
Cursus
Inleiding tot statistiek in R
4 Hr
131.6K
Begrijpen hoe je data analyseert en interpreteert is een onmisbare vaardigheid voor dataprofessionals. Er zijn veel verschillende statistische toetsen die om uiteenlopende redenen worden gebruikt. De chi-kwadraattoets is een veelgebruikte toets in een specifieke context: wanneer je associaties tussen categorische variabelen wilt vaststellen. Dit is iets wat onderzoekers vaak moeten weten, en daarom is de chi-kwadraattoets een van de meest gebruikte statistische toetsen.
Deze tutorial introduceert de chi-kwadraattoets, de verschillende types en de stappen om hem uit te voeren met de programmeertaal R. Aan het einde van deze gids heb je de kennis en vaardigheden om de chi-kwadraattoets vol vertrouwen op je eigen data toe te passen en de resultaten te interpreteren.
Als je nieuw bent met de programmeertaal R, bekijk dan de beginnersvriendelijke carrièreroute Data Analyst with R om de taal te leren aan de hand van praktische data-analysevoorbeelden.
Volg deze stappen om een chi-kwadraattoets in R uit te voeren:
Stap 1: Bereid je data voor in de vorm van een kruistabel (contingentietabel).
Stap 2: Gebruik de functie chisq.test() om de chi-kwadraattoets toe te passen.
Hier is een snel voorbeeld met voorbeelddata:
# Step 1: Creating a contingency table
data <- matrix(c(10, 20, 30, 40), nrow = 2)
# Step 2: Applying the chi-square test function
result <- chisq.test(data)
# Viewing the result
print(result)Deze code maakt een 2x2-kruistabel en voert de chi-kwadraattoets uit. Het resultaat toont de toetsstatistiek, vrijheidsgraden en p-waarde.
Een chi-kwadraattoets is een statistische toets die gebruikt wordt om te bepalen of er een significante associatie is tussen categorische variabelen. Hij vergelijkt de geobserveerde frequenties in verschillende categorieën met de frequenties die je zou verwachten als er geen associatie tussen de variabelen was.
Er zijn twee hoofdtypen chi-kwadraattoetsen:
Om de geldigheid van de chi-kwadraattoets te waarborgen, moeten bepaalde aannames worden voldaan:
Chi-kwadraattoetsen worden veel gebruikt in academische en industriële contexten, vooral om hypotheses te toetsen over de onafhankelijkheid van categorische variabelen. Enkele praktische toepassingen zijn:
Dit zijn enkele van de vele toepassingen in academie en industrie en kunnen worden uitgebreid naar andere domeinen en vakgebieden.
De beste manier om chi-kwadraattoetsen te leren uitvoeren is via een voorbeeld waarbij we de toets op een dataset toepassen. We gebruiken de dataset Anemia Levels in Nigeria, die je kunt downloaden van Kaggle. De dataset is afkomstig uit de Nigeria Demographic and Health Surveys (NDHS) van 2018. Hij onderzoekt de impact van de leeftijd van moeders en sociaaleconomische factoren op het anemieniveau bij kinderen van 0–59 maanden in de 36 staten van Nigeria en het Federale Hoofdstedelijk District.
Laten we de dataset in R laden en een sample bekijken om de data beter te begrijpen. Om CSV-bestanden in R te lezen, moet je het pakket readr installeren.
# Load the necessary libraries
install.packages('readr')
library(readr)
# Load the dataset from the CSV file
dataset <- read_csv("children anemia.csv")
# Display the first few rows of the dataset
head(dataset)
# Rename a column
colnames(dataset)[colnames(dataset) == "Anemia level...8"] <- "Anemia level"
# Display the column names
colnames(dataset)Naast een sample van de dataset zien we hieronder de kolommen van de dataset:
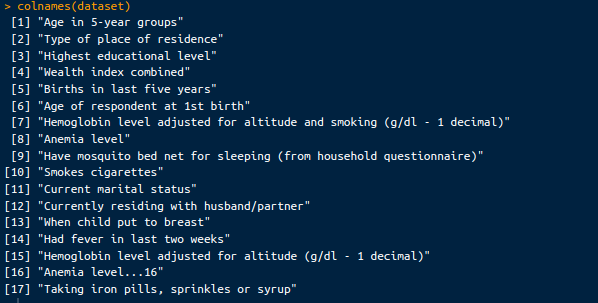 Kolommen in de dataset. Afbeelding door de auteur.
