Programa
Engenheiro de dados Em Python
40 h
O machine learning tradicional envolve trazer os dados dos bancos de dados para onde estão os modelos. Com o recente boom da IA e o tamanho dos conjuntos de dados atuais, essa abordagem está se tornando cada vez mais impraticável.
Terabytes de dados devem ser transferidos do banco de dados para aplicativos do lado do cliente para limpeza, análise e treinamento de modelos. Essa viagem de ida e volta, aparentemente inocente, desperdiça recursos valiosos. Por esse motivo, cada vez mais empresas estão optando por tecnologias no banco de dados para minimizar a movimentação de dados e executar operações de dados sem problemas.
Uma das melhores tecnologias de banco de dados do mercado é o Snowpark, oferecido pela Snowflake Cloud. O Snowpark é um conjunto de bibliotecas e tempos de execução que permite que você execute linguagens de programação com segurança no Snowflake Cloud para desenvolver pipelines de dados e modelos de machine learning no mesmo ambiente que os bancos de dados do Snowflake.
Neste tutorial, discutiremos os fundamentos do Snowpark e como você pode usá-lo em seus projetos. Presumimos que você já esteja familiarizado com o SQL e o Snowflake. Se precisar aprender sobre eles primeiro, você pode fazer o nosso programa SQL Fundamental Skill Track ou ler este tutorial do Snowflake para iniciantes.
Vamos começar!
O Snowflake Snowpark é um conjunto de bibliotecas e tempos de execução que permite que você use com segurança linguagens de programação como Python, Java e Scala para processar dados diretamente na plataforma de nuvem da Snowflake.
Isso elimina a necessidade de mover os dados para fora do Snowflake para processamento, melhorando a eficiência e a segurança. Aqui estão alguns de seus principais benefícios:
Em poucas palavras, o Snowpark é uma maneira poderosa e simples de os desenvolvedores criarem pipelines de dados, soluções de machine learning e aplicativos orientados por dados diretamente no Snowflake Cloud.
Nosso objetivo final neste tutorial é criar um modelo ajustado por hiperparâmetro treinado em uma tabela de um banco de dados Snowflake usando o Snowpark. Para isso, começaremos por você:
Para este tutorial, usaremos um novo ambiente conda:
$ conda create -n snowpark python==3.10 -y
$ conda activate snowparkComo observação, se você estiver executando em um ambiente conda recém-instalado, será necessário executar $conda init antes de ativar o ambiente snowpark.
Após a ativação, precisamos instalar as seguintes bibliotecas:
$ pip install snowflake-snowpark-python #The Snowpark API
$ pip install pandas pyarrow numpy matplotlib seabornSe você for usar o Jupyter, instale também o ipykernel e execute o seguinte comando para que o ambiente que estamos usando seja adicionado como um kernel do Jupyter:
$ pip install ipykernel
$ ipython kernel install --user --name=snowparkVamos agora importar algumas bibliotecas gerais de que precisaremos ao longo do caminho:
import warnings
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
warnings.filterwarnings("ignore")Para este tutorial, usaremos o conjunto de dados Diamonds da Seaborn - você pode baixar o arquivo CSV diretamente do meu GitHub.
Depois que você fizer login no aplicativo Snowflake, siga o GIF abaixo para ingerir o conjunto de dados em uma nova tabela de banco de dados (crie uma nova conta se ainda não tiver uma):
Na prática, você raramente importará arquivos CSV como tabelas para seus bancos de dados do Snowflake. Na maioria das vezes, você trabalhará com bancos de dados existentes com diferentes níveis de acesso concedidos a você pelos administradores de banco de dados da sua empresa.
Agora, precisamos estabelecer uma conexão entre a API do Snowpark e a nuvem do Snowflake para consultar nosso banco de dados. Essa conexão requer as seguintes credenciais do Snowflake: nome da conta, nome de usuário e senha.
