
Cursus
Scientifique des données en Python
26 h
Que vous soyez étudiant, aspirant data scientist ou professionnel souhaitant changer de carrière, si vous souhaitez devenir un data scientist expérimenté, il est nécessaire de suivre un parcours spécifique. Cela n'est pas toujours facile, car le domaine de la science des données s'est considérablement élargi et, par conséquent, il existe différents types de professionnels de la science des données avec des activités et des compétences variées.
Afin de vous aider à définir un parcours dans le domaine de la science des données, cet article présente une vue d'ensemble du secteur de la science des données, vous permettant ainsi d'identifier les postes qui correspondent à vos ambitions. De plus, il fournit des conseils sur la manière d'évoluer ou de progresser vers différents rôles au sein de ce domaine, en répondant à des questions telles que : Quelles compétences devriez-vous développer et quelles méthodes devriez-vous apprendre à maîtriser ?
Commençons par notre feuille de route en matière de science des données.
Dans cet article, nous examinons en détail tous les aspects de la feuille de route. Toutefois, si vous souhaitez obtenir un résumé rapide du plan, vous le trouverez ci-dessous :
En suivant cette feuille de route, vous pourrez vous orienter efficacement dans le domaine de la science des données, acquérir les compétences essentielles et poursuivre une carrière enrichissante dans ce secteur.
Afin de bien appréhender le contexte d'une feuille de route en science des données, il est essentiel de comprendre ce qu'est la science des données. Nous disposons d'un guide complet couvrant les définitions et les explications relatives à la science des données, mais dans le cadre de cet article, nous considérerons la science des données comme l'ensemble des activités visant à résoudre des problèmes à l'aide de données.
Un problème fréquemment rencontré est « J'ai une question, mais je ne connais pas la réponse ». Par conséquent, si vous exécutez une requête SQL sur une base de données commerciale pour déterminer le chiffre d'affaires réalisé par une organisation le mois dernier, vous êtes un data scientist.
Souvent, les problèmes/solutions sont plus complexes et nécessitent un ensemble de compétences plus diversifié. Afin de pouvoir aborder cette large gamme de rôles et de compétences en science des données tout au long de cette feuille de route, nous utiliserons le cycle de vie d'un projet de science des données comme cadre de référence. Cela nous permettra de cartographier les différentes activités et rôles et servira de base pour définir le domaine de la science des données.
Les projets liés à la science des données débutent généralement par une question ou un problème commercial. Un problème déclenche une phase d'initiation, au cours de laquelle un ensemble de solutions possibles est défini et la faisabilité initiale est évaluée. Une collecte initiale de données ou une analyse exploratoire des données disponibles est effectuée afin d'identifier les possibilités et les limites. Les données sont-elles suffisamment riches ? Contient-il suffisamment de fonctionnalités ?
Une fois que tous les voyants sont au vert, nous commençons à élaborer un modèle prédictif. Le modèle utilisera les données fournies pour prédire les résultats. Au départ, il pourrait s'agir d'un modèle unique, formé, testé et validé sur un ensemble de validation croisée k-fold (une technique d'apprentissage automatique permettant d'évaluer les performances probables d'un modèle sur des données non observées). Il s'agit du travail généralement effectué par les scientifiques de données classiques. Une fois que le modèle fonctionne suffisamment bien, il est temps de le mettre en production et de l'intégrer dans un pipeline au sein de l'infrastructure existante, où ses performances seront surveillées et où il sera réentraîné si nécessaire.
Chacune de ces phases requiert des compétences distinctes. Au cours de la phase de démarrage, les personnes doivent posséder un sens aigu des affaires, être familiarisées avec la transformation des données, le nettoyage, les statistiques descriptives et les statistiques inférentielles de base. Ce travail peut être effectué par un analyste de données et/ou un scientifique de données.
Au cours de la phase de modélisation, il est nécessaire de construire des modèles prédictifs. Des modèles simples, tels que les régressions, peuvent être élaborés par un analyste de données, mais si la complexité augmente, il sera nécessaire de faire appel à un data scientist pour créer un modèle à l'aide d'un algorithme existant, voire à un ingénieur en apprentissage automatique pour modifier les algorithmes actuels ou en créer de nouveaux.
