar tantas métricas como queramos). También añadiremos un comentario para describir el modelo:
# Add the models RMSE score
v0.set_metric(metric_name="RMSE", value=rmse_test)
# Add a description
v0.comment = "The first model to predict diamond prices"Hacemos lo mismo con el mejor modelo encontrado con la búsqueda aleatoria. Mientras registras la métrica, no olvides cambiar el valor a optimal_rmse_test.
# Log the optimal model
v1 = registry.log_model(
model_name=model_name,
version_name="v1",
model=regressor,
sample_input_data=sample,
)
# Add the models RMSE score
v1.set_metric(metric_name="RMSE", value=optimal_rmse_test)
# Add a description
v1.comment = "Optimal model found with RandomizedSearchCV"Para confirmar que los modelos se han guardado, puedes llamar a .show_models():
# Confirm the models are added
registry.show_models()Obtén más información sobre cómo gestionar el registro en esta página de la documentación para desarrolladores de Snowpark.
La inferencia suele hacerse eligiendo el mejor modelo de tu registro. Podemos hacerlo filtrando el resultado de .show_models() o recuperando el modelo directamente con su etiqueta de versión, como hacemos a continuación:
# Doing inference with the optimal model
optimal_version = registry.get_model(model_name).version("v1")
results = optimal_version.run(test_df, function_name="predict")
results.columnsEl método get_model() devuelve un objeto genérico model, que es diferente de XGBRegressor. Por eso tienes que llamar a .run() especificando el nombre de la función para realizar una inferencia.
En este tutorial, cubrimos un marco integral para entrenar modelos de aprendizaje automático en Snowflake Snowpark. ¡Bien hecho!
Empezamos con un conjunto de datos sin limpiar y terminamos con un modelo regresor XGBoost ajustado. Hemos realizado todas las acciones en Snowflake Cloud, lo que significa que no hemos tenido que utilizar recursos del sistema en absoluto.
Hemos aprendido lo eficaces que son este tipo de operaciones en la base de datos cuando tenemos grandes conjuntos de datos, y que Snowflake Snowpark es una de las mejores herramientas del mercado para facilitar este proceso.
Si quieres saber más sobre Snowpark o Snowflake, consulta los siguientes recursos:
¡Gracias por leer!
¡Más información sobre Snowflake y big data!
programa
Curso
Curso