

Programa
Fundamentos de agentes de IA
6 h
Se você trabalha com dados, provavelmente lida com várias tarefas repetitivas de código no dia a dia. Coisas como fazer o perfil de novos conjuntos de dados, construir pipelines de dados do zero ou escrever testes de transformação manualmente. Tudo isso é necessário, mas consome um bom tempo.
E se o seu terminal pudesse cuidar e escrever todo esse código boilerplate por você, enquanto você foca sua energia em ideias e decisões? É aí que entra o Codex-CLI da OpenAI. Ele é um agente de codificação com IA, bem poderoso, integrado diretamente à sua linha de comando e, como veremos, é ótimo para agilizar fluxos de trabalho em dados.
Neste tutorial, vamos ver como analistas e cientistas de dados podem usar o Codex-CLI para acelerar as tarefas mais comuns do dia a dia. Vamos cobrir de tudo: desde a análise exploratória inicial até a construção de pipelines completos de dados e a criação de testes automatizados para suas transformações — tudo pelo terminal.
Se quiser saber mais sobre como construir sistemas de IA agentic, recomendo muito se inscrever na nossa trilha de habilidades AI Agent Fundamentals, que cobre tudo o que você precisa.
Antes de mais nada, vamos entender o Codex CLI. No essencial, o Codex CLI é um agente de codificação open-source, baseado em terminal, desenvolvido pela OpenAI.
Ele é construído em Rust, o que o torna rápido e eficiente. Mas o ponto mais importante é que ele opera direto na sua linha de comando, o que dá a ele a capacidade de ler seus arquivos, editar seu código e até executar comandos localmente na sua máquina.
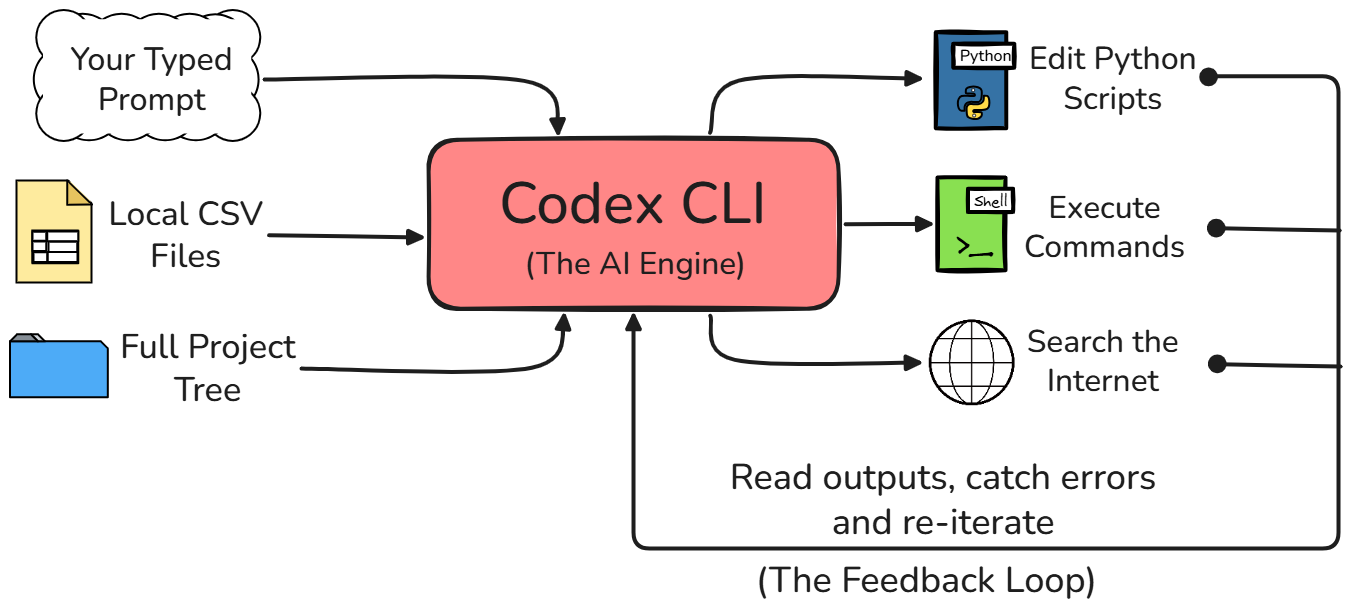
Embora você já possa estar acostumado a usar a interface web do ChatGPT no trabalho, o Codex CLI é bem diferente. Na interface web, o modelo de IA fica completamente isolado do ambiente onde você trabalha.
