
Courses
Nhập môn Thống kê với R
4 giờ
131.6K
Hiểu cách phân tích và diễn giải dữ liệu là một kỹ năng vô giá đối với các chuyên gia dữ liệu. Có nhiều phép kiểm định thống kê khác nhau dùng cho các mục đích khác nhau. Kiểm định chi-square là một phép kiểm định phổ biến dùng trong ngữ cảnh cụ thể: khi bạn cần xác định mối liên hệ giữa các biến phân loại. Đây là điều các nhà nghiên cứu thường phải biết, vì vậy kiểm định chi-square là một trong những phép kiểm định thống kê được sử dụng rộng rãi nhất.
Hướng dẫn này giới thiệu về kiểm định chi-square, các loại kiểm định và các bước thực hiện bằng ngôn ngữ R. Cuối bài, bạn sẽ có kiến thức và kỹ năng để tự tin áp dụng kiểm định chi-square cho dữ liệu của mình và diễn giải kết quả.
Nếu bạn mới làm quen với ngôn ngữ R, bạn có thể xem lộ trình nghề nghiệp thân thiện với người mới bắt đầu Data Analyst with R để làm quen với ngôn ngữ này thông qua các ví dụ phân tích dữ liệu thực hành.
Để thực hiện kiểm định chi-square trong R, hãy làm theo các bước sau:
Bước 1: Chuẩn bị dữ liệu ở định dạng bảng chéo (contingency table).
Bước 2: Sử dụng hàm chisq.test() để áp dụng kiểm định chi-square.
Dưới đây là ví dụ nhanh minh họa bằng dữ liệu mẫu:
# Step 1: Creating a contingency table
data <- matrix(c(10, 20, 30, 40), nrow = 2)
# Step 2: Applying the chi-square test function
result <- chisq.test(data)
# Viewing the result
print(result)Đoạn mã này tạo một bảng chéo 2x2 và thực hiện kiểm định chi-square. Kết quả sẽ hiển thị thống kê kiểm định, bậc tự do và p-value.
Kiểm định chi-square là một phép kiểm định thống kê dùng để xác định liệu có mối liên hệ có ý nghĩa giữa các biến phân loại hay không. Nó so sánh tần suất quan sát được ở các nhóm khác nhau với tần suất kỳ vọng nếu không có mối liên hệ giữa các biến.
Có hai loại kiểm định chi-square chính:
Để đảm bảo tính hợp lệ của kiểm định chi-square, cần đáp ứng một số giả định:
Kiểm định chi-square được sử dụng rộng rãi trong học thuật và công nghiệp, đặc biệt để kiểm định giả thuyết về tính độc lập của các biến phân loại. Một số ứng dụng thực tiễn gồm:
Lưu ý rằng đây chỉ là một số ứng dụng trong học thuật và công nghiệp; chúng còn có thể mở rộng sang nhiều lĩnh vực khác.
Cách tốt nhất để học cách thực hiện kiểm định chi-square là qua một ví dụ áp dụng kiểm định lên một tập dữ liệu. Chúng ta sẽ dùng bộ dữ liệu Anemia Levels in Nigeria, có thể tải từ Kaggle. Bộ dữ liệu đến từ Khảo sát Nhân khẩu và Sức khỏe Nigeria (NDHS) năm 2018. Nó khám phá tác động của độ tuổi của mẹ và các yếu tố kinh tế - xã hội đến mức độ thiếu máu của trẻ em từ 0–59 tháng tại 36 bang của Nigeria và Lãnh thổ Thủ đô Liên bang.
Hãy nạp bộ dữ liệu vào R và xem một mẫu để hiểu rõ hơn dữ liệu. Để đọc tệp CSV trong R, bạn cần cài đặt gói readr.
