Curso
Introducción al Natural Language Processing en Python
4 h
141K
El objetivo de la analítica es obtener información a partir de los datos. Tradicionalmente, estos datos estaban estructurados, es decir, en un formato estandarizado para un acceso eficaz. A medida que el mundo cambia y se digitaliza, gran parte de los datos que se generan no están estructurados, lo que significa que no existe un modelo de datos predefinido.
Según Gartner, los datos no estructurados representan el 80-90% de todos los nuevos datos empresariales. Además, crece tres veces más rápido que los datos estructurados. En consecuencia, los expertos en análisis deben emplear nuevas técnicas para obtener información relevante de sus conjuntos de datos.
Una de estas técnicas es el modelado de temas en el campo de la minería de textos. En el resto de este artículo, trataremos:
El modelado de temas es un enfoque utilizado con frecuencia para descubrir patrones semánticos ocultos retratados por un corpus de texto e identificar automáticamente los temas que existen en él.
Se trata de un tipo de modelización estadística que aprovecha el aprendizaje automático no supervisado para analizar e identificar clusters o grupos de palabras similares en un texto.
Por ejemplo, se puede desplegar un algoritmo de modelado de temas para determinar si el contenido de un documento implica que se trata de una factura, una reclamación o un contrato.
Según algunas fuentes, una persona media genera más de 1,7 MB de datos digitales por segundo. Esta cifra asciende a más de 2,5 quintillones de bytes de datos al día, de los cuales entre el 80 y el 90% no están estructurados.
Consideremos un escenario en el que una empresa emplea a una sola persona para revisar cada pieza de datos no estructurados y segmentarlos en función del tema subyacente. Sería una tarea imposible.
Llevaría mucho tiempo y sería extremadamente tedioso, además de entrañar mucho más riesgo, ya que los humanos son por naturaleza más parciales y propensos a cometer errores que las máquinas.
La solución es el modelado temático.
Con el modelado temático, se puede obtener información de los datos más rápidamente y posiblemente mejor. Esta técnica combina los temas en una estructura comprensible, lo que permite a las empresas entender rápidamente lo que está ocurriendo.
Por ejemplo, una empresa que quiera comprender los mayores retos de sus clientes puede emplear el modelado temático para conocer esta información a través de datos no estructurados.
En resumen, el modelado temático ayuda a las empresas en:
Hemos comprobado que el modelado de temas permite a los profesionales de los datos analizar e identificar rápidamente clusters o grupos de palabras similares dentro de un cuerpo de texto a escala.
Pero, ¿qué son los temas y cómo funciona el modelado temático?
Los temas son las descripciones latentes de un corpus (gran grupo) de texto. Intuitivamente, es más probable que los documentos relativos a un tema específico produzcan ciertas palabras con mayor frecuencia.
Por ejemplo, es más probable que las palabras "perro" y "hueso" aparezcan en documentos relativos a perros, mientras que "gato" y "miau" se encuentran más a menudo en documentos relativos a gatos. En consecuencia, el modelo temático escanearía los documentos y produciría clusters de palabras similares.
Esencialmente, los modelos temáticos funcionan deduciendo palabras y agrupando las similares en temas para crear clusters temáticos.
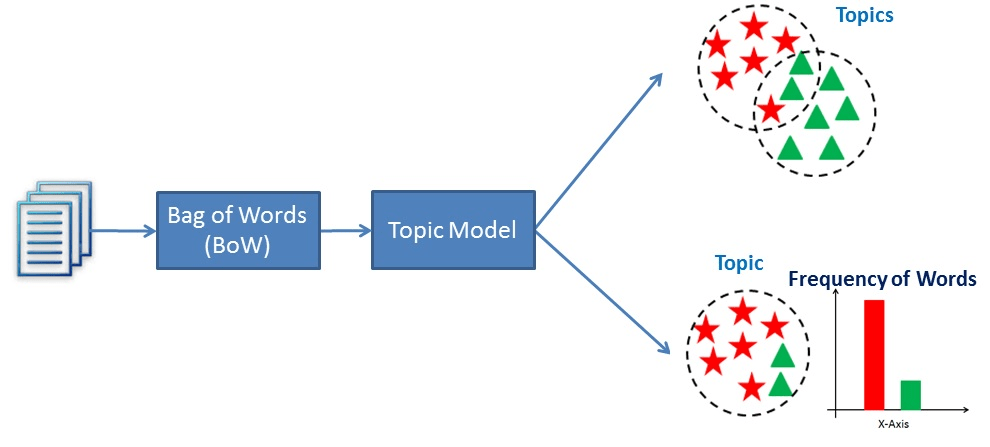
Visualización del funcionamiento del modelado temático
Dos técnicas populares de modelado temático son el Análisis Semántico Latente (LSA) y la Asignación de Dirichlet Latente (LDA). Su objetivo de descubrir patrones semánticos ocultos retratados por datos textuales es el mismo, pero la forma de lograrlo es diferente.
