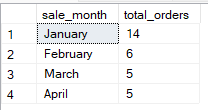

Kurs
PostgreSQL: Zusammenfassende Statistiken und Fensterfunktionen
4 Std.
125.3K
Während das Gruppieren nach einer einzigen Spalte üblich ist, kannst du durch das Gruppieren nach mehreren Spalten große Datensätze zusammenfassen, indem du Zeilen mit gemeinsamen Werten gruppierst. So lassen sich Muster, Trends und Ausreißer leichter erkennen.
In diesem Leitfaden erkläre ich dir, wie die Klausel „ GROUP BY “ funktioniert, zeige dir fortgeschrittene Gruppierungsmethoden und gebe dir Tipps, wie du am besten vorgehst. Wenn du noch keine Erfahrung mit SQL hast, solltest du vielleicht mit unserem Kurs „Einführung in SQL“ oder „SQL für Fortgeschrittene “ anfangen, um dir eine solide Grundlage zu schaffen. Außerdem finde ich das SQL-Grundlagen-Spickzettel, das du runterladen kannst, echt hilfreich, weil es die gängigsten SQL-Funktionen enthält.
Bevor ich erkläre, wie man in SQL nach mehreren Spalten gruppiert, lass uns erst mal die grundlegenden Konzepte der „ GROUP BY “-Klausel verstehen.
Die Klausel „ GROUP BY “ in SQL sortiert gleiche Daten in Gruppen. Es scannt Zeilen in einer Datenbank und gruppiert dann Zeilen mit gleichen Werten in den angegebenen Spalten, sodass Daten innerhalb dieser Gruppen zusammengefasst werden können.
Du kannst die Klausel „ GROUP BY “ mit Aggregatfunktionen wie „ COUNT() “, „ SUM() “, „ AVG() “, „ MIN() “ und „ MAX() “ verwenden, um Berechnungen für Zusammenfassungen jeder Zeichengruppe durchzuführen.
Angenommen, du analysierst Verkaufsdaten und möchtest den Gesamtumsatz pro Region wissen. Mit „ GROUP BY “ kannst du Verkäufe nach Region gruppieren und die Summe für jede Region in einer einzigen Abfrage berechnen.
Die Datenbank verarbeitet die Klausel „ GROUP BY “ für eine einzelne Spalte, indem sie die Zeilen durchsucht und sie nach den eindeutigen Werten in dieser Spalte sortiert. Jeder einzelne Wert bildet eine Gruppe, und Aggregationsfunktionen berechnen die Ergebnisse innerhalb jeder Gruppe.
Wenn du aber mehrere Spalten hinzufügst, gruppiert SQL die Daten nach jeder einzigartigen Kombination dieser Spalten. Das heißt, die Datenbank teilt die Daten in kleinere, genauere Gruppen auf, die durch alle angegebenen Spaltenwerte definiert sind.
Dieser Ansatz zur Aufteilung ermöglicht eine mehrdimensionale Aggregation. Das ist super für detaillierte Business Intelligence und Analysen. Es ermöglicht eine gründliche Analyse, indem es Daten an den Schnittpunkten mehrerer Dimensionen zusammenfasst. Du kannst zum Beispiel Verkäufe nach Region und Produktkategorie gruppieren.
Wie du gesehen hast, kannst du durch das Gruppieren von Daten nach mehreren Spalten mehr Infos bekommen. Schauen wir uns jetzt an, wie SQL diese Gruppierung macht.
Wenn du in SQL nach mehr als einer Spalte gruppierst, sieht die Datenbank-Engine die Spaltenkombination als zusammengesetzte Schlüssel. Jede dieser einzigartigen Kombinationen bildet eine eigene Gruppe. Wenn du zum Beispiel Verkaufsdaten nach „ region “ und „ product_type “ gruppierst, bekommst du für jedes einzigartige Paar eine eigene Gruppe, wie zum Beispiel ('West', 'Electronics'), ('East', 'Furniture') und so weiter.
Das führt zu einer hierarchischen Unterteilung, bei der die erste Spalte die Hauptgruppen bildet, die zweite Spalte diese Hauptgruppen weiter in Untergruppen aufteilt und so weiter. Diese mehrschichtige Gruppierung macht die Daten genauer, indem sie die Infos in detaillierte Kategorien aufteilt.
