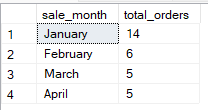

Curso
Estatísticas Resumo e Funções de Janela no PostgreSQL
4 h
125.3K
Embora seja comum agrupar por uma única coluna, agrupar por várias colunas permite resumir grandes conjuntos de dados agrupando linhas que compartilham valores comuns, facilitando a identificação de padrões, tendências e valores atípicos.
Neste guia, vou explicar como funciona a cláusula “ GROUP BY ”, métodos avançados de agrupamento e as melhores práticas. Se você é novo no SQL, considere começar com nosso curso Introdução ao SQL ou curso SQL intermediário para construir uma base sólida. Além disso, acho que a Folha de Referência Básica do SQL, que você pode baixar, é uma referência útil porque tem todas as funções mais comuns do SQL.
Antes de explicar como agrupar por várias colunas no SQL, vamos primeiro entender os conceitos básicos da cláusula GROUP BY.
A cláusula " GROUP BY " no SQL organiza dados iguais em grupos. Ele verifica as linhas em um banco de dados e agrupa as linhas com os mesmos valores nas colunas especificadas, permitindo a agregação de dados dentro desses grupos.
Você pode usar a cláusula “ GROUP BY ” com funções agregadas como “ COUNT() ”, “ SUM() ”, “ AVG() ”, “ MIN() ” e “ MAX() ” para fazer cálculos para resumos em cada grupo de linhas.
Digamos que você está analisando dados de vendas e quer saber a receita total por região. O GROUP BY permite agrupar as vendas por região e calcular a soma de cada uma em uma única consulta.
O banco de dados processa a cláusula “ GROUP BY ” em uma única coluna, verificando as linhas e segmentando-as de acordo com os valores distintos nessa coluna. Cada valor diferente forma um grupo, e as funções de agregação calculam os resultados dentro de cada grupo.
Mas, quando você coloca várias colunas, o SQL junta os dados com base em cada combinação única dessas colunas. Isso quer dizer que o banco de dados divide os dados em grupos menores e mais refinados, definidos por todos os valores de coluna especificados.
Essa abordagem de partição permite uma agregação multidimensional. Isso é útil para inteligência empresarial e análises detalhadas. Permite uma análise detalhada, juntando dados de várias dimensões. Por exemplo, você pode agrupar as vendas por região e categoria de produto.
Como você viu, agrupar dados por várias colunas permite obter mais insights. Agora vamos ver como o SQL lida com esse agrupamento.
Quando você agrupa por mais de uma coluna no SQL, o mecanismo do banco de dados trata a combinação de colunas como chaves compostas. Cada uma dessas combinações únicas forma um grupo diferente. Por exemplo, se você agrupar os dados de vendas por region e product_type, vai ter um grupo separado para cada par único, tipo ('West', 'Electronics'), ('East', 'Furniture'), e assim por diante.
Isso cria um padrão hierárquico de subgrupos, onde a primeira coluna faz os grupos principais, a segunda coluna divide esses grupos principais em subgrupos e assim por diante. Esse agrupamento em camadas melhora a granularidade dos dados, dividindo as informações em categorias detalhadas.
Também é importante saber que tem uma diferença entre agrupamento hierárquico e não hierárquico. O agrupamento hierárquico segue o agrupamento e subagrupamento das colunas seguindo uma sequência específica. Por outro lado, o agrupamento não hierárquico considera cada coluna como uma dimensão diferente e não segue uma hierarquia embutida. Mesmo assim, o agrupamento não hierárquico cria combinações úteis para análise, como quando você quer agrupar as vendas de produtos por estação do ano.
No SQL, a ordem em que você lista as colunas em uma cláusula GROUP BY é muito importante. Quando você agrupa por várias colunas, o SQL trata essas colunas juntas como uma chave combinada, tipo juntar várias peças para identificar cada grupo de forma única.