Lors du déploiement et de la mise en production du modèle, vous entrez dans le domaine de l'ingénieur en apprentissage automatique ou de l'ingénieur de données. Contrairement aux étapes précédentes, il n'y a pas nécessairement de lien étroit avec l'activité commerciale, et la tâche à accomplir consistait à créer et à surveiller un pipeline autour du modèle prédictif afin de fournir des résultats fiables aux systèmes cibles appropriés.
Tout au long du processus, toutes les données doivent être accessibles aux bons endroits avec les métadonnées appropriées, ce qui relève de la responsabilité de l'architecte de données. Lorsque de nouvelles données sont ingérées ou que des données existantes sont transformées en nouvelles informations, elles garantissent également que les données aboutissent au bon endroit.
La manière dont les différents rôles contribuent aux différentes phases du cycle de vie est illustrée dans l'image ci-dessous. Étant donné que les différents rôles contribuent à différentes étapes, ils requièrent des compétences distinctes.
Les rôles au début du cycle de vie exigent davantage de sens des affaires et moins d'ingénierie, tandis que les phases ultérieures requièrent moins de sens des affaires et davantage d'ingénierie et d'optimisation des algorithmes. Pour illustrer ce point, en tant que data scientist, vous pouvez vous contenter de performances informatiques sous-optimales pour démontrer la valeur et les performances de votre modèle. Cependant, dès que vous êtes responsable de la mise en production des modèles, vous devez être en mesure d'optimiser la complexité computationnelle afin de garantir la rentabilité de votre pipeline.
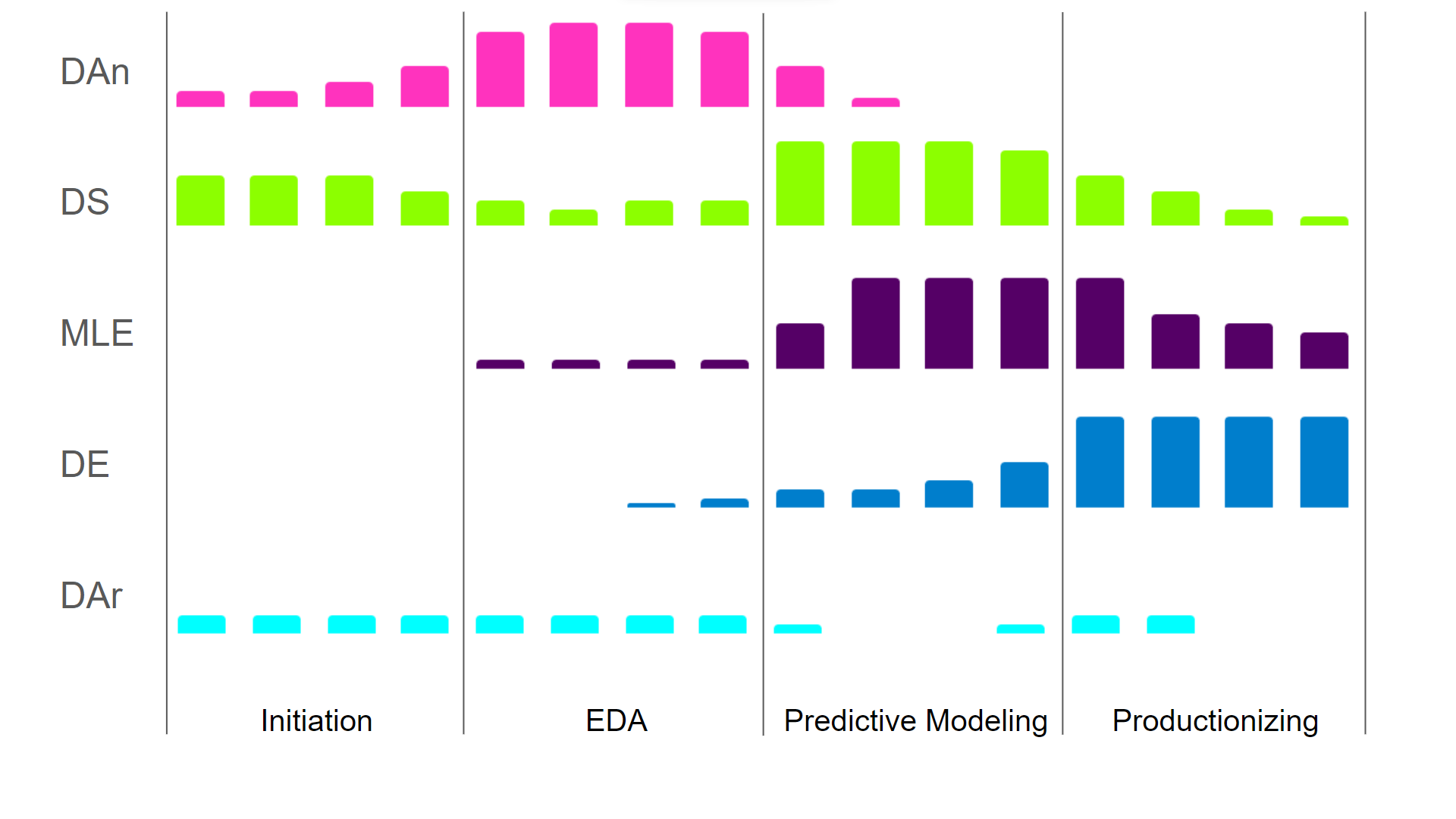
Niveau de contribution des différents rôles en science des données tout au long d'un projet de science des données (DAn - Analyste de données, DS - Scientifique des données, MLE - Ingénieur en apprentissage automatique, DE - Ingénieur de données, DAr - Architecte de données - Image par l'auteur
Il est important de noter que les délimitations entre les rôles ne sont pas strictes. De nombreux scientifiques des données réfléchissent déjà aux systèmes source/cible appropriés et à l'efficacité computationnelle, et en tiennent compte dans leur code. Un ingénieur en apprentissage automatique pourrait constater que certaines approches de génération de caractéristiques pourraient améliorer les performances du modèle. Un analyste de données pourrait fournir des conseils pertinents sur l'emplacement dans le catalogue de données où stocker les fonctionnalités générées pour l'architecte de données. En d'autres termes, tous les rôles doivent, dans une certaine mesure, être conscients du travail des autres rôles, mais ils ne sont pas tenus de comprendre en profondeur les responsabilités de chacun.