Na imagem abaixo, mostrarei como você pode recuperar o nome de usuário e o nome da conta no painel do Snowflake:
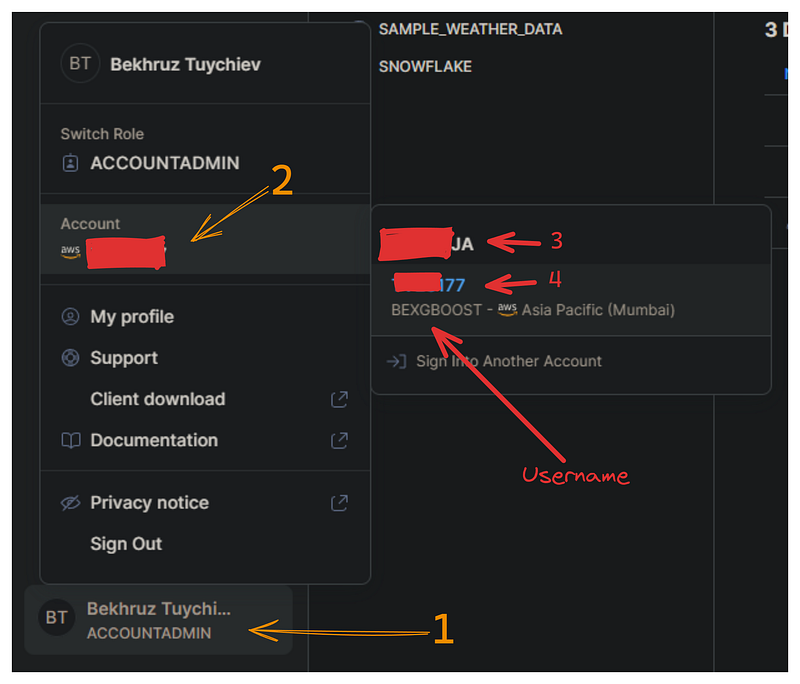
Crie um arquivo separado chamado config.py que contenha um único dicionário chamado credentials com o seguinte formato:
credentials = (
{
"account": "3-4", # Combine 3 and 4 with a hyphen
"username": "bexgboost", # Your username in lowercase
"password": "your_password", # Your Snowflake password
},
)Por motivos de segurança, armazenamos as credenciais em um arquivo separado. Ao adicionar esse arquivo a .gitignore, você garante que suas credenciais do Snowflake não serão vazadas acidentalmente.
Agora, importamos o dicionário credentials e a classe Session do Snowpark:
from config import credentials
from snowflake.snowpark import SessionPara estabelecer uma conexão, usaremos o método Session.builder.configs.create():
connection_parameters = {
"account": credentials["account"],
"user": credentials["username"],
"password": credentials["password"],
}
new_session = Session.builder.configs(connection_parameters).create()
new_session.get_current_user()'"bexgboost"'Se o seu nome de usuário for impresso, sua primeira sessão foi criada com sucesso!
O objeto new_session tem acesso a tudo o que sua conta possui no Snowflake (e ao que você tem permissão para acessar).
A primeira etapa que faremos antes de importar os dados é informar à sessão que estamos usando o banco de dados test_db que criamos na seção anterior:
new_session.sql("USE DATABASE test_db;").collect()[Row(status='Statement executed successfully.')]Fazemos isso usando o método .sql, que nos permite executar qualquer consulta compatível com o Snowflake SQL.
Agora, podemos carregar a tabela diamonds de test_db usando o método table do objeto de sessão:
diamonds_df = new_session.table("diamonds")
diamonds_df.show(5)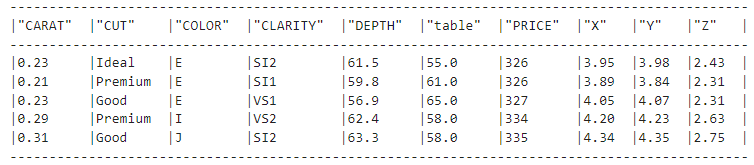
O método .show() é o equivalente ao método DataFrame.describe() do Pandas e mostra que você se conectou com sucesso à tabela.
É isso mesmo, só nos conectamos à tabela de diamantes. O objeto diamonds_df não contém nenhum dado, conforme evidenciado por seu tamanho:
import sys
sys.getsizeof(diamonds_df)48Ele tem apenas 48 bytes, quando deveria ter mais de 3 MBs. Vamos dedicar um pouco mais de tempo para entender por que isso está acontecendo.
Até o momento, abordamos as seguintes etapas:
Agora vamos falar sobre os DataFrames do Snowpark!
Os DataFrames do Pandas usam sua RAM, o que significa que eles vivem em sua máquina. Em comparação, os DataFrames do Snowpark vivem na plataforma de nuvem do Snowflake, embora você possa ver a representação deles no seu ambiente de codificação. Os dados permanecem na nuvem e não precisam ser baixados para o seu computador local para que você faça operações com eles.
Outro aspecto importante dos DataFrames do Snowpark é que eles funcionam de forma preguiçosa. Isso significa que eles não executam nenhuma operação nos dados até que você os informe especificamente.
Em vez disso, eles criam uma representação lógica das operações desejadas que, em seguida, são traduzidas em consultas SQL otimizadas para serem executadas pelo Snowflake.
Em comparação, o Pandas executa as operações imediatamente - em outras palavras, ele realiza a execução ansiosa.
Em termos de desempenho, a avaliação preguiçosa é sempre muito mais rápida do que a execução ansiosa. Como os DataFrames preguiçosos usam os poderosos recursos de computação elástica do Snowflake, eles podem empurrar as operações para o nível do banco de dados e executá-las muito mais rapidamente.