Com o Codex CLI, o agente tem acesso direto ao seu sistema de arquivos local. Ele pode executar scripts Python, ver a saída ou os erros retornados, e mantém consciência total da estrutura do seu projeto, sem você precisar explicar tudo antes.
|
Etapa do fluxo / Recurso |
ChatGPT (navegador) |
Codex CLI (terminal) |
|
Acesso a dados |
Você precisa abrir o CSV manualmente e copiar/colar algumas linhas no chat para ajudar o modelo a entender. |
Ele abre e lê seu CSV diretamente do sistema de arquivos local. |
|
Execução de código |
Você copia o script gerado, cola no seu editor e executa por conta própria. |
Ele escreve o script Python necessário, executa e mostra a saída final no próprio terminal. |
|
Experiência geral |
Exige muito vai e vem cansativo, copiando e colando entre janelas. |
Tudo acontece em um único fluxo contínuo e simples dentro do terminal. |
Claro que, como o agente Codex pode editar arquivos e executar comandos na sua máquina, ele traz modos de aprovação diferentes para garantir que você continue no controle. Os três modos são:
Ao começar, recomendo iniciar em somente leitura e ir avançando conforme você confia no fluxo.
Você pode alternar os modos de aprovação em uma sessão ativa do Codex usando /permissions. É a forma mais simples de passar de somente leitura para Auto quando estiver confortável.
/permissionsSe quiser iniciar o Codex em um modo mais restrito desde o começo, você pode definir os flags de sandbox e política de aprovação ao lançá-lo. Por exemplo, este comando inicia em um setup conservador de somente leitura que ainda solicita confirmação quando necessário.
codex --sandbox read-only --ask-for-approval on-requestHá alguns pré-requisitos para você acompanhar corretamente o tutorial.
Primeiro, você precisa instalar o Codex CLI na sua máquina. Para isso, abra o terminal e instale a CLI globalmente no seu sistema com este comando:
npm install -g @openai/codexO próximo passo é autenticar sua conta, para a ferramenta saber quem você é. Você pode verificar se tudo foi instalado corretamente e lançar o agente pela primeira vez digitando codex no terminal. Ele vai mostrar algo assim:
Ao pressionar Enter, abrirá uma janela no navegador pedindo para você fazer login com sua conta do ChatGPT. Depois do login, a ferramenta estará pronta para uso.
Se você não tiver uma assinatura paga do ChatGPT e quiser usar uma chave de API, há a opção de pagamento por uso. Você pode obter uma chave no console da OpenAI.
Antes de pedir para a IA fazer análises, é importante configurar corretamente o ambiente de dados em Python. Isso é essencial porque o Codex CLI opera dentro do ambiente em que está sendo executado. Então, se o agente precisar escrever um script que usa bibliotecas como pandas, scikit-learn ou matplotlib, você precisa garantir que essas libs estejam instaladas e disponíveis.
Podemos fazer isso ativando um ambiente virtual de Python antes de lançar o Codex. Aqui vai um script de setup com os comandos exatos que você pode rodar no terminal para criar um ambiente virtual, instalar os pacotes necessários, ativá-lo e então iniciar o agente:
python3 -m venv data_env
source data_env/bin/activate
pip install pandas scikit-learn matplotlib
codexMais um passo importante é criar um arquivo chamado AGENTS.md na pasta principal do projeto. Pense nesse arquivo como um conjunto de instruções persistentes que o agente Codex lê automaticamente toda vez que abre seu projeto. Ele indica como você quer que a IA se comporte e como quer que escreva código para esse workspace específico.
