
Kursus
Pengantar Statistika di R
4 Hr
131.6K
Memahami cara menganalisis dan menafsirkan data adalah keterampilan yang sangat berharga bagi para profesional data. Ada banyak uji statistik berbeda yang digunakan untuk alasan yang berbeda. Uji chi-square adalah uji yang umum digunakan dalam konteks tertentu: ketika Anda perlu menentukan hubungan antar variabel kategorikal. Ini adalah hal umum yang perlu diketahui peneliti, itulah sebabnya uji chi-square menjadi salah satu uji statistik yang paling sering digunakan.
Tutorial ini memperkenalkan uji chi-square, jenis-jenisnya, dan langkah-langkah untuk melakukannya menggunakan bahasa pemrograman R. Di akhir panduan ini, Anda akan dibekali pengetahuan dan keterampilan untuk menerapkan uji chi-square pada data Anda sendiri dan menafsirkan hasilnya dengan percaya diri.
Jika Anda baru dalam bahasa pemrograman R, Anda dapat melihat jalur karier Data Analyst with R yang ramah pemula untuk membiasakan diri dengan bahasa tersebut melalui contoh analisis data langsung.
Untuk melakukan uji chi-square di R, ikuti langkah-langkah berikut:
Langkah 1: Siapkan data Anda dalam format tabel kontingensi.
Langkah 2: Gunakan fungsi chisq.test() untuk menerapkan uji chi-square.
Berikut contoh singkat yang mendemonstrasikannya menggunakan data sampel:
# Step 1: Creating a contingency table
data <- matrix(c(10, 20, 30, 40), nrow = 2)
# Step 2: Applying the chi-square test function
result <- chisq.test(data)
# Viewing the result
print(result)Cuplikan kode ini membuat tabel kontingensi 2x2 dan menjalankan uji chi-square. Hasilnya akan menampilkan statistik uji, derajat kebebasan, dan nilai p.
Uji chi-square adalah uji statistik yang digunakan untuk menentukan apakah terdapat asosiasi yang signifikan antara variabel kategorikal. Uji ini membandingkan frekuensi teramati pada berbagai kategori dengan frekuensi yang diharapkan jika tidak ada asosiasi antar variabel.
Ada dua jenis utama uji chi-square:
Untuk memastikan validitas uji chi-square, beberapa asumsi harus dipenuhi:
Uji chi-square banyak digunakan di akademik dan industri, terutama untuk menguji hipotesis tentang kemandirian variabel kategorikal. Beberapa penerapan praktisnya antara lain:
Perlu dicatat bahwa ini hanyalah beberapa dari banyak penerapan di dunia akademik dan industri dan dapat diperluas ke domain dan bidang lain.
Cara terbaik mempelajari cara melakukan uji chi-square adalah melalui contoh saat kita menerapkan uji pada suatu dataset. Kita akan menggunakan dataset Anemia Levels in Nigeria, yang dapat diunduh dari Kaggle. Dataset ini berasal dari Survei Demografi dan Kesehatan Nigeria (NDHS) 2018. Dataset ini mengeksplorasi dampak usia ibu dan faktor sosial ekonomi terhadap tingkat anemia pada anak usia 0–59 bulan di 36 negara bagian Nigeria dan Wilayah Ibu Kota Federal.
Mari memuat dataset di R dan meninjau sampelnya untuk memahami data dengan lebih baik. Untuk membaca file CSV di R, Anda perlu memasang paket bernama readr.
# Load the necessary libraries
install.packages('readr')
library(readr)
# Load the dataset from the CSV file
dataset <- read_csv("children anemia.csv")
# Display the first few rows of the dataset
head(dataset)
# Rename a column
colnames(dataset)[colnames(dataset) == "Anemia level...8"] <- "Anemia level"
# Display the column names
colnames(dataset)Selain sampel dataset, kita juga akan melihat kolom-kolom pada dataset di bawah ini:
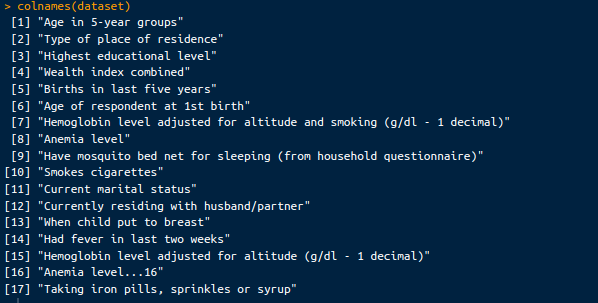 Kolom dalam dataset. Gambar oleh Penulis.