O SQL processa as colunas da esquerda para a direita. Isso quer dizer que primeiro ele agrupa os dados pela primeira coluna que você listar e, depois, dentro de cada um desses grupos, ele agrupa ainda mais pela coluna seguinte e assim por diante. Essa ordem pode influenciar a eficiência com que o banco de dados processa a consulta, como usa os índices e como os agrupamentos intermediários são criados, principalmente quando se trabalha com conjuntos de dados grandes.
Por exemplo, se você quiser agrupar seus dados por região e produto, os dados são primeiro agrupados por região e, em seguida, dentro de cada região, são agrupados por produto. Mas se você trocar a ordem para (produto, região), vai mudar a hierarquia de agrupamento, o que pode levar a resultados e interpretações diferentes nos seus relatórios.
Vamos ver a sintaxe e as variações da cláusula “ GROUP BY ” no SQL pra entender tudo direitinho.
Para usar uma cláusula “ GROUP BY ” em várias colunas, você precisa listar cada coluna na instrução “ SELECT ”, separadas por vírgulas. O banco de dados vai juntar as linhas com base nas combinações únicas desses valores de coluna.
SELECT column1, column2, AGGREGATE_FUNCTION(column3)
FROM table_name
GROUP BY column1, column2;Sempre certifique-se de que todas as colunas usadas na instrução ` SELECT `, que não fazem parte de funções agregadas, apareçam na cláusula ` GROUP BY ` para evitar erros e garantir uma agregação legível.
Digamos que você tem uma tabela Sales com a seguinte estrutura:
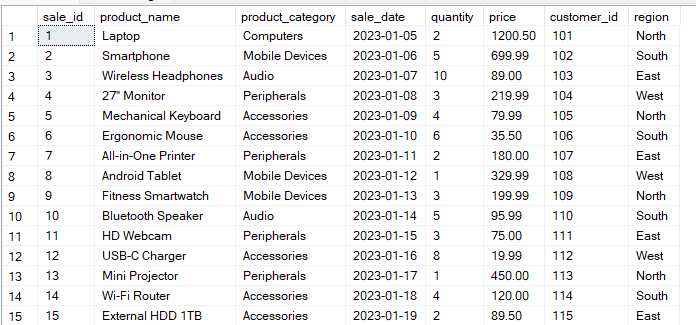
A consulta abaixo agrupa os dados pelas colunas “ region ” e “ product_category ”. Depois, calcula o valor de diferença entre grupos ( total_sales ) para cada combinação de grupos.
-- Group Sales by region and product category
SELECT region, product_category, SUM(quantity) AS total_sales
FROM Sales
GROUP BY region, product_category;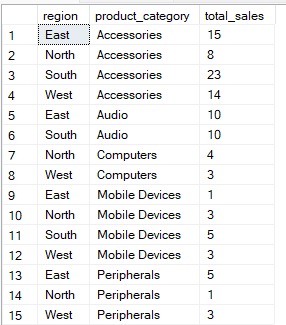
Abaixo estão os diferentes métodos que você pode usar a cláusula GROUP BY em várias colunas no SQL:
Em vez de usar nomes de colunas, o SQL permite indicar a posição das colunas na cláusula GROUP BY. No nosso exemplo anterior, 1 se refere à coluna region e 2 à coluna product_category. Esse método é compatível com MySQL e PostgreSQL, mas não com SQL Server.
-- Group Sales by region and product category
SELECT region, product_category, SUM(quantity) AS total_sales
FROM Sales
GROUP BY 1, 2;Você também pode agrupar por expressões derivadas ou valores calculados. Isso é útil para agrupar dados transformados, como o ano a partir de uma data ou subcadeias. Por exemplo, a consulta abaixo agrupa as vendas por mês, usando os dados da tabela “vendas”, que tem colunas como “mês”, “produto” sale_date.
-- Group Sales by month derived from date column
SELECT
DATENAME(MONTH, sale_date) AS sale_month,
COUNT(*) AS total_orders
FROM Sales
GROUP BY DATENAME(MONTH, sale_date), MONTH(sale_date)
ORDER BY MONTH(sale_date);
Selecionando várias colunas, mas agrupando por apenas uma
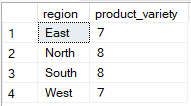
O SQL permite selecionar várias colunas enquanto agrupa por apenas uma, mas somente se as colunas adicionais forem usadas dentro de funções agregadas. No exemplo abaixo, só region está na cláusula GROUP BY, enquanto product_id é usado numa função agregada (COUNT(DISTINCT)), tornando a consulta válida.
