Cours
Concevoir des systèmes agentiques avec LangChain
3 h
12.2K
Bienvenue ! Nous y sommes presque : Slack gazouille, Jira a des tickets, les tests sont verts, et notre CI bloque tous les PR bâclés. La quatrième partie est l'étape finale où nous transformerons l'aire de jeu du fp-ts en quelque chose que nous pourrions, en théorie, montrer au public.
Vous pouvez accéder à tous les tutoriels de la série Devin ici :
Voici le plan de ce quatrième tutoriel :
Nous réfléchirons également à cette programmation en binôme avec Devin et verrons où elle brille et où un humain doit encore régler les détails avant que le monde ne voie le repo. Prêt pour la dernière ligne droite ?
En bref, j'ai demandé à Devin de supprimer le flux anonyme UUID et de me donner une vraie pile d'authentification :
apps/webUser et modifie Progress.sessionId → userId (non nul)Voici un résumé des résultats :
Devinez ce que j'ai vu apparaître à nouveau dans la petite boîte à idées de Devin.
Migration réussie de PostgreSQL vers SQLite pour le développement local 🥳
Exactement ce que je lui avais dit de ne pas faire ( ). Le schéma Prisma a été réécrit pour SQLite, et les chaînes de connexion et les types ont été modifiés (de TIMESTAMP à DATETIME). Je l'ai vu au milieu de la session :
git checkout main apps/api/prisma/schema.prisma (restauration du schéma Postgres).dev.db.npm run prisma:migrate --workspace=apps/api pour réappliquer les migrations Postgres.Dommages : 0,8 ACU et une dizaine de minutes.
J'apprécie vraiment les instructions que Devin donne dans les PR. Ici, il nous a dit de le faire :
# 1 Install new deps
npm install --workspaces
# 2 Run the Postgres migration
npm run prisma:migrate --workspace=apps/api
# 3 Restart everything
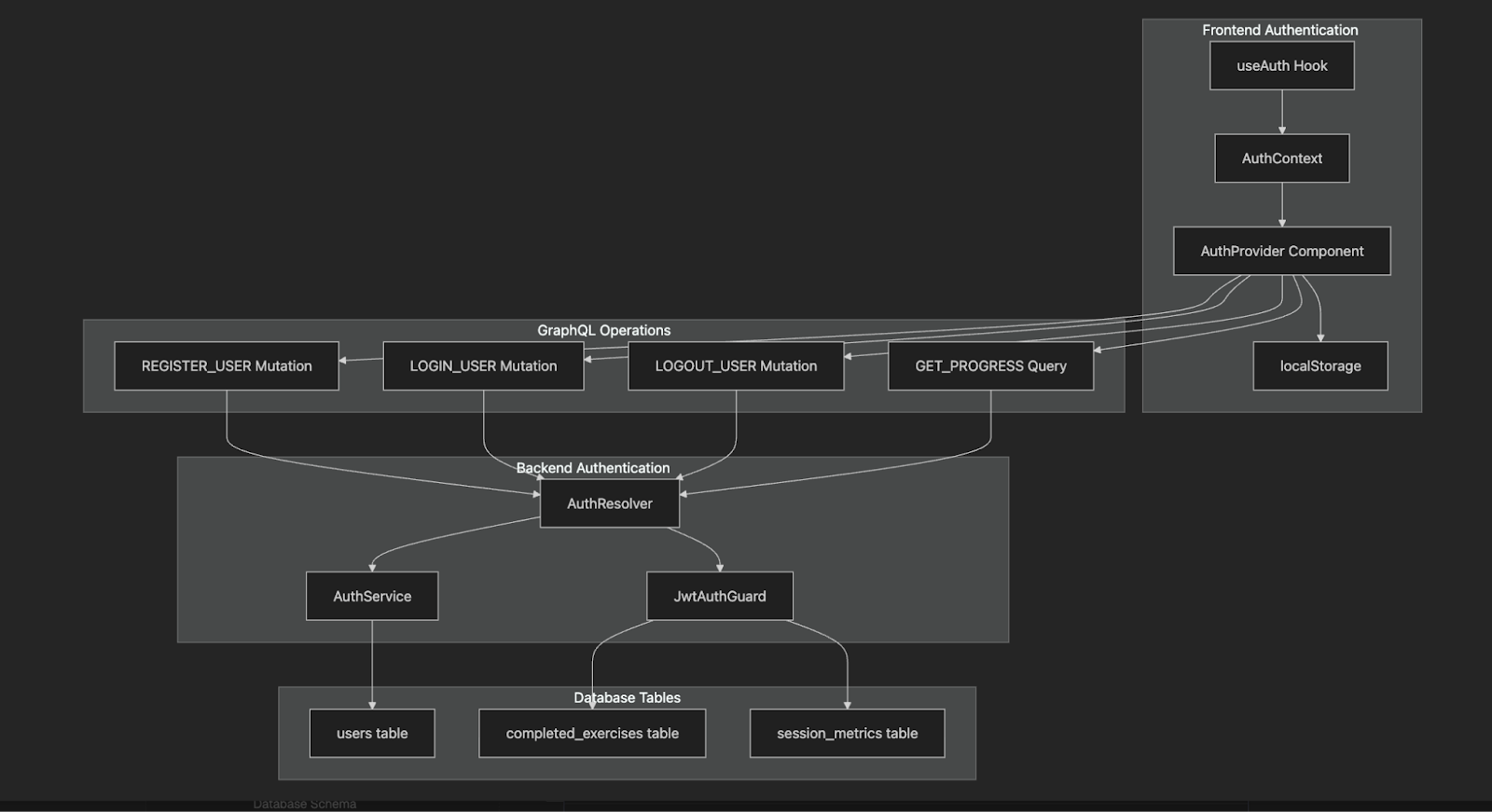
npm run dev:api & npm run dev:webDans le wiki, j'ai trouvé ce diagramme utile de notre nouveau système d'authentification :
Avec de vrais utilisateurs en place et la base de données fermement revenue sur Postgres, nous sommes enfin prêts à suivre les progrès des apprenants authentiques, à envoyer des versions préliminaires à Vercel et à détecter les erreurs d'exécution avec Sentry.