El Análisis Semántico Latente (LSA) es una técnica de procesamiento del lenguaje natural utilizada para analizar las relaciones entre los documentos y los términos que contienen. El método se presentó por primera vez en un artículo de 1988 titulado "Using Latent Semantic Analysis to Improve Access to Textual Information" (Utilización del análisis semántico latente para mejorar el acceso a la información textual ) y se sigue utilizando hoy en día para crear datos estructurados a partir de una colección de textos no estructurados.
Es decir, LSA asume que palabras con significados similares aparecerán en documentos similares. Para ello, construye una matriz que contiene el recuento de palabras por documento, donde cada fila representa una palabra única y las columnas representan cada documento, y luego utiliza una descomposición de valor singular (SVD) para reducir el número de filas preservando la estructura de similitud entre columnas. La SVD es un método matemático que simplifica los datos conservando sus características importantes. Se utiliza aquí para mantener las relaciones entre palabras y documentos.
Para determinar la similitud entre documentos, se utiliza la similitud coseno. Se trata de una medida que calcula el coseno del ángulo entre dos vectores, en este caso, que representan documentos. Un valor cercano a 1 significa que los documentos son muy similares en función de las palabras que contienen, mientras que un valor cercano a 0 significa que son bastante diferentes.
La Asignación de Dirichlet Latente (LDA) se propuso inicialmente en 2000 en un artículo titulado "Inference of population structure using multilocus genotype data". El artículo se centraba principalmente en la genética de poblaciones, que es un subcampo de la genética que se ocupa de las diferencias genéticas dentro de las poblaciones y entre ellas. Tres años más tarde, se aplicó la Asignación de Dirichlet Latente en el aprendizaje automático.
Los autores del artículo describen la técnica como "un modelo generativo para texto y otras colecciones de datos discretos". Así pues, LDA puede describirse como una técnica de lenguaje natural utilizada para identificar los temas a los que pertenece un documento basándose en las palabras que contiene.
Más concretamente, LDA es una red bayesiana, lo que significa que es un modelo estadístico generativo que asume que los documentos están formados por palabras que ayudan a determinar los temas. Así, los documentos se asignan a una lista de temas asignando cada palabra del documento a diferentes temas. Este modelo ignora el orden de las palabras que aparecen en un documento y las trata como una bolsa de palabras.
El Análisis Semántico Latente (LSA) y la Asignación de Dirichlet Latente (LDA) son técnicas de procesamiento del lenguaje natural utilizadas para crear datos estructurados a partir de una colección de textos no estructurados.
Sin embargo, LSA aprovecha la descomposición de valores singulares (SVD) para reducir la dimensionalidad de la matriz término-documento y se basa en el supuesto de que palabras con significados similares aparecerán en documentos similares. Al crear una representación de dimensiones inferiores del texto, el modelo puede captar las relaciones subyacentes entre las palabras para determinar el grado de similitud entre dos documentos.
En cambio, LDA es un modelo probabilístico generativo que aprovecha la inferencia bayesiana para encontrar los temas subyacentes en un corpus de textos. Asume que cada documento es una combinación de un pequeño número de temas latentes, y que cada palabra es generada por un tema concreto.
En última instancia, LSA intenta descubrir las relaciones subyacentes entre las palabras, mientras que LDA trata de descubrir los temas subyacentes en un corpus de texto. Aunque ambas son técnicas utilizadas para crear una representación vectorial del texto, parten de supuestos diferentes.
Veamos cómo funcionan estas técnicas. Utiliza este cuaderno de DataLab para seguir el código.
