
Kurs
Einführung in die Statistik in R
4 Std.
130.4K
Die Fähigkeit, Daten zu analysieren und zu interpretieren, ist für Datenexperten von unschätzbarem Wert. Es gibt viele verschiedene statistische Tests, die aus unterschiedlichen Gründen eingesetzt werden. Der Chi-Quadrat-Test ist ein allgemeiner Test, der in einem bestimmten Zusammenhang verwendet wird: wenn du Assoziationen zwischen kategorialen Variablen bestimmen musst. Das müssen Forscherinnen und Forscher häufig wissen. Deshalb ist der Chi-Quadrat-Test einer der am häufigsten verwendeten statistischen Tests.
In diesem Tutorium werden der Chi-Quadrat-Test, seine verschiedenen Typen und die Schritte zu seiner Durchführung mit der Programmiersprache R vorgestellt. Am Ende dieses Leitfadens wirst du mit dem Wissen und den Fähigkeiten ausgestattet sein, den Chi-Quadrat-Test sicher auf deine eigenen Daten anzuwenden und die Ergebnisse zu interpretieren.
Wenn du die Programmiersprache R noch nicht kennst, solltest du dir den einsteigerfreundlichen Lernpfad Data Analyst with R ansehen, um dich anhand von praktischen Beispielen zur Datenanalyse mit der Sprache vertraut zu machen.
Um einen Chi-Quadrat-Test in R durchzuführen, befolge diese Schritte:
Schritt 1: Bereite deine Daten in Form einer Kontingenztabelle auf.
Schritt 2: Verwende die Funktion chisq.test(), um den Chi-Quadrat-Test anzuwenden.
Hier ist ein kurzes Beispiel, das dies anhand von Beispieldaten demonstriert:
# Step 1: Creating a contingency table
data <- matrix(c(10, 20, 30, 40), nrow = 2)
# Step 2: Applying the chi-square test function
result <- chisq.test(data)
# Viewing the result
print(result)Dieses Codeschnipsel erstellt eine 2x2 Kontingenztabelle und führt den Chi-Quadrat-Test durch. Das Ergebnis zeigt die Teststatistik, die Freiheitsgrade und den p-Wert an.
Ein Chi-Quadrat-Test ist ein statistischer Test, der verwendet wird, um festzustellen, ob ein signifikanter Zusammenhang zwischen kategorialen Variablen besteht. Sie vergleicht die beobachteten Häufigkeiten des Auftretens in verschiedenen Kategorien mit den Häufigkeiten, die erwartet würden, wenn es keine Zusammenhänge zwischen den Variablen gäbe.
Es gibt zwei Haupttypen von Chi-Quadrat-Tests:
Um die Gültigkeit des Chi-Quadrat-Tests zu gewährleisten, müssen bestimmte Annahmen erfüllt sein:
Chi-Quadrat-Tests sind in Wissenschaft und Industrie weit verbreitet, insbesondere um Hypothesen über die Unabhängigkeit von kategorialen Variablen zu testen. Einige dieser praktischen Anwendungen sind:
Es ist erwähnenswert, dass dies nur einige der vielen Anwendungen in der Wissenschaft und in der Industrie sind und auf andere Bereiche und Felder ausgeweitet werden können.
Am besten lernst du die Durchführung von Chi-Quadrat-Tests anhand eines Beispiels, bei dem wir den Test auf einen Datensatz anwenden. Wir verwenden den Datensatz "Anemia Levels in Nigeria ", den du bei Kaggle herunterladen kannst. Der Datensatz stammt aus den Nigeria Demographic and Health Surveys (NDHS) 2018. Sie untersucht die Auswirkungen des Alters der Mütter und sozioökonomischer Faktoren auf die Anämie bei Kindern im Alter von 0-59 Monaten in den 36 nigerianischen Bundesstaaten und dem Federal Capital Territory.
Lass uns den Datensatz in R laden und ein Beispiel untersuchen, um die Daten besser zu verstehen. Um CSV-Dateien in R zu lesen, musst du ein Paket namens readr installieren.