En ce qui concerne les compétences et les outils dont vous aurez besoin, il existe une base claire. Quel que soit le stade du cycle de vie d'un projet de science des données auquel vous contribuez, vous devrez posséder des connaissances de base en mathématiques et en statistiques, en développement logiciel collaboratif et en manipulation de données. De manière générale, le début de toute feuille de route en science des données comprend :
Il existe différents types de postes dans le domaine de la science des données, chacun exigeant des compétences spécifiques : un analyste de données devra posséder des connaissances plus approfondies en SQL qu'un ingénieur de données. Un Data Scientist doit avoir une meilleure connaissance du Machine Learning qu'un Data Architect. C'est donc ici que la feuille de route de la science des données se divise : en fonction de vos ambitions dans le domaine de la science des données, vous devrez acquérir différentes compétences. Les sections suivantes décrivent les différentes branches de la feuille de route que vous pouvez envisager.
Quel que soit votre niveau d'expérience dans le domaine de la science des données, que vous soyez un expert chevronné ou un débutant, tous les projets de science des données commencent par la compréhension de vos données.
Il est essentiel de bien comprendre vos données pour évaluer la faisabilité de votre projet. En commençant par des questions fondamentales telles que « Quelles variables est-ce que je possède ? » et « Combien d'observations est-ce que je possède ? », pour finir par des questions plus complexes telles que « Quelles sont les relations entre les variables ? »
Il arrive fréquemment que les résultats d'une EDA constituent en eux-mêmes la réponse aux questions de vos parties prenantes. Lorsqu'ils sont correctement visualisés et présentés de manière cohérente, par exemple dans un tableau de bord, les résultats d'une analyse de données simple peuvent être utilisés pour répondre à des questions complexes. Cela dépend toutefois des compétences en matière de visualisation des données.
Cependant, le simple fait de démontrer à travers votre EDA qu'il existe, par exemple, différents segments de visiteurs sur votre site web, vous permet d'apporter une valeur ajoutée en tant que data scientist.
