
Course
Introduction to Statistics in R
4 hr
130.4K
Understanding how to analyze and interpret data is an invaluable skill for data professionals. There are many different statistical tests that are used for different reasons. The chi-square test is a common test that is used in a specific context: when you need to determine associations between categorical variables. This is a common thing researchers need to know, which is why the chi square test is one of the most widely used statistical tests.
This tutorial introduces the chi-square test, its different types, and the steps to perform it using the R programming language. By the end of this guide, you’ll be equipped with the knowledge and skills to confidently apply the chi-square test to your own data and interpret the results.
If you’re new to the R programming language, you may want to check out the beginner-friendly Data Analyst with R career track to familiarize yourself with the language through hands-on data analysis examples.
To perform a chi-square test in R, follow these steps:
Step 1: Prepare your data in a contingency table format.
Step 2: Use the chisq.test() function to apply the chi-square test.
Here is a quick example demonstrating it using sample data:
# Step 1: Creating a contingency table
data <- matrix(c(10, 20, 30, 40), nrow = 2)
# Step 2: Applying the chi-square test function
result <- chisq.test(data)
# Viewing the result
print(result)This code snippet creates a 2x2 contingency table and performs the chi-square test. The result will show the test statistic, degrees of freedom, and p-value.
A chi-square test is a statistical test used to determine if there is a significant association between categorical variables. It compares the observed frequencies of occurrences in different categories with the frequencies expected if there were no associations between the variables.
There are two main types of chi-square tests:
To ensure the validity of the chi-square test, certain assumptions must be met:
Chi-square tests are widely used in academia and industry, especially for testing hypotheses about the independence of categorical variables. Some of these practical applications are:
It’s worth noting that these are some of the many applications across academia and the industry and can be extended to other domains and fields.
The best way to learn to perform chi-square tests is through an example where we apply the test to a dataset. We’ll use the Anemia Levels in Nigeria dataset, which can be downloaded from Kaggle. The dataset comes from the 2018 Nigeria Demographic and Health Surveys (NDHS). It explores the impact of mothers’ age and socioeconomic factors on anemia levels among children aged 0–59 months across Nigeria’s 36 states and the Federal Capital Territory.
Let’s load the dataset in R and examine a sample to understand the data better. To read CSV files in R, you’ll need to install a package called readr.
# Load the necessary libraries
install.packages('readr')
library(readr)
# Load the dataset from the CSV file
dataset <- read_csv("children anemia.csv")
# Display the first few rows of the dataset
head(dataset)
# Rename a column
colnames(dataset)[colnames(dataset) == "Anemia level...8"] <- "Anemia level"
# Display the column names
colnames(dataset)In addition to a sample of the dataset, we’ll see the columns of the dataset below:
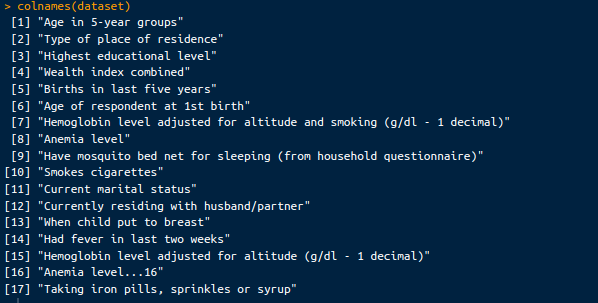 Columns in the dataset. Image by Author.
Columns in the dataset. Image by Author.
Among them, we’ll pick these two columns to evaluate if there is a relationship between them.
Highest educational level: This column categorizes the mother’s education into “No education,” “Primary,” “Secondary,” and “Higher” levels.
Anemia level: This column indicates the anemia level of the child, such as “Moderate,” “Severe,” or “No Anemia.”
A contingency table, also known as a cross-tabulation or cross-tab, shows how the values of two or more categorical variables are distributed across their respective categories.
We’ll select the two selected columns from the dataset and convert them to the required contingency table format. We’ll use a commonly used package called dplyr for these operations.
