Han pasado más de setenta años desde que el célebre matemático estadounidense Samuel S. Wilks afirmara : " El pensamiento estadístico será algún día tan necesario para una ciudadanía eficiente como la capacidad de leer y escribir", parafraseando el libro de HG Wells, Mankind in the Making. Aunque esta afirmación puede haber sido algo exagerada, su mensaje subyacente sobre la importancia de las estadísticas sigue siendo relevante en la actual era de la información.

(Fuente de la imagen: The American Statistical Association)
Con el rápido avance de la tecnología y una innovación sin precedentes, el aprendizaje automático y la IA generativa han cobrado protagonismo. Estos avances han influido profundamente en nuestra vida personal y han facilitado la toma de decisiones basada en datos a mayor escala.
Sin embargo, en medio de toda la algarabía que rodea a estas tecnologías de vanguardia, las estadísticas siguen desempeñando un papel crucial. La inferencia estadística sigue siendo la base de numerosos avances tecnológicos, sobre todo en el ámbito del aprendizaje automático. Es inseparable de la esencia misma de los datos, que es la base de todas las nuevas y apasionantes tecnologías que nos rodean.
¡Desenmascaremos juntos la magia del aprendizaje automático estadístico!
¿Qué es el aprendizaje automático estadístico?
Tan intuitivo como suena por su nombre, el aprendizaje automático estadístico consiste en utilizar técnicas estadísticas para desarrollar modelos que puedan aprender de los datos y hacer predicciones o tomar decisiones.
Es posible que haya oído términos técnicos como aprendizaje supervisado, no supervisado y semisupervisado: todos ellos se basan en una sólida base estadística.
En esencia, el aprendizaje automático estadístico fusiona la eficiencia computacional y la adaptabilidad de los algoritmos de aprendizaje automático con las capacidades de inferencia estadística y modelización.
Mediante el empleo de métodos estadísticos, podemos extraer patrones, relaciones y conocimientos significativos de conjuntos de datos intrincados, fomentando así la eficacia de los algoritmos de aprendizaje automático.
El papel de la estadística en el aprendizaje automático
La estadística constituye la espina dorsal del aprendizaje automático, ya que proporciona las herramientas y técnicas para analizar e interpretar los datos.
Esencialmente, la estadística proporciona el marco teórico sobre el que se construyen los algoritmos de aprendizaje automático.
La estadística es la ciencia que nos permite recopilar, analizar, interpretar, presentar y organizar datos. Proporciona un sólido conjunto de herramientas para comprender patrones y tendencias, y hacer inferencias y predicciones a partir de los datos. Cuando trabajamos con grandes conjuntos de datos, la estadística nos ayuda a comprenderlos y resumirlos, lo que nos permite dar sentido a fenómenos complejos.
El aprendizaje automático, por su parte, es una potente herramienta que permite a los ordenadores aprender de los datos y tomar decisiones o hacer predicciones a partir de ellos. El objetivo último del aprendizaje automático es crear modelos que puedan adaptarse y mejorar con el tiempo, así como generalizar a partir de ejemplos concretos a casos más amplios.
Aquí es donde sale a relucir la belleza de la fusión entre estadística y aprendizaje automático. Los principios de la estadística son los pilares que sostienen la estructura del aprendizaje automático.
- Construcción de modelos de aprendizaje automático. La estadística proporciona las metodologías y los principios para crear modelos en el aprendizaje automático. Por ejemplo, el modelo de regresión lineal aprovecha el método estadístico de los mínimos cuadrados para estimar los coeficientes.
- Interpretación de los resultados. Los conceptos estadísticos nos permiten interpretar los resultados generados por los modelos de aprendizaje automático. Medidas como el valor p, los intervalos de confianza, R-cuadrado y otras nos proporcionan una perspectiva estadística del rendimiento del modelo de aprendizaje automático.
- Validación de modelos. Las técnicas estadísticas son esenciales para validar y perfeccionar los modelos de aprendizaje automático. Por ejemplo, técnicas como las pruebas de hipótesis, la validación cruzada y el bootstrapping nos ayudan a cuantificar el rendimiento de los modelos y evitar problemas como el sobreajuste.
- Técnicas avanzadas de apuntalamiento. Incluso algunos de los algoritmos de aprendizaje automático más complejos, como las redes neuronales, se basan en principios estadísticos. Las técnicas de optimización, como el descenso de gradiente, utilizadas para entrenar estos modelos se basan en la teoría estadística.
En consecuencia, una sólida comprensión de la estadística no sólo nos permite construir y validar mejor los modelos de aprendizaje automático, sino también interpretar sus resultados de forma significativa y útil.
Veamos algunos de los conceptos estadísticos clave estrechamente relacionados con el aprendizaje automático. Puede aprender más sobre estos conceptos en nuestro curso de Fundamentos de Estadística con Python.
