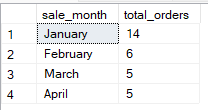

Curso
Estadísticas resumidas y funciones de ventana de PostgreSQL
4 h
125.3K
Aunque es habitual agrupar por una sola columna, agrupar por varias columnas permite resumir grandes conjuntos de datos agrupando filas que comparten valores comunes, lo que facilita la identificación de patrones, tendencias y valores atípicos.
En esta guía, explicaré cómo funciona la cláusula « GROUP BY », métodos avanzados de agrupación y las mejores prácticas. Si eres nuevo en SQL, considera comenzar con nuestro curso Introducción a SQL o el curso SQL intermedio para adquirir una base sólida. Además, la hoja de referencia rápida sobre conceptos básicos de SQL, que puedes descargar, me parece muy útil porque incluye todas las funciones SQL más comunes.
Antes de explicar cómo agrupar por varias columnas en SQL, veamos primero los conceptos básicos de la cláusula « GROUP BY ».
La cláusula « GROUP BY » en SQL organiza datos idénticos en grupos. Escanea filas en una base de datos y luego agrupa las filas con los mismos valores en las columnas especificadas, lo que permite la agregación de datos dentro de estos grupos.
Puedes utilizar la cláusula « GROUP BY » con funciones agregadas como « COUNT() », « SUM() », « AVG() », « MIN() » y « MAX() » para realizar cálculos de resúmenes en cada grupo de filas.
Supongamos que estás analizando datos de ventas y deseas conocer los ingresos totales por región. GROUP BY te permite agrupar las ventas por región y calcular la suma de cada una en una sola consulta.
La base de datos procesa la cláusula « GROUP BY » en una sola columna, escaneando las filas y segmentándolas según los valores distintos de esa columna. Cada valor distinto forma un grupo, y las funciones de agregación calculan los resultados dentro de cada grupo.
Sin embargo, cuando introduces varias columnas, SQL agrupa los datos en función de cada combinación única de esas columnas. Esto significa que la base de datos divide los datos en grupos más pequeños y refinados, definidos por todos los valores de columna especificados.
Este enfoque de partición permite la agregación multidimensional. Esto resulta útil para obtener información empresarial y análisis detallados. Permite realizar análisis en profundidad al resumir datos en la intersección de varias dimensiones. Por ejemplo, puedes agrupar las ventas por región y categoría de producto.
Como has visto, agrupar datos por varias columnas te permite obtener más información. Ahora veamos cómo SQL maneja esta agrupación.
Cuando agrupas por más de una columna en SQL, el motor de la base de datos trata la combinación de columnas como claves compuestas. Cada una de estas combinaciones únicas forma un grupo distinto. Por ejemplo, al agrupar los datos de ventas por region y product_type se genera un grupo independiente para cada par único, como ('West', 'Electronics'), ('East', 'Furniture'), etcétera.
Esto da lugar a un patrón jerárquico de subagrupación, en el que la primera columna crea los grupos principales, la segunda columna segmenta esos grupos principales en subgrupos, y así sucesivamente. Esta agrupación por capas mejora la granularidad de los datos al dividir la información en categorías detalladas.
También debes tener en cuenta que existe una diferencia entre agrupación jerárquica y no jerárquica. La agrupación jerárquica sigue la agrupación y subagrupación de las columnas siguiendo una secuencia específica. Por otro lado, la agrupación no jerárquica toma cada columna como otra dimensión y no sigue una jerarquía inherente. Aun así, la agrupación no jerárquica crea combinaciones útiles para el análisis, como cuando deseas agrupar las ventas de productos por temporada.
En SQL, el orden en que enumeras las columnas en una cláusula GROUP BY es realmente importante. Cuando agrupas por varias columnas, SQL trata esas columnas juntas como una clave combinada, algo así como unir varias piezas para identificar cada grupo de forma única.
SQL procesa las columnas de izquierda a derecha. Esto significa que primero agrupa los datos según la primera columna que indiques y, a continuación, dentro de cada uno de esos grupos, los agrupa según la siguiente columna, y así sucesivamente. Este orden puede influir en la eficiencia con la que la base de datos gestiona la consulta, en cómo utiliza los índices y en cómo se crean las agrupaciones intermedias, especialmente cuando se trabaja con conjuntos de datos de gran tamaño.
