Curso
Introducción a las bases de datos en Python
4 h
101.3K

SQLAlchemy es el conjunto de herramientas SQL de Python que permite a los desarrolladores acceder y gestionar bases de datos SQL con el lenguaje de dominio Python. Puedes escribir una consulta en forma de cadena o encadenar objetos Python para consultas similares. Trabajar con objetos proporciona flexibilidad a los desarrolladores y les permite crear aplicaciones de alto rendimiento basadas en SQL.
En palabras sencillas, permite a los usuarios conectar bases de datos utilizando lenguaje Python, ejecutar consultas SQL mediante programación basada en objetos y agilizar el flujo de trabajo.
Es bastante fácil instalar el paquete y empezar a codificar.
Puedes instalar SQLAlchemy con el gestor de paquetes de Python (pip):
pip install sqlalchemySi utilizas la distribución Anaconda de Python, intenta introducir el comando en el terminal conda:
conda install -c anaconda sqlalchemyComprobemos si el paquete se ha instalado correctamente:
>>> import sqlalchemy
>>> sqlalchemy.__version__
'1.4.41'Excelente, hemos instalado correctamente la versión 1.4.41 de SQLAlchemy.
En esta sección, aprenderemos a conectar bases de datos SQLite, crear objetos de tabla y utilizarlos para ejecutar la consulta SQL.
Utilizaremos la base de datos SQLite de Fútbol europeo de Kaggle y tiene dos tablas: divisiones y partidos.
En primer lugar, crearemos objetos del motor SQLite con 'create_object' y pasaremos la dirección de ubicación de la base de datos. A continuación, crearemos un objeto de conexión conectando el motor. Utilizaremos el objeto 'conn' para ejecutar todo tipo de consultas SQL.
from sqlalchemy as db
engine = db.create_engine("sqlite:///european_database.sqlite")
conn = engine.connect() Si quieres conectar bases de datos PostgreSQL, MySQL, Oracle y Microsoft SQL Server, comprueba la configuración del motor para una conectividad fluida con el servidor.
Este tutorial de SQLAlchemy asume que entiendes los fundamentos de Python y SQL. Si no, no pasa nada. Puedes cursar el programa de habilidades Fundamentos de SQL y Fundamentos de Python para construir una base sólida.
Para crear un objeto tabla, tenemos que proporcionar los nombres de las tablas y los metadatos. Puedes producir metadatos con la función `MetaData()` de SQLAlchemy.
metadata = db.MetaData() #extracting the metadata
division= db.Table('divisions', metadata, autoload=True,
autoload_with=engine) #Table objectVamos a imprimir los metadatos "divisions".
print(repr(metadata.tables['divisions']))Los metadatos contienen el nombre de la tabla, los nombres de las columnas con el tipo y el esquema.
Table('divisions', MetaData(), Column('division', TEXT(), table=<divisions>),
Column('name', TEXT(), table=<divisions>), Column('country', TEXT(),
table=<divisions>), schema=None)Utilicemos el objeto de tabla "division" para imprimir los nombres de las columnas.
print(division.columns.keys())La tabla consta de las columnas división, nombre y país.
['division', 'name', 'country']Ahora viene la parte divertida. Utilizaremos el objeto tabla para ejecutar la consulta y extraer los resultados.
En el código siguiente, seleccionamos todas las columnas de la tabla "division".
query = division.select() #SELECT * FROM divisions
print(query)Nota: También puedes escribir el comando select como "db.select([division])".
Para ver la consulta, imprime el objeto consulta y se mostrará el comando SQL.
SELECT divisions.division, divisions.name, divisions.country
FROM divisionsAhora ejecutaremos la consulta con el objeto de conexión y extraeremos las cinco primeras filas.
exe = conn.execute(query) #executing the query
result = exe.fetchmany(5) #extracting top 5 results
print(result)El resultado muestra las cinco primeras filas de la tabla.
[('B1', 'Division 1A', 'Belgium'), ('D1', 'Bundesliga', 'Deutschland'), ('D2', '2. Bundesliga', 'Deutschland'), ('E0', 'Premier League', 'England'), ('E1', 'EFL Championship', 'England')]En esta sección, veremos varios ejemplos de SQLAlchemy para crear tablas, insertar valores, ejecutar consultas SQL, análisis de datos y gestión de tablas.
Puedes seguirnos o consultar el espacio de trabajo DataCamp Workspace. Contiene una base de datos, el código fuente y los resultados.