Probabilidad
La teoría de la probabilidad es de suma importancia en el aprendizaje automático, ya que proporciona la base para modelar la incertidumbre y realizar predicciones probabilísticas. ¿Cómo podríamos cuantificar la probabilidad de distintos resultados, acontecimientos o simplemente valores numéricos? La probabilidad ayuda. Además, las distribuciones de probabilidad son especialmente importantes en el aprendizaje automático y hacen que se produzca toda la magia.
Algunas de las distribuciones más utilizadas son la gaussiana (normal), la de Bernoulli, la de Poisson y la exponencial. Disponemos de una práctica hoja de trucos de probabilidad que sirve de referencia rápida para las reglas de probabilidad.
Estadísticas descriptivas
Las estadísticas descriptivas nos permiten comprender las características y propiedades de los conjuntos de datos. Nos ayudan a resumir y visualizar los datos, identificar patrones, detectar valores atípicos y obtener una visión inicial que sirva de base para posteriores modelos y análisis.

Nuestra hoja de trucos de estadística descriptiva puede ayudarle a aprender estos conceptos
Medida de tendencia central
La media, la mediana y la moda proporcionan información valiosa sobre los valores centrales o representativos de un conjunto de datos. En el aprendizaje automático, ayudan en el preprocesamiento de datos mediante la imputación de valores perdidos y la identificación de posibles valores atípicos.
Durante la ingeniería de características, también resultan útiles para capturar los valores típicos o más frecuentes que influyen en el rendimiento del modelo.
Varianza y desviación típica
La varianza y la desviación típica cuantifican la dispersión de los datos en torno a la tendencia central. Sirven como indicadores de la coherencia y variabilidad de los datos en el aprendizaje automático.
Estas medidas son útiles para la selección de características o la reducción de la dimensionalidad, identificando características con un poder predictivo limitado.
Además, ayudan a evaluar el rendimiento del modelo analizando la variabilidad de las predicciones o los residuos, lo que facilita la evaluación y comparación de distintos algoritmos.
Medida de dispersión
El rango, el rango intercuartílico y los percentiles son medidas de dispersión que ofrecen información sobre la distribución de los valores de los datos. Son especialmente valiosos en la detección de valores atípicos, ya que ayudan a identificar y tratar los valores atípicos que pueden influir enormemente en el entrenamiento y las predicciones de los modelos. En los casos en que sea necesario transformar o normalizar los datos para mejorar el rendimiento de los algoritmos, estas medidas pueden servir de orientación.
Muestreo
Los modelos de aprendizaje automático se entrenan a partir de datos muestreados. Si las muestras no se seleccionan cuidadosamente, la fiabilidad de nuestros modelos se vuelve incierta. Lo ideal es elegir subconjuntos de datos representativos de poblaciones más amplias.
El empleo de técnicas de muestreo adecuadas también garantiza que los modelos de aprendizaje automático se entrenen con datos diversos e imparciales, fomentando un uso ético y responsable de la tecnología.
Consulte nuestro curso Muestreo en Python para aprender más sobre esta potente habilidad.
Estimación
Las técnicas de estimación son cruciales en el aprendizaje automático para determinar parámetros poblacionales desconocidos a partir de datos de muestra. Nos permiten estimar los parámetros del modelo, evaluar su rendimiento y hacer predicciones sobre datos desconocidos.
El método de estimación más utilizado en el aprendizaje automático es la estimación de máxima verosimilitud (ML), que encuentra el estimador de un parámetro desconocido maximizando la función de verosimilitud.
Pruebas de hipótesis
La comprobación de hipótesis proporciona un enfoque sistemático para evaluar la importancia de las relaciones o diferencias en las tareas de aprendizaje automático. Nos permite evaluar la validez de los supuestos, comparar modelos y tomar decisiones estadísticamente significativas basadas en las pruebas disponibles.
Validación cruzada
La validación cruzada (CV) es una técnica estadística utilizada en el aprendizaje automático para evaluar el rendimiento y el error de generalización de un algoritmo. Su objetivo principal es evitar el sobreajuste, un fenómeno en el que el modelo funciona bien en los datos de entrenamiento pero no generaliza a los datos no vistos.
Al dividir el conjunto de datos en varios subconjuntos y entrenar y evaluar de forma iterativa el modelo en distintas combinaciones, la CV proporciona una estimación más fiable del rendimiento del algoritmo en datos no vistos.
Técnicas populares de aprendizaje automático estadístico
Estos complejos conceptos estadísticos son los primeros pasos hacia algoritmos eficaces de aprendizaje automático. Exploremos ahora algunos de los modelos de aprendizaje automático más populares y veamos cómo la estadística ayudó a conseguir sus notables capacidades.
Regresión lineal
La regresión lineal es un término habitual en la literatura estadística, pero es algo más que eso. También se considera un algoritmo de aprendizaje supervisado que capta la conexión entre una variable dependiente y variables independientes.
La estadística ayuda a estimar coeficientes, realizar pruebas de hipótesis y evaluar la significación de las relaciones, proporcionando valiosas perspectivas y una comprensión más profunda de los datos.