Para trabalhos com dados, queremos garantir que o código gerado pela IA seja limpo, legível e profissional. Aqui está um exemplo de arquivo AGENTS.md feito sob medida para um projeto de dados. Você pode criar esse arquivo e colar o texto abaixo:
# Data Project Guidelines
When writing Python code for this project, please strictly follow these rules:
- Enforce PEP 8 formatting standards for all Python code.
- Always use highly descriptive variable names. Do not use generic, lazy names like df, data, x, or y. Instead, use specific names like transaction_data or revenue_series.
- Prefer pandas best practices, such as using vectorized operations instead of iterating through rows.
- Generate clear, descriptive docstrings for every single function.
- Always include Python type hints for function arguments and return values.Como esse arquivo será lido sempre, independente da tarefa, é boa prática mantê-lo conciso e focar nas instruções que valem para qualquer prompt. Para instruções mais específicas, use skills.
Agora, partindo para o trabalho de dados em si, vamos começar com a análise exploratória (EDA). Como você já sabe, quase sempre esse é o ponto de partida de qualquer novo projeto de dados. Antes de construir modelos ou pipelines, você precisa entender como seus dados são.
A boa notícia é que, com o Codex CLI, um único prompt em linguagem natural pode gerar um script completo de EDA para você.
O cenário: para os exemplos de hoje, vamos imaginar um dataset sintético realista. Digamos que temos um conjunto de dados de e-commerce chamado transactions.csv na pasta do projeto, com dados de negócio como IDs de pedido, IDs de usuário, timestamps de compra e valores de transação.
Ao receber um arquivo novo, a primeira coisa é fazer o profiling para entender a estrutura básica. Em vez de escrever o boilerplate do pandas, você pode simplesmente abrir o terminal, onde sua sessão do Codex está rodando, e digitar um prompt assim:
Profile the transactions.csv file. Show shape, dtypes, missing values, and summary statistics.Ao apertar Enter, o Codex lê as primeiras linhas do seu arquivo transactions.csv direto do sistema de arquivos local. Em seguida, ele gera um script Python completo para fazer o profiling e, no modo "suggest", pergunta se você quer rodá-lo.
Você verá imediatamente o shape dos dados, os tipos das colunas do seu e-commerce e quantos valores ausentes existem (exemplo abaixo), tudo isso sem escrever uma linha de código.
Números no terminal são ótimos, mas em algum momento você precisa ver os dados visualmente. Dá para gerar visualizações surpreendentemente complexas apenas descrevendo o que você quer em inglês simples.
Por exemplo, se você quer uma visão geral do seu negócio de e-commerce, pode dar ao Codex um prompt assim:
Create a matplotlib dashboard with 3 subplots showing revenue by month, product categories ranked by sales, and order distribution by day of week.É um pedido bem complexo. Mas o Codex vai analisar o prompt e o seu arquivo de dados, descobrir como agrupar datas e somar a receita, criar um plano passo a passo e transformar isso em um script robusto em matplotlib para gerar exatamente esses subplots.
Aqui vai um ponto crucial ao trabalhar com agentes de IA: o processo é inerentemente iterativo. Quando o Codex sugerir a primeira versão do código de visualização, vale a pena aprovar e ver como ficou.
Talvez o gráfico seja gerado, mas os rótulos do eixo x fiquem sobrepostos ou as cores muito fortes. Você não precisa abrir o script e ajustar os parâmetros do matplotlib manualmente.
Basta responder com um prompt de continuação, algo como: "Os rótulos de baixo estão sobrepostos, gire 45 graus e deixe as cores da legenda mais suaves." O Codex refina o script, roda novamente e entrega um dashboard atualizado e polido.
Depois de explorar seus dados e fazer a análise inicial, você vai precisar sair dos scripts soltos e ad hoc.