Il existe plusieurs façons de visualiser vos résultats. Soit dans les bibliothèques/packages de visualisation du langage que vous utilisez (tels que ggplot2 de R et matplotlib de Python), soit dans des outils de visualisation de données dédiés (tels que PowerBI, Tableau ou même Excel).
En particulier lorsque nous nous concentrons davantage sur les tâches d'un analyste de données, il est utile d'avoir une compréhension approfondie de la visualisation des données.
Pour la plupart des postes dans le domaine de la science des données, les visualisations peuvent servir à vérifier des hypothèses à l'aide de graphiques à nuages et d'histogrammes. Cependant, lorsque l'analyse elle-même constitue le résultat attendu, comme c'est le cas pour un analyste de données, il est fréquent de vouloir rendre les résultats de l'analyse plus accessibles.
Envisagez des styles maison personnalisés, de nouvelles visualisations ou des infographies qui serviront de base à une unité décisionnelle. Dans ces situations, il est utile de pouvoir créer une visualisation des données qui s'apparente pratiquement à une œuvre d'art. Le cours « Comprendre la visualisation des données » est particulièrement utile pour approfondir vos compétences en la matière.
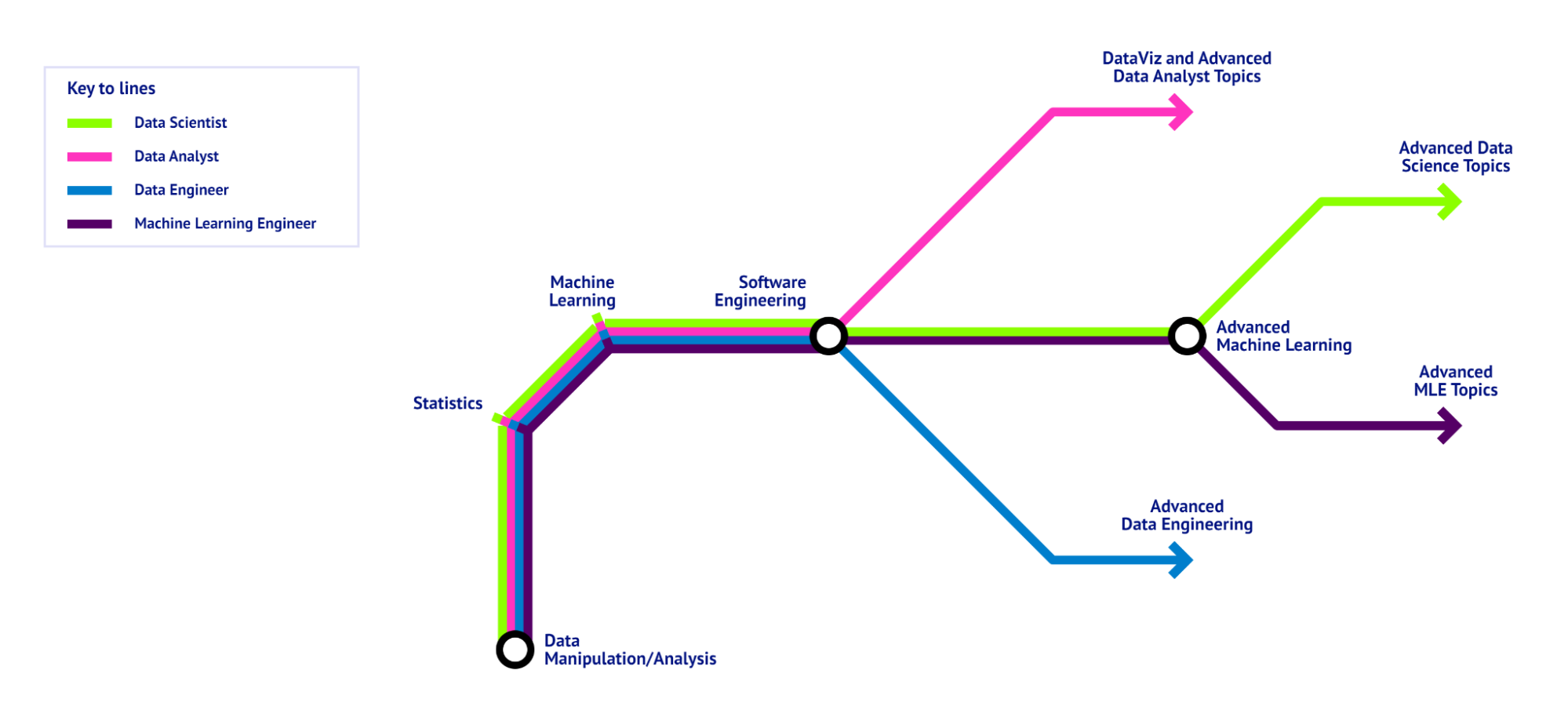
Une feuille de route pour la science des données, représentée sous forme de plan de métro, illustrant les bases communes à tous les rôles dans le domaine de la science des données et les compétences spécifiques à chaque rôle. - Image par l'auteur
Une autre étape importante dans le parcours de la science des données est la statistique. Certaines notions statistiques fondamentales devraient être acquises naturellement par tout type de scientifique des données.
