
Cursus
SQL pour les analystes commerciaux
20 h
Le produit cartésien est un concept fondamental de SQL qui peut être à la fois puissant et complexe. Comprendre comment l'utiliser efficacement peut considérablement améliorer vos capacités de manipulation des données. Dans ce guide, nous allons explorer les tenants et les aboutissants des produits cartésiens, en fournissant des informations pratiques et des exemples.
Pour les débutants en SQL, commencez par notre cours SQL Intermédiaire pour construire une base solide. Par ailleurs, l' aide-mémoire SQL Basics, que vous pouvez télécharger, est une référence utile car il contient toutes les fonctions SQL les plus courantes.
Le produit cartésien en SQL est le résultat de la combinaison de chaque ligne d'un tableau avec chaque ligne d'un autre tableau. Cette opération est le plus souvent générée par le biais d'un site CROSS JOIN, formant un ensemble de résultats contenant toutes les paires possibles de lignes des deux tableaux. Bien que puissant, il peut conduire à des ensembles de résultats très volumineux, en particulier lorsque vous travaillez avec des tableaux contenant de nombreuses lignes, et doit donc être utilisé avec prudence. En fait, je parierais que de nombreux développeurs ont découvert les produits cartésiens à la dure en omettant accidentellement une condition de jointure quelconque, pour se retrouver avec un ensemble de résultats volumineux.
En mathématiques, un produit cartésien (noté A × B) est un ensemble de toutes les paires ordonnées possibles créées en associant chaque élément de l'ensemble A à chaque élément de l'ensemble B. En SQL, cela se traduit par l'association de chaque ligne d'un tableau à chaque ligne d'un autre tableau.
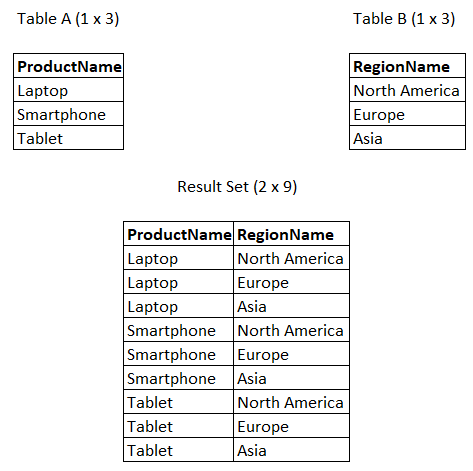
Exemple de produit cartésien. Image par l'auteur.
L'opération de jointure croisée en SQL crée un produit cartésien entre deux tableaux en joignant chaque ligne du premier tableau à chaque ligne du second. Par conséquent, la jonction croisée génère toutes les combinaisons de lignes possibles pour les données. Examinons un exemple d'opération de jointure croisée en SQL.
Supposons que vous ayez deux tableaux, Students et Courses:
Tableau des élèves
| nom | grade |
|---|---|
| Alice | 10 |
| Bob | 11 |
| Charlie | 12 |
Tableau des cours
| cours | niveau |
|---|---|
| Mathématiques | De base |
| Science | Avancé |
| L'histoire | Intermédiaire |
Dans la requête suivante, chaque étudiant est associé à chaque cours, avec indication de sa note et de son niveau de difficulté.
-- Perform the cross join to list each student with every course
SELECT Students.name, Students.grade, Courses.course, Courses.level
FROM Students
CROSS JOIN Courses;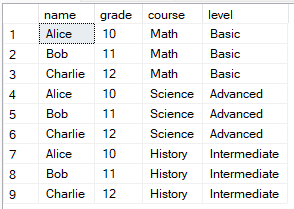
Exemple de produit cartésien en SQL résultant d'une jointure croisée. Image de l'auteur.
Le produit cartésien dans SQL peut être très utile lorsque le comportement est compris et utilisé intentionnellement. Examinons les cas d'utilisation (et les pièges potentiels) du produit cartésien.
