
Corso
Introduzione alla statistica in R
4 h
131.6K
Capire come analizzare e interpretare i dati è una competenza preziosissima per i professionisti dei dati. Esistono molti test statistici diversi, usati per motivi differenti. Il test chi-quadro è un test comune utilizzato in un contesto specifico: quando devi determinare le associazioni tra variabili categoriche. È un’esigenza frequente nella ricerca, motivo per cui il test chi-quadro è uno dei test statistici più usati.
Questo tutorial introduce il test chi-quadro, le sue diverse tipologie e i passaggi per eseguirlo usando il linguaggio R. Al termine della guida avrai le conoscenze e le abilità per applicare con sicurezza il test chi-quadro ai tuoi dati e interpretarne i risultati.
Se sei alle prime armi con il linguaggio R, potresti voler dare un’occhiata al percorso professionale per principianti Data Analyst with R per familiarizzare con il linguaggio attraverso esempi pratici di analisi dei dati.
Per eseguire un test chi-quadro in R, segui questi passaggi:
Passaggio 1: prepara i dati in formato di tabella di contingenza.
Passaggio 2: usa la funzione chisq.test() per applicare il test chi-quadro.
Ecco un esempio rapido che lo dimostra usando dati di esempio:
# Step 1: Creating a contingency table
data <- matrix(c(10, 20, 30, 40), nrow = 2)
# Step 2: Applying the chi-square test function
result <- chisq.test(data)
# Viewing the result
print(result)Questo snippet crea una tabella di contingenza 2x2 ed esegue il test chi-quadro. Il risultato mostrerà la statistica del test, i gradi di libertà e il p-value.
Un test chi-quadro è un test statistico usato per determinare se esiste un’associazione significativa tra variabili categoriche. Confronta le frequenze osservate di occorrenza nelle diverse categorie con le frequenze attese se non ci fosse alcuna associazione tra le variabili.
Esistono due principali tipi di test chi-quadro:
Per garantire la validità del test chi-quadro, devono essere soddisfatte alcune assunzioni:
I test chi-quadro sono ampiamente usati in ambito accademico e industriale, soprattutto per testare ipotesi sull’indipendenza di variabili categoriche. Alcune applicazioni pratiche sono:
Vale la pena notare che queste sono solo alcune delle molte applicazioni in ambito accademico e industriale e possono estendersi ad altri domini e settori.
Il modo migliore per imparare a eseguire test chi-quadro è tramite un esempio in cui applichiamo il test a un dataset. Useremo il dataset Anemia Levels in Nigeria, scaricabile da Kaggle. Il dataset proviene dalle Nigeria Demographic and Health Surveys (NDHS) del 2018. Esplora l’impatto dell’età delle madri e dei fattori socioeconomici sui livelli di anemia tra i bambini di 0–59 mesi nei 36 stati della Nigeria e nel Territorio della Capitale Federale.
Carichiamo il dataset in R ed esaminiamone un campione per capirlo meglio. Per leggere file CSV in R, dovrai installare un pacchetto chiamato readr.
# Load the necessary libraries
install.packages('readr')
library(readr)
# Load the dataset from the CSV file
dataset <- read_csv("children anemia.csv")
# Display the first few rows of the dataset
head(dataset)
# Rename a column
colnames(dataset)[colnames(dataset) == "Anemia level...8"] <- "Anemia level"
# Display the column names
colnames(dataset)Oltre a un campione del dataset, qui sotto vedremo anche le colonne del dataset:
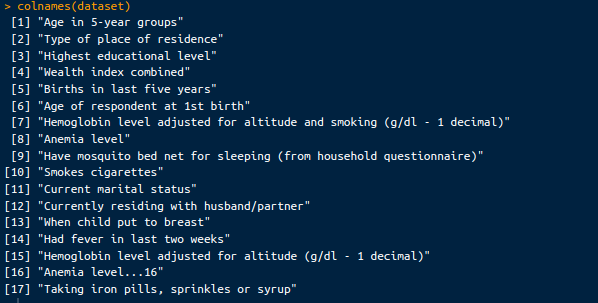 Colonne nel dataset. Immagine dell’autore.
Colonne nel dataset. Immagine dell’autore.
Tra queste, sceglieremo due colonne per valutare se esiste una relazione tra loro.
Highest educational level: questa colonna classifica l’istruzione della madre in livelli “No education”, “Primary”, “Secondary” e “Higher”.
Anemia level: questa colonna indica il livello di anemia del bambino, ad esempio “Moderate”, “Severe” o “No Anemia”.
Una tabella di contingenza, nota anche come tabella a doppia entrata o cross-tab, mostra come i valori di due o più variabili categoriche sono distribuiti nelle rispettive categorie.
Selezioneremo le due colonne scelte dal dataset e le convertiremo nel formato di tabella di contingenza richiesto. Useremo un pacchetto molto diffuso chiamato dplyr per queste operazioni.
