

Program
Dasar-Dasar Agen Kecerdasan Buatan
6 Hr
Jika Anda seorang profesional data, kemungkinan Anda menangani banyak tugas pengodean berulang setiap hari. Hal-hal seperti memprofil dataset baru sepenuhnya, membangun pipeline data dari nol, atau menulis pengujian transformasi data secara manual. Hal seperti ini perlu dilakukan, tetapi memakan banyak waktu.
Namun bagaimana jika terminal Anda bisa mengelola dan menulis semua kode boilerplate berulang itu untuk Anda, sementara Anda memusatkan energi pada tugas brainstorming dan pengambilan keputusan? Di situlah Codex-CLI dari OpenAI berperan. Ini adalah agen pengodean AI yang sangat andal dan terpasang langsung di command line Anda, dan seperti yang akan kita lihat, ini sangat bagus untuk merampingkan alur kerja data.
Dalam tutorial ini, kita akan membahas bagaimana analis dan ilmuwan data dapat menggunakan Codex-CLI untuk mempercepat tugas data sehari-hari yang paling umum. Kita akan membahas semuanya mulai dari melakukan analisis data eksploratori awal hingga membangun pipeline data lengkap, dan bahkan membuat pengujian otomatis untuk transformasi Anda—semuanya melalui terminal itu sendiri.
Jika Anda ingin mengetahui lebih lanjut tentang membangun sistem AI agensial, saya sangat merekomendasikan mendaftar ke jalur keterampilan AI Agent Fundamentals kami, yang mencakup semua yang perlu Anda ketahui.
Pertama, mari pahami apa itu Codex CLI. Intinya, Codex CLI adalah agen pengodean berbasis terminal, open-source, yang dikembangkan oleh OpenAI.
Ia dibangun menggunakan bahasa pemrograman Rust, sehingga cukup cepat dan efisien. Namun yang paling penting untuk dipahami adalah ia beroperasi langsung dari command line Anda, yang memberinya kemampuan untuk membaca file, mengedit kode, dan bahkan mengeksekusi perintah secara lokal di mesin.
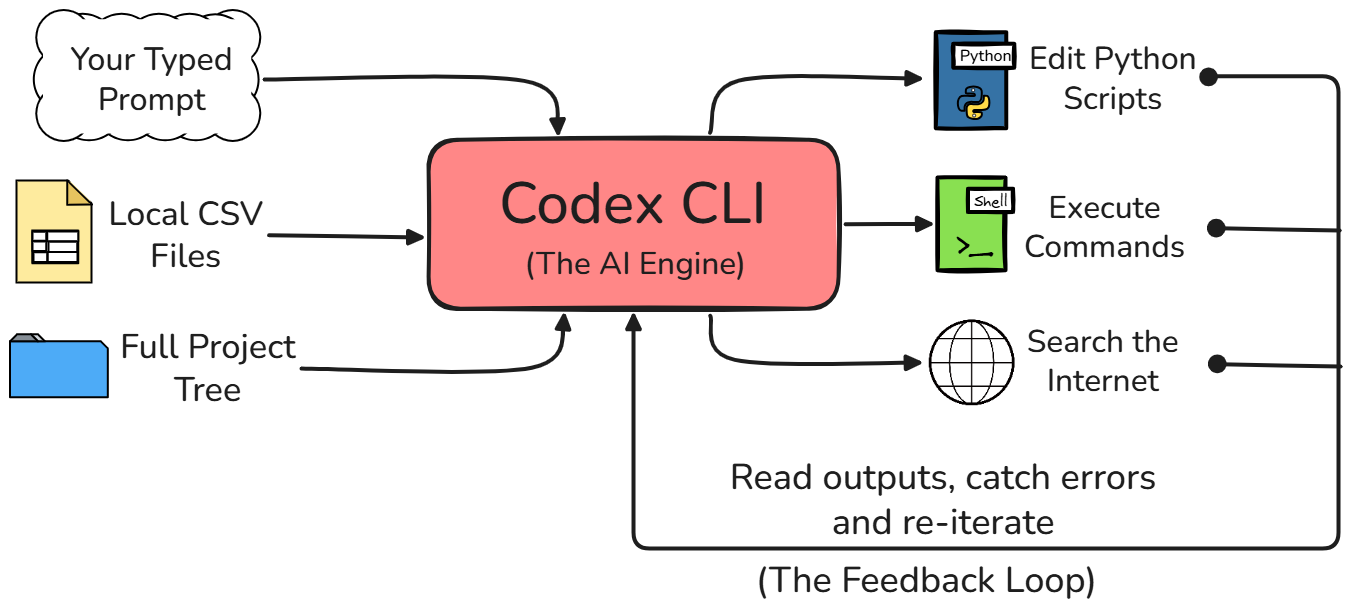
Meskipun Anda mungkin sudah terbiasa menggunakan antarmuka web ChatGPT standar untuk pekerjaan Anda, Codex CLI sangat berbeda. Saat Anda menggunakan antarmuka web, model AI sepenuhnya terisolasi dari lingkungan tempat Anda bekerja.