# Load the necessary libraries
install.packages('readr')
library(readr)
# Load the dataset from the CSV file
dataset <- read_csv("children anemia.csv")
# Display the first few rows of the dataset
head(dataset)
# Rename a column
colnames(dataset)[colnames(dataset) == "Anemia level...8"] <- "Anemia level"
# Display the column names
colnames(dataset)Zusätzlich zu einem Beispiel des Datensatzes sehen wir unten die Spalten des Datensatzes:
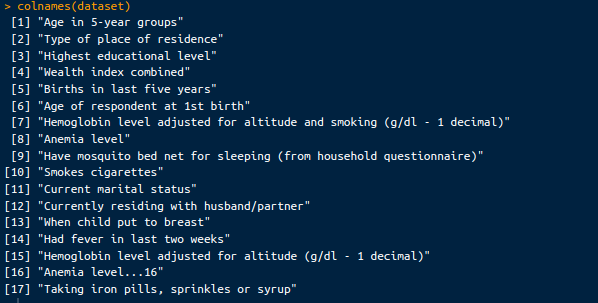 Spalten im Dataset. Bild vom Autor.
Spalten im Dataset. Bild vom Autor.
Wir wählen diese beiden Spalten aus, um herauszufinden, ob es eine Beziehung zwischen ihnen gibt.
Höchster Bildungsgrad: In dieser Spalte wird die Bildung der Mutter in die Kategorien "keine Bildung", "Grundschule", "Sekundarstufe" und "höhere Bildung" eingeteilt.
Grad der Anämie: In dieser Spalte wird der Grad der Anämie des Kindes angegeben, z. B. "mäßig", "schwer" oder "keine Anämie".
Eine Kontingenztabelle, die auch als Kreuztabelle oder Kreuztabelle bezeichnet wird, zeigt, wie die Werte von zwei oder mehr kategorialen Variablen auf ihre jeweiligen Kategorien verteilt sind.
Wir wählen die beiden ausgewählten Spalten aus dem Datensatz aus und konvertieren sie in das erforderliche Format der Kontingenztabelle. Für diese Vorgänge verwenden wir ein häufig verwendetes Paket namens dplyr.
# Install and load the package
install.packages('dplyr')
library(dplyr)
# Select the columns of interest
selected_data <- dataset %>% select(Highest educational level, Anemia level)
# Create a contingency table for Highest educational level and Anemia level
contingency_table <- table(selected_data$Highest educational level, selected_data$Anemia level)
# View the contingency table
print(contingency_table)Die resultierende Tabelle sieht wie folgt aus:
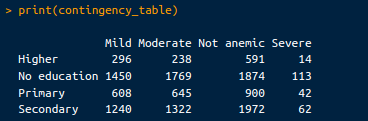
Kontingenztabelle. Bild vom Autor.
Da wir den Datensatz in dem gewünschten Format der Kontingenztabelle haben, können wir einfach die Funktion chisq.test() anwenden. Es müssen keine Bibliotheken geladen werden, um diese Funktion aufzurufen, da sie im Basispaket von R verfügbar ist.
# Perform chi-square test
chi_square_test <- chisq.test(contingency_table)
# View the results
print(chi_square_test)Die Ausgabe sieht dann so aus:
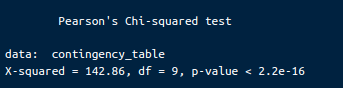
Ergebnisse des Chi-Quadrat-Tests von Pearson. Bild vom Autor.
Das war's! Wir haben den Chi-Quadrat-Test in zwei einfachen Schritten durchgeführt. Wie interpretieren wir nun die Ergebnisse?
Hypothesen geben klar an, was wir testen, und bilden einen Rahmen für die Interpretation der Ergebnisse. Einfacher ausgedrückt: Die von uns formulierte Hypothese gibt uns eine klare Frage vor, die wir beantworten müssen, und der Chi-Quadrat-Test hilft uns festzustellen, ob die beobachteten Daten die Behauptung unterstützen oder widerlegen.
Wenn wir einen Chi-Quadrat-Test durchführen, stellen wir normalerweise zwei Hypothesen auf:
Wenn wir die Konzepte der Null- und Alternativhypothese auf die Variablen anwenden, für die wir den Chi-Quadrat-Test durchgeführt haben, können wir die Hypothese wie folgt formulieren:
Nachdem wir nun eine Hypothese aufgestellt haben, können wir die Ergebnisse im Zusammenhang mit der Hypothese interpretieren:
Chi-Quadrat-Statistik (X-Quadrat): Die Chi-Quadrat-Teststatistik lautet 142.86. Dieser Wert misst die Diskrepanz zwischen den beobachteten Häufigkeiten in der Kontingenztabelle und den Häufigkeiten, die wir erwarten würden, wenn es keine Zusammenhänge zwischen den Variablen gäbe.
Freiheitsgrade (df): Der Freiheitsgrad für diesen Test ist 9. Dies wird berechnet als (Anzahl der Zeilen - 1) * (Anzahl der Spalten - 1).