Beachte auch, dass es einen Unterschied zwischen hierarchischer und nicht-hierarchischer Gruppierung gibt. Die hierarchische Gruppierung folgt der Spaltengruppierung und Untergruppierung der Spalten in einer bestimmten Reihenfolge. Andererseits sieht die nicht-hierarchische Gruppierung jede Spalte als eigene Dimension und folgt keiner festen Hierarchie. Trotzdem sind nicht-hierarchische Gruppierungen super für Analysen, zum Beispiel wenn du Produktverkäufe nach Jahreszeiten sortieren willst.
In SQL ist es echt wichtig, in welcher Reihenfolge du die Spalten in einer GROUP BY-Klausel auflistest. Wenn du nach mehreren Spalten gruppierst, behandelt SQL diese Spalten zusammen als kombinierten Schlüssel, so als würdest du mehrere Teile zusammensetzen, um jede Gruppe eindeutig zu identifizieren.
SQL geht die Spalten von links nach rechts durch. Das heißt, die Daten werden erst nach der ersten Spalte sortiert, dann innerhalb jeder Gruppe nach der nächsten Spalte und so weiter. Diese Reihenfolge kann beeinflussen, wie gut die Datenbank die Abfrage verarbeitet, wie sie Indizes nutzt und wie Zwischengruppen gebildet werden, vor allem bei großen Datensätzen.
Wenn du deine Daten zum Beispiel nach Region und Produkt sortieren willst, werden sie erst nach Region sortiert und dann innerhalb jeder Region nach Produkt. Wenn du aber die Reihenfolge auf (Produkt, Region) änderst, änderst du die Gruppierungshierarchie, was zu anderen Ergebnissen und Interpretationen in deinen Berichten führen kann.
Schauen wir uns mal die Syntax und die Varianten der Klausel „ GROUP BY “ in SQL an, um sie richtig zu verstehen.
Um eine „ GROUP BY “-Klausel in mehreren Spalten zu verwenden, musst du jede Spalte in der „ SELECT “-Anweisung durch Kommas getrennt auflisten. Die Datenbank sortiert dann die Zeilen nach den einzigartigen Kombinationen dieser Spaltenwerte.
SELECT column1, column2, AGGREGATE_FUNCTION(column3)
FROM table_name
GROUP BY column1, column2;Stell immer sicher, dass alle Spalten, die in der Anweisung „ SELECT “ verwendet werden und nicht Teil von Aggregatfunktionen sind, auch in der Klausel „ GROUP BY “ vorkommen, um Fehler zu vermeiden und eine lesbare Aggregation zu gewährleisten.
Angenommen, du hast eine Tabelle „ Sales ” mit folgender Struktur:
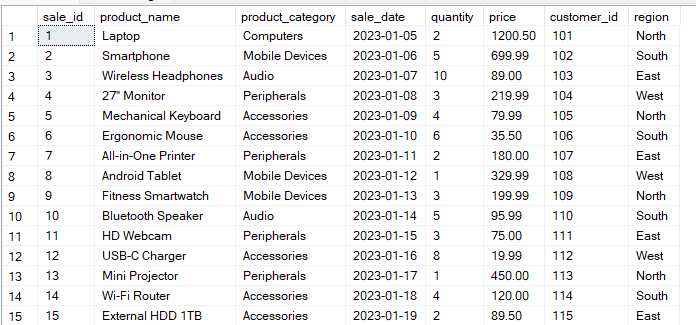
Die folgende Abfrage sortiert die Daten nach den Spalten „ region “ und „ product_category “. Dann wird für jede Gruppenkombination der Wert „ total_sales “ berechnet.
-- Group Sales by region and product category
SELECT region, product_category, SUM(quantity) AS total_sales
FROM Sales
GROUP BY region, product_category;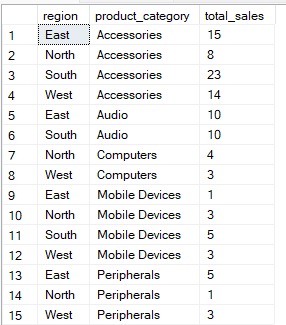
Hier sind die verschiedenen Möglichkeiten, wie du die Klausel „ GROUP BY “ in SQL für mehrere Spalten verwenden kannst:
GROUP BY Anstatt Spaltennamen zu verwenden, kannst du in SQL die Position der Spalten in der Spaltenliste angeben. In unserem vorherigen Beispiel bezieht sich „ 1 “ auf die Spalte „ region “ und „ 2 “ auf die Spalte „ product_category “. Diese Methode wird von MySQL und PostgreSQL unterstützt, aber nicht von SQL Server.