Une fois les connexions sécurisées mises en place, la prochaine étape évidente était de montrer au monde quelque chose de cliquable. Nous avons décidé de ne déployer que le front-end Next.js pour l'instant. API et Postgres resteront sur ma machine locale jusqu'à ce que nous choisissions un hébergeur qui corresponde à notre budget.
Connecter Devin à mon compte Vercel personnel via les intégrations natives n'est pas encore possible. Je l'ai donc fait manuellement, via le tableau de bord Vercel :
fp-ts-exercises, laissez la commande de construction comme npm run build --workspace apps/web, et cliquez sur Deploy.VERCEL_PROJECT_ID et VERCEL_TOKEN dans GitHub Secrets.Suite à mon invitation, Devin a ajouté une tâche unique au bas du flux de travail existant et une minuscule étape shell qui boucle l'URL générée vers Slack :
- name: Deploy to Vercel
if: ${{ success() && github.event_name == 'pull_request' }}
run: npx vercel deploy --prod --token ${{ secrets.VERCEL_TOKEN }}
env:
VERCEL_ORG_ID: ${{ secrets.VERCEL_ORG_ID }}
VERCEL_PROJECT_ID: ${{ secrets.VERCEL_PROJECT_ID }}Pousser une branche → CI green → Slack ping :
✅ Preview ready: https://fp-ts-exercises-git-my-branch.vercel.appEn ouvrant le lien, vous avez pu voir notre aire de jeu, notre flux d'authentification complet et notre tableau de bord de l'apprenant. Aucune modification de l'environnement n'est encore nécessaire du côté de Vercel, car le front-end communique avec mon API locale via http://localhost:4000.
Avant d'intégrer Sentry, j'ai jeté un coup d'œil au système de secrets de Devin pour savoir si je devais l'utiliser. Devin propose un coffre-fort intégré "Secrets" qui vous permet de donner à l'agent des clés API, des URL de base de données ou des jetons OAuth sans les enregistrer dans Git et sans les exposer dans le chat. Considérez-le comme un équivalent léger des secrets d'actions de GitHub ou des variables d'environnement de Vercel, mais limité aux espaces de travail de Devin dans le cloud.
Voici les étapes à suivre pour ajouter un secret :
SENTRY_DSN_WEB ) et sa valeur.$.SENTRY_DSN_WEB.
Tâche : mise à jour de l'initialisation de l'API Sentry ; définir le DSN sur $SECRET.SENTRY_DSN_API
Devin substitue la valeur lorsqu'il écrit main.ts. Dans l'onglet shell, vous verrez le DSN littéral, mais le journal de discussion le masque.
Pour :
Cons :
.env. Les essais en dehors de Devin nécessitent une configuration manuelle.Je trouve qu'il est plus facile d'utiliser le coffre-fort de Devin lorsque Devin lui-même a besoin de la clé (par exemple, en poussant vers Vercel, en frappant un registre privé, ou en câblant Sentry pendant la construction). Je continuerais à utiliser .env / GitHub Actions secrets pour tout ce qui s'exécute également dans votre shell de développement local ou vos exécutions CI.
Voici le texte que j'ai utilisé : Ajoutez Sentry aux deux applications pour que chaque exception apparaisse dans mon tableau de bord. Utilisez les variables d'environnement dans .env. Il n'y a pas d'autre changement de comportement".
Voici un résumé des résultats :
Voici les étapes que j'ai suivies :
.env.http://localhost:4000/graphql pour vérifier qu'elle fonctionnait. Un problème est apparu dans Sentry en quelques secondes.C'est la raison pour laquelle j'ai sauté l'étape des secrets de Devin :
.env partout.Il y a quatre parties de tutoriel, ce repo était une pile poussiéreuse d'exercices de fp-ts - maintenant, c'est fait :
Nous avons dépensé environ ≈ 70 UCA au total (~157 $ pour le plan de base) et environ deux jours ouvrables d'examen pratique.
C'est là que je pense que Devin est très bon :
C'est sur ce point que je pense que Devin doit encore s'améliorer :
Les documents de Devin n'ont jamais promis un constructeur de produits. Ils définissent une zone de tolérance beaucoup plus étroite et, rétrospectivement, j'aurais dû rester à l'intérieur de cette zone. La page officielle "Quels sont les points forts de Devin ? énumère quatre utilisations des titres :

La documentation qualifie d'"expérimental" le développement de fonctionnalités qui couvrent l'interface utilisateur, l'API et les flux de données. Ils sont décrits comme des tâches importantes et ouvertes pour lesquelles l'agent peut "nécessiter une révision et une itération humaines significatives". C'est exactement ce que nous avons vu lorsque Sandpack a codé des tests en dur ou lorsque le tableau de bord semblait bon mais ne calculait pas réellement les données.
Donc, en règle générale :
Utilisez Devin pour tout ce qu'un développeur senior pourrait automatiser à l'aide d'un script, et gardez le volant pour les tâches qui nécessitent un sens du produit.
Nous sommes arrivés à la fin de notre tutoriel en quatre parties :
Voici les prochaines étapes à suivre :
Si vous suivez la même voie, rappelez-vous : vous pouvez laisser l'agent poser le béton, mais c'est à vous de concevoir la maison. Bon codage !
Créez des agents d'intelligence artificielle avec ces cours :
Cours
Cours
Cours