-- Group Sales by region only
SELECT region, COUNT(DISTINCT sale_id) AS product_variety
FROM Sales
GROUP BY region;
Recomendo experimentar nosso projeto Analisando e formatando dados de vendas do PostgreSQL para entender como manipular dados no PostgreSQL. Além disso, o Folha de Referência do MySQL Basics vai ser um guia de referência útil para consultas básicas em tabelas, filtragem de dados e agregação de dados, especialmente se você preferir usar o MySQL.
A vantagem da cláusula GROUP BY no SQL é que você pode usá-la com funções agregadas para obter um resumo dos dados agrupados.
As funções agregadas oferecem insights multidimensionais em várias combinações de dados ao agrupar por várias colunas. Essas são as funções mais usadas com a cláusula “ GROUP BY ”:
SUM(): Soma todos os valores numa coluna numérica para cada grupo.
COUNT(): Conta o número de linhas ou valores não nulos em cada grupo.
AVG(): Calcula o valor médio dentro de cada grupo.
MIN(): Encontra o menor valor em cada grupo.
MAX(): Encontra o maior valor em cada grupo.
Por exemplo, a consulta abaixo calcula o total de vendas e a contagem de registros de vendas para cada combinação de região e categoria de produto.
-- Group by region, product_category then aggregate
SELECT region, product_category, SUM(quantity) AS total_sales, COUNT(*) AS sales_count
FROM Sales
GROUP BY region, product_category;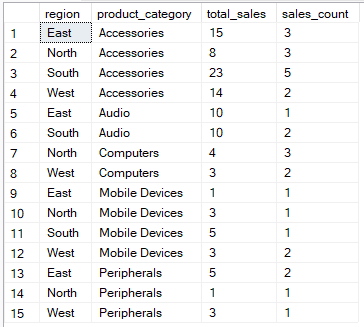
Nos exemplos acima, você viu que a cláusula ` GROUP BY ` é usada com funções agregadas. Mas dá pra usar sem agregação se você quiser agrupar linhas pelas colunas especificadas, mas sem o resumo.
Por exemplo, a consulta abaixo mostra pares únicos de região e categoria de produto sem agregação. Então, dá pra usar esse método pra conferir se os dados estão certos.
--Group by multiple columns without aggregate
SELECT region, product_category
FROM Sales
GROUP BY region, product_category;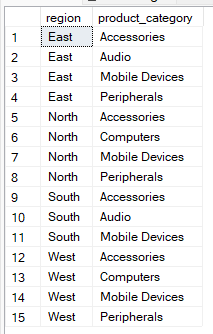
Agora que vimos como podemos agrupar por várias colunas, vamos ver as diferentes operações avançadas de agrupamento usadas com a cláusula “ GROUP BY ”.
A operação ROLLUP usa a cláusula padrão GROUP BY, criando níveis de resumo que são agrupados nas colunas especificadas. Além de mostrar grupos detalhados, também adiciona subtotais e um total geral, juntando tudo passo a passo da direita para a esquerda nas colunas que você agrupar.
Por exemplo, na consulta abaixo, você obtém o “ total_quantity ” para cada combinação de “ region ” e “ product_category. ”. Os resultados incluem subtotais para cada região (onde “ product_category ” aparece como “ NULL ”) e um total geral que soma tudo em todas as regiões e categorias.