Para que você entenda melhor a diferença entre a avaliação preguiçosa e a execução ansiosa, imagine que nossos dados no Snowflake são uma biblioteca gigante. Temos os dois cenários a seguir:
Como o Snowpark pode converter para DataFrames do Pandas, quando você deve usar um em vez do outro?
pandas_diamonds = diamonds_df.to_pandas()
pandas_diamonds.head()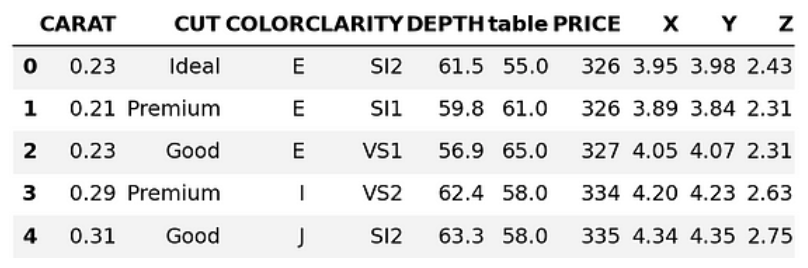
A resposta depende muito do tamanho do conjunto de dados.
Se o seu conjunto de dados for pequeno (como o conjunto de dados Diamonds), você poderá baixá-lo localmente e alimentá-lo no Pandas sem problemas (que é o que o método DataFrame.to_pandas() faz).
Porém, com os conjuntos de dados atuais, as coisas podem sair do controle rapidamente e podemos ter que esperar horas para fazer o download do nosso banco de dados. E lembre-se de que é uma passagem de mão dupla: todos os novos dados que quisermos preservar também devem ser enviados de volta. E é isso que torna o aprendizado da API do DataFrame do Snowpark tão valioso.
Como alternativa, o método Session.sql() nos permite executar qualquer expressão SQL compatível com o Snowflake (veja o exemplo abaixo). No entanto, recomendo que você domine a API DataFrame do Snowpark, pois ela tem muitas funções integradas para mais de 100 funções e expressões SQL.
result = new_session.sql(
"""
SELECT PRICE, CUT FROM DIAMONDS LIMIT 10
"""
)
type(result)
snowflake.snowpark.dataframe.DataFrameresult.show()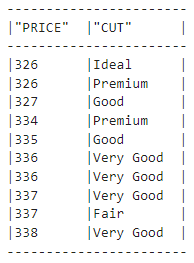
Você passará a maior parte do tempo no Snowpark usando suas funções de transformação. Eles estão disponíveis no seguinte submódulo:
# The convention is to import it as F
import snowflake.snowpark.functions as FTodas as funções em F (que você pode listar chamando dir(F)) especificam como um DataFrame deve ser transformado. Vejamos um exemplo:
F.upper(F.col("CUT"))Aqui, a função col cria uma referência para a coluna fornecida e retorna um objeto Column. Em seguida, o site .upper() converte os valores da coluna CUT em letras maiúsculas:
diamonds_df.show(5)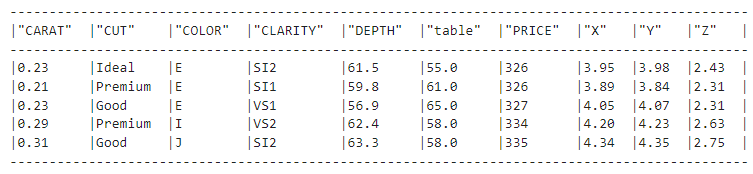
Mas se você observar o conjunto de dados de diamantes, verá que os valores na coluna CUT ainda têm letras minúsculas. Por que isso acontece? Bem, a expressão F.upper(F.col("CUT")) é equivalente à seguinte consulta SQL:
SELECT UPPER(CUT);O que está faltando aqui?
Obviamente, a cláusula FROM que especifica o nome da tabela à qual a transformação deve ser aplicada!
Portanto, devemos combinar a expressão F.upper(F.col("CUT")) com o objeto diamonds_df. Há três maneiras principais de fazer isso:
.select().filter().with_column()Como nossa expressão transforma uma coluna, nós a passaremos para .select():
our_expression = F.upper(F.col("CUT"))
diamonds_df.select(our_expression).show()
Alteramos os valores com sucesso!
Agora vamos escrever uma expressão que filtra as linhas:
diamonds_df.filter(F.col("PRICE") > 10000).count()5222Descobrimos que há mais de 5.000 diamantes em nosso conjunto de dados que custam mais de US$ 10.000. Vamos tentar criar uma coluna também:
(
diamonds_df.with_column("PRICE_SQUARED", F.col("PRICE") ** 2)
.select("PRICE", "PRICE_SQUARED")
.show(5)
)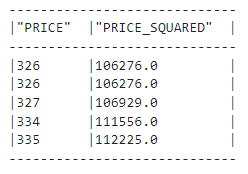
Acima, mostramos que os métodos de encadeamento também são permitidos - temos uma nova coluna chamada "PRICE_SQUARED". Vemos que as funções do Snowpark DataFrame são semelhantes às do Pandas.