En primer lugar, crearemos una nueva base de datos llamada "datacamp.sqlite". create_engine creará una nueva base de datos automáticamente si no existe ninguna base de datos con el mismo nombre. Por tanto, crear y conectar son bastante similares.
A continuación, conectaremos la base de datos y crearemos un objeto de metadatos.
Utilizaremos la función Tabla de SQLAlchmy para crear una tabla llamada "Student".
Consta de columnas:
Hemos creado la estructura de la tabla. Vamos a añadirlo a la base de datos utilizando `metadata.create_all(engine)`.
engine = db.create_engine('sqlite:///datacamp.sqlite')
conn = engine.connect()
metadata = db.MetaData()
Student = db.Table('Student', metadata,
db.Column('Id', db.Integer(),primary_key=True),
db.Column('Name', db.String(255), nullable=False),
db.Column('Major', db.String(255), default="Math"),
db.Column('Pass', db.Boolean(), default=True)
)
metadata.create_all(engine) Para añadir una sola fila, utilizaremos primero `insert` y añadiremos el objeto tabla. Después, utiliza `values` y añade valores a las columnas manualmente. Funciona de forma similar a añadir argumentos a las funciones de Python.
Por último, ejecutaremos la consulta utilizando la conexión para ejecutar la función.
query = db.insert(Student).values(Id=1, Name='Matthew', Major="English", Pass=True)
Result = conn.execute(query)Comprobemos si añadimos la fila a la tabla "Student" al ejecutar una consulta select y obtener todas las filas.
output = conn.execute(Student.select()).fetchall()
print(output)Hemos añadido correctamente los valores.
[(1, 'Matthew', 'English', True)]Añadir valores uno a uno no es una forma práctica de poblar la base de datos. Vamos a añadir varios valores utilizando listas.
query = db.insert(Student)
values_list = [{'Id':'2', 'Name':'Nisha', 'Major':"Science", 'Pass':False},
{'Id':'3', 'Name':'Natasha', 'Major':"Math", 'Pass':True},
{'Id':'4', 'Name':'Ben', 'Major':"English", 'Pass':False}]
Result = conn.execute(query,values_list)Para validar nuestros resultados, ejecuta la consulta select simple.
output = conn.execute(db.select([Student])).fetchall()
print(output)La tabla contiene ahora más filas.
[(1, 'Matthew', 'English', True), (2, 'Nisha', 'Science', False), (3, 'Natasha', 'Math', True), (4, 'Ben', 'English', False)]En lugar de utilizar objetos Python, también podemos ejecutar consultas SQL utilizando String.
Solo tienes que añadir el argumento como cadena a la función `execute` y ver el resultado con `fetchall`.
output = conn.execute("SELECT * FROM Student")
print(output.fetchall())Salida:
[(1, 'Matthew', 'English', 1), (2, 'Nisha', 'Science', 0), (3, 'Natasha', 'Math', 1), (4, 'Ben', 'English', 0)]Incluso puedes pasar consultas SQL más complejas. En nuestro caso, seleccionamos las columnas Name and Major en las que los alumnos han aprobado el examen.
output = conn.execute("SELECT Name, Major FROM Student WHERE Pass = True")
print(output.fetchall())Salida:
[('Matthew', 'English'), ('Natasha', 'Math')]En las secciones anteriores, hemos estado utilizando simples API/objetos SQLAlchemy. Vamos a sumergirnos en consultas más complejas y de varios pasos.
En el ejemplo siguiente, seleccionaremos todas las columnas en las que la especialidad del alumno sea inglés.
query = Student.select().where(Student.columns.Major == 'English')
output = conn.execute(query)
print(output.fetchall())Salida:
[(1, 'Matthew', 'English', True), (4, 'Ben', 'English', False)]Apliquemos la lógica AND a la consulta WHERE.
En nuestro caso, buscamos estudiantes que hayan cursado una especialidad de inglés y hayan suspendido.
Nota: No igual a '!=' True es False.
query = Student.select().where(db.and_(Student.columns.Major == 'English', Student.columns.Pass != True))
output = conn.execute(query)
print(output.fetchall())Solo Ben ha suspendido el examen con un título de inglés.
[(4, 'Ben', 'English', False)]Con una tabla similar, podemos ejecutar todo tipo de comandos, como se muestra en la tabla siguiente.