Kolom dalam dataset. Gambar oleh Penulis.
Di antaranya, kita akan memilih dua kolom berikut untuk mengevaluasi apakah ada hubungan di antara keduanya.
Tingkat pendidikan tertinggi: Kolom ini mengategorikan pendidikan ibu menjadi tingkat “No education”, “Primary”, “Secondary”, dan “Higher”.
Tingkat anemia: Kolom ini menunjukkan tingkat anemia pada anak, seperti “Moderate”, “Severe”, atau “No Anemia”.
Tabel kontingensi, juga dikenal sebagai tabulasi silang atau cross-tab, menunjukkan bagaimana nilai dari dua atau lebih variabel kategorikal terdistribusi di berbagai kategorinya.
Kita akan memilih dua kolom yang telah dipilih dari dataset dan mengonversinya ke format tabel kontingensi yang diperlukan. Kita akan menggunakan paket yang umum digunakan bernama dplyr untuk operasi ini.
# Install and load the package
install.packages('dplyr')
library(dplyr)
# Select the columns of interest
selected_data <- dataset %>% select(Highest educational level, Anemia level)
# Create a contingency table for Highest educational level and Anemia level
contingency_table <- table(selected_data$Highest educational level, selected_data$Anemia level)
# View the contingency table
print(contingency_table)Tabel kontingensi yang dihasilkan terlihat seperti ini:
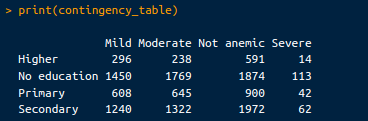
Tabel kontingensi. Gambar oleh Penulis.
Karena kita telah memiliki dataset dalam format tabel kontingensi yang diinginkan, kita dapat langsung menerapkan fungsi chisq.test(). Tidak perlu memuat pustaka apa pun untuk memanggil fungsi ini karena tersedia di paket dasar R.
# Perform chi-square test
chi_square_test <- chisq.test(contingency_table)
# View the results
print(chi_square_test)Keluaran akan terlihat seperti:
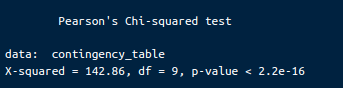
Hasil uji chi-square Pearson. Gambar oleh Penulis.
Selesai! Kita telah melakukan uji chi-square dalam dua langkah sederhana. Selanjutnya, bagaimana kita menafsirkan hasilnya?
Hipotesis menyatakan dengan jelas apa yang kita uji dan menetapkan kerangka untuk menafsirkan hasil. Secara sederhana, hipotesis yang kita rumuskan memberi kita pertanyaan yang jelas untuk dijawab, dan uji chi-square membantu menentukan apakah data yang diamati mendukung atau menolak klaim tersebut.
Saat melakukan uji chi-square, kita biasanya menetapkan dua hipotesis:
Menerapkan konsep hipotesis nol dan alternatif pada variabel yang kita uji dengan chi-square, kita dapat merumuskan hipotesis sebagai berikut:
Sekarang kita telah membentuk hipotesis, kita dapat menafsirkan hasil dalam konteks hipotesis tersebut:
Statistik Chi-Square (X-squared): Statistik uji chi-square adalah 142.86. Nilai ini mengukur ketidaksesuaian antara frekuensi teramati dalam tabel kontingensi dan frekuensi yang diharapkan jika tidak ada asosiasi antar variabel.
Derajat Kebebasan (df): Derajat kebebasan untuk uji ini adalah 9. Ini dihitung sebagai (jumlah baris - 1) * (jumlah kolom - 1).