-- Group by region, product_category and ROLLUP by region
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY ROLLUP(region, product_category);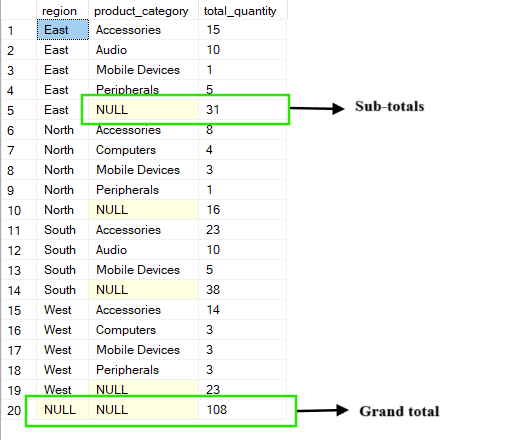
A operação “ CUBE ” gera todas as combinações possíveis das colunas de agrupamento. Diferente da operação “ ROLLUP ”, que cria uma hierarquia, “ CUBE ” cria um cubo de dados completo com agregações.
Ele mostra uma tabulação cruzada das agregações para cada subconjunto das colunas que você escolheu. A saída da operação “ CUBE ” inclui resumos para cada coluna, todas as combinações de colunas e o total geral.
Por exemplo, se a gente consultar a tabela acima e agrupar pelas colunas (region, product_category), a operação CUBE vai gerar as seguintes combinações:
(region, product_category)
(region, NULL)
(NULL, product_category)
(NULL, NULL), que é o total geral.
-- Group by multiple columns using CUBE operation
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY CUBE(region, product_category);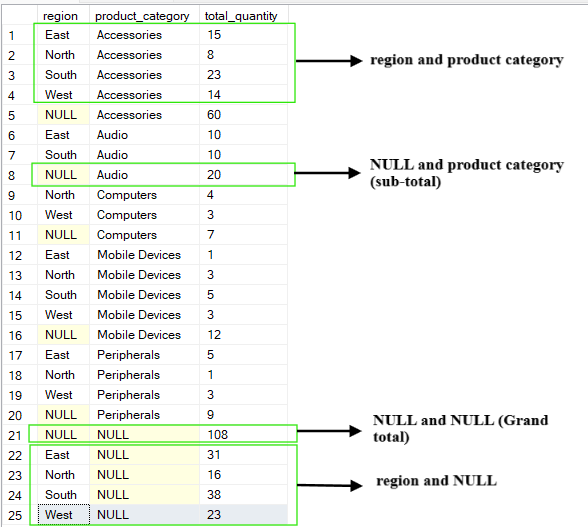
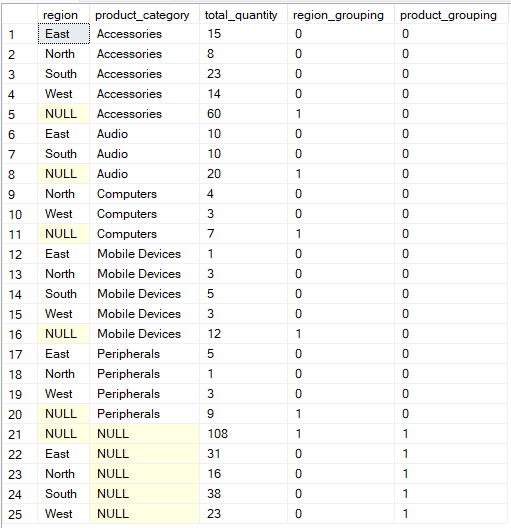
Se você quer um controle mais flexível sobre como seus dados são agrupados, a operação “ GROUPING SETS ” permite definir explicitamente vários agrupamentos em uma única consulta.
Nesse caso, a função ` GROUPING() ` fornece metadados sobre quais colunas são agregadas em cada linha do resultado, identificando os valores NULL que representam linhas de subtotal ou total, em vez de dados realmente ausentes.
-- Group by multiple columns using GROUPING SETS operation
SELECT region, product_category, SUM(quantity) AS total_quantity,
GROUPING(region) AS region_grouping,
GROUPING(product_category) AS product_grouping
FROM Sales
GROUP BY GROUPING SETS (
(region, product_category),
(region),
(product_category),
()
);
Quando você estiver escrevendo consultas que agrupam várias colunas, é importante otimizá-las para melhorar a eficiência e o desempenho geral do banco de dados. Aqui vão algumas dicas práticas que usei pra ajudar na otimização de consultas e gerenciamento de recursos.