# Install and load the package
install.packages('dplyr')
library(dplyr)
# Select the columns of interest
selected_data <- dataset %>% select(Highest educational level, Anemia level)
# Create a contingency table for Highest educational level and Anemia level
contingency_table <- table(selected_data$Highest educational level, selected_data$Anemia level)
# View the contingency table
print(contingency_table)The resulting contingency table looks like this:
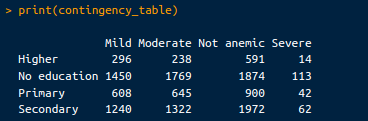
Contingency table. Image by Author.
Since we have the dataset in the contingency table format we want, we can simply apply the chisq.test() function. No libraries need to be loaded to call this function, as it’s available in the base R package.
# Perform chi-square test
chi_square_test <- chisq.test(contingency_table)
# View the results
print(chi_square_test)The output will look like:
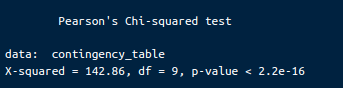
Pearson’s chi-square test results. Image by Author.
That’s it! We have performed the chi-square test in two simple steps. Next, how do we interpret the results?
Hypotheses clearly state what we are testing and establish a framework for interpreting the results. In simpler terms, the hypothesis we formulate gives us a clear question to answer, and the chi-square test helps us determine whether the observed data supports or refutes the claim.
When performing a chi-square test, we typically establish two hypotheses:
Applying the concepts of null and alternative hypothesis to the variables we have performed the chi-square test on, we can formulate the hypothesis as:
Now that we’ve formed a hypothesis, we can interpret the results in the context of the hypothesis:
Chi-Square Statistic (X-squared): The chi-square test statistic is 142.86. This value measures the discrepancy between the observed frequencies in the contingency table and the frequencies we would expect if there were no associations between the variables.
Degrees of Freedom (df): The degree of freedom for this test is 9. This is calculated as (number of row - 1) * (number of columns - 1).
P-Value: The p-value is less than 2.2e-16, which is extremely small. This p-value indicates the probability of observing a chi-square statistic as extreme as, or more extreme than, 142.86 if the null hypothesis were true.
We reject the null hypothesis since the p-value is much smaller than common significance levels (e.g., 0.05, 0.01, or even 0.001). This provides strong evidence of a significant association between the mother’s education level and the child’s anemia status. In other words, the chi-square test results indicate that the likelihood of a child having anemia is significantly associated with the mother’s level of education.
Beyond hypothesis testing, we can retrieve certain values from the object returned by the chisq.test() function:
These represent the actual counts of children with different anemia levels across each mother’s education level. The observed counts can be retrieved from the following code:
# Observed counts
observed_counts <- chi_square_test$observed
print(observed_counts)The output is as follows:
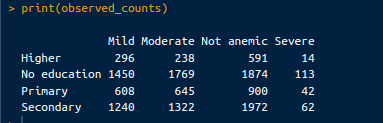
Observed counts. Image by Author.
These counts are calculated under the assumption that there is no association between the mother’s education level and the child’s anemia status. The expected counts can be retrieved from the following code:
# Expected counts
expected_counts <- chi_square_test$expected
print(round(expected_counts, 2))The output is as follows:
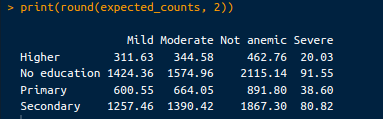
Expected counts. Image by Author.
These residuals help identify the largest discrepancies between observed and expected counts, indicating which cells contribute most to the chi-square statistic. The Pearson residuals can be retrieved from the following code:
# Pearson residuals
pearson_residuals <- chi_square_test$residuals
print(round(pearson_residuals, 2))The output is as follows:
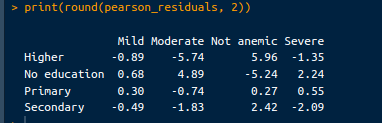
Residuals output. Image by Author.
Let us try to understand what these residual numbers mean:
Positive Residuals: Positive residuals indicate that the observed count is higher than expected. For example, a residual of 5.96 for "Not anemic" in the "Higher" education group means that there are significantly more children who are not anemic than expected among mothers with higher education.