Vous trouverez ci-dessous les scénarios dans lesquels l'utilisation du produit cartésien peut s'avérer utile :
Bien que le produit cartésien soit utile dans certains cas, il présente certains risques, notamment les suivants :
Bien que le produit cartésien puisse être utilisé avec parcimonie en raison des risques potentiels, il est utile dans les scénarios où vous devez combiner toutes les paires possibles d'éléments de données.
Le produit cartésien est utile pour calculer les performances relatives, analyser la compatibilité ou créer des systèmes de classement. Lorsque vous devez comparer tous les éléments de deux ensembles de données, vous pouvez utiliser le produit cartésien pour associer chaque élément à tous les autres.
Par exemple, pour comparer les performances de chaque employé avec celles de tous les autres employés, le produit cartésien créerait toutes les paires d'employés possibles :
-- Select two columns with employee names from the Employees table
SELECT
A.employee_name AS Employee1,
B.employee_name AS Employee2
FROM Employees AS A
-- Cross join to create all possible pairs of employees
CROSS JOIN Employees AS B;Le produit cartésien est également important dans l'analyse du commerce électronique pour explorer toute la gamme des combinaisons produit-rabais. Supposons que vous ayez des tableaux pour Products et Discounts, une jointure croisée pourrait créer une liste de toutes les combinaisons produit-rabais :
-- Select product names and discount types
SELECT
Products.product_name,
Discounts.discount_type
FROM Products
-- Generate all product and discount combinations
CROSS JOIN Discounts;Un produit cartésien permet de créer toutes les combinaisons de paramètres possibles dans les environnements de test, ce qui est essentiel pour tester des scénarios complets. Par exemple, si vous testez un système avec différentes configurations de systèmes d'exploitation, d'appareils et de navigateurs, l'utilisation d'une jonction croisée garantit que toutes les configurations possibles sont testées.
-- Select combinations of operating systems, devices, and browsers
SELECT
OS.name AS OperatingSystem,
Device.name AS Device,
Browser.name AS Browser
FROM OperatingSystems AS OS
-- All combinations with devices
CROSS JOIN Devices AS Device
-- All combinations with browsers
CROSS JOIN Browsers AS Browser;Un produit cartésien peut aider à identifier les enregistrements manquants, ce qui le rend utile pour garantir l'exhaustivité des données. Par exemple, lorsque vous analysez des données de ventes quotidiennes et que vous confirmez que des données existent pour chaque produit chaque jour, vous pouvez créer un produit cartésien des tableaux Products et Dates. Vous pouvez ensuite joindre à gauche les données de vente réelles afin d'identifier les entrées date-produit manquantes.
-- Select dates and products with no sales
SELECT
Dates.date,
Products.product_name,
Sales.sales_amount
FROM Dates
-- Create all date and product combinations
CROSS JOIN Products
-- Match sales by date and product
LEFT JOIN
Sales ON Dates.date = Sales.date
AND Products.product_name = Sales.product_name
-- Filter for combinations with no sales
WHERE Sales.sales_amount IS NULL;Étant donné que les produits cartésiens génèrent des combinaisons de données possibles entre deux tableaux, des problèmes de performance importants peuvent survenir lorsque des tableaux de grande taille sont concernés. Je propose les techniques suivantes pour l'optimisation des requêtes et la gestion de grands ensembles de données afin d'améliorer les performances des bases de données.
Considérez les méthodes suivantes pour écrire des requêtes efficaces qui impliquent des produits cartésiens.
Limitez le nombre de rangs avant l'assemblage : Pour réduire le nombre de tableaux impliqués dans le produit cartésien, appliquez des filtres à chaque tableau avant d'effectuer la jointure croisée. Par exemple, utilisez les clauses WHERE pour filtrer chaque tableau en fonction de critères pertinents, afin de minimiser l'ensemble de données résultant.
Utilisez SELECT avec des colonnes spécifiques : Lorsque vous effectuez un produit cartésien, spécifiez uniquement les colonnes dont vous avez besoin dans la clause SELECT afin de réduire l'utilisation de la mémoire et d'améliorer les performances. Évitez d'utiliser SELECT *, car il renvoie toutes les colonnes, ce qui risque de produire des résultats volumineux et difficiles à manipuler.