Kolommen in de dataset. Afbeelding door de auteur.
Hieruit kiezen we deze twee kolommen om te beoordelen of er een relatie tussen bestaat.
Hoogst behaalde opleidingsniveau: Deze kolom categoriseert de opleiding van de moeder in “Geen onderwijs”, “Basisonderwijs”, “Voortgezet onderwijs” en “Hoger onderwijs”.
Anemieniveau: Deze kolom geeft het anemieniveau van het kind aan, zoals “Matig”, “Ernstig” of “Geen anemie”.
Een kruistabel, ook wel cross-tab of contingentietabel genoemd, laat zien hoe de waarden van twee of meer categorische variabelen over hun categorieën zijn verdeeld.
We selecteren de twee gekozen kolommen uit de dataset en zetten ze om naar het vereiste kruistabelformaat. Voor deze bewerkingen gebruiken we het veelgebruikte pakket dplyr.
# Install and load the package
install.packages('dplyr')
library(dplyr)
# Select the columns of interest
selected_data <- dataset %>% select(Highest educational level, Anemia level)
# Create a contingency table for Highest educational level and Anemia level
contingency_table <- table(selected_data$Highest educational level, selected_data$Anemia level)
# View the contingency table
print(contingency_table)De resulterende kruistabel ziet er zo uit:
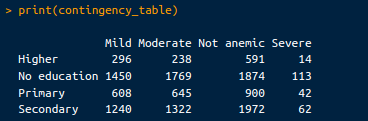
Kruistabel. Afbeelding door de auteur.
Omdat we de dataset nu in het gewenste kruistabelformaat hebben, kunnen we simpelweg de functie chisq.test() toepassen. Je hoeft geen extra libraries te laden om deze functie aan te roepen, want hij is beschikbaar in base R.
# Perform chi-square test
chi_square_test <- chisq.test(contingency_table)
# View the results
print(chi_square_test)De output ziet er als volgt uit:
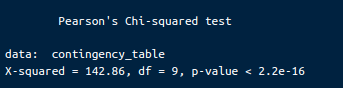
Resultaten van Pearson’s chi-kwadraattoets. Afbeelding door de auteur.
Dat is alles! We hebben de chi-kwadraattoets in twee eenvoudige stappen uitgevoerd. Hoe interpreteren we nu de resultaten?
Hypothesen geven duidelijk aan wat we testen en bieden een kader om de resultaten te interpreteren. Simpeler gezegd: de geformuleerde hypothese geeft ons een duidelijke vraag om te beantwoorden, en de chi-kwadraattoets helpt bepalen of de geobserveerde data de bewering ondersteunt of weerlegt.
Bij het uitvoeren van een chi-kwadraattoets formuleren we doorgaans twee hypothesen:
Toegepast op de variabelen waarop we de chi-kwadraattoets hebben uitgevoerd, kunnen we de hypothesen als volgt formuleren:
Nu we een hypothese hebben gevormd, kunnen we de resultaten in die context interpreteren:
Chi-kwadraatstatistiek (X-squared): De chi-kwadraattoetsstatistiek is 142.86. Deze waarde meet de discrepantie tussen de geobserveerde frequenties in de kruistabel en de frequenties die we zouden verwachten als er geen associatie tussen de variabelen was.
Vrijheidsgraden (df): Het aantal vrijheidsgraden voor deze toets is 9. Dit wordt berekend als (aantal rijen - 1) * (aantal kolommen - 1).