-- Group Sales by region and product category
SELECT region, product_category, SUM(quantity) AS total_sales
FROM Sales
GROUP BY 1, 2;Du kannst auch nach abgeleiteten Ausdrücken oder berechneten Werten gruppieren. Das ist praktisch, wenn du Daten nach ihrer Umwandlung gruppieren willst, zum Beispiel das Jahr aus einem Datum oder Teilzeichenfolgen. Die folgende Abfrage gruppiert zum Beispiel die Verkäufe nach Monat, die aus sale_date.
-- Group Sales by month derived from date column
SELECT
DATENAME(MONTH, sale_date) AS sale_month,
COUNT(*) AS total_orders
FROM Sales
GROUP BY DATENAME(MONTH, sale_date), MONTH(sale_date)
ORDER BY MONTH(sale_date);
Mehrere Spalten auswählen, aber nur nach einer gruppieren
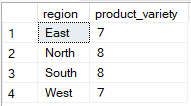
Mit SQL kannst du mehrere Spalten auswählen, während du nach nur einer gruppierst, aber nur, wenn die zusätzlichen Spalten in Aggregatfunktionen verwendet werden. Im folgenden Beispiel steht nur „ region “ in der „ GROUP BY “-Klausel, während „ product_id “ in einer Aggregatfunktion „ (COUNT(DISTINCT)) “ verwendet wird, wodurch die Abfrage gültig wird.
-- Group Sales by region only
SELECT region, COUNT(DISTINCT sale_id) AS product_variety
FROM Sales
GROUP BY region;
Ich empfehle dir, unser Projekt „Analyse und Formatierung von PostgreSQL-Verkaufsdaten”, um zu verstehen, wie man Daten in PostgreSQL bearbeitet. Außerdem gibt's die MySQL-Grundlagen-Spickzettel ist ein praktischer Leitfaden für grundlegende Abfragen von Tabellen, das Filtern und Aggregieren von Daten, vor allem, wenn du MySQL bevorzugst.
Der Vorteil der GROUP BY-Klausel in SQL ist, dass du sie mit Aggregatfunktionen verwenden kannst, um eine Zusammenfassung gruppierter Daten zu erhalten.
Die Aggregatfunktionen bieten mehrdimensionale Einblicke in verschiedene Datenkombinationen, wenn nach mehreren Spalten gruppiert wird. Hier sind die häufig verwendeten Funktionen mit der Klausel „ GROUP BY “:
SUM(): Addiert alle Werte in einer numerischen Spalte für jede Gruppe.
COUNT(): Zählt die Anzahl der Zeilen oder Nicht-Null-Werte in jeder Gruppe.
AVG(): Berechnet den Durchschnittswert innerhalb jeder Gruppe.
MIN(): Sucht den kleinsten Wert in jeder Gruppe.
MAX(): Sucht den größten Wert in jeder Gruppe.
Die folgende Abfrage berechnet zum Beispiel den Gesamtumsatz und die Anzahl der Verkaufsdatensätze für jede Kombination aus Region und Produktkategorie.
-- Group by region, product_category then aggregate
SELECT region, product_category, SUM(quantity) AS total_sales, COUNT(*) AS sales_count
FROM Sales
GROUP BY region, product_category;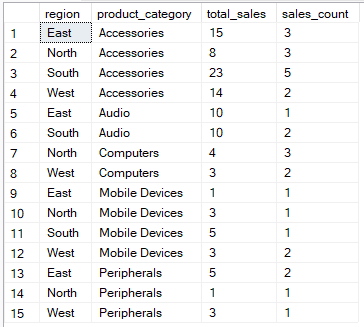
In den obigen Beispielen hast du gesehen, dass die Klausel „ GROUP BY “ zusammen mit Aggregatfunktionen verwendet wird. Aggregatfunktionenverwendet wird. Du kannst es aber auch ohne Aggregation benutzen, wenn du Zeilen nach den angegebenen Spalten gruppieren willst, aber ohne die Zusammenfassung.