Lo primero que necesitamos son datos.
Para el modelado temático, los datos que utilizamos se denominan corpus, que no es más que una colección de textos.
He aquí un pequeño corpus que he creado a partir de datos de Internet:
# Creating example documents
doc_1 = "A whopping 96.5 percent of water on Earth is in our oceans, covering 71 percent of the surface of our planet. And at any given time, about 0.001 percent is floating above us in the atmosphere. If all of that water fell as rain at once, the whole planet would get about 1 inch of rain."
doc_2 = "One-third of your life is spent sleeping. Sleeping 7-9 hours each night should help your body heal itself, activate the immune system, and give your heart a break. Beyond that--sleep experts are still trying to learn more about what happens once we fall asleep."
doc_3 = "A newborn baby is 78 percent water. Adults are 55-60 percent water. Water is involved in just about everything our body does."
doc_4 = "While still in high school, a student went 264.4 hours without sleep, for which he won first place in the 10th Annual Great San Diego Science Fair in 1964."
doc_5 = "We experience water in all three states: solid ice, liquid water, and gas water vapor."
# Create corpus
corpus = [doc_1, doc_2, doc_3, doc_4, doc_5]El siguiente paso es limpiar el texto:
# Code source: https://www.analyticsvidhya.com/blog/2016/08/beginners-guide-to-topic-modeling-in-python/
import string
import nltk
nltk.download('stopwords')
nltk.download('wordnet')
nltk.download('omw-1.4')
from nltk.corpus import stopwords
from nltk.stem.wordnet import WordNetLemmatizer
# remove stopwords, punctuation, and normalize the corpus
stop = set(stopwords.words('english'))
exclude = set(string.punctuation)
lemma = WordNetLemmatizer()
def clean(doc):
stop_free = " ".join([i for i in doc.lower().split() if i not in stop])
punc_free = "".join(ch for ch in stop_free if ch not in exclude)
normalized = " ".join(lemma.lemmatize(word) for word in punc_free.split())
return normalized
clean_corpus = [clean(doc).split() for doc in corpus]En el código anterior
Pero esto aún no significa que estemos preparados.
Antes de poder utilizar estos datos como entrada para un modelo LDA o LSA, hay que convertirlos en una matriz término-documento. Una matriz término-documento no es más que una representación matemática de un conjunto de documentos y de los términos que contienen.
Se crea contando la aparición de cada término en cada documento y, a continuación, normalizando los recuentos para crear una matriz de valores que pueda utilizarse para el análisis.
Para hacer esto en Python, vamos a aprovechar la biblioteca Gensim.
from gensim import corpora
# Creating document-term matrix
dictionary = corpora.Dictionary(clean_corpus)
doc_term_matrix = [dictionary.doc2bow(doc) for doc in clean_corpus]Ahora, podemos ajustar nuestros modelos.
El primer modelo que utilizaremos en LSA:
from gensim.models import LsiModel
# LSA model
lsa = LsiModel(doc_term_matrix, num_topics=3, id2word = dictionary)
# LSA model
print(lsa.print_topics(num_topics=3, num_words=3))
"""
[
(0, '0.555*"water" + 0.489*"percent" + 0.239*"planet"'),
(1, '0.361*"sleeping" + 0.215*"hour" + 0.215*"still"'),
(2, '-0.562*"water" + 0.231*"rain" + 0.231*"planet"')
]
"""De esta forma se obtienen los temas (cada línea) con términos temáticos individuales (términos) y sus ponderaciones.
Intentémoslo con LDA:
from gensim.models import LdaModel
# LDA model
lda = LdaModel(doc_term_matrix, num_topics=3, id2word = dictionary)
# Results
print(lda.print_topics(num_topics=3, num_words=3))
"""
[
(0, '0.071*"water" + 0.025*"state" + 0.025*"three"'),
(1, '0.030*"still" + 0.028*"hour" + 0.026*"sleeping"'),
(2, '0.073*"percent" + 0.069*"water" + 0.031*"rain"')
]
"""Al eliminar las tareas manuales y repetitivas, el modelado temático puede acelerar los procesos de forma sencilla y económica. He aquí algunos ejemplos:
El modelado de temas puede utilizarse para ayudar al personal de atención al cliente a analizar las consultas de asistencia para identificar los problemas principales y determinar los que se repiten. A partir de esos datos, pueden crear contenidos de autoservicio más informativos o ayudar directamente a los clientes.