# Load the necessary libraries
install.packages('readr')
library(readr)
# Load the dataset from the CSV file
dataset <- read_csv("children anemia.csv")
# Display the first few rows of the dataset
head(dataset)
# Rename a column
colnames(dataset)[colnames(dataset) == "Anemia level...8"] <- "Anemia level"
# Display the column names
colnames(dataset)Ngoài mẫu dữ liệu, chúng ta sẽ thấy các cột của bộ dữ liệu như dưới đây:
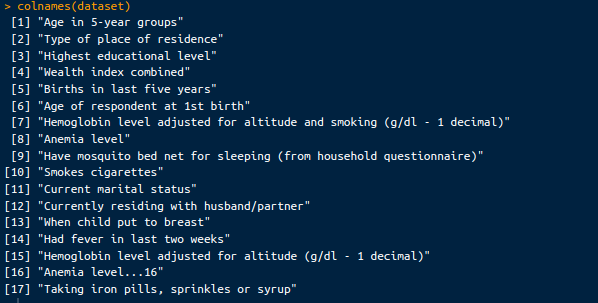 Các cột trong bộ dữ liệu. Ảnh: Tác giả.
Các cột trong bộ dữ liệu. Ảnh: Tác giả.
Trong số đó, chúng ta sẽ chọn hai cột sau để đánh giá liệu có mối quan hệ giữa chúng hay không.
Trình độ học vấn cao nhất: Cột này phân loại trình độ học vấn của người mẹ thành “Không học”, “Tiểu học”, “Trung học” và “Cao hơn”.
Mức độ thiếu máu: Cột này cho biết mức độ thiếu máu của trẻ, như “Vừa”, “Nặng” hoặc “Không thiếu máu”.
Bảng chéo, còn gọi là bảng phân phối chéo (cross-tab), cho thấy cách các giá trị của hai hoặc nhiều biến phân loại được phân bổ qua các nhóm tương ứng.
Chúng ta sẽ chọn hai cột đã chọn từ bộ dữ liệu và chuyển chúng về định dạng bảng chéo cần thiết. Ta sẽ dùng gói phổ biến dplyr cho các thao tác này.
# Install and load the package
install.packages('dplyr')
library(dplyr)
# Select the columns of interest
selected_data <- dataset %>% select(Highest educational level, Anemia level)
# Create a contingency table for Highest educational level and Anemia level
contingency_table <- table(selected_data$Highest educational level, selected_data$Anemia level)
# View the contingency table
print(contingency_table)Bảng chéo thu được như sau:
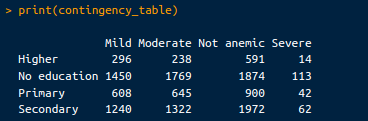
Bảng chéo. Ảnh: Tác giả.
Vì chúng ta đã có dữ liệu ở định dạng bảng chéo như mong muốn, ta chỉ cần áp dụng hàm chisq.test(). Không cần nạp thư viện vì hàm này có sẵn trong gói base của R.
# Perform chi-square test
chi_square_test <- chisq.test(contingency_table)
# View the results
print(chi_square_test)Đầu ra sẽ trông như sau:
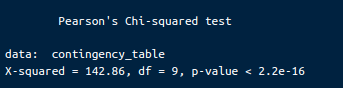
Kết quả kiểm định chi-square của Pearson. Ảnh: Tác giả.
Vậy là xong! Chúng ta đã thực hiện kiểm định chi-square trong hai bước đơn giản. Tiếp theo, diễn giải kết quả như thế nào?
Giả thuyết nêu rõ điều chúng ta kiểm định và thiết lập khung để diễn giải kết quả. Nói đơn giản, giả thuyết đưa ra câu hỏi rõ ràng cần trả lời, và kiểm định chi-square giúp xác định liệu dữ liệu quan sát ủng hộ hay bác bỏ nhận định đó.
Khi thực hiện kiểm định chi-square, ta thường thiết lập hai giả thuyết:
Áp dụng khái niệm giả thuyết không và giả thuyết đối cho các biến ta đã kiểm định chi-square, có thể phát biểu giả thuyết như sau:
Sau khi đã xây dựng giả thuyết, ta có thể diễn giải kết quả trong bối cảnh giả thuyết:
Thống kê Chi-Square (X-squared): Giá trị thống kê chi-square là 142.86. Giá trị này đo độ chênh lệch giữa tần suất quan sát trong bảng chéo và tần suất kỳ vọng nếu không có mối liên hệ giữa các biến.