À tout moment, vous devrez être en mesure de décrire vos données et les sous-groupes qui les composent. Quel est le revenu moyen dans votre ensemble de données ? Quels sont les revenus minimum et maximum requis ? Quelle est l'écart type, ou quelles sont les autres mesures de dispersion ? Et si vous avez des valeurs catégorielles, combien y a-t-il de valeurs uniques ? Quel est le plus fréquent ? Toutes les valeurs apparaissent-elles avec la même fréquence ou leur répartition est-elle moins uniforme ?
Répondre à des questions à l'aide d'analyses descriptives sur des groupes/sous-groupes peut déjà fournir des informations précieuses, mais le plus souvent, il est nécessaire d'examiner la relation entre les variables de votre ensemble de données et de s'orienter vers des statistiques inférentielles.
L'aspect stimulant et intéressant des statistiques inférentielles réside dans les différents types de valeurs catégorielles et numériques et dans les relations qui existent entre elles. Parmi ces exemples, on peut citer :
Pour pouvoir répondre à ces questions, il est nécessaire de connaître les différents types de tests statistiques, allant du test T, le plus simple, à des méthodes plus complexes telles que les régressions linéaires multivariées ou l'analyse des séries chronologiques.
Vous pouvez suivre des cours pertinents pour approfondir vos connaissances en statistiques dans les domaines suivants : Python, R, et même indépendamment des outils. Ces cours fournissent une base adéquate pour commencer à travailler avec l'apprentissage automatique. En comprenant statistiquement la relation entre les prédicteurs et les variables cibles, vous saurez appréhender les principes des algorithmes utilisés pour créer des modèles d'apprentissage supervisé.
Le niveau d'approfondissement de ce domaine dépendra à nouveau de l'orientation que vous souhaitez donner à votre feuille de route en matière de science des données. Si vous souhaitez devenir analyste de données, il peut suffire de comprendre les bases des statistiques. Les architectes de données peuvent ne nécessiter aucune connaissance en statistiques. Cependant, les scientifiques des données et les ingénieurs en apprentissage automatique seront certainement confrontés à des situations dans lesquelles ils devront s'appuyer sur leur expertise statistique.
La science des données repose sur les chiffres et les calculs, et par conséquent, les mathématiques y occupent une place importante. Bien qu'un diplôme supérieur en mathématiques ne soit pas indispensable pour se lancer dans la science des données, la maîtrise de l'algèbre et du calcul différentiel vous aidera à comprendre les concepts qui sous-tendent un certain nombre de méthodes couramment utilisées dans ce domaine. La plupart des approches de réduction de dimensionnalité (telles que l'ACP et la factorisation matricielle) s'appuient sur l'algèbre linéaire, et de nombreux algorithmes d'optimisation (tels que la descente de gradient) s'appuient sur le calcul différentiel et intégral.
Tout comme pour les statistiques et l'analyse de données, ces connaissances ne sont pas nécessairement pertinentes pour tous les postes dans le domaine de la science des données. Si vous souhaitez devenir ingénieur en apprentissage automatique, il est indispensable de maîtriser les mathématiques. Cependant, la plupart des autres postes, y compris celui de data scientist, peuvent être occupés sans nécessairement maîtriser l'algèbre et le calcul différentiel.
Pour approfondir et mieux appréhender les concepts algébriques, nous vous invitons à consulter notre cours sur l'algèbre linéaire pour la science des données dans R.