Dengan Codex CLI, agen tersebut benar-benar memiliki akses langsung ke sistem file lokal Anda. Ia dapat menjalankan skrip Python, melihat output atau error yang kembali, dan mempertahankan kesadaran penuh atas seluruh struktur proyek Anda tanpa Anda harus menjelaskan semuanya terlebih dahulu.
|
Langkah Alur Kerja / Fitur |
ChatGPT (Peramban Web) |
Codex CLI (Terminal) |
|
Mengakses Data |
Anda harus membuka file CSV secara manual dan menyalin-tempel beberapa baris data mentah ke chat agar AI memahaminya. |
Ia dapat membuka dan membaca file CSV Anda secara mandiri langsung dari sistem file lokal. |
|
Menjalankan Kode |
Anda harus menyalin skrip yang dihasilkan, menempelkannya ke editor kode lokal, lalu menjalankannya sendiri. |
Ia secara otomatis menulis skrip Python yang diperlukan, menjalankannya, dan menampilkan output akhir langsung di terminal. |
|
Pengalaman Keseluruhan |
Melibatkan banyak bolak-balik yang melelahkan, menyalin dan menempel antar jendela. |
Semuanya terjadi dalam satu alur yang tunggal, berkesinambungan, dan mulus di dalam terminal. |
Tentu saja, karena agen Codex memiliki kekuatan untuk langsung mengedit file Anda dan menjalankan perintah di mesin Anda, ia hadir dengan berbagai mode persetujuan agar Anda selalu tetap memegang kendali. Tiga mode persetujuan tersebut adalah:
Saat pertama kali memulai, saya sarankan memulai dalam Read-only, lalu beralih setelah Anda mempercayai alur kerjanya.
Anda dapat mengganti mode persetujuan di dalam sesi Codex yang sedang berjalan menggunakan /permissions. Ini cara termudah untuk berpindah dari Read-only ke Auto setelah Anda merasa nyaman.
/permissionsJika ingin memulai Codex dalam mode yang lebih ketat sejak awal, Anda dapat mengatur flag sandbox dan kebijakan persetujuan saat meluncurkannya. Misalnya, ini memulai dalam setelan konservatif read-only yang tetap meminta persetujuan saat diperlukan.
codex --sandbox read-only --ask-for-approval on-requestAda beberapa prasyarat yang perlu Anda miliki agar dapat mengikuti tutorial ini dengan baik.
Pertama-tama, Anda perlu memasang Codex CLI di mesin Anda. Untuk melakukannya, cukup buka terminal dan pasang CLI secara global di sistem Anda menggunakan perintah ini:
npm install -g @openai/codexLangkah berikutnya adalah melakukan autentikasi akun Anda, agar alat ini mengenali Anda. Anda dapat memverifikasi bahwa semuanya terpasang dengan benar dan meluncurkan agen untuk pertama kali hanya dengan mengetik codex di terminal. Ini akan menampilkan seperti berikut:
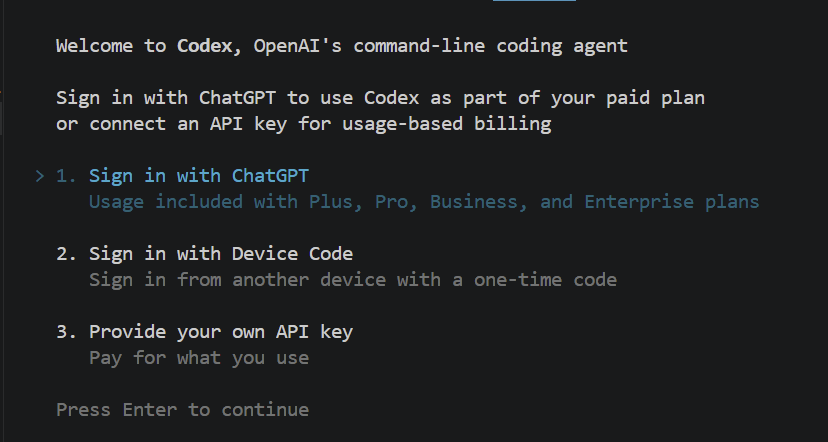
Setelah Anda menekan enter, jendela peramban akan terbuka dan Anda akan diminta masuk melalui akun ChatGPT Anda. Setelah masuk, Anda siap menggunakan alat ini.