Bậc tự do (df): Bậc tự do của kiểm định này là 9. Công thức tính: (số hàng - 1) * (số cột - 1).
P-value: P-value nhỏ hơn 2.2e-16, cực kỳ nhỏ. P-value này biểu thị xác suất quan sát được một thống kê chi-square lớn như, hoặc lớn hơn, 142.86 nếu giả thuyết không là đúng.
Chúng ta bác bỏ giả thuyết không vì p-value nhỏ hơn rất nhiều so với các mức ý nghĩa thông dụng (ví dụ 0,05; 0,01; thậm chí 0,001). Điều này cung cấp bằng chứng mạnh mẽ về mối liên hệ có ý nghĩa giữa trình độ học vấn của mẹ và tình trạng thiếu máu của trẻ. Nói cách khác, kết quả kiểm định chi-square cho thấy khả năng trẻ bị thiếu máu có liên quan đáng kể đến trình độ học vấn của mẹ.
Ngoài việc kiểm định giả thuyết, chúng ta có thể truy xuất một số giá trị từ đối tượng trả về bởi hàm chisq.test():
Đây là số đếm thực tế của trẻ với các mức độ thiếu máu khác nhau theo từng trình độ học vấn của mẹ. Có thể truy xuất số đếm quan sát bằng mã sau:
# Observed counts
observed_counts <- chi_square_test$observed
print(observed_counts)Đầu ra như sau:
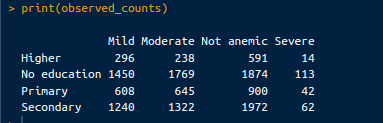
Số đếm quan sát. Ảnh: Tác giả.
Những số đếm này được tính dưới giả định rằng không có mối liên hệ giữa trình độ học vấn của mẹ và tình trạng thiếu máu của trẻ. Có thể truy xuất số đếm kỳ vọng bằng mã sau:
# Expected counts
expected_counts <- chi_square_test$expected
print(round(expected_counts, 2))Đầu ra như sau:
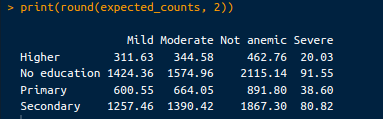
Số đếm kỳ vọng. Ảnh: Tác giả.
Các phần dư này giúp xác định những chênh lệch lớn nhất giữa số đếm quan sát và kỳ vọng, cho biết ô nào đóng góp nhiều nhất vào thống kê chi-square. Có thể truy xuất phần dư Pearson bằng mã sau:
# Pearson residuals
pearson_residuals <- chi_square_test$residuals
print(round(pearson_residuals, 2))Đầu ra như sau:
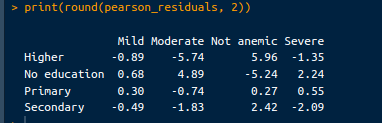
Đầu ra phần dư. Ảnh: Tác giả.
Hãy cùng hiểu ý nghĩa của các con số phần dư này:
Phần dư dương: Cho biết số đếm quan sát lớn hơn kỳ vọng. Ví dụ, phần dư 5.96 cho "Không thiếu máu" trong nhóm học vấn "Cao hơn" nghĩa là có nhiều trẻ không thiếu máu hơn kỳ vọng đáng kể trong số các bà mẹ có học vấn cao hơn.
Phần dư âm: Cho biết số đếm quan sát thấp hơn kỳ vọng. Chẳng hạn, phần dư -5.74 cho thiếu máu "Vừa" trong nhóm học vấn "Cao hơn" gợi ý có ít trẻ thiếu máu mức vừa hơn kỳ vọng đáng kể trong nhóm các bà mẹ có học vấn cao hơn.
Phần dư lớn: Phần dư dương hoặc âm lớn cho thấy độ lệch đáng kể so với kỳ vọng. Các ô này đóng góp nhiều nhất vào thống kê chi-square. Ví dụ, phần dư dương lớn cho “Không thiếu máu” ở nhóm “Cao hơn” và phần dư âm lớn cho thiếu máu “Vừa” trong cùng nhóm cho thấy sự lệch mạnh về mức thiếu máu của trẻ dựa trên trình độ học vấn của mẹ.