L'apprentissage automatique est l'art de créer des logiciels qui apprennent à partir de données. Il s'agit véritablement d'un élément essentiel pour les scientifiques des données, les ingénieurs en apprentissage automatique et même les ingénieurs de données. La partie de votre solution qui fournit les revenus de vente attendus pour votre entreprise, en fonction de votre inventaire et de vos prix ? Ceci est réalisé grâce à l'apprentissage automatique.
Le niveau minimum de connaissances requis pour un data scientist est la capacité à former et à évaluer des modèles. Dans certaines situations, il peut être souhaitable d'approfondir vos connaissances et d'apprendre à modifier des algorithmes existants, voire à en créer de nouveaux, entrant ainsi dans le domaine de l'ingénierie en apprentissage automatique.
Vous disposez d'une grande liberté dans la manière dont vous abordez l'apprentissage automatique. Vous pouvez soit coder tout vous-même (en Python, R, C# ou Java, avec les bibliothèques appropriées), soit utiliser des progiciels locaux (tels que Weka et RapidMiner), soit encore recourir à des solutions cloud (telles que Databricks et AWS SageMaker). Bien que cela complique le choix des matières à étudier, les compétences acquises sont facilement transférables. Une bonne approche pour déterminer quel kit d'outils d'apprentissage automatique utiliser consiste à commencer par un langage que vous maîtrisez déjà ou à examiner les outils utilisés dans le secteur qui vous intéresse.
Vous pouvez débuter avec notre cursus professionnel « Machine Learning Scientist with Python », qui couvre de nombreux principes fondamentaux dont vous aurez besoin pour démarrer votre carrière.
La relation entre l'apprentissage automatique, l'apprentissage profond et l'intelligence artificielle est sujette à débat.
Lorsque j'enseignais l'apprentissage automatique, ma première conférence consistait toujours en un débat animé en classe sur l'affirmation suivante : « L'apprentissage automatique est une forme d'IA. » Bien que ces termes soient parfois utilisés de manière interchangeable, je suis convaincu que l'apprentissage automatique rend possible l'intelligence artificielle, mais cela ne signifie pas pour autant que l'utilisation de l'apprentissage automatique équivaut à la création d'une intelligence artificielle.
Pour qu'une application de données devienne une IA, il est essentiel qu'il existe une boucle de rétroaction dans laquelle l'application ou le modèle apprend à partir de ses résultats. Dans ce cas, un algorithme d'apprentissage supervisé ponctuel n'est pas nécessairement de l'IA. Si vous renvoyez les résultats du modèle vers le modèle (comme dans le cas de l'apprentissage par renforcement), vous obtenez effectivement une IA, car vous disposez d'un système qui continue automatiquement à apprendre à partir de ses prédictions correctes et incorrectes.
L'apprentissage profond n'est guère plus que des réseaux neuronaux optimisés. Ce qui rend ces applications intéressantes, c'est que le Deep Learning permet d'obtenir des résultats très concrets, car ces modèles peuvent produire du texte, des images et de la parole. Si vous travaillez sur un projet de science des données où il est essentiel que les modèles produisent quelque chose qui puisse être perçu ou expérimenté par les utilisateurs finaux humains, la compréhension du deep learning peut constituer un réel avantage. Le cours « Introduction au Deep Learning en Python » constitue une excellente initiation.
Aucun effort en science des données n'est isolé. Au fur et à mesure que vous progressez dans votre parcours, il est important de conserver et de mettre en valeur les artefacts que vous produisez. Une partie du métier de data scientist consiste à démontrer ses capacités.
Pour moi, l'aspect le plus passionnant de la science des données est qu'elle ne nécessite pas beaucoup de ressources. Il vous suffit d'un ensemble de données publiques et d'un peu de créativité pour formuler une question intéressante, puis d'y répondre à l'aide des données. Vous pouvez également vous rendre sur DataLabou Kaggle et commencer à travailler sur les devoirs et/ou les concours, en vous inspirant des autres contributions.
Vous pouvez également collecter et utiliser vos propres données. J'ai analysé mes données cyclistes téléchargées depuis Strava et j'ai collecté des données immobilières afin de m'aider dans ma recherche sur le marché immobilier.