Jika Anda tidak memiliki langganan ChatGPT berbayar dan ingin menggunakan kunci API, tersedia juga opsi bayar sesuai pemakaian. Anda dapat memperoleh kunci dari konsol OpenAI.
Sebelum kita mulai meminta AI melakukan analisis data, penting untuk mengonfigurasi lingkungan data Python dengan benar. Ini penting karena Codex CLI beroperasi di dalam lingkungan apa pun yang saat ini ia jalankan. Jadi, jika agen perlu menulis skrip yang menggunakan pustaka sains data seperti pandas, scikit-learn, atau matplotlib, Anda harus memastikan pustaka-pustaka tersebut terpasang dan tersedia untuk digunakan.
Kita dapat melakukannya dengan mengaktifkan virtual environment Python sebelum meluncurkan Codex. Berikut skrip setup contoh dengan perintah tepat yang dapat Anda jalankan di terminal untuk membuat virtual environment, memasang paket data yang diperlukan, mengaktifkannya, lalu meluncurkan agen:
python3 -m venv data_env
source data_env/bin/activate
pip install pandas scikit-learn matplotlib
codexSatu langkah penting lagi dalam menyiapkan proyek Anda adalah membuat file bernama AGENTS.md di dalam folder proyek utama. Anda dapat menganggap file ini sebagai serangkaian instruksi persisten yang dibaca agen Codex secara otomatis setiap kali membuka proyek Anda. File ini memberi tahu AI bagaimana Anda ingin ia berperilaku dan bagaimana ia harus menulis kode untuk ruang kerja spesifik ini.
Untuk pekerjaan data, kita ingin memastikan kode yang dihasilkan AI bersih, mudah dibaca, dan profesional. Jadi, berikut contoh file AGENTS.md yang secara khusus disesuaikan untuk proyek data. Anda cukup membuat file ini dan menempelkan teks berikut:
# Data Project Guidelines
When writing Python code for this project, please strictly follow these rules:
- Enforce PEP 8 formatting standards for all Python code.
- Always use highly descriptive variable names. Do not use generic, lazy names like df, data, x, or y. Instead, use specific names like transaction_data or revenue_series.
- Prefer pandas best practices, such as using vectorized operations instead of iterating through rows.
- Generate clear, descriptive docstrings for every single function.
- Always include Python type hints for function arguments and return values.Karena file ini akan dibaca setiap saat, terlepas dari tugas yang sedang dikerjakan, praktik terbaiknya adalah menjaganya ringkas dan hanya fokus pada instruksi yang berlaku untuk setiap prompt. Untuk instruksi yang lebih spesifik, sebaiknya gunakan skills sebagai gantinya.
Sekarang, beralih ke pekerjaan data sebenarnya, kita akan mulai dengan Exploratory Data Analysis, atau EDA. Seperti yang mungkin sudah Anda ketahui, ini hampir selalu menjadi titik awal paling umum untuk proyek data baru apa pun yang Anda tangani. Sebelum dapat membangun model atau pipeline, Anda harus tahu seperti apa data Anda.
Hal terbaiknya di sini adalah dengan Codex CLI, satu prompt bahasa alami yang sederhana dapat menghasilkan skrip EDA yang lengkap dan siap jalan untuk Anda.
Skenario: Untuk contoh hari ini, bayangkan kita bekerja dengan dataset sintetis yang realistis. Misalnya kita memiliki dataset e-commerce bernama transactions.csv yang berada di folder proyek kita. Ini berisi data bisnis realistis seperti ID pesanan, ID pengguna, cap waktu pembelian, dan nilai transaksi.