Em resumo, se você está procurando uma alternativa do Snowpark para uma função do Pandas, ela está em F ou faz parte dos métodos do DataFrames do Snowpark. Você pode verificar chamando dir(F) ou dir(diamonds_df) ou lendo a referência do Python do Snowpark.
Uma parte significativa da realização da análise exploratória de dados (EDA) é a criação de recursos visuais. Para nossa sorte, não precisamos do Snowpark para isso, pois podemos continuar usando a pilha de dados moderna.
A ideia é a seguinte: Como a EDA tem a ver com a descoberta de tendências e percepções gerais, muitas vezes podemos usar uma amostra em vez de todo o conjunto de dados. Depois de baixar uma amostra representativa, você pode convertê-la em Pandas DataFrame e usar o bom e velho Matplotlib ou Seaborn.
Vamos começar com a conversão:
sample = diamonds_df.sample(0.25).to_pandas()
sample.head()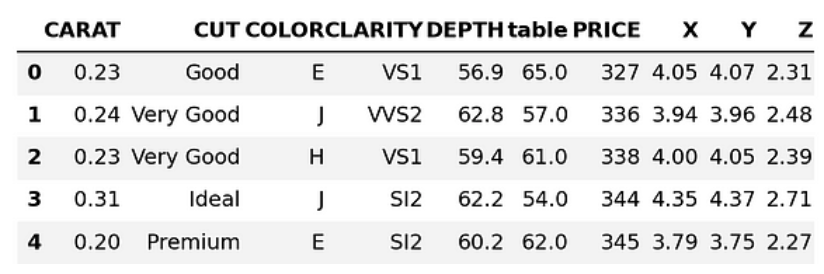
Acima, estamos baixando 25% do conjunto de dados como um DataFrame do Pandas. Vamos converter os nomes das colunas em letras minúsculas:
sample.columns = [col.lower() for col in sample.columns]
sample.columnsIndex(['carat', 'cut', 'color', 'clarity', 'depth', 'table', 'price', 'x', 'y', 'z'], dtype='object')Agora, você pode fazer a EDA como faria em qualquer conjunto de dados. A seguir, exploramos algumas ideias possíveis e começamos gerando um gráfico de dispersão para visualizar a relação entre preço e quilate:
#Remember we imported seaborn as sns
sns.scatterplot(data=sample, x="price", y="carat", s=1)
plt.title("Diamond prices vs. carat")
plt.show()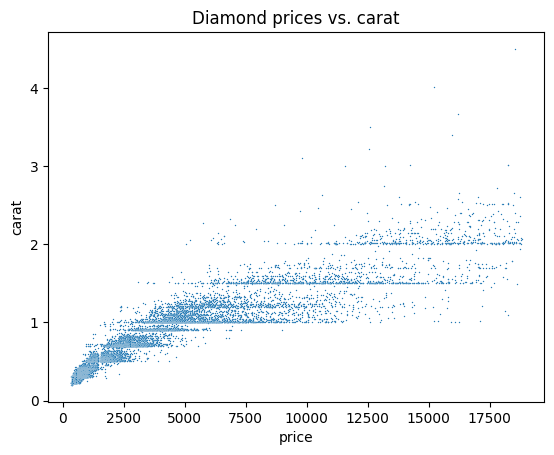
Vamos agora traçar uma matriz de correlação para ver a correlação entre cada par de recursos numéricos:
corr_matrix = sample.corr(numeric_only=True)
sns.heatmap(corr_matrix, center=0, square=True, annot=True
plt.title("The correlation matrix of Diamond numeric features")
plt.show()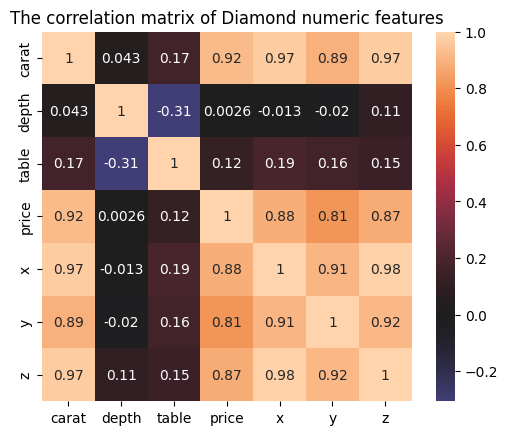
Também poderíamos criar um gráfico de barras das categorias de corte de diamante:
cut_counts = sample.groupby("cut")["cut"].count()
cut_counts.plot(kind="bar")
plt.title("Category counts of diamond cuts")
plt.xlabel("Diamond cut")
plt.show()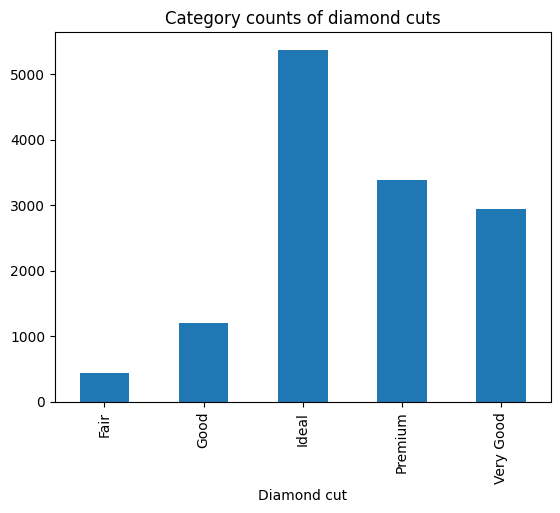
Para confirmar que esses gráficos serão praticamente os mesmos em todo o conjunto de dados, executaremos a versão SQL do gráfico de barras acima.