Por ejemplo, si deseas agrupar los datos por región y producto, primero se agrupan por región y, a continuación, dentro de cada región, se agrupan por producto. Pero si cambias el orden a (producto, región), modificas la jerarquía de agrupación, lo que puede dar lugar a resultados e interpretaciones diferentes en tus informes.
Examinemos la sintaxis y las variaciones de la cláusula « GROUP BY » en SQL para comprenderla completamente.
Para utilizar una cláusula « GROUP BY » en varias columnas, debes enumerar cada columna en la instrucción « SELECT », separadas por comas. A continuación, la base de datos agrupará las filas en función de las combinaciones únicas de los valores de esas columnas.
SELECT column1, column2, AGGREGATE_FUNCTION(column3)
FROM table_name
GROUP BY column1, column2;Asegúrate siempre de que todas las columnas utilizadas en la instrucción « SELECT », que no formen parte de funciones agregadas, aparezcan en la cláusula « GROUP BY » para evitar errores y garantizar una agregación legible.
Supongamos que tienes una tabla Sales con la siguiente estructura:
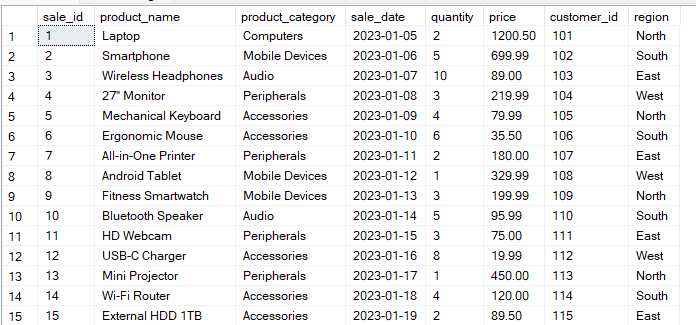
La consulta siguiente agrupa los datos por las columnas « region » y « product_category ». A continuación, calcula el valor de error de la medida ( total_sales ) para cada combinación de grupos.
-- Group Sales by region and product category
SELECT region, product_category, SUM(quantity) AS total_sales
FROM Sales
GROUP BY region, product_category;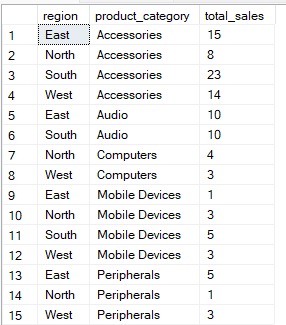
A continuación se muestran los diferentes métodos que puedes utilizar para aplicar la cláusula « GROUP BY » en varias columnas en SQL:
En lugar de utilizar nombres de columnas, SQL permite indicar la posición de las columnas en la cláusula GROUP BY. En nuestro ejemplo anterior, 1 hace referencia a la columna region y 2 a la columna product_category. Este método es compatible con MySQL y PostgreSQL, pero no con SQL Server.
-- Group Sales by region and product category
SELECT region, product_category, SUM(quantity) AS total_sales
FROM Sales
GROUP BY 1, 2;También puedes agrupar por expresiones derivadas o valores calculados. Esto resulta útil para agrupar datos transformados, como el año de una fecha o subcadenas. Por ejemplo, la consulta siguiente agrupa las ventas por mes derivadas de sale_date.
-- Group Sales by month derived from date column
SELECT
DATENAME(MONTH, sale_date) AS sale_month,
COUNT(*) AS total_orders
FROM Sales
GROUP BY DATENAME(MONTH, sale_date), MONTH(sale_date)
ORDER BY MONTH(sale_date);
Seleccionar varias columnas pero agrupar por una sola
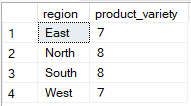
SQL te permite seleccionar varias columnas mientras agrupas por una sola, pero solo si las columnas adicionales se utilizan dentro de funciones agregadas. En el ejemplo siguiente, solo region aparece en la cláusula GROUP BY, mientras que product_id se utiliza en una función agregada (COUNT(DISTINCT)), lo que hace que la consulta sea válida.