Para manter suas consultas funcionando bem e usando o mínimo de recursos:
Identifique os gargalos de desempenho: as consultas do GROUP BY podem ficar lentas quando lidam com grandes conjuntos de dados por causa da varredura, classificação e agregação de muitos dados. Para evitar esse problema, sempre filtre logo com uma cláusula “ WHERE ” e não pegue dados que você não precisa.
Use a indexação de forma eficaz: Indexar colunas deixa o GROUP BY mais rápido. Criar índices compostos nas colunas usadas na cláusula GROUP BY ajuda o mecanismo de banco de dados a localizar e agrupar linhas rapidamente, sem precisar fazer varreduras ou classificações completas e caras nas tabelas.
Limitar colunas: Só inclua as colunas que você precisa para agrupar e analisar, pra deixar tudo mais simples e melhorar o desempenho.
Aproveite os planos de consulta: Quando puder, dá uma olhada nos planos de execução ou usa dicas de consulta pra ajudar o otimizador do banco de dados a escolher as melhores estratégias.
A memória é super importante pro desempenho das consultas d GROUP BY. Classificar e agrupar dados muitas vezes precisa guardar dados intermediários na memória. Se não tiver memória suficiente, tudo fica bem mais lento.
Para gerenciar melhor os recursos:
Além disso, lembre-se de que o tamanho dos seus dados tem um grande impacto no desempenho. Conjuntos de dados grandes com muitas combinações únicas de grupos usam mais memória e poder de processamento. Técnicas como dividir tabelas grandes, criar tabelas de resumo antes ou usar visualizações materializadas ajudam a manter tudo sob controle.
A cláusula ` GROUP BY ` funciona bem com outras cláusulas SQL, tornando suas consultas mais poderosas e flexíveis. Depois, você vai ver exemplos práticos de como juntar GROUP BY com diferentes cláusulas SQL pra melhorar sua análise.
A cláusula “ WHERE ” filtra as linhas antes do agrupamento. Limita o conjunto de dados para que só as linhas necessárias sejam incluídas no processo de agregação. Por exemplo, a consulta abaixo agrupa por region and product_category`, mas inclui registros em que a região é “Norte”.
-- Group by multiple columns, filter using WHERE clause
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
WHERE region = 'North'
GROUP BY region, product_category;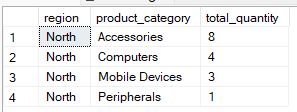
O HAVING, por outro lado, filtra após a agregação. É usado pra limitar quais grupos aparecem no resultado final com base nos valores agregados. A consulta abaixo agrupa por region and product_category but includes records where the total_quantity` é maior que 5.
-- Group by multiple columns, filter using HAVING clause
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY region, product_category
HAVING SUM(quantity) > 4;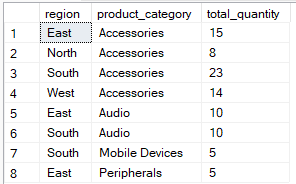
Na ordem de execução do SQL, ta cláusula ORDER BY vem depois da cláusula GROUP BY e é usada para classificar os resultados agrupados, facilitando a leitura ou o processamento posterior. Usando os índices certos e escolhendo com cuidado a ordem das colunas na cláusula “ ORDER BY ”, você pode acelerar sua consulta, reduzindo o trabalho necessário para classificar os dados.
Por exemplo, essa consulta agrupa os dados por region e product_category e, em seguida, classifica os resultados para que os grupos com o maior total_quantity apareçam primeiro.
-- Group by multiple columns, ORDER BY total_quantity
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY region, product_category
ORDER BY total_quantity DESC;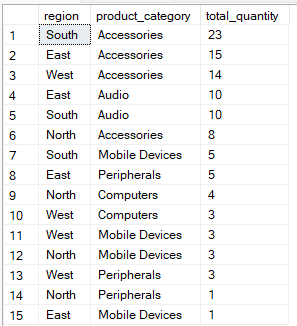
JOIN Você também pode juntar operações de tabela com a cláusula " GROUP BY " para agrupar dados em várias tabelas relacionadas. É bom tomar cuidado ao usar esse método, pois ele pode complicar as coisas por juntar dados maiores.