Primeiro, escreveremos uma expressão SQL para agrupar o conjunto de dados de diamantes por CUT:
result = new_session.sql(
"""
SELECT cut, COUNT(*) AS count
FROM diamonds
GROUP BY cut;
"""
)
Agora, vamos converter e baixar o resultado como um DataFrame do Pandas:
result_pd = result.to_pandas()
result_pd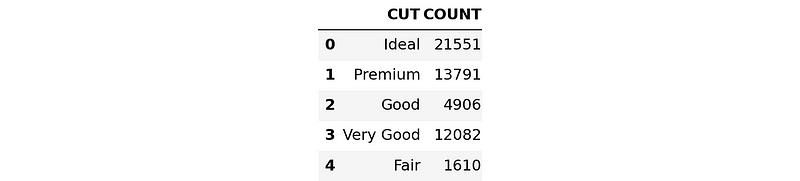
Desta vez, usaremos a função plt.bar() para criar o gráfico:
plt.bar(x=result_pd["CUT"], height=result_pd["COUNT"])
plt.show()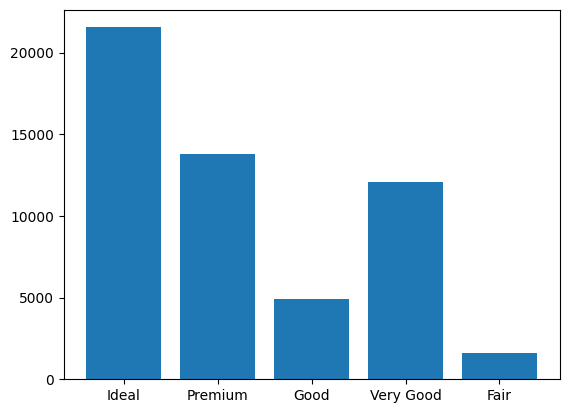
A ordem das barras é diferente, mas se você as observar lado a lado, verá que elas transmitem as mesmas informações.
Agora estamos prontos para aprender a treinar modelos de machine learning no Snowpark!
Começaremos limpando o conjunto de dados.
Primeiro, vamos nos certificar de que todas as colunas tenham o tipo de dados correto:
list(diamonds_df.schema)[StructField('CARAT', DecimalType(38, 2), nullable=True),
StructField('CUT', StringType(16777216), nullable=True),
StructField('COLOR', StringType(16777216), nullable=True),
StructField('CLARITY', StringType(16777216), nullable=True),
StructField('DEPTH', DecimalType(38, 1), nullable=True),
StructField('"table"', DecimalType(38, 1), nullable=True),
StructField('PRICE', LongType(), nullable=True),
StructField('X', DecimalType(38, 2), nullable=True),
StructField('Y', DecimalType(38, 2), nullable=True),
StructField('Z', DecimalType(38, 2), nullable=True)]A coluna table tem um nome estranho, portanto, vamos convertê-lo para maiúsculas em TABLE_ (com um sublinhado à direita para que não entre em conflito com uma palavra-chave SQL incorporada):
diamonds_df = diamonds_df.with_column_renamed('"table"', "TABLE_")
diamonds_df.columns['CARAT', 'CUT', 'COLOR', 'CLARITY', 'DEPTH', 'TABLE_', 'PRICE', 'X', 'Y', 'Z']Você precisará alterar o tipo de dados dos recursos numéricos de DecimalType para DoubleType porque os decimais ainda não são compatíveis com o Snowpark.
from snowflake.snowpark.types import DoubleType
numeric_features = ["CARAT", "X", "Y", "Z", "DEPTH", "TABLE_"]
for col in numeric_features:
diamonds_df = diamonds_df.with_column(col, diamonds_df[col].cast(DoubleType()))
list(diamonds_df.select(*numeric_features))[Column("CARAT"),
Column("X"),
Column("Y"),
Column("Z"),
Column("DEPTH"),
Column("TABLE_")]No snippet acima, usamos o método .with_column() novamente. Outro novo método é o .cast(), que faz parte dos métodos do Snowpark DataFrames.