Die folgende Abfrage zeigt zum Beispiel eindeutige Paare aus Region und Produktkategorie ohne Aggregation an. Du kannst diese Methode also nutzen, um zu checken, ob die Daten stimmen.
--Group by multiple columns without aggregate
SELECT region, product_category
FROM Sales
GROUP BY region, product_category;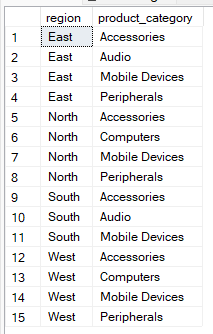
Nachdem wir uns angesehen haben, wie wir nach mehreren Spalten gruppieren können, schauen wir uns die verschiedenen erweiterten Gruppierungsoperationen an, die mit der Klausel „ GROUP BY “ verwendet werden.
Die ROLLUP-Operation baut auf der Standard GROUP BY -Klausel auf, indem sie Zusammenfassungsebenen erstellt, die entlang der angegebenen Spalten zusammengefasst werden. Es werden nicht nur detaillierte Gruppen angezeigt, sondern auch Zwischensummen und eine Gesamtsumme, indem die Spalten, nach denen du gruppierst, Schritt für Schritt von rechts nach links zusammengefasst werden.
In der folgenden Abfrage bekommst du zum Beispiel die „ total_quantity ” für jede Kombination aus „ region ” und „ product_category. ”. Die Ergebnisse zeigen Zwischensummen für jede Region (wo „ product_category ” als „ NULL ” erscheint) und eine Gesamtsumme, die alles über alle Regionen und Kategorien zusammenfasst.
-- Group by region, product_category and ROLLUP by region
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY ROLLUP(region, product_category);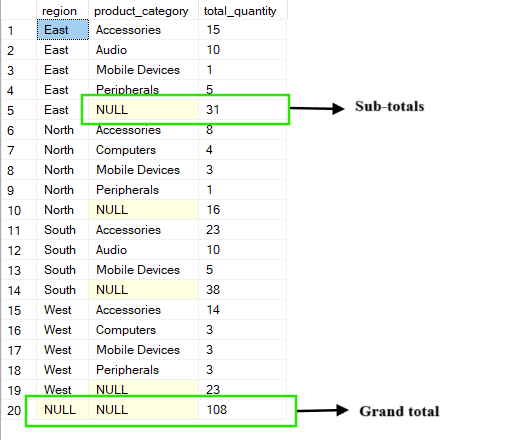
Die Funktion „ CUBE “ macht alle möglichen Kombinationen der Gruppierungsspalten. Anders als die Funktion „ ROLLUP “, die eine Hierarchie erzeugt, macht „ CUBE “ einen kompletten Datenwürfel mit Aggregationen.
Es gibt eine Kreuztabelle mit den Summen für jede Teilmenge der angegebenen Spalten. Die Ausgabe der Funktion „ CUBE “ enthält Zusammenfassungen für jede Spalte, jede Spaltenkombination und die Gesamtsumme.
Wenn wir zum Beispiel die obige Tabelle abfragen und nach den Spalten (region, product_category) gruppieren, ergibt die Operation „ CUBE “ die folgenden Kombinationen:
(region, product_category)
(region, NULL)
(NULL, product_category)
(NULL, NULL), was insgesamt
-- Group by multiple columns using CUBE operation
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY CUBE(region, product_category);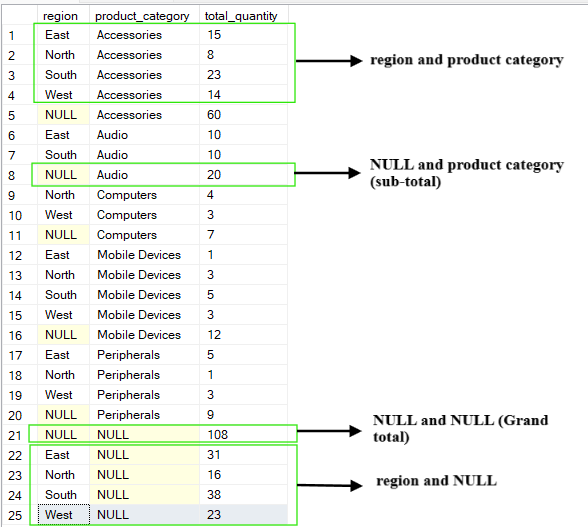
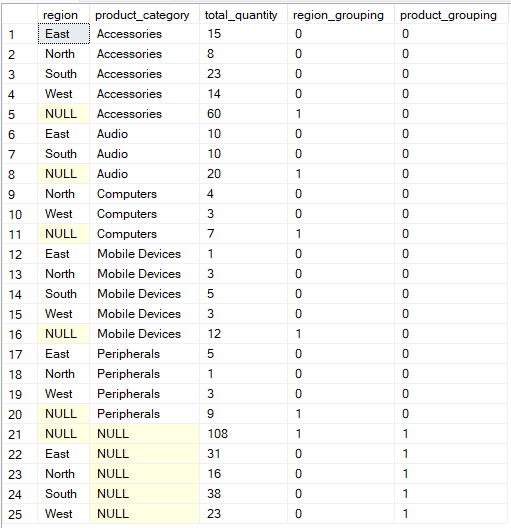
Wenn du deine Daten flexibler gruppieren willst, kannst du mit der Funktion „ GROUPING SETS “ mehrere Gruppierungen in einer einzigen Abfrage festlegen.