-- Retrieve the number of sales per region and product category
SELECT
c.region,
p.product_category,
COUNT(*) AS sales_count
-- Join customer, sales, and product data
FROM customers c
JOIN sales_data s
ON c.customer_id = s.customer_id
JOIN products p
ON s.product_id = p.product_id
-- Group results by region and product category
GROUP BY c.region, p.product_category
-- Order results by region first, then sales count in descending order
ORDER BY c.region, sales_count DESC;Recomendo fazer nosso curso Joining Data in SQL para aprender os diferentes tipos de junções e como usá-las em consultas aninhadas. Você pode baixar nossa Guia rápido de junções SQL para referência e saber mais sobre como juntar dados no SQL.
A expressão “ CASE ” em “ GROUP BY ” permite agrupamentos personalizados, transformando os valores das colunas de forma dinâmica durante o processo de agrupamento.
A consulta abaixo classifica os produtos por faixa de preço e conta a quantidade total vendida por região e categoria de produto.
-- Categorize products by price range and count total quantity sold per region & product category
SELECT
region,
product_category,
-- Categorize based on product price
CASE
WHEN price >= 1000 THEN 'High-Priced Products'
WHEN price >= 500 THEN 'Mid-Priced Products'
ELSE 'Low-Priced Products'
END AS price_category,
SUM(quantity) AS total_quantity
FROM Sales
-- Group by region, product category, and price category
GROUP BY
region,
product_category,
CASE
WHEN price >= 1000 THEN 'High-Priced Products'
WHEN price >= 500 THEN 'Mid-Priced Products'
ELSE 'Low-Priced Products'
END
-- Sort results for easier interpretation
ORDER BY
region,
product_category,
total_quantity DESC;
À medida que você continuar usando a cláusula GROUP BY para agrupar várias colunas, você vai perceber os padrões que se repetem e vai melhorar seu uso. Vamos falar sobre essas coisas que rolam com considerações sobre desempenho.
Você já deve ter percebido que a maioria dos conjuntos de dados tem hierarquias, tipo geografia (continente → país → cidade), categorias de produtos ou estruturas organizacionais. Então, a cláusula “ GROUP BY ” é perfeita pra resumir dados em diferentes níveis dessas hierarquias.
Quando a gente vê dados com datas e horários, a análise temporal pode ajudar a identificar tendências, sazonalidade e comportamentos baseados no tempo, agrupando por partes da data, como ano, trimestre, mês ou dia.
Antes, a gente falou sobre dois tipos de padrões de agrupamento. Os agrupamentos hierárquicos envolvem colunas que têm uma relação natural e aninhada, como agrupar primeiro por departamento e, depois, dentro de cada departamento, por equipe. Já os agrupamentos não hierárquicos misturam dimensões que não têm nada a ver, tipo tipo de produto e forma de pagamento, mostrando combinações sem nenhuma ordem ou estrutura implícita.
Quando estiver usando GROUP BY com várias colunas, você pode melhorar o desempenho seguindo essas dicas práticas:
Limitar colunas de agrupamento: Sempre certifique-se de agrupar pelas colunas necessárias para a análise, pra reduzir a sobrecarga computacional dos grupos.
Otimização do índice: Certifique-se de que as colunas agrupadas estejam indexadas para acelerar o desempenho da consulta, ajudando o banco de dados a lidar com operações de classificação de forma mais eficiente.
Filtra logo: Use a cláusula “ WHERE ” para limitar seu conjunto de dados antes de agrupar, reduzindo assim a quantidade de dados processados.
Use planos de consulta e dicas: Dá uma olhada nos planos de execução ou adiciona dicas de consulta, se o seu banco de dados aceitar, pra ajudar a otimizar o processo de agrupamento.
Aproveite os recursos avançados do SQL: Pense em usar técnicas como ROLLUP ou GROUPING SETS para criar resumos de forma mais eficiente e evitar consultas repetitivas, principalmente quando estiver trabalhando com dados hierárquicos ou multidimensionais.