# Install and load the package
install.packages('dplyr')
library(dplyr)
# Select the columns of interest
selected_data <- dataset %>% select(Highest educational level, Anemia level)
# Create a contingency table for Highest educational level and Anemia level
contingency_table <- table(selected_data$Highest educational level, selected_data$Anemia level)
# View the contingency table
print(contingency_table)La tabella di contingenza risultante è la seguente:
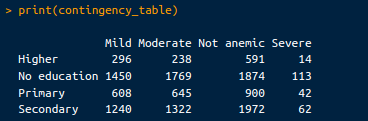
Tabella di contingenza. Immagine dell’autore.
Dato che abbiamo il dataset nel formato di tabella di contingenza desiderato, possiamo semplicemente applicare la funzione chisq.test(). Non è necessario caricare librerie per chiamare questa funzione, perché è disponibile nel pacchetto base di R.
# Perform chi-square test
chi_square_test <- chisq.test(contingency_table)
# View the results
print(chi_square_test)L’output sarà simile a questo:
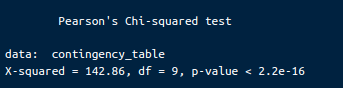
Risultati del test chi-quadro di Pearson. Immagine dell’autore.
Tutto qui! Abbiamo eseguito il test chi-quadro in due semplici passaggi. E ora, come interpretiamo i risultati?
Le ipotesi indicano chiaramente cosa stiamo testando e definiscono un quadro per interpretare i risultati. In parole semplici, l’ipotesi che formuliamo ci dà una domanda chiara a cui rispondere, e il test chi-quadro ci aiuta a determinare se i dati osservati supportano o smentiscono l’affermazione.
Quando eseguiamo un test chi-quadro, in genere formuliamo due ipotesi:
Applicando i concetti di ipotesi nulla e alternativa alle variabili su cui abbiamo eseguito il test chi-quadro, possiamo formulare così l’ipotesi:
Ora che abbiamo formulato l’ipotesi, possiamo interpretare i risultati nel suo contesto:
Statistica chi-quadro (X-squared): la statistica del test chi-quadro è 142.86. Questo valore misura la discrepanza tra le frequenze osservate nella tabella di contingenza e le frequenze attese se non ci fosse associazione tra le variabili.
Gradi di libertà (df): i gradi di libertà per questo test sono 9. Si calcolano come (numero di righe - 1) * (numero di colonne - 1).
P-value: il p-value è inferiore a 2.2e-16, estremamente piccolo. Questo p-value indica la probabilità di osservare una statistica chi-quadro pari a, o più estrema di, 142.86 se l’ipotesi nulla fosse vera.
Rifiutiamo l’ipotesi nulla poiché il p-value è molto più piccolo dei livelli di significatività comuni (ad es., 0,05, 0,01 o anche 0,001). Questo fornisce una forte evidenza di un’associazione significativa tra il livello di istruzione della madre e lo stato di anemia del bambino. In altre parole, i risultati del test chi-quadro indicano che la probabilità che un bambino sia anemico è significativamente associata al livello di istruzione della madre.
Oltre al test d’ipotesi, possiamo recuperare alcuni valori dall’oggetto restituito dalla funzione chisq.test():
Rappresentano i conteggi effettivi di bambini con diversi livelli di anemia per ciascun livello di istruzione della madre. I conteggi osservati possono essere recuperati con il seguente codice:
# Observed counts
observed_counts <- chi_square_test$observed
print(observed_counts)L’output è il seguente:
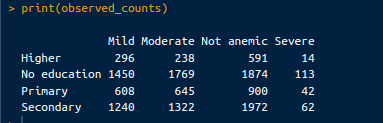
Conteggi osservati. Immagine dell’autore.
Questi conteggi sono calcolati nell’ipotesi che non vi sia associazione tra il livello di istruzione della madre e lo stato di anemia del bambino. I conteggi attesi possono essere recuperati con il seguente codice:
# Expected counts
expected_counts <- chi_square_test$expected
print(round(expected_counts, 2))L’output è il seguente:
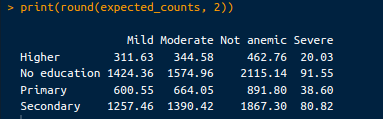
Conteggi attesi. Immagine dell’autore.
Questi residui aiutano a identificare le maggiori discrepanze tra conteggi osservati e attesi, indicando quali celle contribuiscono maggiormente alla statistica chi-quadro. I residui di Pearson possono essere recuperati con il seguente codice:
# Pearson residuals
pearson_residuals <- chi_square_test$residuals
print(round(pearson_residuals, 2))L’output è il seguente:
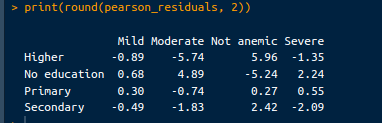
Output dei residui. Immagine dell’autore.