P-waarde: De p-waarde is kleiner dan 2.2e-16, wat extreem klein is. Deze p-waarde geeft de kans aan om een chi-kwadraatstatistiek te observeren die minstens zo extreem is als 142.86 als de nulhypothese waar zou zijn.
We verwerpen de nulhypothese omdat de p-waarde veel kleiner is dan gangbare significantieniveaus (bijv. 0,05, 0,01 of zelfs 0,001). Dit levert sterk bewijs voor een significante associatie tussen het opleidingsniveau van de moeder en de anemiestatus van het kind. Met andere woorden: de resultaten van de chi-kwadraattoets geven aan dat de kans op anemie bij een kind significant samenhangt met het opleidingsniveau van de moeder.
Naast hypothesetoetsing kunnen we bepaalde waarden ophalen uit het object dat door de functie chisq.test() wordt geretourneerd:
Dit zijn de daadwerkelijke tellingen van kinderen met verschillende anemieniveaus per opleidingsniveau van de moeder. De geobserveerde tellingen kun je als volgt ophalen:
# Observed counts
observed_counts <- chi_square_test$observed
print(observed_counts)De output is als volgt:
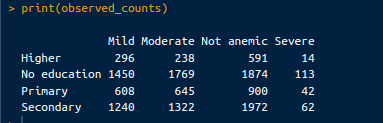
Geobserveerde tellingen. Afbeelding door de auteur.
Deze tellingen worden berekend onder de aanname dat er geen associatie is tussen het opleidingsniveau van de moeder en de anemiestatus van het kind. De verwachte tellingen kun je als volgt ophalen:
# Expected counts
expected_counts <- chi_square_test$expected
print(round(expected_counts, 2))De output is als volgt:
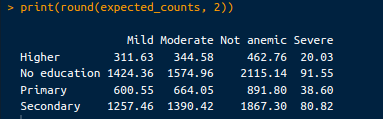
Verwachte tellingen. Afbeelding door de auteur.
Deze residuen helpen de grootste discrepanties tussen geobserveerde en verwachte tellingen te identificeren en laten zien welke cellen het meest bijdragen aan de chi-kwadraatstatistiek. De Pearson-residuen kun je als volgt ophalen:
# Pearson residuals
pearson_residuals <- chi_square_test$residuals
print(round(pearson_residuals, 2))De output is als volgt:
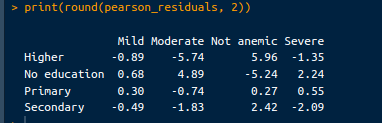
Residuen-output. Afbeelding door de auteur.
Laten we begrijpen wat deze residuwaarden betekenen:
Positieve residuen: Positieve residuen geven aan dat de geobserveerde telling hoger is dan verwacht. Bijvoorbeeld, een residu van 5.96 voor "Niet anemisch" in de groep “Hoger onderwijs” betekent dat er aanzienlijk meer kinderen zonder anemie zijn dan verwacht bij moeders met hoger onderwijs.
Negatieve residuen: Negatieve residuen geven aan dat de geobserveerde telling lager is dan verwacht. Zo suggereert een residu van -5.74 voor "Matig" anemie in de groep “Hoger onderwijs” dat er aanzienlijk minder kinderen met matige anemie zijn dan verwacht bij moeders met hoger onderwijs.
Grote residuen: Grote positieve of negatieve residuen wijzen op een sterke afwijking van wat verwacht werd. Deze cellen dragen het meest bij aan de chi-kwadraatstatistiek. Bijvoorbeeld, het grote positieve residu voor “Niet anemisch” in de groep “Hoger onderwijs” en het grote negatieve residu voor “Matig” anemie in dezelfde groep duiden op sterke afwijkingen in de anemieniveaus van kinderen op basis van het opleidingsniveau van de moeder.