Phần dư nhỏ: Phần dư gần 0 cho thấy số đếm quan sát gần với kỳ vọng, nghĩa là độ lệch yếu hơn. Ví dụ, phần dư cho nhóm “Tiểu học” qua các mức thiếu máu tương đối nhỏ, cho thấy số đếm quan sát và kỳ vọng gần nhau hơn cho nhóm này.
Dựa trên các giá trị đã trích xuất ở trên, đóng góp của mỗi ô vào thống kê chi-square có thể được tính bằng đoạn mã dưới đây và chuyển thành phần trăm:
# Calculate contribution to chi-square statistic
contributions <- (observed_counts - expected_counts)^2 / expected_counts
# Calculate percentage contributions
total_chi_square <- chi_square_test$statistic
percentage_contributions <- 100 * contributions / total_chi_square
# Print percentage contributions
print("Percentage Contributions:")
print(round(percentage_contributions, 2))Đầu ra sẽ như sau:
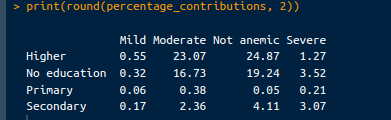 Tỷ lệ đóng góp. Ảnh: Tác giả.
Tỷ lệ đóng góp. Ảnh: Tác giả.
Có thể trực quan hóa tỷ lệ đóng góp dưới dạng heatmap. Chúng ta sẽ dùng gói pheatmap để thực hiện, sau khi cài đặt và nạp gói.
# Install and load heatmap package
install.packages("pheatmap")
library(heatmap)
# Create heatmap for percentage contributions
pheatmap(percentage_contributions,
display_numbers = TRUE,
cluster_rows = FALSE,
cluster_cols = FALSE,
main = "Percentage Contribution to Chi-Square Statistic")Đầu ra thu được như sau:
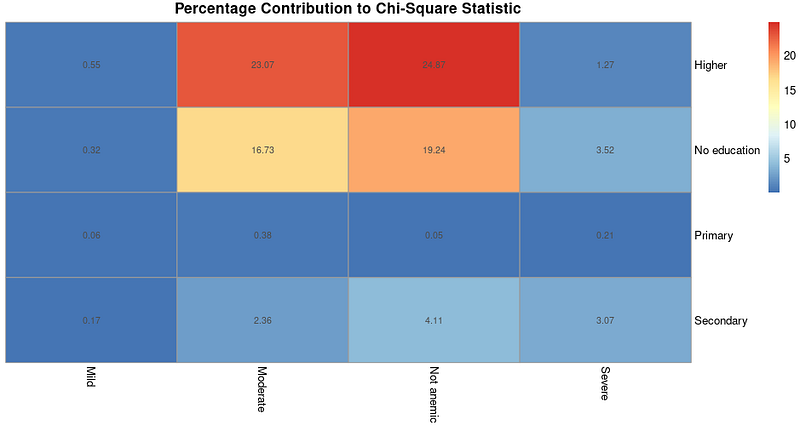 Heatmap tỷ lệ đóng góp vào thống kê chi-square. Ảnh: Tác giả.
Heatmap tỷ lệ đóng góp vào thống kê chi-square. Ảnh: Tác giả.
Một heatmap như trên với các tỷ lệ đóng góp có thể hữu ích nếu bạn muốn phân tích sâu hơn để hiểu loại mối liên hệ nào tồn tại sau khi ta phát hiện có mối liên hệ dựa trên kết quả kiểm định chi-square.
Hướng dẫn này đã giới thiệu bạn về kiểm định chi-square, các loại kiểm định và các giả định cơ bản. Chúng ta cũng đã học cách thực hiện kiểm định và diễn giải kết quả trong R, kèm theo trực quan hóa qua ví dụ.
Kiểm định chi-square được sử dụng phổ biến trong kiểm định giả thuyết và nói chung trong thống kê. Hãy cân nhắc tham gia một trong các khóa học sau để củng cố hiểu biết về phân tích dữ liệu và thống kê bằng R:
Học cùng DataCamp
Courses
Courses
Courses