Explore el tema en mayor profundidad con nuestro tutorial Fundamentos de la regresión lineal en Python o en nuestro curso Introducción a la regresión en R.
Regresión logística
Al igual que la regresión lineal, la regresión logística es un algoritmo de clasificación estadística que estima la probabilidad de resultados categóricos basándose en variables independientes. Aplicando una función logística, predice la aparición de una clase determinada.
Tenemos una explicación completa del tema en nuestro tutorial Comprender la regresión logística en Python.
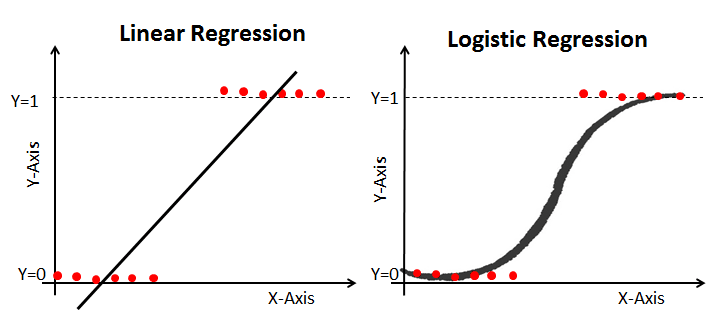
Regresión logística y lineal
Árboles de decisión
Los árboles de decisión son algoritmos versátiles que utilizan la estadística para dividir los datos en función de las características, creando una estructura en forma de árbol para la clasificación o la regresión. Son intuitivos, interpretables y manejan datos categóricos y numéricos.
A menudo se incorporan medidas basadas en estadísticas, como la impureza de Gini o la ganancia de información, para guiar las divisiones a lo largo del proceso de construcción del árbol.
Puede aprender sobre la clasificación de árboles de decisión en Python en un tutorial aparte, o explorar los árboles de decisión en el aprendizaje automático utilizando R.
Bosque aleatorio
Random Forest es un método de aprendizaje por conjuntos que mejora la precisión de las predicciones combinando varios árboles de decisión. Emplea el muestreo para seleccionar aleatoriamente subconjuntos de características y datos para construir los árboles. Las predicciones de cada uno de estos árboles se suman para obtener la predicción final.
Este algoritmo es una opción eficaz, ya que introduce diversidad y reduce el sobreajuste. La incorporación de la diversidad permite obtener un modelo más robusto y completo que capta una amplia gama de patrones de datos, y la reducción del sobreajuste garantiza que el modelo generalice bien a datos no vistos, lo que lo convierte en una herramienta fiable y precisa para el análisis predictivo.
Disponemos de un tutorial independiente sobre la clasificación de bosques aleatorios, que cubre cómo y cuándo utilizar la técnica estadística en el aprendizaje automático.
Un ejemplo de clasificación de bosque aleatorio
Máquinas de vectores soporte (SVM)
SVM es un potente algoritmo que puede utilizarse para tareas de clasificación y regresión. Utiliza principios estadísticos para crear una frontera entre distintos grupos de puntos de datos, lo que facilita su diferenciación. Al optimizar este límite, la SVM reduce las posibilidades de cometer errores y mejora la precisión general.
Tenemos tutoriales que exploran las máquinas de vectores soporte con SciKit learn en Python, así como SVMs en R.
Vecinos más próximos (KNN)
KNN es un algoritmo sencillo pero eficaz utilizado para clasificar puntos de datos basándose en el voto mayoritario de sus vecinos más cercanos. Es adecuado tanto para problemas de clasificación como de regresión y no requiere entrenamiento.
En KNN, se utilizan medidas estadísticas para determinar la proximidad entre los puntos de datos, lo que ayuda a identificar a los vecinos más cercanos. A continuación, se utiliza el voto mayoritario de los vecinos más próximos para clasificar o predecir la variable objetivo.
De nuevo, puede explorar el concepto de KKNs en más detalle con nuestro tutorial K-Nearst Neighbors Classification with scikit-learn.
Reflexiones finales
A medida que nos adentramos en la apasionante era del avance de la tecnología y la toma de decisiones basada en los datos, adquirir unos sólidos conocimientos de estadística resulta muy valioso para mejorar nuestras habilidades de aprendizaje automático. Al profundizar en los fundamentos de la estadística, abrimos la puerta para liberar el verdadero potencial del aprendizaje automático.
Tanto si es un principiante como un profesional experimentado, comience hoy mismo su viaje de aprendizaje con los cursos Fundamentos de estadística con Python y Fundamentos de aprendizaje automático con Python para aprender más sobre el fascinante campo del aprendizaje automático estadístico.
Fuentes
- Todo de Estadística (Un curso conciso de inferencia estadística) por larry Wasserman
- Los elementos del aprendizaje estadístico por Jerome H. Friedman, Robert Tibshirani y Trevor Hastie