O Snowpark também exige que todos os recursos de texto estejam em letras maiúsculas e não tenham espaços entre as palavras antes de codificá-los. Atualmente, os valores do recurso CUT violam esse requisito, portanto, vamos corrigi-lo com transformações de função:
import snowflake.snowpark.functions as F
def remove_space_and_upper(df):
df = df.with_column("CUT", F.upper(F.replace(F.col("CUT"), " ", "_")))
return df
diamonds_df = remove_space_and_upper(diamonds_df)
Nossos dados agora estão livres de problemas de limpeza. Você pode salvá-la novamente como uma nova tabela no Snowflake:
diamonds_df.write.mode("overwrite").save_as_table("diamonds_cleaned")Certifique-se de adicionar o modo overwrite, pois talvez você precise voltar e alterar algumas operações de limpeza e salvar novamente.
Nesta seção, trataremos de todos os problemas de pré-processamento restantes que possam impedir o treinamento dos modelos. Vamos carregar a tabela limpa da seção anterior:
clean_df = new_session.table("diamonds_cleaned")
clean_df.show()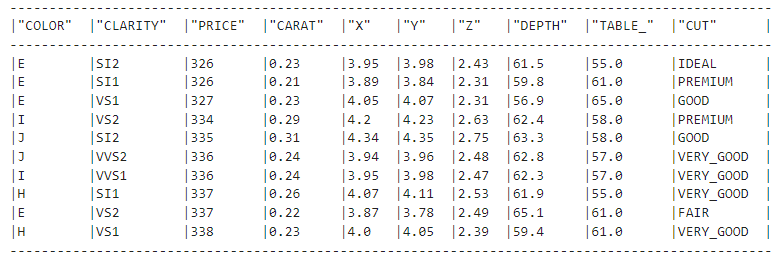
Muito bom!
Em seguida, importaremos os submódulos preprocessing e pipeline do namespace snowflake.ml.
import snowflake.ml.modeling.preprocessing as snowml
from snowflake.ml.modeling.pipeline import PipelineEnquanto a API DataFrame do Snowpark está disponível em snowflake.snowpark, os módulos ML do Snowpark estão presentes em snowflake.ml. Isso pode ser confuso no início, portanto, reserve um tempo para você se acostumar.
No código abaixo, você:
# List all the features for processing
cat_cols = ["CUT", "COLOR", "CLARITY"]
cat_cols_encoded = ["CUT_OE", "COLOR_OE", "CLARITY_OE"]
# We already have numeric_features
# List the correct ordering of categorical features
categories = {
"CUT": np.array(["IDEAL", "PREMIUM", "VERY_GOOD", "GOOD", "FAIR"]),
"CLARITY": np.array(
["IF", "VVS1", "VVS2", "VS1", "VS2", "SI1", "SI2", "I1", "I2", "I3"]
),
"COLOR": np.array(["D", "E", "F", "G", "H", "I", "J"]),
}Agora estamos prontos para criar um pipeline semelhante a um pipeline do Scikit-learn:
# Build the pipeline
preprocessing_pipeline = Pipeline(
steps=[
(
"OE",
snowml.OrdinalEncoder(
input_cols=cat_cols, output_cols=cat_cols_encoded, categories=categories
),
),
(
"SS",
snowml.StandardScaler(
input_cols=numeric_features, output_cols=numeric_features
),
),
]
)
A classe Pipeline aceita uma lista de etapas, cada uma delas uma classe de pré-processamento. Aqui, estamos usando OrdinalEncoder para codificar as categorias como 0, 1, 3, etc. e StandardScaler para normalizar os recursos numéricos.
No final, salvaremos o pipeline localmente com joblib e o testaremos em todo o conjunto de dados:
import joblib
PIPELINE_FILE = "pipeline.joblib"
# Pickle locally first
joblib.dump(preprocessing_pipeline, PIPELINE_FILE)
transformed_diamonds_df = preprocessing_pipeline.fit(clean_df).transform(clean_df)
# transformed_diamonds_df.show() - commented because of long outputO snippet é executado sem erros, portanto, nosso pipeline está funcionando, sinalizando que podemos finalmente treinar um modelo.
Para treinar um modelo, listaremos novamente os nomes dos recursos e dos alvos:
# Define the columns again
cat_cols_encoded = ["CUT_OE", "COLOR_OE", "CLARITY_OE"]
numeric_features = ["CARAT", "X", "Y", "Z", "DEPTH", "TABLE_"]
label_cols = ["PRICE"] # Must be a list
output_cols = ["PRICE_PREDICTED"] # Required in snowparkAgora, dividiremos os dados usando DataFrame.random_split() e daremos pesos para representar a fração dos conjuntos de treinamento e teste:
# Split the data
train_df, test_df = diamonds_df.random_split(weights=[0.8, 0.2], seed=42)Em seguida, carregaremos o pipeline e ajustaremos a transformação dos conjuntos de treinamento e teste.