GROUP BY também pode ser uma maneira prática de limpar seus dados, removendo tirar os dados que estão repetidos com base em campos específicos. Isso é útil quando o seu conjunto de dados tem várias linhas iguais ou parcialmente duplicadas.
Por exemplo, pra tirar registros de vendas duplicados, você vai agrupar por region, product_category e product_name e, depois, escolher o preço mais alto por grupo pra manter o registro mais relevante.
-- Remove duplicate sales records by keeping only unique combinations
-- of region, product_category, and product_name
SELECT
region,
product_category,
product_name,
MAX(price) AS price,
SUM(quantity) AS total_quantity
FROM Sales
GROUP BY
region,
product_category,
product_name
ORDER BY
region,
product_category,
product_name;Quando estiver usando GROUP BY em várias colunas, lembre-se destas armadilhas comuns:
Um dos erros mais comuns nas consultas do GROUP BY tem a ver com a especificação incorreta das colunas. GROUP BY O SQL exige que, ao selecionar várias colunas que não estejam envolvidas em uma função agregada, elas sejam incluídas na cláusula INCLUDE. Por exemplo, se você selecionar uma coluna e uma coluna que não está envolvida em uma função agregada, e depois selecionar uma coluna que está envolvida Se você não fizer isso, vai aparecer um erro. Então, sempre inclua as colunas não agregadas na cláusula “ GROUP BY ” se elas estiverem na instrução “ SELECT ”.
Você também pode encontrar erros se os dados que você está agrupando tiverem incompatibilidades, principalmente quando estiver agrupando por expressões. Vamos supor que você está agrupando seus dados por uma data formatada. Nesse caso, você vai ver um erro se os valores da data tiverem formatos ou níveis de precisão diferentes, o que pode levar a resultados inesperados ou errados.
Usar consultas GROUP BY às vezes pode deixar seu banco de dados mais lento, principalmente se você estiver agrupando por colunas com muitos valores únicos (cardinalidade alta) ou se essas colunas não estiverem indexadas. Conjuntos de dados grandes também precisam de bastante memória pra lidar com as etapas de classificação e agrupamento, o que aumenta a carga.
Para evitar esses problemas, sempre indexe as colunas e filtre usando WHERE para limitar os dados que você consulta.
Além disso, é importante saber como o SQL lida com valores NULL no agrupamento: todos os NULLs em uma coluna de agrupamento são tratados como o mesmo grupo, não importa quantos existam. Mas, o NULL nunca é igual a nenhum valor real (não NULL), então esses grupos continuam diferentes.
Usar a cláusula “ GROUP BY ” para juntar várias colunas no SQL é uma técnica super útil que permite uma análise mais profunda e multidimensional, juntando dados de várias combinações de campos. Isso permite que os analistas vão além dos resumos básicos e entendam melhor os padrões e as relações entre os dados. Essa capacidade é importante para relatórios, acompanhamento de desempenho e tomada de decisões nos ambientes de negócios modernos.
À medida que os dados ficam mais complexos e aumentam de volume, o SQL continua sendo uma ferramenta essencial na análise. Para melhorar ainda mais suas habilidades, considere explorar funções de janela, expressões de tabela comum (CTEs) e visualizações materializadas, que abrem as portas para transformações de dados e fluxos de trabalho de relatórios ainda mais avançados.
Recomendo fazer nosso curso PostgreSQL Summary Stats and Window Functions pra aprender a escrever consultas pra análise de negócios usando funções Window como um profissional. Também te desafio a experimentar nossos projetos: Analisando as emissões de carbono da indústria e analisando as vendas de peças de motocicletas para testar suas habilidades em SQLe mostrar que você sabe usar SQL para resolver problemas de negócios.
Aprenda SQL com o DataCamp
Curso
Curso
Curso
Tutorial
Eugenia Anello
Tutorial
DataCamp Team
Tutorial
Allan Ouko
Tutorial
Elena Kosourova
Tutorial
Sejal Jaiswal
Tutorial
DataCamp Team