Puedes copiar y pegar estos comandos para probar los resultados por tu cuenta. Consulta el espacio de trabajo Workspace DataCamp si te quedas atascado en alguno de los comandos dados.
|
Comandos |
API |
|
in |
Student.select().where(Student.columns.Major.in_(['English','Math'])) |
|
and, or, not |
Student.select().where(db.or_(Student.columns.Major == 'English', Student.columns.Pass = True)) |
|
order by |
Student.select().order_by(db.desc(Student.columns.Name)) |
|
limit |
Student.select().limit(3) |
|
sum, avg, count, min, max |
db.select([db.func.sum(Student.columns.Id)]) |
|
group by |
db.select([db.func.sum(Student.columns.Id),Student.columns.Major]).group_by(Student.columns.Pass) |
|
distinct |
db.select([Student.columns.Major.distinct()]) |
Para conocer otras funciones y comandos, consulta la documentación oficial de la API de expresiones y sentencias SQL.
Los científicos y analistas de datos aprecian los dataframes de pandas y les encantaría trabajar con ellos. En esta parte, aprenderemos a convertir el resultado de una consulta SQLAlchemy en un marco de datos pandas.
Primero, ejecuta la consulta y guarda los resultados.
query = Student.select().where(Student.columns.Major.in_(['English','Math']))
output = conn.execute(query)
results = output.fetchall()A continuación, utiliza la función DataFrame y proporciona los resultados SQL como argumento. Por último, añade los nombres de las columnas utilizando la primera fila de resultados `results[0]` y `.keys()`.
Nota: Puedes proporcionar cualquier fila válida para extraer los nombres de las columnas utilizando `keys()`.
data = pd.DataFrame(results)
data.columns = results[0].keys()
data
En esta parte, conectaremos la base de datos del fútbol europeo y realizaremos consultas complejas y visualizaremos los resultados.
Como de costumbre, conectaremos la base de datos utilizando las funciones `create_engine` y `connect`.
En nuestro caso, vamos a unir dos tablas, por lo que tenemos que crear dos objetos de tabla: división y partido (division y match).
engine = create_engine("sqlite:///european_database.sqlite")
conn = engine.connect()
metadata = db.MetaData()
division = db.Table('divisions', metadata, autoload=True, autoload_with=engine)
match = db.Table('matchs', metadata, autoload=True, autoload_with=engine)Incluso puedes crear consultas más complejas añadiendo módulos adicionales.
Nota: Para unir automáticamente dos tablas también puedes utilizar: `db.select([division.columns.division,match.columns.Div])`
query = db.select([division,match]).\
select_from(division.join(match,division.columns.division == match.columns.Div)).\
where(db.and_(division.columns.division == "E1", match.columns.season == 2009 )).\
order_by(match.columns.HomeTeam)
output = conn.execute(query)
results = output.fetchall()
data = pd.DataFrame(results)
data.columns = results[0].keys()
data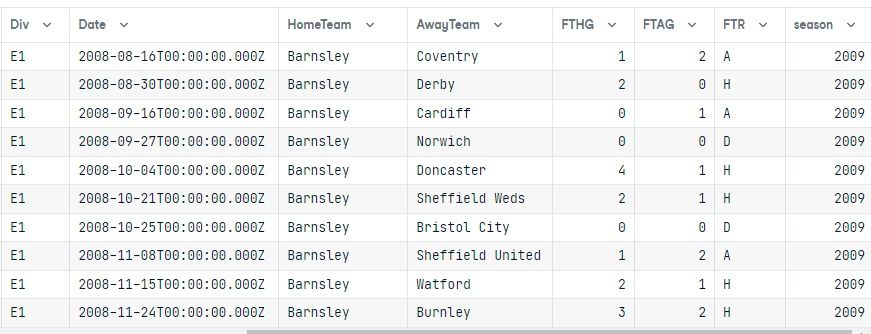
Tras ejecutar la consulta, convertimos el resultado en un marco de datos pandas.
Ambas tablas están unidas, y los resultados solo muestran la división E1 de la temporada 2009 ordenada por la columna HomeTeam.
Ahora que tenemos un marco de datos, podemos visualizar los resultados en forma de gráfico de barras utilizando Seaborn.
Lo que haremos será:
El objetivo principal de esta parte es mostrarte cómo puedes utilizar la salida de la consulta SQL y crear una asombrosa visualización de datos.