# Load the pre-processing pipeline locally
pipeline = joblib.load("pipeline.joblib")
# Apply it to both dataframes
train_df_transformed = pipeline.fit(train_df).transform(train_df)
test_df_transformed = pipeline.transform(test_df)Acima, certifique-se de que você chama apenas .transform() no conjunto de teste para evitar vazamento de dados.
Em seguida, inicializamos um modelo de regressor XGBoost em ml.modeling.xgboost sub-module:
# Snowpark has models from scikit-learn and lightgbm too
from snowflake.ml.modeling.xgboost import XGBRegressor
# Initialize
regressor = XGBRegressor(
input_cols=cat_cols_encoded + numeric_features,
label_cols=label_cols,
output_cols=output_cols,
)A classe XGBRegressor requer todos os nomes de entrada, todos os nomes de destino e nomes de coluna de saída. Depois de inseri-los, chamamos .fit() para iniciar o processo de treinamento:
# Train
regressor.fit(train_df_transformed)O treinamento poderá ser executado lentamente se você tiver uma conta gratuita do Snowflake com recursos de computação limitados e sem GPU.
Após o término do treinamento, podemos gerar previsões:
# Prever
train_preds = regressor.predict(train_df_transformed)
test_preds = regressor.predict(test_df_transformed)Vamos dar uma olhada nas previsões:
train_preds.select("PRICE", "PRICE_PREDICTED").show(5)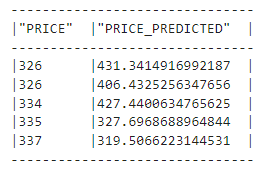
Agora temos que medir o desempenho de nosso modelo inicial. O Snowpark inclui dezenas de métricas do Scikit-learn em seu submódulo ml.modeling.metrics, que importamos como M:
import snowflake.ml.modeling.metrics as MEm seguida, executamos o site mean_squared_error duas vezes para medir a raiz do erro quadrático médio (RMSE) nos conjuntos de treinamento e teste (abaixo, squared=False retorna RMSE em vez de MSE):
rmse_train = M.mean_squared_error(
df=train_preds,
y_true_col_names=label_cols,
y_pred_col_names=output_cols,
squared=False,
)
rmse_test = M.mean_squared_error(
df=test_preds,
y_true_col_names=label_cols,
y_pred_col_names=output_cols,
squared=False,
)
print(f"Train RMSE score for XGBRegressor: {rmse_train:.4f}")
print(f"Test RMSE score for XGBRegressor: {rmse_test:.4f}")Train RMSE score for XGBRegressor: 371.9664
Test RMSE score for XGBRegressor: 542.1566Nosso modelo tem um erro de US$ 542 em média e também pode estar se ajustando um pouco demais porque a diferença entre os RMSEs de treinamento e teste é grande.
Vamos ajustar os hiperparâmetros do modelo para lidar com esses problemas.
Atualmente, o Snowpark oferece duas classes de ajuste de hiperparâmetro:
GridSearchCVPesquisa exaustiva de todas as combinações de hiperparâmetros com validação cruzada.RandomizedSearchCVPesquisa aleatória de uma determinada distribuição de hiperparâmetros com validação cruzada.O XGBoost tem cerca de uma dúzia de hiperparâmetros que podem melhorar seu desempenho (você pode saber mais neste tutorial sobre como usar o XGBoost em Python). Isso nos leva a fazer uma pesquisa aleatória. Pessoalmente, eu preferiria usar o Optuna, que usa a pesquisa bayesiana, mas ainda não temos esse luxo no Snowpark.
Vamos definir a pesquisa agora:
from snowflake.ml.modeling.model_selection import RandomizedSearchCV
rscv = RandomizedSearchCV(
estimator=XGBRegressor(),
param_distributions={
"n_estimators": [2000],
"max_depth": list(range(3, 13)),
"learning_rate": np.linspace(0.1, 0.5, num=10),
},
n_jobs=-1,
scoring="neg_mean_squared_error",
input_cols=numeric_features + cat_cols_encoded,
label_cols=label_cols,
output_cols=output_cols,
n_iter=10,
)
rscv.fit(train_df_transformed)
Estamos fixando o número de estimadores em 2.000 e ajustando apenas os parâmetros max_depth e learning_rate. O rscv tem um parâmetro padrão de n_iter=10, o que significa que a pesquisa será realizada 10 vezes, cada vez escolhendo uma combinação aleatória de parâmetros. Para obter resultados mais precisos, é melhor você escolher um número maior para esse parâmetro.