-- Group Sales by region only
SELECT region, COUNT(DISTINCT sale_id) AS product_variety
FROM Sales
GROUP BY region;
Te recomiendo que pruebes nuestro proyecto Análisis y formateo de datos de ventas de PostgreSQL para comprender cómo manipular datos en PostgreSQL. Además, la hoja de referencia rápida de MySQL será una guía de referencia útil para realizar consultas básicas en tablas, filtrar datos y agregar datos, especialmente si prefieres utilizar MySQL.
La ventaja de la cláusula GROUP BY en SQL es que puedes usarla con funciones agregadas para obtener un resumen de los datos agrupados.
Las funciones agregadas ofrecen información multidimensional sobre diversas combinaciones de datos al agruparlos por varias columnas. Estas son las funciones más utilizadas con la cláusula « GROUP BY »:
SUM(): Suma todos los valores de una columna numérica para cada grupo.
COUNT(): Cuenta el número de filas o valores no nulos en cada grupo.
AVG(): Calcula el valor promedio dentro de cada grupo.
MIN(): Busca el valor más pequeño de cada grupo.
MAX(): Busca el valor más grande en cada grupo.
Por ejemplo, la consulta siguiente calcula el total de ventas y el recuento de registros de ventas para cada combinación de región y categoría de producto.
-- Group by region, product_category then aggregate
SELECT region, product_category, SUM(quantity) AS total_sales, COUNT(*) AS sales_count
FROM Sales
GROUP BY region, product_category;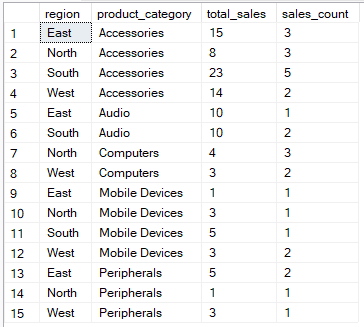
En los ejemplos anteriores, has visto que la cláusula « GROUP BY » se utiliza con funciones agregadas. Sin embargo, puedes utilizarlo sin agregación si deseas agrupar filas por las columnas especificadas, pero sin el resumen.
Por ejemplo, la consulta siguiente muestra pares únicos de región y categoría de producto sin agregación. Por lo tanto, puedes utilizar este método para comprobar la coherencia de los datos.
--Group by multiple columns without aggregate
SELECT region, product_category
FROM Sales
GROUP BY region, product_category;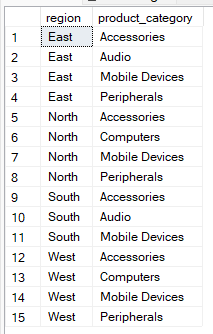
Ahora que hemos visto cómo se puede agrupar por varias columnas, veamos las diferentes operaciones de agrupación avanzadas que se utilizan con la cláusula GROUP BY.
La operación ROLLUP se basa en la cláusula estándar GROUP BY, creando niveles de resumen que se acumulan a lo largo de las columnas especificadas. Además de mostrar grupos detallados, también añade subtotales y un total general agregando paso a paso de derecha a izquierda a través de las columnas por las que agrupas.
Por ejemplo, en la consulta siguiente, se obtiene el valor « total_quantity » (Total de pedidos) para cada combinación de « region » (Categoría de producto) y « product_category. » (Región). Los resultados incluyen subtotales para cada región (donde « product_category » aparece como « NULL ») y un total general que suma todo en todas las regiones y categorías.
-- Group by region, product_category and ROLLUP by region
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY ROLLUP(region, product_category);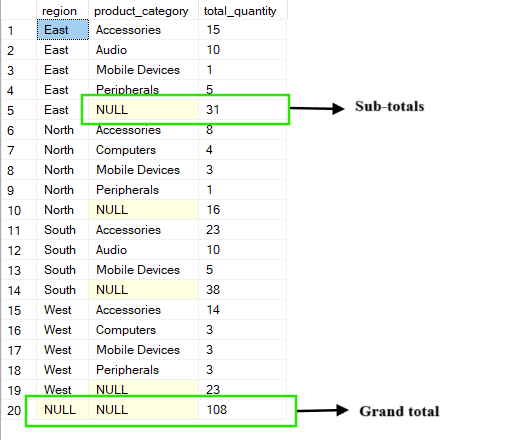
La operación « CUBE » genera todas las combinaciones posibles de las columnas de agrupación. A diferencia de la operación « ROLLUP », que produce una jerarquía, « CUBE » produce un cubo de datos completo de agregaciones.