In diesem Fall liefert die Funktion „ GROUPING() “ Metadaten darüber, welche Spalten in jeder Zeile des Ergebnisses zusammengefasst sind, und erkennt NULL-Werte, die Zwischensummen- oder Summenzeilen darstellen, anstatt tatsächlich fehlende Daten.
-- Group by multiple columns using GROUPING SETS operation
SELECT region, product_category, SUM(quantity) AS total_quantity,
GROUPING(region) AS region_grouping,
GROUPING(product_category) AS product_grouping
FROM Sales
GROUP BY GROUPING SETS (
(region, product_category),
(region),
(product_category),
()
);
Wenn du Abfragen schreibst, die nach mehreren Spalten gruppiert sind, solltest du sie auf jeden Fall optimieren, damit sie effizienter laufen und die Datenbank insgesamt besser funktioniert. Hier sind ein paar praktische Tipps, die ich für die Optimierung von Abfragen und das Ressourcenmanagement verwendet habe
Damit deine Abfragen reibungslos laufen und nur wenig Ressourcen verbrauchen:
Leistungsengpässe erkennen: Abfragen in der GROUP BY können bei großen Datensätzen langsamer werden, weil viele Daten gescannt, sortiert und zusammengefasst werden müssen. Um das zu vermeiden, filtere immer früh mit einer „ WHERE “-Klausel und hole keine Daten, die du nicht brauchst.
Indexierung effektiv nutzen: Das Indizieren von Spalten macht die Leistung von „ GROUP BY “ schneller. Das Erstellen von zusammengesetzten Indizes für die Spalten, die in der Klausel „ GROUP BY “ verwendet werden, hilft der Datenbank-Engine, Zeilen schnell zu finden und zu gruppieren, ohne dass teure vollständige Tabellen-Scans oder Sortierungen nötig sind.
Spalten begrenzen: Nimm nur Spalten mit, die du für deine Gruppierung und Analyse brauchst, um die Komplexität zu reduzieren und die Leistung zu verbessern.
Abfragepläne nutzen: Wenn möglich, check mal die Ausführungspläne oder nutze Abfragehinweise, um den Datenbankoptimierer auf die besten Strategien hinzuweisen.
Der Speicher ist echt wichtig für die Leistung von „ GROUP BY “-Abfragen. Zum Sortieren und Gruppieren von Daten muss man oft Zwischendaten im Speicher halten. Wenn nicht genug Speicher da ist, wird alles ziemlich langsam.
Um Ressourcen besser zu verwalten:
Denk auch daran, dass die Größe deiner Daten einen großen Einfluss auf die Leistung hat. Große Datensätze mit vielen einzigartigen Gruppenkombinationen brauchen mehr Speicherplatz und Rechenleistung. Techniken wie das Aufteilen großer Tabellen, das Erstellen von Übersichtstabellen im Voraus oder die Verwendung von materialisierten Ansichten helfen dabei, den Überblick zu behalten.
Die Klausel „ GROUP BY “ lässt sich gut mit anderen SQL-Klauseln kombinieren, wodurch deine Abfragen leistungsfähiger und flexibler werden. Als Nächstes zeig ich dir praktische Beispiele, wie du GROUP BY mit verschiedenen SQL-Klauseln kombinieren kannst, um deine Analyse zu verbessern.