Cerchiamo di capire cosa significano questi numeri dei residui:
Residui positivi: indicano che il conteggio osservato è superiore a quello atteso. Ad esempio, un residuo di 5.96 per "Not anemic" nel gruppo con istruzione "Higher" significa che ci sono significativamente più bambini non anemici del previsto tra le madri con istruzione più alta.
Residui negativi: indicano che il conteggio osservato è inferiore a quello atteso. Per esempio, un residuo di -5.74 per l’anemia "Moderate" nel gruppo con istruzione "Higher" suggerisce che ci sono significativamente meno bambini moderatamente anemici del previsto tra le madri con istruzione più alta.
Residui grandi: residui positivi o negativi di grande entità suggeriscono una deviazione significativa da quanto atteso. Queste celle contribuiscono maggiormente alla statistica chi-quadro. Ad esempio, il grande residuo positivo per “Not anemic” nel gruppo “Higher” e il grande residuo negativo per l’anemia “Moderate” nello stesso gruppo indicano forti deviazioni nei livelli di anemia dei bambini in base al livello di istruzione della madre.
Residui piccoli: residui piccoli (vicini a 0) suggeriscono che i conteggi osservati sono vicini a quelli attesi, indicando una deviazione più debole. Ad esempio, i residui per l’istruzione “Primary” sui livelli di anemia sono relativamente più piccoli, indicando che i conteggi osservati e attesi sono più vicini per questo gruppo.
Sulla base dei valori estratti sopra, il contributo di ciascuna cella alla statistica chi-quadro può essere calcolato con il codice seguente e convertito in percentuale:
# Calculate contribution to chi-square statistic
contributions <- (observed_counts - expected_counts)^2 / expected_counts
# Calculate percentage contributions
total_chi_square <- chi_square_test$statistic
percentage_contributions <- 100 * contributions / total_chi_square
# Print percentage contributions
print("Percentage Contributions:")
print(round(percentage_contributions, 2))L’output che vedremo è il seguente:
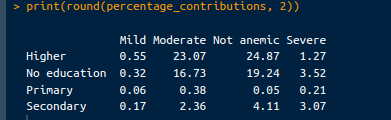 Contributi percentuali. Immagine dell’autore.
Contributi percentuali. Immagine dell’autore.
Il contributo calcolato può essere visualizzato come una heatmap. Useremo un pacchetto chiamato pheatmap per farlo, dopo aver installato e caricato il pacchetto.
# Install and load heatmap package
install.packages("pheatmap")
library(heatmap)
# Create heatmap for percentage contributions
pheatmap(percentage_contributions,
display_numbers = TRUE,
cluster_rows = FALSE,
cluster_cols = FALSE,
main = "Percentage Contribution to Chi-Square Statistic")L’output risultante è il seguente:
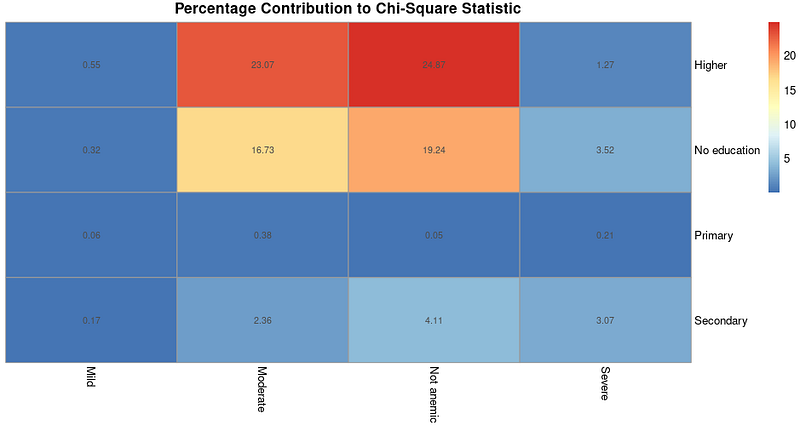 Heatmap del contributo percentuale alla statistica chi-quadro. Immagine dell’autore.
Heatmap del contributo percentuale alla statistica chi-quadro. Immagine dell’autore.
Una heatmap come quella sopra, con i contributi, può essere utile se decidi di svolgere ulteriori analisi per capire che tipo di associazioni esistono dopo aver verificato, con i risultati del test chi-quadro, che un’associazione effettivamente c’è.
Questo tutorial ti ha introdotto al test chi-quadro, alle sue diverse tipologie e alle assunzioni alla base. Abbiamo inoltre imparato come eseguire il test e interpretarne i risultati in R con un esempio corredato di visualizzazioni.
I test chi-quadro sono comunemente usati nei test d’ipotesi e, in generale, in statistica. Prendi in considerazione uno di questi corsi per consolidare la tua comprensione di analytics e statistica in R:
Impara con DataCamp
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