Le plus important est de documenter vos actions. Veuillez vous efforcer de rendre votre travail reproductible, d'expliquer les étapes que vous avez suivies, de partager votre code et de partager les résultats de votre analyse ou de votre système. Qui sait ? Il est possible que votre exercice pratique soit la solution exacte au problème de quelqu'un.

À mon avis, les projets les plus intéressants sont ceux qui découlent de votre propre passion et de vos propres intérêts. Si vous utilisez un ensemble de données provenant d'une source que vous connaissez bien, il y a de fortes chances que vous puissiez formuler des questions uniques et intéressantes. Vous connaissez le domaine et vous connaissez les données... Cependant, si vous débutez véritablement à partir de zéro, il existe de nombreux domaines dans lesquels vous pouvez vous lancer, notamment les applications de rencontre, le trading et le sport.
Vous pouvez également trouver une vaste gamme de projets liés à la science des données sur DataCamp, qui vous permettront de vous familiariser avec ce type de travail. Que vous commenciez par des projets d'analyse de données ou que vous travailliez sur des projets Python spécifiques, vous pouvez évoluer vers des projets d'apprentissage automatique et même d'intelligence artificielle. Il existe de nombreuses options pour vous aider à démarrer.
Si, malgré toutes les ressources disponibles, vous ne parvenez pas à vous lancer, une autre alternative utile pourrait être de participer à des hackathons. De nombreux instituts de recherche et grandes entreprises organisent régulièrement des hackathons.
Ces hackathons ont souvent pour objectif de réunir des équipes de scientifiques des données autour d'un problème pertinent et offrent ainsi l'occasion de collaborer avec d'autres professionnels de la science des données et d'apprendre à leurs côtés. Cela vous permet de développer un réseau et d'être remarqué par des employeurs potentiels tout en acquérant une expérience précieuse.
De nos jours, il est difficile d'imaginer un data scientist qui ne dispose pas d'un profil GitHub, d'un portfolio DataCamp, d'une page Medium ou d'un blog avec du code. Un portfolio est un élément essentiel en science des données, tout comme dans d'autres industries créatives.
Être en mesure de présenter des projets antérieurs constitue un excellent moyen de convaincre les gens que vous possédez les compétences requises. C'est pourquoi il est important de commencer à documenter votre travail dans un portfolio. Vous pouvez également documenter votre travail et vos points de vue sous forme d'articles de blog ou même de publications universitaires. Nous vous invitons à consulter notre article sur la mise en valeur de votre expertise en matière de données à l'aide d'un portfolio pour trouver l'inspiration.
Quel que soit votre choix, veillez à conserver une vue d'ensemble présentable des projets sur lesquels vous avez travaillé.
Cet article a mis en évidence les différentes compétences, connaissances et outils à la disposition d'un data scientist. Cependant, par où commencer lorsqu'il s'agit de choisir une carrière ?
À mon avis, cela dépend vraiment de vos ambitions. Cet article devrait avoir clairement démontré que je ne considère pas qu'il existe une feuille de route unique en matière de science des données.
Bien entendu, chaque poste dans le domaine de la science des données repose sur des bases solides en statistiques, en manipulation de données, en apprentissage automatique et en génie logiciel. Cependant, cela dépend vraiment des circonstances.
Un data scientist utilise des algorithmes, tandis qu'un ingénieur en apprentissage automatique modifie ou crée des algorithmes. Le data scientist peut donc se contenter de connaître un grand nombre d'algorithmes et de savoir quand les appliquer, tandis que l'ingénieur en apprentissage automatique doit vraiment comprendre les concepts mathématiques qui sous-tendent les algorithmes.
De même, si vous tirez votre énergie du partage des résultats d'analyses, comme c'est le cas des scientifiques ou des analystes de données, vous tirerez probablement davantage profit d'une connaissance approfondie de la visualisation des données et de l'EDA que d'une grande maîtrise de la modélisation des données.
Ainsi, la feuille de route de la science des données comporte plusieurs bifurcations, et vous pouvez décider vous-même jusqu'où vous souhaitez vous engager dans les différentes branches de la science des données.
Malgré les différences entre les postes, lors de tout entretien, vos compétences techniques et relationnelles seront évaluées. Ces tests varieront en fonction du poste que vous visez.