Negative Residuals: Negative residuals indicate that the observed count is lower than expected. For instance, a residual of -5.74 for "Moderate" anemia in the "Higher" education group suggests that there are significantly fewer moderately anemic children than expected among mothers with higher education.
Large Residuals: Large positive or negative residuals suggest a significant deviation from what was expected. These cells contribute most to the chi-square statistic. For example, the large positive residual for “Not anemic” in the “Higher” education group and the large negative residual for “Moderate” anemia in the same group indicate strong deviations in the anemia levels of children based on the mother’s education level.
Small Residuals: Small residuals (close to 0) suggest that the observed counts are close to the expected counts, indicating a weaker deviation. For example, the residuals for “Primary” education across the anemia levels are relatively smaller, indicating that the observed and expected counts are closer for this group.
Based on the values extracted above, the contribution of each cell to the chi-square statistic can be calculated by the code below and converted into a percentage:
# Calculate contribution to chi-square statistic
contributions <- (observed_counts - expected_counts)^2 / expected_counts
# Calculate percentage contributions
total_chi_square <- chi_square_test$statistic
percentage_contributions <- 100 * contributions / total_chi_square
# Print percentage contributions
print("Percentage Contributions:")
print(round(percentage_contributions, 2))The output we’ll see is as follows:
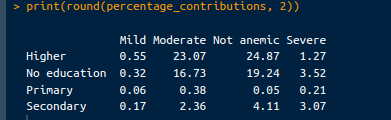 Percentage contributions. Image by Author.
Percentage contributions. Image by Author.
The calculated contribution can be visualized as a heatmap. We will use a package called pheatmap to do so, after installing and loading the package.
# Install and load heatmap package
install.packages("pheatmap")
library(heatmap)
# Create heatmap for percentage contributions
pheatmap(percentage_contributions,
display_numbers = TRUE,
cluster_rows = FALSE,
cluster_cols = FALSE,
main = "Percentage Contribution to Chi-Square Statistic")The resulting output is as follows:
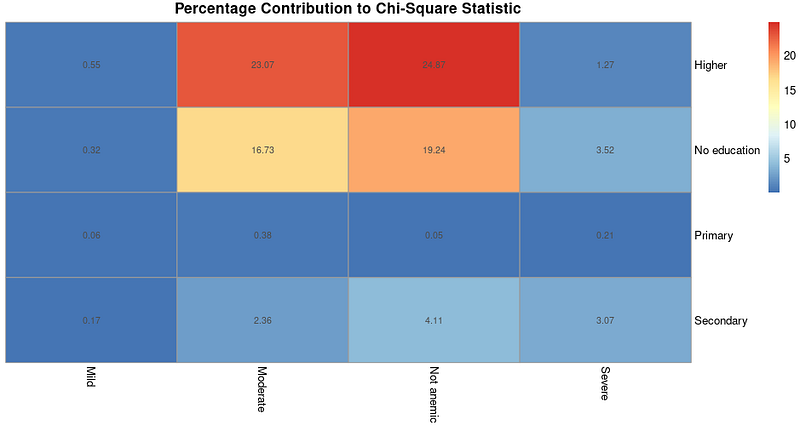 Percentage contribution to chi-square statistic heatmap. Image by Author.
Percentage contribution to chi-square statistic heatmap. Image by Author.
A heatmap like the one above with contributions can be useful if you choose to perform further analysis to understand what type of associations exist after we find out associations exist based on the chi-square test results.
This tutorial introduced you to the chi-square test, its different types, and the underlying assumptions. We further learned how to perform the test and interpret the results in R with added visualization using an example.
Chi-square tests are commonly used during hypothesis testing and generally in statistics. Consider taking up one of these courses to solidify your understanding of data analytics and statistics using R:
Learn how to extract business value from AI and LLMs.
Learn with DataCamp
Course
Course
Course
Tutorial
Vedabrata Basu
Tutorial
Avinash Navlani
Tutorial
Łukasz Deryło
Tutorial
Abid Ali Awan
Tutorial
Karlijn Willems
code-along
Arne Warnke