Kleine residuen: Kleine residuen (dicht bij 0) suggereren dat de geobserveerde tellingen dicht bij de verwachte tellingen liggen, wat op een zwakkere afwijking wijst. Bijvoorbeeld, de residuen voor “Basisonderwijs” over de anemieniveaus zijn relatief klein, wat aangeeft dat geobserveerde en verwachte tellingen dichter bij elkaar liggen voor deze groep.
Op basis van de hierboven opgehaalde waarden kan de bijdrage van elke cel aan de chi-kwadraatstatistiek met onderstaande code worden berekend en omgezet naar een percentage:
# Calculate contribution to chi-square statistic
contributions <- (observed_counts - expected_counts)^2 / expected_counts
# Calculate percentage contributions
total_chi_square <- chi_square_test$statistic
percentage_contributions <- 100 * contributions / total_chi_square
# Print percentage contributions
print("Percentage Contributions:")
print(round(percentage_contributions, 2))De output is als volgt:
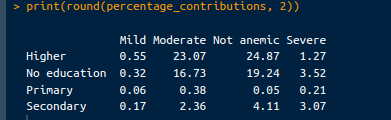 Percentagebijdragen. Afbeelding door de auteur.
Percentagebijdragen. Afbeelding door de auteur.
De berekende bijdrage kan worden gevisualiseerd als een heatmap. We gebruiken hiervoor een pakket genaamd pheatmap, nadat we het hebben geïnstalleerd en geladen.
# Install and load heatmap package
install.packages("pheatmap")
library(heatmap)
# Create heatmap for percentage contributions
pheatmap(percentage_contributions,
display_numbers = TRUE,
cluster_rows = FALSE,
cluster_cols = FALSE,
main = "Percentage Contribution to Chi-Square Statistic")De resulterende output is als volgt:
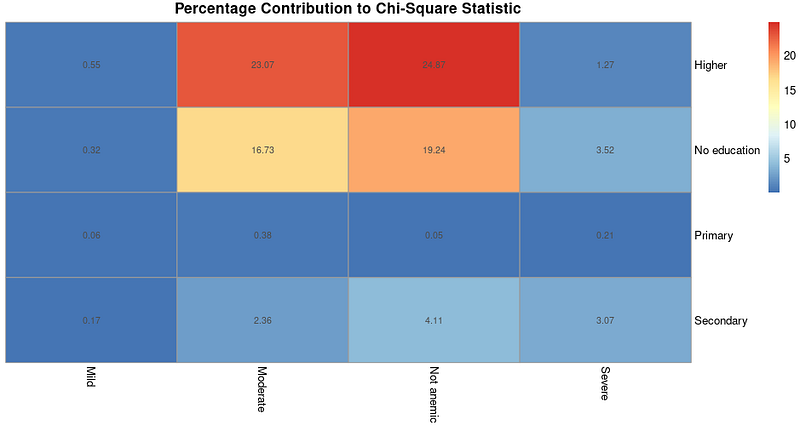 Heatmap van percentagebijdrage aan chi-kwadraatstatistiek. Afbeelding door de auteur.
Heatmap van percentagebijdrage aan chi-kwadraatstatistiek. Afbeelding door de auteur.
Een heatmap zoals hierboven met bijdragen kan nuttig zijn als je verdere analyses wilt uitvoeren om te begrijpen welk type associaties er bestaan, nadat we met de chi-kwadraattoets hebben vastgesteld dát er associaties zijn.
Deze tutorial heeft je kennis laten maken met de chi-kwadraattoets, de verschillende typen en de onderliggende aannames. We hebben ook geleerd hoe je de toets uitvoert en de resultaten in R interpreteert, met aanvullende visualisatie aan de hand van een voorbeeld.
Chi-kwadraattoetsen worden vaak gebruikt bij hypothesetoetsing en in de statistiek in het algemeen. Overweeg een van deze cursussen om je begrip van data-analyse en statistiek met R te versterken:
Leren met DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