P-Value: Der p-Wert ist kleiner als 2.2e-16, was extrem klein ist. Dieser p-Wert gibt die Wahrscheinlichkeit an, dass eine Chi-Quadrat-Statistik so extrem wie oder extremer als 142.86 ist, wenn die Nullhypothese wahr wäre.
Wir verwerfen die Nullhypothese, da der p-Wert viel kleiner ist als die üblichen Signifikanzniveaus (z. B. 0,05, 0,01 oder sogar 0,001). Dies ist ein deutlicher Hinweis auf einen signifikanten Zusammenhang zwischen dem Bildungsniveau der Mutter und dem Anämiestatus des Kindes. Mit anderen Worten: Die Ergebnisse des Chi-Quadrat-Tests deuten darauf hin, dass die Wahrscheinlichkeit, dass ein Kind an Anämie leidet, signifikant mit dem Bildungsstand der Mutter zusammenhängt.
Über die Hypothesentests hinaus können wir bestimmte Werte aus dem Objekt abrufen, das von der Funktion chisq.test() zurückgegeben wird:
Sie stellen die tatsächliche Anzahl der Kinder mit verschiedenen Anämiegraden je nach Bildungsniveau der Mutter dar. Die beobachteten Zahlen können mit dem folgenden Code abgerufen werden:
# Observed counts
observed_counts <- chi_square_test$observed
print(observed_counts)Die Ausgabe sieht folgendermaßen aus:
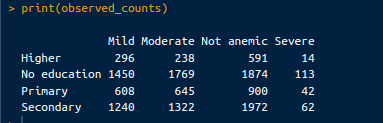
Beobachtete Zählungen. Bild vom Autor.
Diese Zahlen werden unter der Annahme berechnet, dass es keinen Zusammenhang zwischen dem Bildungsniveau der Mutter und dem Anämiestatus des Kindes gibt. Die erwarteten Zählerstände können über den folgenden Code abgerufen werden:
# Expected counts
expected_counts <- chi_square_test$expected
print(round(expected_counts, 2))Die Ausgabe sieht folgendermaßen aus:
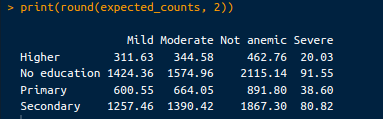
Erwartete Zahlen. Bild vom Autor.
Diese Residuen helfen dabei, die größten Diskrepanzen zwischen den beobachteten und den erwarteten Zählungen zu identifizieren und zeigen an, welche Zellen am meisten zur Chi-Quadrat-Statistik beitragen. Die Pearson-Residuen können mit folgendem Code abgerufen werden:
# Pearson residuals
pearson_residuals <- chi_square_test$residuals
print(round(pearson_residuals, 2))Die Ausgabe sieht folgendermaßen aus:
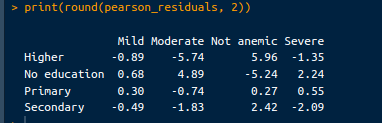
Residuale Ausgabe. Bild vom Autor.
Versuchen wir zu verstehen, was diese restlichen Zahlen bedeuten:
Positive Residuen: Positive Residuen zeigen an, dass die beobachtete Anzahl höher ist als erwartet. Ein Restwert von 5.96 für "Nicht anämisch" in der Gruppe "Höhere Bildung" bedeutet zum Beispiel, dass es unter den Müttern mit höherer Bildung deutlich mehr Kinder gibt, die nicht anämisch sind als erwartet.
Negative Residuen: Negative Residuen zeigen an, dass die beobachtete Anzahl niedriger ist als erwartet. Zum Beispiel deutet ein Restwert von -5.74 für "mäßige" Anämie in der Gruppe mit "höherer" Bildung darauf hin, dass es unter Müttern mit höherer Bildung deutlich weniger mäßig anämische Kinder gibt als erwartet.
Große Residuen: Große positive oder negative Residuen deuten auf eine erhebliche Abweichung vom Erwarteten hin. Diese Zellen tragen am meisten zur Chi-Quadrat-Statistik bei. Der große positive Restwert für "Nicht anämisch" in der Gruppe "Höhere Bildung" und der große negative Restwert für "Mäßige" Anämie in derselben Gruppe weisen beispielsweise auf starke Abweichungen bei den Anämiewerten der Kinder in Abhängigkeit vom Bildungsniveau der Mutter hin.