Saat Anda mendapatkan file baru seperti ini, hal pertama yang ingin dilakukan adalah memprofilnya untuk memahami struktur dasarnya. Alih-alih menulis kode pandas boilerplate sendiri, Anda bisa langsung membuka terminal tempat sesi Codex Anda berjalan, dan mengetikkan prompt persis seperti ini:
Profile the transactions.csv file. Show shape, dtypes, missing values, and summary statistics.Saat Anda menekan enter, Codex membaca beberapa baris pertama dari file transactions.csv Anda langsung dari sistem file lokal. Ia kemudian akan menghasilkan skrip Python lengkap untuk melakukan pemprofilan, dan dalam mode "suggest" akan menanyakan apakah Anda ingin menjalankannya.
Anda akan langsung melihat bentuk data, tipe data kolom e-commerce Anda, dan tepatnya berapa banyak nilai hilang yang harus ditangani (contoh ditunjukkan di bawah), semuanya tanpa menulis satu baris kode pun.
Angka di terminal bagus, tetapi pada akhirnya Anda perlu melihat data secara visual. Anda dapat menghasilkan visualisasi yang mengejutkan kompleks hanya dengan mendeskripsikan apa yang Anda inginkan dalam bahasa Inggris sederhana.
Misalnya, jika Anda ingin mendapatkan pandangan menyeluruh atas bisnis e-commerce Anda, Anda bisa memberikan Codex prompt seperti ini:
Create a matplotlib dashboard with 3 subplots showing revenue by month, product categories ranked by sales, and order distribution by day of week.Itu permintaan yang cukup kompleks. Namun Codex akan menganalisis baik prompt maupun file data Anda lagi, mencari cara mengelompokkan tanggal dan menjumlahkan pendapatan, membuat rencana langkah demi langkah, dan mengubahnya menjadi skrip matplotlib yang andal untuk menghasilkan subplot tersebut.
Sekarang, ini poin yang sangat krusial saat bekerja dengan agen AI seperti ini: prosesnya pada dasarnya bersifat iteratif. Ketika Codex menyarankan versi pertama kode visualisasi, Anda sebaiknya menyetujuinya untuk melihat hasilnya.
Mungkin versi pertama menghasilkan bagan, tetapi Anda melihat label sumbu x tumpang tindih dan sulit dibaca, atau mungkin warnanya terlalu terang. Anda tidak perlu membuka skrip dan memperbaiki parameter matplotlib secara manual.
Cukup balas dengan prompt tindak lanjut, misalnya, "Label di bawah saling tumpang tindih, tolong putar 45 derajat dan buat warna legenda lebih lembut." Codex kemudian akan menyempurnakan skrip, menjalankannya lagi, dan memberi Anda dasbor yang diperbarui dan dipoles.
Jadi, setelah Anda selesai bermain-main dengan data dan melakukan analisis eksploratori awal, pada akhirnya Anda perlu beranjak dari skrip ad-hoc yang berantakan itu.
Yang sebenarnya Anda inginkan adalah beralih ke pembuatan kode yang nyata, dapat direproduksi, dan modular. Di dunia data, ini biasanya berarti membangun pipeline ETL (Extract, Transform, and Load). Ini adalah cara standar untuk menarik data Anda, membersihkannya, dan menyimpan hasilnya untuk digunakan nanti.
Untuk menunjukkan cara kerjanya, kita akan menggunakan skenario yang sangat praktis. Kita ingin mengimpor data transaksi e-commerce dari file CSV yang sama, membersihkan data yang berantakan, menghitung beberapa agregasi bisnis, lalu menyimpan hasil akhir ke file baru yang bersih.
Alih-alih menulis semua arsitektur boilerplate itu sendiri, Anda dapat menggunakan Codex CLI untuk membuat kerangka keseluruhannya dari deskripsi tingkat tinggi.
