
Cours
Introduction aux statistiques en R
4 h
130.4K
Comprendre comment analyser et interpréter les données est une compétence inestimable pour les professionnels des données. Il existe de nombreux tests statistiques différents qui sont utilisés pour différentes raisons. Le test du chi-carré est un test courant qui est utilisé dans un contexte spécifique : lorsque vous devez déterminer des associations entre des variables catégorielles. C'est une chose courante que les chercheurs doivent savoir, et c'est pourquoi le test du chi carré est l'un des tests statistiques les plus utilisés.
Ce tutoriel présente le test du chi-carré, ses différents types et les étapes à suivre pour l'effectuer à l'aide du langage de programmation R. À la fin de ce guide, vous aurez acquis les connaissances et les compétences nécessaires pour appliquer en toute confiance le test du chi-carré à vos propres données et en interpréter les résultats.
Si vous ne connaissez pas le langage de programmation R, vous pouvez consulter le cursus professionnel Data Analyst with R, qui s'adresse aux débutants, afin de vous familiariser avec le langage à l'aide d'exemples pratiques d'analyse de données.
Pour effectuer un test du chi-carré dans R, procédez comme suit :
Étape 1: Préparez vos données sous la forme d'un tableau de contingence.
Étape 2: Utilisez la fonction chisq.test() pour appliquer le test du chi-carré.
Voici un exemple rapide de démonstration à l'aide d'un échantillon de données :
# Step 1: Creating a contingency table
data <- matrix(c(10, 20, 30, 40), nrow = 2)
# Step 2: Applying the chi-square test function
result <- chisq.test(data)
# Viewing the result
print(result)Cet extrait de code crée un tableau de contingence 2x2 et effectue le test du chi-carré. Le résultat indiquera la statistique du test, les degrés de liberté et la valeur p.
Le test du chi-carré est un test statistique utilisé pour déterminer s'il existe une association significative entre des variables catégorielles. Elle compare les fréquences observées des occurrences dans les différentes catégories avec les fréquences attendues s'il n'y avait pas d'association entre les variables.
Il existe deux types principaux de tests du chi-carré :
Pour garantir la validité du test du chi-carré, certaines hypothèses doivent être respectées :
Les tests du khi-deux sont largement utilisés dans le monde universitaire et dans l'industrie, en particulier pour tester des hypothèses sur l'indépendance de variables catégorielles. Voici quelques-unes de ces applications pratiques :
Il convient de noter qu'il s'agit là de quelques-unes des nombreuses applications dans les universités et l'industrie et qu'elles peuvent être étendues à d'autres domaines et champs d'activité.
La meilleure façon d'apprendre à effectuer des tests du khi-deux est d'utiliser un exemple dans lequel nous appliquons le test à un ensemble de données. Nous utiliserons le jeu de données Niveaux d'anémie au Nigeria, qui peut être téléchargé sur Kaggle. Les données proviennent des enquêtes démographiques et de santé du Nigéria (NDHS) de 2018. Elle étudie l'impact de l'âge des mères et des facteurs socio-économiques sur les niveaux d'anémie chez les enfants âgés de 0 à 59 mois dans les 36 États du Nigeria et le Territoire de la capitale fédérale.
Chargeons l'ensemble de données dans R et examinons un échantillon pour mieux comprendre les données. Pour lire les fichiers CSV dans R, vous devez installer un paquetage appelé readr.
# Load the necessary libraries
install.packages('readr')
library(readr)
# Load the dataset from the CSV file
dataset <- read_csv("children anemia.csv")
# Display the first few rows of the dataset
head(dataset)
# Rename a column
colnames(dataset)[colnames(dataset) == "Anemia level...8"] <- "Anemia level"
# Display the column names
colnames(dataset)En plus d'un échantillon de l'ensemble de données, nous verrons les colonnes de l'ensemble de données ci-dessous :
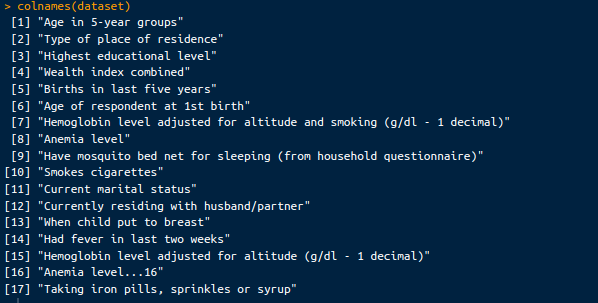 Colonnes de l'ensemble de données. Image par l'auteur.