Proporciona una tabulación cruzada de agregaciones para cada subconjunto de las columnas especificadas. El resultado de la operación « CUBE » incluye resúmenes de cada columna, todas las combinaciones de columnas y el total general.
Por ejemplo, si consultamos la tabla anterior y agrupamos por las columnas (region, product_category), la operación CUBE producirá las siguientes combinaciones:
(region, product_category)
(region, NULL)
(NULL, product_category)
(NULL, NULL), que es el total general.
-- Group by multiple columns using CUBE operation
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY CUBE(region, product_category);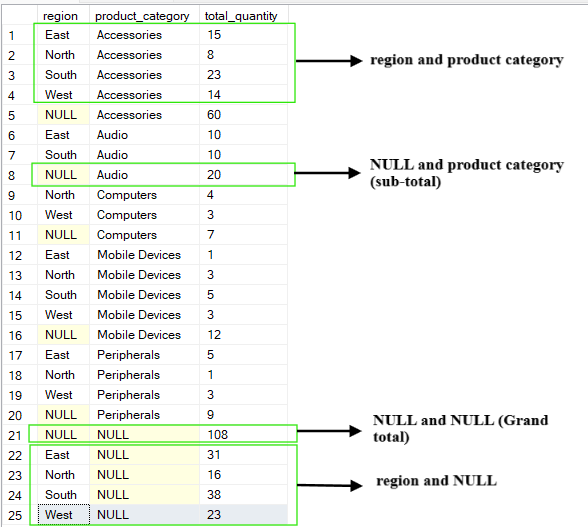
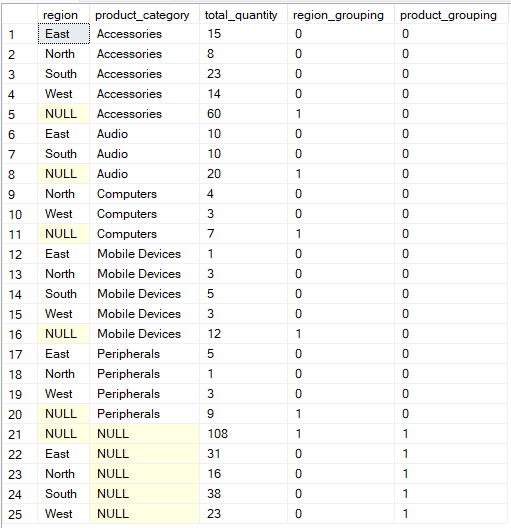
Si deseas un control más flexible sobre cómo se agrupan tus datos, la operación « GROUPING SETS » te permite definir explícitamente varias agrupaciones en una sola consulta.
En este caso, la función « GROUPING() » proporciona metadatos sobre las columnas que se agregan en cada fila del resultado, identificando los valores NULL que representan filas de subtotal o total en lugar de datos que realmente faltan.
-- Group by multiple columns using GROUPING SETS operation
SELECT region, product_category, SUM(quantity) AS total_quantity,
GROUPING(region) AS region_grouping,
GROUPING(product_category) AS product_grouping
FROM Sales
GROUP BY GROUPING SETS (
(region, product_category),
(region),
(product_category),
()
);
Al escribir consultas que agrupan varias columnas, es importante optimizarlas para mejorar la eficiencia y el rendimiento general de la base de datos. A continuación, se incluyen algunos consejos prácticos que he utilizado para ayudar con la optimización de consultas y la gestión de recursos.
Para que tus consultas se ejecuten sin problemas y con un uso mínimo de recursos:
Identifica los cuellos de botella en el rendimiento: las consultas de GROUP BY pueden ralentizarse cuando se trata de conjuntos de datos grandes debido al escaneo, la clasificación y la agregación de gran cantidad de datos. Para evitar este problema, filtra siempre desde el principio con una cláusula « WHERE » y evita recuperar datos que no necesites.