O ideal é caminhar para um código real, reprodutível e modular. No mundo de dados, isso geralmente significa construir um pipeline de ETL (Extract, Transform, Load). É o padrão para trazer os dados, limpá-los e salvar resultados para uso posterior.
Para mostrar como funciona, vamos usar um cenário prático. Queremos ingerir os mesmos dados de transações do CSV, limpar dados problemáticos, calcular agregações de negócio e salvar o resultado final em um arquivo novo e limpo.
Em vez de escrever toda essa arquitetura boilerplate, você pode usar o Codex CLI para criar o esqueleto a partir de uma descrição de alto nível.
O primeiro passo é montar a estrutura do projeto. Um bom pipeline de dados é dividido em arquivos separados, para facilitar leitura e manutenção. Você pode pedir para o Codex fazer esse trabalho pesado. No terminal, envie um prompt assim:
Create a project layout for an ETL pipeline. I need separate Python modules for extraction, transformation, and loading, plus a main entry point script to run them all.O Codex vai criar esses arquivos no seu diretório. Ao ver a árvore de arquivos após aprovar a ação, você verá uma arquitetura limpa e profissional, algo como:
etl_pipeline/
├──__init__.py
├── extract.py
├── transformation.py
└── loading.py
– run_etl.pyO motivo dessa arquitetura é separar responsabilidades. A lógica de leitura de dados fica separada da lógica de negócio e matemática — exatamente como engenheiros de dados estruturam seu trabalho.
Agora vamos descrever a transformação que queremos. Em um pipeline ETL, a transformação costuma ser a parte mais difícil, mas podemos simplesmente pedir para o Codex cuidar dos detalhes. Digamos que precisamos remover valores ausentes e calcular quanto dinheiro cada pedido gerou.
Você pode digitar no CLI um prompt dizendo:
In transformation.py, write a function that takes the transactions data, drops any rows where the user ID is missing, and creates a new derived column called 'revenue' by multiplying the 'quantity' column by the 'unit_price' column.Como o Codex pode ler seu transactions.csv, ele sabe os nomes reais das colunas. Ele não vai chutar e escrever df['qty'] * df['price'] esperando dar certo. Ele vai ver que as colunas se chamam quantity e unit_price e escrever o código exato em pandas para a transformação funcionar.
Depois do código gerado, o passo final é rodar o pipeline de ponta a ponta para garantir que funciona. Você pode simplesmente dizer ao Codex, "Run the run_etl.py script."
Ao executar, você verá toda a saída no terminal, algo como:
O novo processed_transactions.csv deve ficar algo assim:
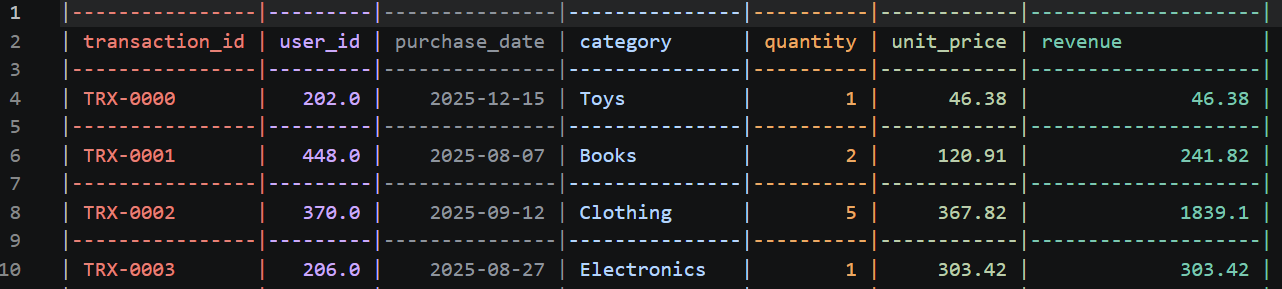
No mundo real, coisas quebram. Talvez exista uma string estranha escondida em uma coluna numérica causando um TypeError. Se isso acontecer, não precisa entrar em pânico ou copiar/colar o erro no navegador. O Codex CLI captura o erro, lê o traceback do Python e, muitas vezes, corrige o próprio código propondo um ajuste na hora.