Langkah pertama adalah menyiapkan struktur proyek yang sebenarnya. Pipeline data yang baik dipecah menjadi file terpisah agar mudah dibaca dan dipelihara di kemudian hari. Anda dapat meminta agen Codex melakukan pekerjaan berat ini. Di terminal, Anda akan memberinya prompt seperti ini:
Create a project layout for an ETL pipeline. I need separate Python modules for extraction, transformation, and loading, plus a main entry point script to run them all.Codex akan membuat file-file tersebut langsung di direktori Anda. Jika Anda melihat pohon file setelah menyetujui tindakan, Anda akan melihat arsitektur yang bersih dan profesional seperti ini:
etl_pipeline/
├──__init__.py
├── extract.py
├── transformation.py
└── loading.py
– run_etl.pyAlasan Codex memilih arsitektur ini adalah karena memisahkan concern dalam kode Anda. Logika pembacaan data berada terpisah dari logika matematika dan bisnis, yang memang seharusnya demikian menurut praktik terbaik rekayasa data.
Sekarang, mari kita uraikan transformasi yang kita inginkan untuk data kita. Dalam pipeline ETL, logika transformasi biasanya yang paling sulit, tetapi kita bisa meminta Codex menangani detailnya. Misalnya kita perlu membersihkan beberapa nilai hilang dan menghitung tepat berapa banyak uang yang dihasilkan setiap pesanan.
Anda dapat mengetik prompt langsung ke CLI yang menyatakan:
In transformation.py, write a function that takes the transactions data, drops any rows where the user ID is missing, and creates a new derived column called 'revenue' by multiplying the 'quantity' column by the 'unit_price' column.Karena Codex dapat membaca file transactions.csv Anda, ia mengetahui nama kolom yang sebenarnya. Ia tidak akan menebak dan menulis df['qty'] * df['price'] dan berharap yang terbaik. Ia akan melihat file Anda, mengetahui kolom Anda sebenarnya bernama quantity dan unit_price, dan menulis kode pandas yang tepat agar skrip tersebut berjalan.
Setelah kode dihasilkan, langkah terakhir adalah menjalankan pipeline end-to-end untuk memastikan semuanya berfungsi. Anda dapat memberi tahu Codex, "Jalankan skrip run_etl.py."
Saat berjalan, Anda akan melihat semua output terminal dicetak tepat di depan Anda, dan mungkin terlihat seperti ini:
File processed_transactions.csv baru seharusnya terlihat seperti ini:
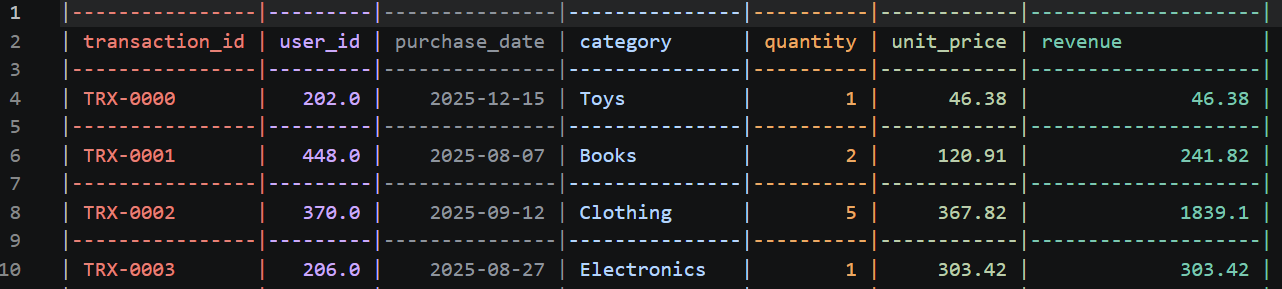
Dalam dunia nyata, hal-hal bisa gagal. Mungkin ada nilai string aneh yang tersembunyi di dalam kolom numerik, menyebabkan TypeError. Jika itu terjadi, Anda tidak perlu panik atau menyalin-tempel error ke peramban web. Codex CLI akan otomatis menangkap error tersebut, membaca traceback Python, dan sering kali memperbaiki kodenya sendiri dengan mengusulkan perbaikan saat itu juga.
Ini benar-benar menyoroti loop inti iteratif saat bekerja dengan agen pengodean AI:
Ini adalah loop kolaboratif berkelanjutan yang membangun perangkat lunak yang berfungsi jauh lebih cepat daripada mengetik semuanya secara manual.
Menguji kode Anda sangat krusial agar Anda tidak secara tidak sengaja merusak sesuatu di produksi, namun ini tetap menjadi langkah yang hampir selalu dilewati.