Usa la indexación de forma eficaz: La indexación de columnas acelera el rendimiento de la búsqueda rápida ( GROUP BY ). Crear índices compuestos en las columnas utilizadas en la cláusula GROUP BY ayuda al motor de base de datos a localizar y agrupar rápidamente las filas sin necesidad de realizar costosos escaneos completos de tablas o clasificaciones.
Limitar columnas: Incluye solo las columnas necesarias para la agrupación y el análisis, a fin de reducir la complejidad y mejorar el rendimiento.
Aprovecha los planes de consulta: Cuando sea posible, comprueba los planes de ejecución o utiliza sugerencias de consulta para guiar al optimizador de la base de datos hacia las mejores estrategias.
La memoria desempeña un papel importante en el rendimiento de las consultas de GROUP BY. La clasificación y agrupación de datos a menudo requieren mantener datos intermedios en la memoria. Si no hay suficiente memoria, todo se ralentiza considerablemente.
Para gestionar mejor los recursos:
Además, recuerda que el tamaño de los datos tiene un gran impacto en el rendimiento. Los conjuntos de datos grandes con muchas combinaciones de grupos únicos utilizan más memoria y potencia de procesamiento. Técnicas como dividir tablas grandes, crear tablas resumen con antelación o utilizar vistas materializadas ayudan a mantener todo bajo control.
La cláusula « GROUP BY » funciona bien con otras cláusulas SQL, lo que hace que tus consultas sean más potentes y flexibles. A continuación, verás ejemplos prácticos de cómo combinar GROUP BY con diferentes cláusulas SQL para mejorar tu análisis.
La cláusula WHERE filtra las filas antes de que se produzca la agrupación. Limita el conjunto de datos para que solo se incluyan las filas necesarias en el proceso de agregación. Por ejemplo, la consulta siguiente agrupa por region and product_category`, pero incluye registros en los que la región es «North».
-- Group by multiple columns, filter using WHERE clause
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
WHERE region = 'North'
GROUP BY region, product_category;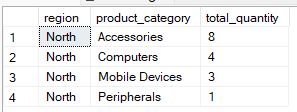
El cláusula HAVING, por otro lado, filtra después de la agregación. Se utiliza para limitar los grupos que aparecen en el resultado final en función de valores agregados. La consulta siguiente agrupa por region and product_category but includes records where the total_quantity` es mayor que 5.
-- Group by multiple columns, filter using HAVING clause
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY region, product_category
HAVING SUM(quantity) > 4;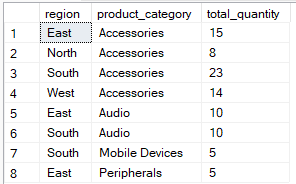
En el orden de ejecución de SQL, tla cláusula « ORDER BY » aparece después de la cláusula « GROUP BY » y se utiliza para ordenar los resultados agrupados, lo que facilita su lectura o su procesamiento posterior. Al utilizar los índices adecuados y seleccionar cuidadosamente el orden de las columnas en la cláusula ORDER BY, puedes acelerar la consulta al reducir el trabajo necesario para ordenar los datos.
Por ejemplo, esta consulta agrupa los datos por region y product_category, y luego ordena los resultados de modo que los grupos con el total_quantity más alto aparezcan primero.
-- Group by multiple columns, ORDER BY total_quantity
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY region, product_category
ORDER BY total_quantity DESC;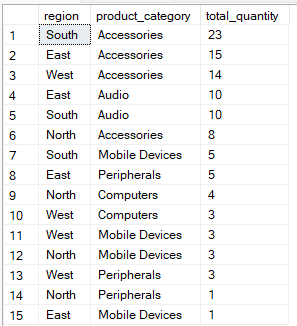
También puedes combinar operaciones de JOIN con la cláusula GROUP BY para agrupar datos de varias tablas relacionadas. Debes tener cuidado al utilizar este método, ya que puede introducir complejidad debido a la unión de datos con tamaños más grandes.