Agora, vamos medir o desempenho do melhor modelo encontrado. O código é o mesmo de antes, mas, em vez de regressor, usaremos o objeto rscv:
# Predict
train_preds = rscv.predict(train_df_transformed)
test_preds = rscv.predict(test_df_transformed)
rmse_train = M.mean_squared_error(
df=train_preds,
y_true_col_names=label_cols,
y_pred_col_names=output_cols,
squared=False,
)
optimal_rmse_test = M.mean_squared_error(
df=test_preds,
y_true_col_names=label_cols,
y_pred_col_names=output_cols,
squared=False,
)
print(f"Train RMSE score for optimal model: {rmse_train:.4f}")
print(f"Test RMSE score for optimal model: {rmse_test:.4f}")Train RMSE score for optimal model: 224.2405
Test RMSE score for optimal model: 572.0517O RMSE de treinamento diminuiu, mas o RMSE de teste é ainda maior. Isso indica que ainda estamos fazendo um ajuste excessivo e que precisamos expandir nossa pesquisa e incluir outros parâmetros para podar as árvores de decisão que o XGBoost usa nos bastidores.
Deixarei essa parte para você.
Se fecharmos a sessão agora, perderemos nosso modelo ajustado. Para salvá-lo, usaremos o registro de modelo nativo do Snowpark, que é um armazenamento virtual que você pode usar para salvar qualquer modelo e seus metadados.
O registro está disponível como a classe Registry e requer os nomes do banco de dados e do esquema da sessão atual. Isso também exige que você dê um nome ao projeto para que não haja conflitos com modelos de outros projetos:
# Set up for Registry
from snowflake.ml.registry import Registry
# Get the current db and schema name
db_name = new_session.get_current_database()
schema_name = new_session.get_current_schema()
# Define global model name for the project
model_name = "diamond_prices_regression"
# Initialize a registry to log models
registry = Registry(session=new_session, database_name=db_name, schema_name=schema_name)Usaremos o método Registry.log_model() para salvar nossos modelos:
# Get sample data to pass into registry for schema
sample = train_df.select(cat_cols_encoded + numeric_features).limit(50)
# Log the first model
v0 = registry.log_model(
model_name=model_name,
version_name="v0",
model=regressor,
sample_input_data=sample,
)Podemos registrar uma métrica para o modelo com o método .set_metric() (podemos registrar quantas métricas quisermos). Também adicionaremos um comentário para descrever o modelo:
# Add the models RMSE score
v0.set_metric(metric_name="RMSE", value=rmse_test)
# Add a description
v0.comment = "The first model to predict diamond prices"Fazemos o mesmo com o melhor modelo encontrado com a pesquisa aleatória. Ao registrar a métrica, não se esqueça de alterar o valor para optimal_rmse_test.
# Log the optimal model
v1 = registry.log_model(
model_name=model_name,
version_name="v1",
model=regressor,
sample_input_data=sample,
)
# Add the models RMSE score
v1.set_metric(metric_name="RMSE", value=optimal_rmse_test)
# Add a description
v1.comment = "Optimal model found with RandomizedSearchCV"Para confirmar que os modelos estão salvos, você pode ligar para .show_models():
# Confirm the models are added
registry.show_models()Saiba mais sobre como gerenciar o registro nesta página dos documentos do desenvolvedor no Snowpark.
A inferência geralmente é feita escolhendo o melhor modelo do seu registro. Você pode fazer isso filtrando o resultado de .show_models() ou recuperando o modelo diretamente com sua tag de versão, como fazemos abaixo:
# Doing inference with the optimal model
optimal_version = registry.get_model(model_name).version("v1")
results = optimal_version.run(test_df, function_name="predict")
results.columnsO método get_model() retorna um objeto genérico model, que é diferente de XGBRegressor. É por isso que você precisa chamar .run() especificando o nome da função para realizar uma inferência.
Neste tutorial, abordamos uma estrutura completa para você treinar modelos de machine learning no Snowflake Snowpark. Muito bem!
Começamos com um conjunto de dados básicos não limpos e terminamos com um modelo regressor XGBoost ajustado. Realizamos todas as ações na Snowflake Cloud, o que significa que você não precisou usar nenhum recurso do sistema.
Aprendemos como esse tipo de operação no banco de dados é eficaz quando temos grandes conjuntos de dados - e que o Snowflake Snowpark é uma das melhores ferramentas do mercado para facilitar esse processo.
Se você quiser saber mais sobre o Snowpark ou o Snowflake, consulte os seguintes recursos:
Obrigado a você por ler!
Saiba mais sobre o Snowflake e o big data!
Programa
Curso
Curso
blog
Nisha Arya Ahmed
15 min
Tutorial
Natassha Selvaraj
Tutorial
Abid Ali Awan
Tutorial
Bex Tuychiev