Appliquer des conditions pour convertir les jointures croisées en jointures internes : Si seules certaines combinaisons de lignes sont pertinentes, envisagez d'ajouter des conditions de jointure croisée supplémentaires qui fonctionnent comme INNER JOIN. Cela permet de restreindre les résultats en limitant les rangs de chaque tableau qui doivent être appariés.
Traitement par lots : Pour les grands ensembles de données, divisez les requêtes en morceaux gérables pour le traitement par lots. Cela permet d'éviter les débordements de mémoire et d'améliorer le temps de réponse, en particulier lorsque les requêtes portent sur des tableaux de grande taille.
Utilisez les techniques suivantes pour gérer les grands ensembles de données résultant de l'utilisation de produits cartésiens.
Indexation : Ajoutez des index sur les colonnes fréquemment jointes pour améliorer les performances lors du filtrage ou de l'appariement de tableaux volumineux. Bien que l'indexation n'accélère pas directement les jointures croisées, elle est utile lorsque vous filtrez ou joignez ultérieurement le produit cartésien à d'autres tableaux, ce qui permet à la base de données d'accéder plus rapidement aux lignes.
Partitionnement de tableaux de grande taille : Le partitionnement des tableaux peut améliorer les performances des requêtes impliquant des produits cartésiens. Le partitionnement divise les tableaux en éléments plus petits et plus faciles à gérer sur la base de colonnes spécifiques, ce qui permet à la base de données de ne lire que les partitions pertinentes lors de l'exécution de la requête.
Limiter les lignes de résultats : Utilisez la clause LIMIT pour limiter le nombre de lignes renvoyées dans les cas où vous n'avez besoin que d'un échantillon du produit cartésien à des fins de test ou de vérification.
Utilisez des tableaux temporaires pour les résultats intermédiaires : Stockez les résultats intermédiaires dans des tableaux temporaires si vous devez réutiliser un produit cartésien plusieurs fois afin de réduire les nouveaux calculs et d'accélérer les opérations ultérieures.
Dans les cas où la génération d'un produit cartésien complet n'est pas efficace, il existe d'autres méthodes. Les méthodes ci-dessous vous permettent d'obtenir les résultats escomptés sans surcharger la base de données.
Une adresse INNER JOIN ne renvoie que les lignes dont les colonnes spécifiées correspondent dans les deux tableaux. Cette technique permet de limiter le résultat aux combinaisons pertinentes et d'éviter les multiples lignes d'un produit cartésien. La jointure interne convient lorsque vous n'avez besoin que des lignes répondant à des critères spécifiques dans les deux tableaux.
Dans l'exemple ci-dessous, le site INNER JOIN ne renvoie que les produits et les remises qui partagent la même catégorie.
-- Select products and corresponding discounts by category
SELECT
A.product_name,
B.discount_type
FROM Products AS A
-- Match products and discounts by category
INNER JOIN Discounts AS B ON A.category_id = B.category_id;La jointure externe (LEFT JOIN, RIGHT JOIN, et FULL JOIN) renvoie les lignes appariées et non appariées d'un tableau ou des deux tableaux. Cette technique est utile pour récupérer tous les tableaux d'un tableau et toutes les lignes correspondantes de l'autre tableau, mais sans créer toutes les combinaisons possibles. La jointure externe est appropriée lorsque vous souhaitez inclure des données non appariées pour l'analyse, mais pas un appariement cartésien complet.
La requête LEFT JOIN ci-dessous renvoie tous les produits, y compris ceux qui n'ont pas de remise correspondante, avec les valeurs NULL pour les remises non correspondantes.
-- Select products with corresponding discounts, (NULL if no matching discount)
SELECT
A.product_name,
B.discount_type
FROM Products AS A
-- Match products with discounts by category
LEFT JOIN Discounts AS B ON A.category_id = B.category_id; Je vous recommande de suivre le cours Introduction à SQL Server de DataCamp pour en savoir plus sur la manière de joindre des tableaux et d'extraire des données de plusieurs tableaux.