-- Retrieve the number of sales per region and product category
SELECT
c.region,
p.product_category,
COUNT(*) AS sales_count
-- Join customer, sales, and product data
FROM customers c
JOIN sales_data s
ON c.customer_id = s.customer_id
JOIN products p
ON s.product_id = p.product_id
-- Group results by region and product category
GROUP BY c.region, p.product_category
-- Order results by region first, then sales count in descending order
ORDER BY c.region, sales_count DESC;Te recomiendo que realices nuestro curso «Unir datos en SQL» para aprender los diferentes tipos de uniones y cómo utilizarlas en consultas anidadas. Puedes descargar nuestra Guía rápida de uniones SQL para obtener más información sobre cómo unir datos en SQL.
La expresión « CASE » (Valor de columna en grupo) de GROUP BY permite realizar agrupaciones personalizadas transformando los valores de las columnas de forma dinámica dentro del proceso de agrupación.
La consulta siguiente clasifica los productos por rango de precios y cuenta la cantidad total vendida por región y categoría de producto.
-- Categorize products by price range and count total quantity sold per region & product category
SELECT
region,
product_category,
-- Categorize based on product price
CASE
WHEN price >= 1000 THEN 'High-Priced Products'
WHEN price >= 500 THEN 'Mid-Priced Products'
ELSE 'Low-Priced Products'
END AS price_category,
SUM(quantity) AS total_quantity
FROM Sales
-- Group by region, product category, and price category
GROUP BY
region,
product_category,
CASE
WHEN price >= 1000 THEN 'High-Priced Products'
WHEN price >= 500 THEN 'Mid-Priced Products'
ELSE 'Low-Priced Products'
END
-- Sort results for easier interpretation
ORDER BY
region,
product_category,
total_quantity DESC;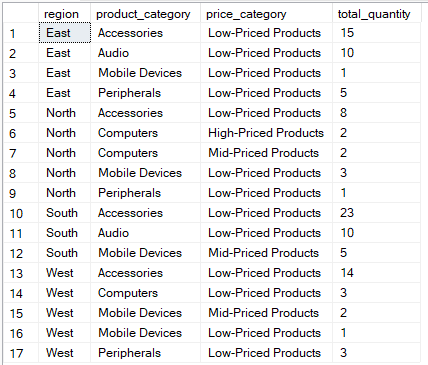
A medida que sigas utilizando la cláusula GROUP BY para agrupar varias columnas, reconocerás los patrones recurrentes que te permitirán mejorar su uso. Analizaremos estos casos habituales teniendo en cuenta aspectos relacionados con el rendimiento.
Es posible que hayas observado que la mayoría de los conjuntos de datos tienen jerarquías inherentes, como la geografía (continente → país → ciudad), las categorías de productos o las estructuras organizativas. Por lo tanto, la cláusula « GROUP BY » es ideal para resumir datos en diferentes niveles de estas jerarquías.
Cuando se presentan datos con fechas y marcas de tiempo, el análisis temporal puede ayudar a identificar tendencias, estacionalidad y comportamientos basados en el tiempo agrupándolos por partes de la fecha, como año, trimestre, mes o día.
Anteriormente, hablamos de dos tipos de patrones de agrupación. Las agrupaciones jerárquicas incluyen columnas que tienen una relación natural y anidada, como agrupar primero por departamento y luego, dentro de cada departamento, por equipo. Por el contrario, las agrupaciones no jerárquicas mezclan dimensiones no relacionadas, como el tipo de producto y el método de pago, mostrando combinaciones sin ningún orden ni estructura implícitos.
Cuando utilices GROUP BY con varias columnas, puedes mejorar el rendimiento siguiendo estos consejos prácticos:
Limitar las columnas de agrupación: Asegúrate siempre de agrupar por columnas necesarias para el análisis a fin de reducir la sobrecarga computacional de los grupos.
Optimización del índice: Asegúrate de que las columnas agrupadas estén indexadas para acelerar el rendimiento de las consultas, ya que esto ayuda a la base de datos a gestionar las operaciones de clasificación de forma más eficiente.
Filtra desde el principio: Utiliza la cláusula « WHERE » para limitar el conjunto de datos antes de agruparlos y reducir así la cantidad de datos que se procesan.
Utiliza planes de consulta y sugerencias: Revisa los planes de ejecución o añade sugerencias de consulta si tu base de datos los admite para ayudar a optimizar el proceso de agrupación.