Nilai-p: Nilai-p lebih kecil dari 2.2e-16, yang sangat kecil. Nilai-p ini menunjukkan probabilitas mengamati statistik chi-square setinggi, atau lebih ekstrem dari, 142.86 jika hipotesis nol benar.
Kita menolak hipotesis nol karena nilai-p jauh lebih kecil dari tingkat signifikansi umum (misalnya, 0,05; 0,01; atau bahkan 0,001). Ini memberikan bukti kuat adanya asosiasi yang signifikan antara tingkat pendidikan ibu dan status anemia anak. Dengan kata lain, hasil uji chi-square menunjukkan bahwa kemungkinan seorang anak mengalami anemia berhubungan signifikan dengan tingkat pendidikan ibunya.
Selain pengujian hipotesis, kita dapat mengambil nilai-nilai tertentu dari objek yang dikembalikan oleh fungsi chisq.test():
Ini merepresentasikan jumlah aktual anak dengan tingkat anemia berbeda pada setiap tingkat pendidikan ibu. Hitungan teramati dapat diambil dengan kode berikut:
# Observed counts
observed_counts <- chi_square_test$observed
print(observed_counts)Keluaran sebagai berikut:
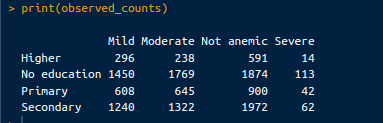
Hitungan teramati. Gambar oleh Penulis.
Hitungan ini dihitung dengan asumsi tidak ada asosiasi antara tingkat pendidikan ibu dan status anemia anak. Hitungan yang diharapkan dapat diambil dengan kode berikut:
# Expected counts
expected_counts <- chi_square_test$expected
print(round(expected_counts, 2))Keluaran sebagai berikut:
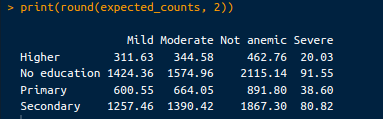
Hitungan yang diharapkan. Gambar oleh Penulis.
Residual ini membantu mengidentifikasi perbedaan terbesar antara hitungan teramati dan yang diharapkan, menunjukkan sel mana yang paling banyak berkontribusi pada statistik chi-square. Residual Pearson dapat diambil dengan kode berikut:
# Pearson residuals
pearson_residuals <- chi_square_test$residuals
print(round(pearson_residuals, 2))Keluaran sebagai berikut:
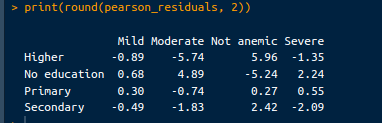
Keluaran residual. Gambar oleh Penulis.
Mari coba memahami apa arti angka residual ini:
Residual Positif: Residual positif menunjukkan bahwa hitungan teramati lebih tinggi daripada yang diharapkan. Misalnya, residual 5.96 untuk "Not anemic" pada kelompok pendidikan "Higher" berarti terdapat jauh lebih banyak anak yang tidak anemia daripada yang diharapkan di antara ibu dengan pendidikan lebih tinggi.
Residual Negatif: Residual negatif menunjukkan bahwa hitungan teramati lebih rendah daripada yang diharapkan. Misalnya, residual -5.74 untuk anemia "Moderate" pada kelompok pendidikan "Higher" menunjukkan bahwa terdapat jauh lebih sedikit anak dengan anemia sedang daripada yang diharapkan di antara ibu dengan pendidikan lebih tinggi.
Residual Besar: Residual positif atau negatif yang besar menunjukkan deviasi yang signifikan dari yang diharapkan. Sel-sel ini memberikan kontribusi terbesar pada statistik chi-square. Misalnya, residual positif besar untuk “Not anemic” pada kelompok pendidikan “Higher” dan residual negatif besar untuk anemia “Moderate” pada kelompok yang sama menunjukkan deviasi kuat pada tingkat anemia anak berdasarkan tingkat pendidikan ibu.