Les sous-requêtes vous permettent de sélectionner des données spécifiques dans un tableau et de les utiliser pour filtrer les résultats de la requête principale. Cela permet d'éviter les combinaisons de lignes inutiles en filtrant les données pour ne conserver que les entrées pertinentes. Les sous-requêtes sont utiles lorsque vous devez pré-filtrer des données ou calculer des valeurs spécifiques à utiliser dans la requête principale sans avoir besoin d'une jointure cartésienne complète.
La sous-requête filtre les remises dont la valeur est supérieure à 10 avant la jointure, ce qui réduit les données traitées et évite une jointure croisée inutile.
-- Select products with discounts greater than 10 by category
SELECT
A.product_name,
B.discount
FROM Products AS A
-- Subquery to filter discounts over 10
INNER JOIN
(SELECT discount, category_id
FROM Discounts
WHERE discount > 10) AS B
-- Match products with filtered discounts by category
ON A.category_id = B.category_id; Les CTE, ou clauses WITH, permettent de décomposer les requêtes complexes en plusieurs étapes. Cette méthode permet d'éviter les produits cartésiens en filtrant ou en agrégeant les données avant de les joindre. Les ETC sont utiles pour simplifier les requêtes en plusieurs étapes, en particulier lors de l'agrégation préalable des données ou de l'exécution de jointures multiples, tout en évitant d'obtenir un résultat cartésien complet.
La requête ci-dessous utilise une expression de tableau commune (CTE) pour filtrer les remises supérieures à 10 avant de les associer à des produits basés sur la catégorie.
-- Filter discounts and join with products by category
WITH FilteredDiscounts AS (
SELECT discount, category_id
FROM Discounts
WHERE discount > 10
)
SELECT
A.product_name,
FD.discount
FROM Products AS A
-- Join with filtered discounts by category
INNER JOIN
FilteredDiscounts AS FD ON A.category_id = FD.category_id;Si le produit cartésien est largement utilisé dans les opérations SQL de base, il a des applications qui vont au-delà des cas d'utilisation traditionnels des bases de données. Voyons comment le produit cartésien peut être utilisé dans la préparation des données d'apprentissage automatique et la génération d'ensembles de données synthétiques pour la simulation.
Il est important de disposer d'ensembles de données diversifiés et complets lorsque l'on prépare des données pour l'apprentissage automatique afin de former des modèles robustes. Les produits cartésiens permettent de créer un ensemble de données complet qui couvre toutes les combinaisons possibles de valeurs de caractéristiques, ce qui permet à un modèle d'apprendre à partir d'un plus grand nombre de scénarios.
Par exemple, lorsque vous élaborez des modèles de détection des fraudes, vous pouvez combiner des types de transactions, des régions et des types d'appareils pour simuler différentes conditions, ce qui permet au modèle de se généraliser dans différents cas.
Les données synthétiques sont souvent utilisées pour tester des systèmes dans un large éventail de conditions ou pour protéger la vie privée en évitant d'utiliser des données réelles. Les produits cartésiens peuvent aider à générer divers ensembles de données synthétiques, qui sont utiles dans des applications allant des simulations à l'augmentation des données pour les modèles d'apprentissage automatique.
Par exemple, vous pouvez combiner différentes conditions de marché, taux d'intérêt et profils de clients dans des simulations financières pour tester les performances d'un modèle ou d'un algorithme en fonction de ces variables.
Vous trouverez ci-dessous un exemple simple de la manière dont vous pouvez créer des données synthétiques "à partir de rien", pour ainsi dire, en SQL, puis utiliser CROSS JOIN pour les étendre à un ensemble de données plus important. L'idée est que chaque petit tableau représente une dimension de nos données de test et que, lorsque nous les croisons, nous obtenons toutes les combinaisons possibles.