Aprovecha las funciones avanzadas de SQL: Considera la posibilidad de utilizar técnicas como ROLLUP o GROUPING SETS para crear resúmenes de forma más eficiente y evitar ejecutar consultas repetitivas, especialmente cuando trabajes con datos jerárquicos o multidimensionales.
GROUP BY También puede ser una forma práctica de limpiar tus datos al eliminar duplicados en función de campos específicos. Esto resulta útil cuando el conjunto de datos tiene varias filas idénticas o parcialmente duplicadas.
Por ejemplo, para eliminar registros de ventas duplicados, agruparás por region, product_category y product_name, y luego seleccionarás el precio más alto por grupo para conservar el registro más relevante.
-- Remove duplicate sales records by keeping only unique combinations
-- of region, product_category, and product_name
SELECT
region,
product_category,
product_name,
MAX(price) AS price,
SUM(quantity) AS total_quantity
FROM Sales
GROUP BY
region,
product_category,
product_name
ORDER BY
region,
product_category,
product_name;Cuando trabajes con GROUP BY en varias columnas, ten en cuenta estos errores comunes:
Uno de los errores más frecuentes en las consultas de la tabla de valores ( GROUP BY ) está relacionado con la especificación incorrecta de las columnas. SQL requiere que, al seleccionar varias columnas que no estén envueltas en una función agregada, estas se incluyan en la cláusula GROUP BY. Si no lo haces, se producirá un error. Por lo tanto, incluye siempre las columnas no agregadas en la cláusula « GROUP BY » si se incluyen en la instrucción « SELECT ».
También pueden aparecer errores si los datos que estás agrupando contienen discrepancias, especialmente cuando agrupas por expresiones. Supongamos que estás agrupando tus datos por una fecha formateada. En ese caso, aparecerá un error si los valores de fecha tienen formatos o niveles de precisión diferentes, lo que dará lugar a resultados inesperados o incorrectos.
El uso de consultas « GROUP BY » puede ralentizar en ocasiones la base de datos, especialmente si se agrupan columnas con muchos valores únicos (cardinalidad alta) o si dichas columnas no están indexadas. Los conjuntos de datos grandes también necesitan suficiente memoria para gestionar los pasos de clasificación y agrupación, lo que aumenta la carga.
Para evitar estos problemas, indexa siempre las columnas y filtra utilizando WHERE para limitar los datos que consultas.
Además, es importante saber cómo gestiona SQL los valores NULL en la agrupación: todos los valores NULL de una columna de agrupación se tratan como el mismo grupo, independientemente de cuántos haya. Sin embargo, NULL nunca se considera igual a ningún valor real (no NULL), por lo que esos grupos permanecen diferenciados.
El uso de la cláusula « GROUP BY » para agrupar varias columnas en SQL es una técnica muy eficaz que permite realizar análisis multidimensionales más profundos mediante la agregación de datos en combinaciones de campos. Permite a los analistas ir más allá de los resúmenes básicos y obtener más información sobre los patrones y las relaciones dentro de los datos. Esta capacidad es importante para la elaboración de informes, el seguimiento del rendimiento y la toma de decisiones en los entornos empresariales modernos.
A medida que los datos aumentan en complejidad y volumen, SQL sigue siendo una herramienta fundamental en el análisis. Para mejorar aún más tus habilidades, considera explorar las funciones de ventana, las expresiones de tabla comunes (CTE) y las vistas materializadas, que abren la puerta a transformaciones de datos y flujos de trabajo de generación de informes aún más avanzados.
Te recomiendo que realices nuestro curso «Estadísticas resumidas y funciones de ventana de PostgreSQL» para aprender a escribir consultas para análisis empresariales utilizando funciones de ventana como un profesional. También te reto a que pruebes nuestros proyectos: Análisis de las emisiones de carbono de la industria y análisis de las ventas de piezas de motocicletas para poner a prueba tus habilidades con SQLy demostrar tu dominio del uso de SQL para resolver problemas empresariales.
Aprende SQL con DataCamp
Curso
Curso
Curso
Tutorial
Eugenia Anello
Tutorial
DataCamp Team
Tutorial
Allan Ouko
Tutorial
Elena Kosourova
Tutorial
Sejal Jaiswal
Tutorial
Travis Tang