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style="whitegrid")
f, ax = plt.subplots(figsize=(15, 6))
plt.xticks(rotation=90)
sns.set_color_codes("pastel")
sns.barplot(x="HomeTeam", y="FTHG", data=data,
label="Home Team Goals", color="b")
sns.barplot(x="HomeTeam", y="FTAG", data=data,
label="Away Team Goals", color="r")
ax.legend(ncol=2, loc="upper left", frameon=True)
ax.set(ylabel="", xlabel="")
sns.despine(left=True, bottom=True)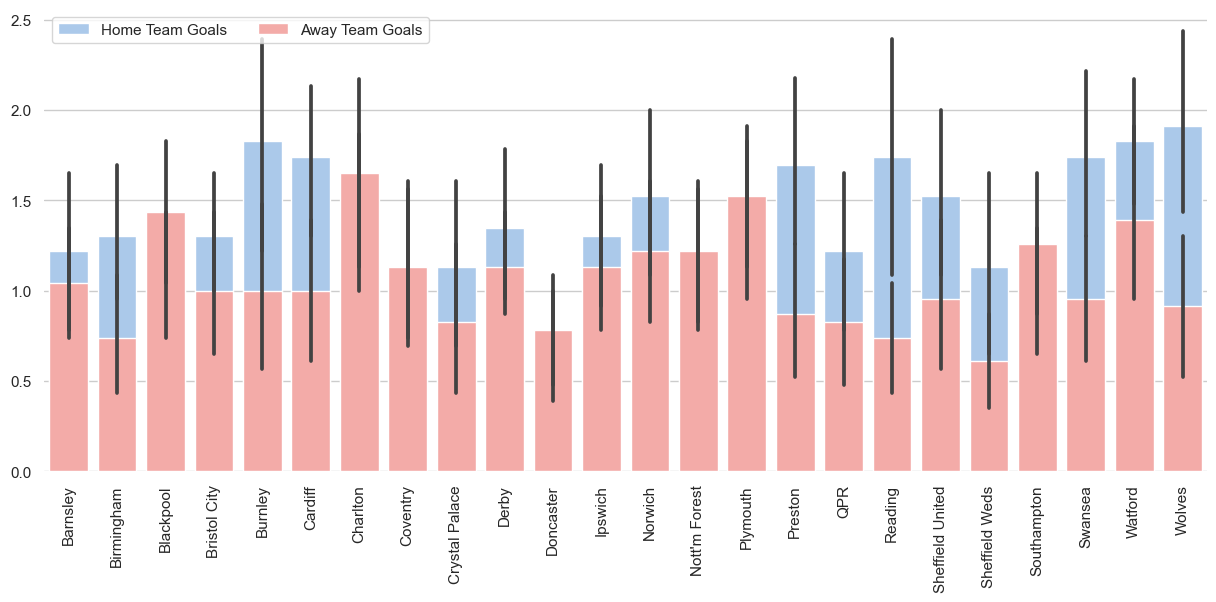
Tras convertir el resultado de la consulta en un marco de datos de pandas, solo tienes que utilizar la función '.to_csv' con el nombre del archivo.
output = conn.execute("SELECT * FROM matchs WHERE HomeTeam LIKE 'Norwich'")
results = output.fetchall()
data = pd.DataFrame(results)
data.columns = results[0].keys()Evita añadir una columna llamada "Índice" utilizando `index=False`.
data.to_csv("SQl_result.csv",index=False)En esta parte, convertiremos el archivo CSV dedatos bursátiles en una tabla SQL.
Primero, conéctate a la base de datos sqlite de DataCamp.
engine = create_engine("sqlite:///datacamp.sqlite")A continuación, importa el archivo CSV utilizando la función read_csv. Al final, utiliza la función `to_sql` para guardar el marco de datos de pandas como una tabla SQL.
Principalmente, la función `to_sql` requiere como argumento la conexión y el nombre de la tabla. También puedes utilizar `if_exisits` para sustituir una tabla existente con el mismo nombre y `index` para eliminar la columna del índice.
df = pd.read_csv('Stock Exchange Data.csv')
df.to_sql(con=engine, name="Stock_price", if_exists='replace', index=False)
>>> 2222Para validar los resultados, necesitamos conectar la base de datos y crear un objeto tabla.
conn = engine.connect()
metadata = db.MetaData()
stock = db.Table('Stock_price', metadata, autoload=True, autoload_with=engine)A continuación, ejecuta la consulta y muestra los resultados.
query = stock.select()
exe = conn.execute(query)
result = exe.fetchmany(5)
for r in result:
print(r)Como puedes ver, hemos transferido con éxito todos los valores del archivo CSV a la tabla SQL.