Menulis pengujian itu melelahkan, terutama saat Anda hanya menginginkan wawasan cepat dari dataset baru; menghentikan semuanya untuk menulis unit test terasa seperti pekerjaan berat. Namun dengan Codex CLI tepat di terminal Anda, hambatan itu pada dasarnya hilang.
Jika Anda ingin menghasilkan pengujian untuk kode transformasi yang baru saja kita tulis di bagian sebelumnya, Anda bahkan tidak perlu meninggalkan terminal atau membuka file kosong. Kita dapat menggunakan framework pengujian Python standar seperti pytest. Anda dapat melakukannya dengan memberikan Codex prompt sederhana seperti ini:
Write high-quality, maintainable pytest tests for the transform module. Test null handling, extreme edge cases like zeroes or negative values, type casting, and revenue calculation.Codex akan kembali melihat file transformation.py yang dibuat sebelumnya. Ia membaca logika Anda, memahami apa yang seharusnya dilakukan fungsi-fungsi tersebut, lalu menghasilkan file pengujian baru untuk Anda. Di bawah ini adalah apa yang mungkin Anda lihat di terminal setelah Codex selesai membuat pengujian tersebut.
Dalam kasus saya, ia menghasilkan skrip test_transformation.py baru di dalam folder tests, yang bertugas memeriksa apakah fungsi transformasi yang ditetapkan berjalan dengan benar.
Codex tidak hanya menulis assertion generik, tetapi juga membuat input data sintetis kecil synthetic data (disebut fixture) untuk dimasukkan ke fungsi Anda guna melakukan stress test. Ia dengan sengaja membuat kasus tepi, seperti baris dengan ID pengguna hilang seluruhnya atau kuantitas pembelian negatif, hanya untuk memastikan logika transformasi Anda menangani skenario aneh dan rusak tersebut secara tangguh dan benar.
Sekarang, menguji kode Python itu satu hal, tetapi sebagai profesional data, kita juga perlu menguji data yang mengalir melalui kode tersebut. Ini biasanya disebut validasi data. Anda ingin menghasilkan assertion nyata yang memeriksa kualitas keseluruhan data sebelum Anda menyerahkannya ke pemangku kepentingan atau memuatnya ke dasbor.
Anda dapat mendemonstrasikan ini dengan meminta Codex membuat skrip validasi data khusus. Cukup ketik prompt seperti:
Create a data validation script that runs after the very end of the pipeline. It should check that the schema matches our expectations, ensure the null-percentage for user_id is exactly 0%, and verify that all revenue values are greater than or equal to zero.Codex kemudian akan menghasilkan skrip validasi khusus yang bertindak sebagai jaring pengaman terakhir untuk proyek Anda. Anda dapat dengan mudah mengonfigurasinya agar berjalan sebagai langkah pasca-akhir dari pipeline Anda.
Dengan demikian, jika struktur data CSV mentah tiba-tiba berubah besok, atau jika gangguan aneh menyebabkan nilai pendapatan negatif muncul entah dari mana, skrip ini akan menangkapnya dan langsung melempar error. Ini memastikan pipeline Anda tidak diam-diam meneruskan data buruk ke pengguna bisnis Anda.
Sejauh ini, kita sebagian besar melihat cara menggunakan Codex CLI secara interaktif, dengan mengetik bolak-balik. Namun bagi profesional data yang benar-benar ingin mengintegrasikan alat ini ke dalam alur kerja harian mereka, ada pola penggunaan yang lebih lanjut yang pada dasarnya dapat mengatur pekerjaan membosankan Anda ke mode otomatis.
Jupyter Notebook sangat fantastis untuk bermain-main dengan data dan melakukan eksplorasi awal, tetapi cukup buruk saat tiba waktunya menjalankan kode itu secara andal di produksi. Biasanya, Anda harus menghabiskan waktu berjam-jam menyalin sel secara manual, menempelkannya ke file Python, dan memperbaiki semua masalah variabel global yang aneh.
Dengan Codex CLI, Anda bisa langsung menunjuk agen ke notebook Anda dan memintanya melakukan pekerjaan berat untuk Anda. Buka terminal dan ketik prompt persis seperti ini:
Refactor analysis.ipynb into a modular Python package with separate files for data loading, transformation, visualization, and a main.py entry point.Saat Anda menyetujuinya, Codex membaca struktur JSON file notebook Anda, mengekstrak kode Python yang sebenarnya, mengabaikan log output acak, dan menata ulang seluruhnya.