Die Klausel „ WHERE “ filtert Zeilen, bevor die Gruppierung passiert. Es schränkt den Datensatz ein, sodass nur die benötigten Zeilen in den Aggregationsprozess einbezogen werden. Die folgende Abfrage gruppiert zum Beispiel nach „ region and product_category“, zeigt aber auch Datensätze, wo die Region „North“ ist.
-- Group by multiple columns, filter using WHERE clause
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
WHERE region = 'North'
GROUP BY region, product_category;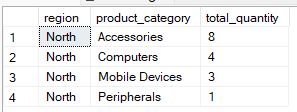
Die HAVING -Klausel filtert dagegen nach der Aggregation. Damit kannst du anhand von Gesamtwerten festlegen, welche Gruppen im Endergebnis angezeigt werden. Die folgende Abfrage gruppiert nach „ region and “ und „product_category“ but includes records where the total_quantity` ist größer als 5.
-- Group by multiple columns, filter using HAVING clause
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY region, product_category
HAVING SUM(quantity) > 4;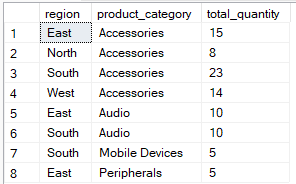
In der SQL-Ausführungsreihenfolge kommt die „the ORDER BY “-Klausel nach der „ GROUP BY “-Klausel und sortiert die gruppierten Ergebnisse, damit sie leichter zu lesen oder weiterzuverarbeiten sind. Mit den richtigen Indizes und einer cleveren Spaltenreihenfolge in der „ ORDER BY “-Klausel kannst du deine Abfrage beschleunigen, weil du weniger Daten sortieren musst.
Diese Abfrage gruppiert zum Beispiel die Daten nach „ region “ und „ product_category “ und sortiert die Ergebnisse so, dass die Gruppen mit dem höchsten „ total_quantity “ zuerst angezeigt werden.
-- Group by multiple columns, ORDER BY total_quantity
SELECT region, product_category, SUM(quantity) AS total_quantity
FROM Sales
GROUP BY region, product_category
ORDER BY total_quantity DESC;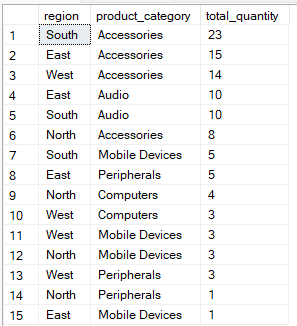
Du kannst auch „ JOIN “-Operationen mit der „ GROUP BY “-Klausel kombinieren, um Daten aus mehreren verbundenen Tabellen zu gruppieren. Sei vorsichtig bei dieser Methode, da sie durch das Zusammenführen größerer Datenmengen zu Komplexität führen kann.
-- Retrieve the number of sales per region and product category
SELECT
c.region,
p.product_category,
COUNT(*) AS sales_count
-- Join customer, sales, and product data
FROM customers c
JOIN sales_data s
ON c.customer_id = s.customer_id
JOIN products p
ON s.product_id = p.product_id
-- Group results by region and product category
GROUP BY c.region, p.product_category
-- Order results by region first, then sales count in descending order
ORDER BY c.region, sales_count DESC;Ich empfehle dir, unseren Kurs „Joining Data in SQL”, um die verschiedenen Arten von Verknüpfungen kennenzulernen und zu lernen, wie man sie in verschachtelten Abfragen benutzt. Du kannst unser SQL-Joins-Spickzettel als Referenz herunterladen, um mehr über das Verknüpfen von Daten in SQL zu erfahren.
Der Ausdruck „ CASE “ in „ GROUP BY “ ermöglicht benutzerdefinierte Gruppierungen, indem Spaltenwerte während des Gruppierungsvorgangs dynamisch umgewandelt werden.
Die folgende Abfrage sortiert die Produkte nach Preisklasse und zählt die Gesamtmenge, die pro Region und Produktkategorie verkauft wurde.