('HSI', '1986-12-31', 2568.300049, 2568.300049, 2568.300049, 2568.300049, 2568.300049, 0, 333.87900637)
('HSI', '1987-01-02', 2540.100098, 2540.100098, 2540.100098, 2540.100098, 2540.100098, 0, 330.21301274)
('HSI', '1987-01-05', 2552.399902, 2552.399902, 2552.399902, 2552.399902, 2552.399902, 0, 331.81198726)
('HSI', '1987-01-06', 2583.899902, 2583.899902, 2583.899902, 2583.899902, 2583.899902, 0, 335.90698726)
('HSI', '1987-01-07', 2607.100098, 2607.100098, 2607.100098, 2607.100098, 2607.100098, 0, 338.92301274)Actualizar los valores es sencillo. Utilizaremos las funciones update, values y where para actualizar el valor concreto de la tabla.
table.update().values(column_1=1, column_2=4,...).where(table.columns.column_5 >= 5)En nuestro caso, hemos cambiado el valor "Aprobado" de False a True cuando el nombre del alumno es "Nisha".
Student = db.Table('Student', metadata, autoload=True, autoload_with=engine)
query = Student.update().values(Pass = True).where(Student.columns.Name == "Nisha")
results = conn.execute(query)Para validar los resultados, vamos a ejecutar una consulta sencilla y mostrar los resultados en forma de marco de datos pandas.
output = conn.execute(Student.select()).fetchall()
data = pd.DataFrame(output)
data.columns = output[0].keys()
dataHemos cambiado correctamente el valor "Aprobado" a True para el nombre del alumno "Nisha".
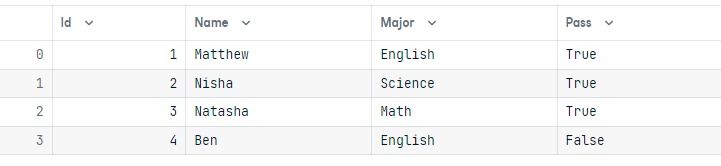
Borrar las filas es similar a actualizar. Requiere la función suprimir y dónde.
table.delete().where(table.columns.column_1 == 6)En nuestro caso, estamos borrando el registro del alumno llamado "Ben".
Student = db.Table('Student', metadata, autoload=True, autoload_with=engine)
query = Student.delete().where(Student.columns.Name == "Ben")
results = conn.execute(query)Para validar los resultados, ejecutaremos una consulta rápida y mostraremos los resultados en forma de marco de datos. Como puedes ver, hemos eliminado la fila que contiene el nombre del alumno "Ben".
output = conn.execute(Student.select()).fetchall()
data = pd.DataFrame(output)
data.columns = output[0].keys()
data
Si utilizas SQLite, al eliminar la tabla aparecerá el error "la base de datos está bloqueada". ¿Por qué? Porque SQLite es una versión muy ligera. Solo puede realizar una función a la vez. Actualmente, está ejecutando una consulta select. Tenemos que cerrar toda la ejecución antes de borrar la tabla.
results.close()
exe.close()Después, utiliza la función drop_all de metadatos y selecciona un objeto de tabla para eliminar la tabla única. También puedes utilizar el comando `Student.drop(motor)` para eliminar una sola tabla.
metadata.drop_all(engine, [Student], checkfirst=True)Si no especificas ninguna tabla para la función drop_all. Soltará todas las tablas de la base de datos.
metadata.drop_all(engine)El tutorial de SQLAlchemy cubre varias funciones de SQLAlchemy, desde la conexión a la base de datos hasta la modificación de tablas, y si te interesa aprender más, prueba a completar el curso interactivo Introducción a las bases de datos en Python. Conocerás los fundamentos de las bases de datos relacionales, el filtrado, la ordenación y la agrupación. Además, conocerás las funciones avanzadas de SQLAlchemy para la manipulación de datos.
Si encuentras algún problema al seguir el tutorial, puedes ejecutar el código fuente utilizando el espacio de trabajo y comparar tu código con él. Incluso puedes duplicar el cuaderno Jupyter y ejecutar el código con solo pulsar dos botones.
Cursos de Python y SQL
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Sejal Jaiswal
Tutorial
Abid Ali Awan
Tutorial
Elena Kosourova
Tutorial
Javier Canales Luna
Tutorial
Théo Vanderheyden