Jika Anda melihat struktur sebelum dan sesudah, perbedaannya sangat besar. Sebelum, Anda hanya memiliki satu file analysis.ipynb raksasa di mana semuanya tercampur.
Setelah Codex selesai, Anda akan melihat folder yang bersih dan profesional dengan file data_loader.py, transformer.py, dan visualizer.py terpisah (namanya mungkin berbeda bagi Anda), semuanya diikat rapi oleh skrip main.py. Ini langsung menjembatani kesenjangan antara analisis data eksploratori yang berantakan dan rekayasa perangkat lunak yang siap produksi.
Terkadang Anda tidak ingin duduk dan berinteraksi dengan antarmuka chat sama sekali. Jika Anda membangun pipeline otomatis, seperti pemeriksaan otomatis yang berjalan tepat sebelum Anda membagikan kode dengan tim, Anda memerlukan AI yang hanya bekerja di latar belakang, sepenuhnya otomatis.
Di situlah perintah codex exec berperan. Perintah ini dirancang khusus untuk menjalankan Codex dalam skrip dan lingkungan non-interaktif tanpa meminta izin Anda di setiap langkah.
Untuk memberi contoh praktis cara menggunakannya, mari kita jalankan uji cepat. Kita dapat menggunakan codex exec sebagai pemeriksaan CI/CD simulasi untuk menangkap/memvalidasi data buruk secara otomatis.
Buka terminal dan ketik perintah berikut persis:
codex exec --skip-git-repo-check "Read transactions.csv. Write and run a quick python script to check if the 'quantity' column contains any negative numbers. If it does, print 'DATA VALIDATION FAILED: Negative quantities detected.' If it is clean, print 'DATA VALIDATION PASSED'." 2> /dev/nullSaat Anda menekan enter, Codex akan berjalan secara non-interaktif. Ia tidak akan membuka antarmuka chat interaktif biasa, dan perilaku persetujuan bergantung pada flag persetujuan dan default yang dikonfigurasi; Anda mungkin tetap perlu mengizinkan tindakan tertentu kecuali Anda menonaktifkan persetujuan. Untuk informasi selengkapnya, saya sarankan membaca Dokumentasi Codex.
Ia akan dengan cepat menulis skrip validasi, mengeksekusinya terhadap file CSV lokal Anda, lalu mencetak hasil akhir langsung ke output terminal standar Anda selama direktori diperlakukan sebagai tepercaya dan persetujuan dikonfigurasi untuk mengizinkan ini. Anda akan melihat output tercetak di konsol yang terlihat seperti ini:
Pernyataan ini memiliki banyak kasus penggunaan. Bayangkan menggunakan perintah ini apa adanya dalam pre-commit hook atau workflow GitHub Actions. Jika pipeline Anda menemui data yang kehilangan kolom, memiliki nilai NaN, atau perilaku tak terduga lainnya, Codex dapat menangkapnya saat itu juga, tanpa Anda harus menulis skrip PyTest dan validasi tersebut secara manual.
Saat Anda menggunakan alat AI untuk pekerjaan data, cara Anda berinteraksi dengan agen sepenuhnya mengubah kualitas kode Python yang Anda dapatkan. Mari lihat beberapa praktik terbaik agar alur kerja Anda tetap lancar dan profesional.
Hal pertama yang perlu dikuasai adalah menulis prompt yang efektif. Anda tidak bisa hanya mengatakan kepada AI untuk "membersihkan data" dan mengharapkan hasil sempurna. Berikut cara Anda harus menyusun permintaan:
Spesifik: Anda harus spesifik tentang nama kolom yang sebenarnya, tipe data yang diinginkan, dan format output yang Anda cari. Misalnya, alih-alih permintaan yang samar, Anda harus secara eksplisit mengatakan, "ubah tipe kolom 'purchase_date' menjadi datetime dan keluarkan CSV teringkas."
Referensikan file secara langsung: Trik yang sangat berguna adalah mereferensikan file Anda langsung menggunakan sintaks @ dalam prompt. Jika Anda mengetik @transactions.csv, itu memaksa Codex membaca file spesifik tersebut langsung ke dalam konteksnya saat itu juga.