Si vous ne postulez pas pour un poste tel que celui d'ingénieur en apprentissage automatique ou en données, il est peu probable qu'on vous pose des questions telles que « Comment optimiseriez-vous l'algorithme A ou B ? ». Il est donc essentiel de se concentrer sur les compétences et, par conséquent, sur les questions sur lesquelles vous êtes invité et désireux de travailler. Recevoir des questions sur des sujets que vous ne maîtrisez pas peut indiquer que le poste n'est pas adapté à votre profil.
Dans ce domaine relativement nouveau, en particulier dans les entreprises où les données sont encore peu utilisées, il existe de nombreuses idées fausses sur ce qu'est un data scientist et sur son rôle.
Je suis conscient d'avoir postulé au poste de data scientist, pour lequel le recruteur a utilisé indifféremment les termes « data scientist » et « ingénieur en apprentissage automatique ». Il est donc tout à fait possible que le responsable du recrutement ait commis une erreur si l'on vous pose des questions auxquelles vous ne pouvez pas répondre. Il est rare qu'un ingénieur de données soit interrogé sur la manière dont il gérerait les parties prenantes dans le cadre d'un projet, par exemple.
Heureusement, plusieurs ressources sont disponibles pour vous aider à vous préparer aux entretiens dans ce domaine, en fonction du poste auquel vous postulez :
Le domaine de la science des données est en constante évolution, et il est essentiel de se tenir informé des dernières tendances. Avec chatGPT, l'IA générative s'est généralisée, et il est désormais difficile d'imaginer un data scientist qui n'ait pas au moins une notion des intégrations de tokens et/ou des modèles d'attention. De même, l'introduction du MLOps rend difficile l'idée qu'un ingénieur de données vérifie manuellement les performances et la dérive des modèles.
Avec cette croissance dynamique, différents aspects de l'IA prennent de l'importance. Actuellement, les aspects éthiques et juridiques de l'IA font l'objet d'une attention particulière, comme en témoignent plusieurs débats universitaires et politiques qui ont notamment abouti à l'adoption de nouvelles règles et réglementations.
Indépendamment des décisions prises par les gouvernements en matière d'IA, personne ne souhaite être tenu responsable du prochain scandale dans le domaine de la science des données. La seule manière d'éviter cela est de rester conscient des limites éthiques et juridiques. Ou mieux encore, en tant que professionnel des sciences de la donnée, vous pouvez commencer à contribuer à ces développements en utilisant votre expérience et en formant et exprimant votre opinion.
Il existe de nombreuses façons de se tenir informé. Bien entendu, il existe DataCamp en tant que plateforme, mais vous pouvez également commencer à rechercher et à suivre des professionnels inspirants dans le domaine de la science des données qui travaillent dans votre secteur. Vérifiez s'ils disposent de blogs, de publications sur X ou Medium, ou de tout autre support permettant de comprendre leur vision de ce paysage en constante évolution.

Comme nous l'avons souligné tout au long de cet article, il existe de nombreuses ressources à la disposition de toute personne souhaitant se lancer ou se perfectionner dans le domaine de la science des données. Sinon, si vous souhaitez être au plus près de la source, vous pouvez vous tourner vers des conférences techniques telles que NeurIPS, ICML ou KDD. Découvrez ces conférences et bien d'autres encore dans notre liste des meilleures conférences sur la science des données pour 2026.
Bien qu'il existe de nombreuses étapes dans le parcours de la science des données, il n'y a pas de voie unique à suivre dans ce domaine. Pour vous orienter dans le domaine de la science des données, il est nécessaire que vous ayez 1) une compréhension du domaine (que vous obtiendrez, nous l'espérons, grâce à cet article) et 2) une connaissance de vos forces, faiblesses et intérêts, afin de pouvoir déterminer la voie à suivre.
Si vous possédez ces qualités, vous pouvez vous appuyer sur cet article pour vous orienter dans la bonne direction et déterminer les compétences sur lesquelles vous devez mettre l'accent pendant votre formation. Heureusement, il existe des ressources utiles pour vous aider à démarrer, telles que les cursus professionnels de DataCamp, qui vous fournissent les compétences nécessaires pour explorer différentes professions :
Commencez dès aujourd'hui votre parcours dans le domaine de la science des données.
Cursus
Cours
Cours