Residual Kecil: Residual kecil (mendekati 0) menunjukkan bahwa hitungan teramati dekat dengan yang diharapkan, menandakan deviasi yang lebih lemah. Misalnya, residual untuk pendidikan “Primary” di berbagai tingkat anemia relatif lebih kecil, mengindikasikan bahwa hitungan teramati dan diharapkan lebih dekat untuk kelompok ini.
Berdasarkan nilai yang diekstrak di atas, kontribusi setiap sel terhadap statistik chi-square dapat dihitung dengan kode di bawah ini dan diubah menjadi persentase:
# Calculate contribution to chi-square statistic
contributions <- (observed_counts - expected_counts)^2 / expected_counts
# Calculate percentage contributions
total_chi_square <- chi_square_test$statistic
percentage_contributions <- 100 * contributions / total_chi_square
# Print percentage contributions
print("Percentage Contributions:")
print(round(percentage_contributions, 2))Keluaran yang akan kita lihat adalah sebagai berikut:
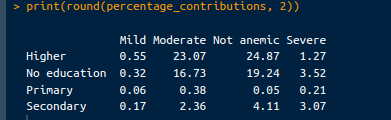 Persentase kontribusi. Gambar oleh Penulis.
Persentase kontribusi. Gambar oleh Penulis.
Kontribusi yang dihitung dapat divisualisasikan sebagai heatmap. Kita akan menggunakan paket bernama pheatmap untuk melakukannya, setelah memasang dan memuat paketnya.
# Install and load heatmap package
install.packages("pheatmap")
library(heatmap)
# Create heatmap for percentage contributions
pheatmap(percentage_contributions,
display_numbers = TRUE,
cluster_rows = FALSE,
cluster_cols = FALSE,
main = "Percentage Contribution to Chi-Square Statistic")Keluaran yang dihasilkan adalah sebagai berikut:
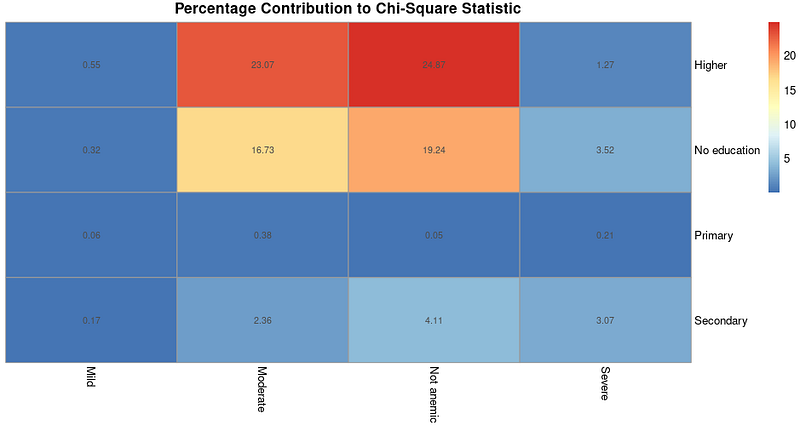 Heatmap persentase kontribusi terhadap statistik chi-square. Gambar oleh Penulis.
Heatmap persentase kontribusi terhadap statistik chi-square. Gambar oleh Penulis.
Heatmap seperti di atas dengan kontribusi dapat berguna jika Anda memilih untuk melakukan analisis lebih lanjut untuk memahami jenis asosiasi apa yang ada setelah kita mengetahui adanya asosiasi berdasarkan hasil uji chi-square.
Tutorial ini memperkenalkan Anda pada uji chi-square, jenis-jenisnya, dan asumsi yang mendasarinya. Kita juga mempelajari cara melakukan uji dan menafsirkan hasilnya di R beserta visualisasi tambahan menggunakan sebuah contoh.
Uji chi-square umum digunakan dalam pengujian hipotesis dan statistik secara umum. Pertimbangkan untuk mengambil salah satu kursus berikut untuk memperkuat pemahaman Anda tentang analitik data dan statistik menggunakan R:
Belajar bersama DataCamp
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