Colonnes de l'ensemble de données. Image par l'auteur.
Parmi elles, nous choisirons ces deux colonnes pour évaluer s'il existe une relation entre elles.
Niveau d'études le plus élevé : Cette colonne classe le niveau d'éducation de la mère en "Pas d'éducation", "Primaire", "Secondaire" et "Supérieur".
Niveau d'anémie : Cette colonne indique le niveau d'anémie de l'enfant, par exemple "Modéré", "Sévère" ou "Pas d'anémie".
Un tableau de contingence, également appelé tableau croisé, montre comment les valeurs de deux ou plusieurs variables catégorielles sont réparties dans leurs catégories respectives.
Nous allons sélectionner les deux tableaux de l'ensemble de données et les convertir au format requis pour les tableaux de contingence. Pour ces opérations, nous utiliserons un paquetage couramment utilisé, appelé dplyr.
# Install and load the package
install.packages('dplyr')
library(dplyr)
# Select the columns of interest
selected_data <- dataset %>% select(Highest educational level, Anemia level)
# Create a contingency table for Highest educational level and Anemia level
contingency_table <- table(selected_data$Highest educational level, selected_data$Anemia level)
# View the contingency table
print(contingency_table)Le tableau de contingence qui en résulte se présente comme suit :
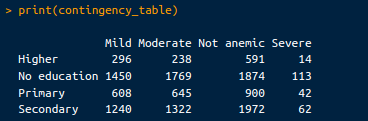
Tableau de contingence. Image par l'auteur.
Puisque nous disposons de l'ensemble des données dans le format de tableau de contingence souhaité, il nous suffit d'appliquer la fonction chisq.test(). Il n'est pas nécessaire de charger des bibliothèques pour appeler cette fonction, car elle est disponible dans le paquetage de base de R.
# Perform chi-square test
chi_square_test <- chisq.test(contingency_table)
# View the results
print(chi_square_test)Le résultat sera le suivant :
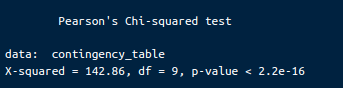
Résultats du test chi-carré de Pearson. Image par l'auteur.
C'est tout ! Nous avons effectué le test du chi-carré en deux étapes simples. Ensuite, comment interpréter les résultats ?
Les hypothèses énoncent clairement ce que nous testons et établissent un cadre pour l'interprétation des résultats. En termes plus simples, l'hypothèse que nous formulons nous donne une question claire à laquelle nous devons répondre, et le test du chi-deux nous aide à déterminer si les données observées soutiennent ou réfutent l'affirmation.
Lorsque vous effectuez un test du chi-carré, vous établissez généralement deux hypothèses :
En appliquant les concepts d'hypothèse nulle et d'hypothèse alternative aux variables sur lesquelles nous avons effectué le test du khi-deux, nous pouvons formuler l'hypothèse comme suit :
Maintenant que nous avons formulé une hypothèse, nous pouvons interpréter les résultats dans le contexte de l'hypothèse :
Statistique du chi-carré (X-carré) : La statistique du test du chi-carré est 142.86. Cette valeur mesure l'écart entre les fréquences observées dans le tableau de contingence et les fréquences auxquelles on s'attendrait s'il n'y avait pas d'association entre les variables.
Degrés de liberté (df) : Le degré de liberté de ce test est 9. Elle est calculée comme suit : (nombre de lignes - 1) * (nombre de colonnes - 1).