-- Categorize products by price range and count total quantity sold per region & product category
SELECT
region,
product_category,
-- Categorize based on product price
CASE
WHEN price >= 1000 THEN 'High-Priced Products'
WHEN price >= 500 THEN 'Mid-Priced Products'
ELSE 'Low-Priced Products'
END AS price_category,
SUM(quantity) AS total_quantity
FROM Sales
-- Group by region, product category, and price category
GROUP BY
region,
product_category,
CASE
WHEN price >= 1000 THEN 'High-Priced Products'
WHEN price >= 500 THEN 'Mid-Priced Products'
ELSE 'Low-Priced Products'
END
-- Sort results for easier interpretation
ORDER BY
region,
product_category,
total_quantity DESC;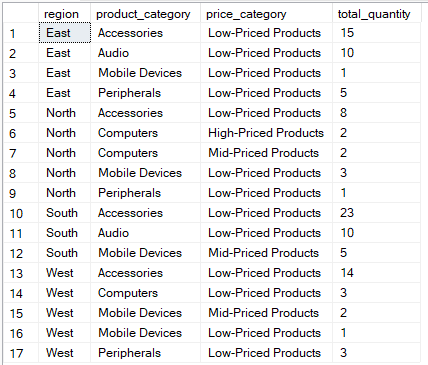
Wenn du die Klausel „ GROUP BY “ zum Gruppieren mehrerer Spalten weiter verwendest, wirst du wiederkehrende Muster erkennen, die dir die Verwendung erleichtern. Wir werden diese häufig auftretenden Probleme unter Berücksichtigung der Leistungsaspekte besprechen.
Du hast vielleicht schon gemerkt, dass die meisten Datensätze eine eingebaute Hierarchie haben, wie zum Beispiel Geografie (Kontinent → Land → Stadt), Produktkategorien oder Organisationsstrukturen. Deshalb ist die Klausel „ GROUP BY “ super, um Daten auf verschiedenen Ebenen dieser Hierarchien zusammenzufassen.
Wenn du Daten mit Datums- und Zeitstempeln hast, kann eine zeitliche Analyse helfen, Trends, Saisonalität und zeitbasiertes Verhalten zu erkennen, indem sie nach Datumsangaben wie Jahr, Quartal, Monat oder Tag gruppiert werden.
Vorhin haben wir über zwei Arten von Gruppierungsmustern gesprochen. Hierarchische Gruppierungen bestehen aus Spalten, die eine natürliche, verschachtelte Beziehung zueinander haben, wie zum Beispiel eine Gruppierung zuerst nach Abteilung und dann innerhalb jeder Abteilung nach Team. Im Gegensatz dazu mischen nicht-hierarchische Gruppierungen verschiedene Sachen, wie zum Beispiel Produkttyp und Zahlungsmethode, und zeigen Kombinationen ohne eine bestimmte Reihenfolge oder Struktur.
Wenn du „ GROUP BY “ mit mehreren Spalten verwendest, kannst du die Leistung mit diesen praktischen Tipps verbessern:
Säulen gruppieren begrenzen: Achte immer darauf, dass du nach den Spalten gruppierst, die für die Analyse wichtig sind, um den Rechenaufwand für Gruppen zu reduzieren.
Indexoptimierung: Stell sicher, dass die gruppierten Spalten indiziert sind, damit die Datenbank Sortiervorgänge besser hinkriegt und die Abfragen schneller laufen.
Frühzeitig filtern: Verwende die Klausel „ WHERE “, um deinen Datensatz vor dem Gruppieren zu begrenzen und so die zu verarbeitende Datenmenge zu reduzieren.
Verwende Abfragepläne und Hinweise: Schau dir die Ausführungspläne an oder füge Abfragehinweise hinzu, wenn deine Datenbank das unterstützt, um den Gruppierungsprozess zu optimieren.
Nutze die coolen SQL-Features: Probier mal Techniken wie ROLLUP oder GROUPING SETS aus, um Zusammenfassungen effizienter zu erstellen und wiederholte Abfragen zu vermeiden, vor allem wenn du mit hierarchischen oder mehrdimensionalen Daten arbeitest.
GROUP BY kann auch eine praktische Möglichkeit sein, deine Daten zu bereinigen, indem du Duplikate basierend auf bestimmten Feldern. Das ist praktisch, wenn dein Datensatz mehrere identische oder teilweise doppelte Zeilen hat.
Um zum Beispiel doppelte Verkaufsdatensätze loszuwerden, gruppierst du nach „ region “, „ product_category “ und „ product_name “ und wählst dann den höchsten Preis pro Gruppe aus, um den relevantesten Datensatz zu behalten.