Supposons que vous souhaitiez simuler différents scénarios financiers basés sur les conditions du marché, les taux d'intérêt et les profils des clients. Nous pouvons définir chaque dimension au moyen d'une expression de tableau commune (CTE) ou d'un tableau temporaire utilisant des valeurs littérales. Ensuite, un site CROSS JOIN les fusionne pour obtenir toutes les combinaisons possibles :
WITH MarketConditions AS (
SELECT 'Bull' AS condition
UNION ALL
SELECT 'Bear'
UNION ALL
SELECT 'Sideways'
),
InterestRates AS (
SELECT 1.5 AS rate
UNION ALL
SELECT 2.0
UNION ALL
SELECT 3.25
),
CustomerProfiles AS (
SELECT 'Younger' AS profile
UNION ALL
SELECT 'Mid-career'
UNION ALL
SELECT 'Retired'
)
SELECT
mc.condition,
ir.rate,
cp.profile
FROM
MarketConditions mc
CROSS JOIN
InterestRates ir
CROSS JOIN
CustomerProfiles cp;L'ensemble de résultats comprendra 3×3×3 = 27 lignes. Chaque ligne représente une combinaison unique de conditions de marché, de taux d'intérêt et de profil de client.
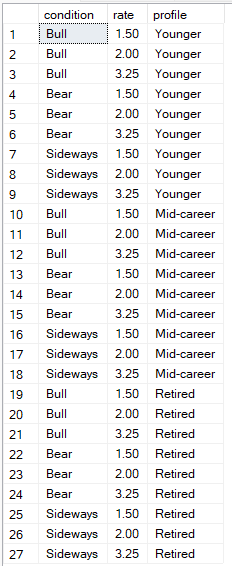
Exemple de génération de données synthétiques à l'aide du produit cartésien. Image par l'auteur.
Une autre technique consiste à générer une plage de nombres ou d'intervalles de temps en croisant de petits tableaux avec eux-mêmes. Cela permet de produire de grands volumes de lignes synthétiques pour des tests rapides. Par exemple, nous pouvons utiliser la requête suivante pour générer les nombres de 1 à 10.
WITH
Nums AS (
SELECT 1 AS n
UNION ALL SELECT 2
UNION ALL SELECT 3
UNION ALL SELECT 4
UNION ALL SELECT 5
UNION ALL SELECT 6
UNION ALL SELECT 7
UNION ALL SELECT 8
UNION ALL SELECT 9
UNION ALL SELECT 10
)
SELECT n
FROM Nums;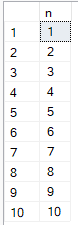
Utilisation du produit cartésien pour générer des lignes à l'aide de séquences. Image par l'auteur.
Nous pouvons ensuite joindre le même ensemble de 10 rangées à lui-même pour obtenir 10×10=100 :
WITH
Nums AS (
SELECT 1 AS n
UNION ALL SELECT 2
UNION ALL SELECT 3
UNION ALL SELECT 4
UNION ALL SELECT 5
UNION ALL SELECT 6
UNION ALL SELECT 7
UNION ALL SELECT 8
UNION ALL SELECT 9
UNION ALL SELECT 10
)
SELECT A.n AS n1, B.n AS n2
FROM Nums A
CROSS JOIN Nums B
ORDER BY A.n, B.n;Pour les résultats, vous obtiendrez 100 lignes, chaque ligne contenant une paire de valeurs (n1,n2). Vous pouvez étendre cette logique à des centaines, des milliers, voire des millions de lignes, mais attention aux performances et à l'espace de stockage.
En utilisant ces approches - les CTE (ou clauses VALUES ) pour la définition des dimensions et CROSS JOIN pour la combinaison - vous pouvez rapidement créer des ensembles de données synthétiques en SQL sans vous appuyer sur des tableaux existants.
La compréhension du produit cartésien en SQL ouvre de nombreuses possibilités de manipulation et d'analyse des données. En maîtrisant ce concept, vous pouvez améliorer votre capacité à travailler avec des ensembles de données complexes et optimiser vos requêtes de base de données. Pour des connaissances plus avancées, envisagez notre cursus de compétences SQL Server Fundamentals pour approfondir votre expertise.
En fonction de votre orientation professionnelle, je vous recommande de vous inscrire soit au cursus Associate Data Analyst in SQL de DataCamp pour acquérir les compétences requises pour devenir analyste de données, soit à notre cursus Associate Date Engineer in SQL pour devenir ingénieur de données.
Apprenez SQL avec DataCamp
Cursus
Cours
Cours