Pecah tugas kompleks: Barangkali yang paling penting, Anda harus selalu mencoba memecah tugas menjadi unit yang lebih kecil daripada membiarkan Codex bertindak berdasarkan satu mega-prompt. Menggunakan mode rencana khusus Codex untuk terlebih dahulu membuat draf lalu mengeksekusinya langkah demi langkah adalah cara tepat untuk tugas kompleks.
Jika Anda ingin meningkatkan kemampuan membuat prompt ke tingkat berikutnya, saya merekomendasikan mengikuti kursus Prompt Engineering with the OpenAI API kami.
Seperti yang telah disinggung sebelumnya, CLI memiliki mode persetujuan berbeda, dan mengetahui kapan menggunakan masing-masing mode itu penting. Berikut panduan kapan Anda sebaiknya menggunakan mode mana:
Terakhir, menjaga alur kerja data agar dapat direproduksi sangat penting bagi profesional data mana pun. Salah satu aturan terbesar yang harus Anda ikuti adalah selalu jalankan Codex di dalam repositori Git yang telah diinisialisasi. Karena Codex akan menulis dan mengedit file di mesin Anda, memiliki Git yang melacak perubahan tersebut berarti Anda dapat dengan mudah melihat tepat apa yang dilakukan AI dan membatalkannya jika terjadi kesalahan.
Anda juga harus memastikan untuk melakukan commit file AGENTS.md yang kita buat sebelumnya bersama kode proyek Anda. Dengan begitu, jika ilmuwan data lain di tim Anda meng-klone repositori dan membuka Codex, seluruh tim mendapatkan manfaat dari standar pengodean dan instruksi yang sama persis.
Hal yang sama berlaku untuk agent skills apa pun yang Anda definisikan untuk tugas individual. Untuk inspirasi, lihat panduan kami tentang lebih dari seratus top agent skills untuk Codex dan alat pengodean agensial lainnya.
Dan jika Anda mengerjakan analisis berat selama beberapa hari, Anda tidak perlu memulai dari awal setiap pagi. Anda cukup menggunakan perintah codex resume di terminal untuk melanjutkan proyek data multi-sesi. Ini memuat kembali ke chat sebelumnya, tanpa kehilangan konteks berharga tentang apa yang Anda dan agen lakukan kemarin.
Jika Anda mengerjakan analisis berat selama beberapa hari, Anda tidak perlu memulai dari awal setiap pagi. Anda cukup menggunakan perintah codex resume di terminal untuk melanjutkan proyek data multi‑sesi. Ini membuka kembali sesi Codex terakhir Anda di proyek tersebut sehingga Anda dapat melanjutkan dari titik terakhir, dengan percakapan, rencana, dan perubahan file sebelumnya tetap dalam konteks (tergantung batas model dan riwayat normal).
Untuk lebih banyak praktik terbaik dalam pengodean agensial, Anda juga dapat melihat panduan kami Claude Code Best Practices. Meskipun Claude Code dan Codex berbeda, seperti yang kami soroti dalam perbandingan Codex vs Claude Code, banyak konsep dasarnya juga berlaku untuk Codex.
Kita menyiapkan Codex CLI khusus untuk pekerjaan data Anda dan lingkungan Python lokal Anda. Dari sana, kita menelusuri pembuatan skrip analisis data eksploratori awal dari nol, membangun pipeline data ETL yang dapat direproduksi, menulis pengujian transformasi otomatis (yang terlalu sering dilewatkan), dan akhirnya menjelajahi cara lanjutan untuk mengotomatisasi tugas data harian yang sangat berulang.
Bagian terpenting untuk diingat adalah kita melakukan semuanya langsung dari command line, sepenuhnya tanpa bolak-balik ke peramban web. Codex CLI secara efektif menjembatani kesenjangan yang membuat frustrasi antara analisis data eksploratori yang berantakan dan rekayasa data berkualitas produksi yang sesungguhnya.
Jika Anda tertarik mempelajari cara membangun agen yang lebih kompleks dengan Codex CLI, saya merekomendasikan Anda mengikuti Tutorial Codex CLI MCP kami. Tutorial ini memandu Anda membuat agen dasbor portofolio keuangan.
Kursus AI
Program
Kursus
Kursus
blogs
Javier Canales Luna
14 mnt
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