-- Remove duplicate sales records by keeping only unique combinations
-- of region, product_category, and product_name
SELECT
region,
product_category,
product_name,
MAX(price) AS price,
SUM(quantity) AS total_quantity
FROM Sales
GROUP BY
region,
product_category,
product_name
ORDER BY
region,
product_category,
product_name;Wenn du mit „ GROUP BY “ in mehreren Spalten arbeitest, solltest du auf diese häufigen Fallstricke achten:
Einer der häufigsten Fehler bei Abfragen in „ GROUP BY ” hat mit falschen Spaltenspezifikationen zu tun. SQL verlangt, dass when beim Auswählen mehrerer Spalten nicht in eine Aggregatfunktion eingeschlossen werden dürfen (), sondern in die GROUP BY -Klausel aufgenommen werden müssen. Wenn du das nicht machst, kommt es zu einem Fehler. Also, vergiss nicht, die nicht aggregierten Spalten immer in die „ GROUP BY “-Klausel zu packen, wenn sie in der „ SELECT “-Anweisung enthalten sind.
Es können auch Fehler auftreten, wenn die zu gruppierenden Daten nicht übereinstimmen, insbesondere wenn du nach Ausdrücken gruppierst. Nehmen wir mal an, du gruppierst deine Daten nach einem formatierten Datum. In diesem Fall bekommst du eine Fehlermeldung, wenn die Datumswerte unterschiedliche Formate oder Genauigkeitsstufen haben, was zu unerwarteten oder falschen Ergebnissen führen kann.
GROUP BY -Abfragen können manchmal deine Datenbank verlangsamen, vor allem wenn du nach Spalten mit vielen eindeutigen Werten (hohe Kardinalität) gruppierst oder wenn diese Spalten nicht indiziert sind. Große Datensätze brauchen auch genug Speicherplatz, um die Sortier- und Gruppierungsschritte zu schaffen, was die Belastung erhöht.
Um solche Probleme zu vermeiden, solltest du die Spalten immer indizieren und mit „ WHERE “ filtern, um die abgefragten Daten zu begrenzen.
Außerdem solltest du wissen, wie SQL NULL-Werte beim Gruppieren behandelt: Alle NULL-Werte in einer Gruppierungsspalte werden als dieselbe Gruppe behandelt, egal wie viele es davon gibt. NULL wird aber nie als gleich wie irgendein echter (nicht NULL) Wert angesehen, also bleiben diese Gruppen unterschiedlich.
Mit der „ GROUP BY “-Klausel kannst du mehrere Spalten in SQL zusammenfassen. Das ist echt praktisch, wenn du eine tiefere, mehrdimensionale Analyse machen willst, indem du Daten aus verschiedenen Feldern zusammenfasst. Damit können Analysten über einfache Zusammenfassungen hinausgehen und mehr über Muster und Zusammenhänge in den Daten erfahren. Diese Funktion ist wichtig für die Berichterstellung, Leistungsüberwachung und Entscheidungsfindung in modernen Geschäftsumgebungen.
Da Daten immer komplexer und umfangreicher werden, bleibt SQL ein wichtiges Tool für die Analyse. Um deine Fähigkeiten noch weiter auszubauen, solltest du dich mit Fensterfunktionen, Common Table Expressions (CTEs) und materialisierten Ansichten beschäftigen, die dir die Tür zu noch fortgeschritteneren Datentransformationen und Berichtsworkflows öffnen.
Ich empfehle dir unseren Kurs „PostgreSQL Summary Stats and Window Functions“, um zu lernen, wie du mit Fensterfunktionen wie ein Profi Abfragen für Geschäftsanalysen schreibst. Ich fordere dich auch auf, unsere Projekte auszuprobieren: Analyse der CO2-Emissionen der Industrie und Analyse des Motorradteilverkaufs, um deine SQL-Kenntnisse zu testenund zu zeigen, dass du SQL super drauf hast, um geschäftliche Probleme zu lösen.
Lerne SQL mit DataCamp
Kurs
Kurs
Kurs
Tutorial
Allan Ouko
Tutorial
Sejal Jaiswal
Tutorial
Laiba Siddiqui
Tutorial
Kurtis Pykes
Tutorial
Neetika Khandelwal
Tutorial
Aditya Sharma