Valeur P : La valeur p est inférieure à 2.2e-16, ce qui est extrêmement faible. Cette valeur p indique la probabilité d'observer une statistique du chi-carré aussi extrême que, ou plus extrême que, 142.86 si l'hypothèse nulle était vraie.
Nous rejetons l'hypothèse nulle car la valeur p est beaucoup plus petite que les niveaux de signification courants (par exemple, 0,05, 0,01 ou même 0,001). Cela prouve bien qu'il existe une association significative entre le niveau d'éducation de la mère et l'état d'anémie de l'enfant. En d'autres termes, les résultats du test du chi-deux indiquent que la probabilité qu'un enfant souffre d'anémie est significativement associée au niveau d'éducation de la mère.
Au-delà des tests d'hypothèse, nous pouvons récupérer certaines valeurs de l'objet renvoyé par la fonction chisq.test():
Ces chiffres représentent le nombre réel d'enfants présentant différents niveaux d'anémie en fonction du niveau d'éducation de la mère. Les chiffres observés peuvent être récupérés à partir du code suivant :
# Observed counts
observed_counts <- chi_square_test$observed
print(observed_counts)Le résultat est le suivant :
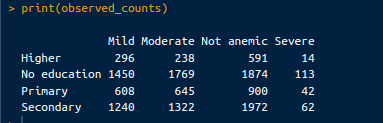
Chiffres observés. Image par l'auteur.
Ces chiffres sont calculés en supposant qu'il n'y a pas d'association entre le niveau d'éducation de la mère et l'état d'anémie de l'enfant. Les nombres attendus peuvent être récupérés à partir du code suivant :
# Expected counts
expected_counts <- chi_square_test$expected
print(round(expected_counts, 2))Le résultat est le suivant :
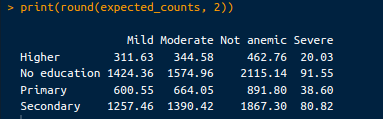
Chiffres attendus. Image par l'auteur.
Ces résidus permettent d'identifier les écarts les plus importants entre les effectifs observés et les effectifs attendus, en indiquant les cellules qui contribuent le plus à la statistique du khi-deux. Les résidus de Pearson peuvent être récupérés à partir du code suivant :
# Pearson residuals
pearson_residuals <- chi_square_test$residuals
print(round(pearson_residuals, 2))Le résultat est le suivant :
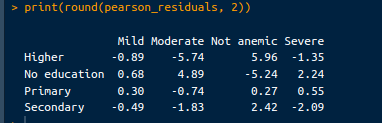
Sortie des résidus. Image par l'auteur.
Essayons de comprendre ce que signifient ces chiffres résiduels :
Résidus positifs : Des résidus positifs indiquent que le nombre observé est plus élevé que prévu. Par exemple, un résidu de 5.96 pour "Pas anémique" dans le groupe d'éducation "supérieure" signifie qu'il y a significativement plus d'enfants qui ne sont pas anémiques que prévu parmi les mères ayant un niveau d'éducation supérieur.
Résidus négatifs : Des résidus négatifs indiquent que le nombre observé est plus faible que prévu. Par exemple, un résidu de -5.74 pour l'anémie "modérée" dans le groupe d'éducation "supérieure" suggère qu'il y a significativement moins d'enfants modérément anémiques que prévu parmi les mères ayant un niveau d'éducation supérieur.
Des résidus importants : Des résidus positifs ou négatifs importants suggèrent un écart significatif par rapport à ce qui était attendu. Ces cellules contribuent le plus à la statistique du chi-carré. Par exemple, l'important résidu positif pour "Pas anémique" dans le groupe d'éducation "supérieure" et l'important résidu négatif pour l'anémie "modérée" dans le même groupe indiquent de fortes divergences dans les niveaux d'anémie des enfants en fonction du niveau d'éducation de la mère.
Petits résidus : Des résidus faibles (proches de 0) suggèrent que les nombres observés sont proches des nombres attendus, ce qui indique une déviation plus faible. Par exemple, les résidus pour l'éducation "primaire" à travers les niveaux d'anémie sont relativement plus petits, ce qui indique que les comptes observés et attendus sont plus proches pour ce groupe.