Se puede utilizar el modelado de temas para etiquetar las conversaciones de modo que se puedan dirigir al equipo más adecuado. Por ejemplo, una conversación que incluya palabras como "precios", "suscripción", "renovación", etc., podría enviarse directamente al departamento de contabilidad para recibir asistencia.
El modelado de temas se utiliza para descubrir los temas latentes que existen en una colección de documentos. Se trata de identificar patrones en las palabras y frases que aparecen en los documentos y agruparlas en temas en función de su similitud.
Por el contrario, el clustering es una técnica utilizada para agrupar objetos similares basándose en una medida de similitud. Estos métodos se emplean para descubrir patrones y estructuras en los datos agrupando puntos de datos similares.
Aunque ambos enfoques pueden descubrir patrones en los datos de texto, tienen objetivos diferentes. El modelado de temas se ocupa de identificar temas latentes en una colección de documentos, mientras que el clustering se ocupa de agrupar puntos de datos similares.
La clasificación de textos, aunque es una técnica de procesamiento del lenguaje natural, pertenece a la categoría del aprendizaje supervisado. En concreto, la clasificación de textos se emplea para etiquetar categorías predefinidas o un determinado fragmento de texto. Para que el modelo logre esta hazaña, primero debe aprender de un conjunto de datos etiquetados antes de poder utilizarlo para hacer predicciones sobre nuevas muestras de texto no vistas.
Por otro lado, el modelado temático es una técnica de aprendizaje no supervisado que se utiliza para encontrar los temas subyacentes en una colección de documentos de texto. Esto significa que no tiene que aprender de un conjunto de datos etiquetados.
Así, la diferencia entre ambos métodos es que la clasificación de textos se utiliza para asignar etiquetas predefinidas al texto, mientras que el modelado temático descubre los temas subyacentes en una colección de documentos.
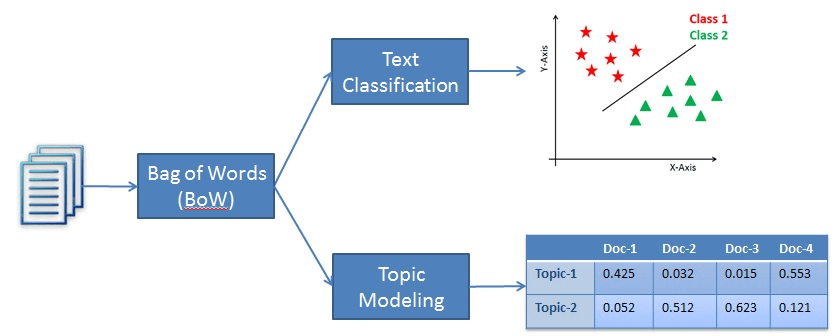
Un ejemplo de clasificación frente a modelización temática
El modelado de temas es una popular técnica de procesamiento del lenguaje natural utilizada para crear datos estructurados a partir de una colección de datos no estructurados. En otras palabras, la técnica permite a las empresas aprender los patrones semánticos ocultos que retrata un corpus de texto e identificar automáticamente los temas que existen en él.
Dos enfoques populares de modelado temático son LSA y LDA. Ambos buscan descubrir los patrones ocultos en los datos de texto, pero parten de supuestos diferentes para lograr su objetivo. Mientras que LSA asume que palabras con significados similares aparecerán en documentos similares, LDA asume que los documentos están formados por palabras que ayudan a determinar los temas.
En este tutorial hemos tratado los conceptos básicos del modelado temático, una implementación práctica y en qué se diferencia de otras técnicas, como la clasificación de textos y la agrupación en clústeres. Para seguir aprendiendo, consulte algunos de nuestros otros recursos:
Comience hoy mismo su viaje por el modelado temático.
Curso
Curso
Curso
blog
Natassha Selvaraj
15 min
blog
Zoumana Keita
14 min
blog
Tim Lu
12 min
Tutorial
Joanne Xiong
Tutorial
Joleen Bothma
Tutorial
Moez Ali