Kleine Restbeträge: Kleine Residuen (nahe 0) deuten darauf hin, dass die beobachteten Zählungen nahe an den erwarteten Zählungen liegen, was auf eine geringere Abweichung hindeutet. Zum Beispiel sind die Residuen für die "Grundschulbildung" über die Anämiestufen hinweg relativ kleiner, was darauf hindeutet, dass die beobachteten und erwarteten Werte für diese Gruppe näher beieinander liegen.
Ausgehend von den oben extrahierten Werten kann der Beitrag jeder Zelle zur Chi-Quadrat-Statistik mit dem folgenden Code berechnet und in einen Prozentsatz umgewandelt werden:
# Calculate contribution to chi-square statistic
contributions <- (observed_counts - expected_counts)^2 / expected_counts
# Calculate percentage contributions
total_chi_square <- chi_square_test$statistic
percentage_contributions <- 100 * contributions / total_chi_square
# Print percentage contributions
print("Percentage Contributions:")
print(round(percentage_contributions, 2))Die Ausgabe, die wir sehen werden, ist wie folgt:
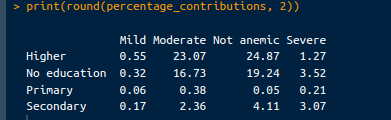 Prozentuale Beiträge. Bild vom Autor.
Prozentuale Beiträge. Bild vom Autor.
Der berechnete Beitrag kann als Heatmap visualisiert werden. Dazu verwenden wir ein Paket namens pheatmap, nachdem wir das Paket installiert und geladen haben.
# Install and load heatmap package
install.packages("pheatmap")
library(heatmap)
# Create heatmap for percentage contributions
pheatmap(percentage_contributions,
display_numbers = TRUE,
cluster_rows = FALSE,
cluster_cols = FALSE,
main = "Percentage Contribution to Chi-Square Statistic")Die Ausgabe sieht folgendermaßen aus:
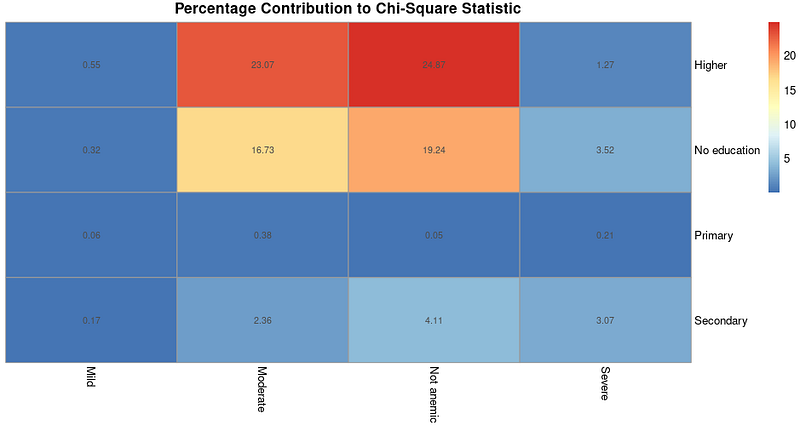 Prozentualer Beitrag zur Chi-Quadrat-Statistik Heatmap. Bild vom Autor.
Prozentualer Beitrag zur Chi-Quadrat-Statistik Heatmap. Bild vom Autor.
Eine Heatmap wie die obige mit den Beiträgen kann nützlich sein, wenn du weitere Analysen durchführst, um zu verstehen, welche Art von Assoziationen bestehen, nachdem wir anhand der Ergebnisse des Chi-Quadrat-Tests herausgefunden haben, dass es Assoziationen gibt.
In diesem Lernprogramm hast du den Chi-Quadrat-Test, seine verschiedenen Arten und die zugrunde liegenden Annahmen kennengelernt. Außerdem lernten wir, wie man den Test durchführt und die Ergebnisse in R mit zusätzlicher Visualisierung anhand eines Beispiels interpretiert.
Chi-Quadrat-Tests werden häufig bei Hypothesentests und allgemein in der Statistik verwendet. Ziehe in Erwägung, einen dieser Kurse zu belegen, um dein Verständnis von Datenanalyse und Statistik mit R zu vertiefen:
Lerne, wie du aus KI und LLMs geschäftlichen Nutzen ziehen kannst.
Lernen mit DataCamp
Kurs
Kurs
Kurs
Tutorial
Allan Ouko
Tutorial
Laiba Siddiqui
Tutorial
Allan Ouko
Tutorial
DataCamp Team
Tutorial
Matt Crabtree
Tutorial
Aditya Sharma