Sur la base des valeurs extraites ci-dessus, la contribution de chaque cellule à la statistique du chi-carré peut être calculée par le code ci-dessous et convertie en pourcentage :
# Calculate contribution to chi-square statistic
contributions <- (observed_counts - expected_counts)^2 / expected_counts
# Calculate percentage contributions
total_chi_square <- chi_square_test$statistic
percentage_contributions <- 100 * contributions / total_chi_square
# Print percentage contributions
print("Percentage Contributions:")
print(round(percentage_contributions, 2))La sortie que nous verrons est la suivante :
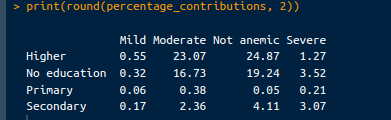 Pourcentage de contribution. Image par l'auteur.
Pourcentage de contribution. Image par l'auteur.
La contribution calculée peut être visualisée sous forme de carte thermique. Pour ce faire, nous utiliserons un paquet appelé pheatmap, après l'avoir installé et chargé.
# Install and load heatmap package
install.packages("pheatmap")
library(heatmap)
# Create heatmap for percentage contributions
pheatmap(percentage_contributions,
display_numbers = TRUE,
cluster_rows = FALSE,
cluster_cols = FALSE,
main = "Percentage Contribution to Chi-Square Statistic")Le résultat est le suivant :
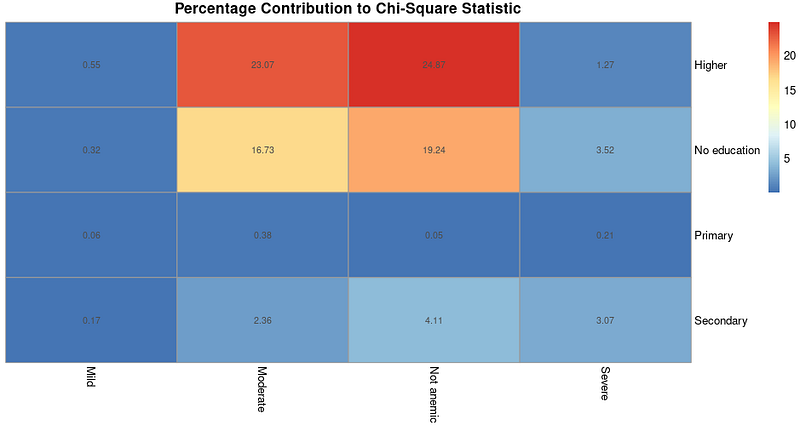 Pourcentage de contribution à la carte thermique de la statistique du chi-carré. Image par l'auteur.
Pourcentage de contribution à la carte thermique de la statistique du chi-carré. Image par l'auteur.
Une carte thermique comme celle ci-dessus avec les contributions peut être utile si vous décidez d'effectuer une analyse plus approfondie pour comprendre quel type d'association existe après que nous ayons découvert l'existence d'associations sur la base des résultats du test du khi-deux.
Ce didacticiel vous a présenté le test du chi-carré, ses différents types et les hypothèses sous-jacentes. Nous avons également appris à effectuer le test et à interpréter les résultats en R avec une visualisation supplémentaire à l'aide d'un exemple.
Les tests du khi-deux sont couramment utilisés lors des tests d'hypothèses et, de manière générale, en statistique. Envisagez de suivre l'un de ces cours pour consolider votre compréhension de l'analyse des données et des statistiques à l'aide de R :
Apprenez à tirer une valeur commerciale de l'IA et des LLM.
Apprenez avec DataCamp
Cours
Cours
Cours
Tutoriel
Allan Ouko
Tutoriel
DataCamp Team
Tutoriel
Laiba Siddiqui
Tutoriel
Aditya Sharma
Tutoriel
Matt Crabtree
Tutoriel
Aditya Sharma