Isso destaca o loop iterativo central de trabalhar com um agente de codificação com IA:
É um ciclo contínuo e colaborativo que constrói software funcional muito mais rápido do que digitar tudo à mão.
Testar seu código é absolutamente crítico para você não quebrar nada em produção, mas ainda é a etapa que quase sempre é pulada.
Escrever testes é trabalhoso, especialmente quando você só quer insights rápidos de um novo dataset; parar tudo para escrever unit tests parece um trampo enorme. Mas ter o Codex CLI no terminal praticamente remove essa barreira.
Se você quiser gerar testes para a transformação que escrevemos na seção anterior, nem precisa sair do terminal ou abrir um arquivo em branco. Podemos usar um framework padrão como o pytest. Basta dar ao Codex um prompt simples como:
Write high-quality, maintainable pytest tests for the transform module. Test null handling, extreme edge cases like zeroes or negative values, type casting, and revenue calculation.O Codex volta ao arquivo transformation.py criado anteriormente. Lê sua lógica, entende o propósito das funções e gera um novo arquivo de testes para você. Abaixo está um exemplo do que pode aparecer no terminal depois que o Codex terminar de gerar os testes.
No meu caso, ele gerou um novo script test_transformation.py dentro de uma pasta tests, para verificar se as funções de transformação fizeram o trabalho corretamente.
O Codex não escreve apenas asserções genéricas — ele cria entradas pequenas de dados sintéticos (fixtures) para alimentar suas funções e estressá-las. Ele cria de propósito casos de borda, como linhas com user IDs totalmente ausentes ou quantidades negativas, para garantir que sua lógica de transformação lide com cenários estranhos e quebrados de forma robusta e correta.
Testar o código em si é uma coisa, mas como profissionais de dados, também precisamos testar os próprios dados que passam por ele. Isso é o que chamamos de validação de dados. Você quer gerar asserções que chequem a qualidade do dado antes de enviar para as partes interessadas ou carregar em um dashboard.
Você pode demonstrar isso pedindo ao Codex para gerar um script específico de validação de dados. Digite um prompt como:
Create a data validation script that runs after the very end of the pipeline. It should check that the schema matches our expectations, ensure the null-percentage for user_id is exactly 0%, and verify that all revenue values are greater than or equal to zero.O Codex vai gerar um script dedicado de validação que atua como uma última rede de segurança. Você pode configurá-lo para rodar como etapa final do pipeline.
Assim, se amanhã o CSV bruto mudar de estrutura ou um bug fizer aparecer valores de receita negativos do nada, esse script vai detectar e lançar um erro imediatamente. Ele garante que seu pipeline não deixe dados ruins passarem silenciosamente para os usuários de negócio.
Até aqui, vimos o uso do Codex CLI de forma interativa, trocando mensagens. Mas, para quem quer integrar a ferramenta ao fluxo de trabalho diário, há padrões mais avançados que praticamente colocam o trabalho chato no piloto automático.
Jupyter Notebooks são ótimos para explorar dados no início, mas são ruins quando chega a hora de rodar o código de forma confiável em produção. Normalmente, você passa horas copiando células, colando em arquivos Python e ajustando variáveis globais.
Com o Codex CLI, você pode simplesmente apontar o agente para o notebook e pedir para ele fazer o trabalho pesado. No terminal, digite um prompt exatamente assim:
Refactor analysis.ipynb into a modular Python package with separate files for data loading, transformation, visualization, and a main.py entry point.Ao aprovar, o Codex lê a estrutura JSON do notebook, extrai o código Python, ignora logs de saída aleatórios e reorganiza tudo.
Comparando o antes e depois, a diferença é grande. Antes, você tinha um único analysis.ipynb gigante com tudo misturado.
Depois, você verá uma pasta limpa e profissional com arquivos como data_loader.py, transformer.py e visualizer.py (os nomes podem variar), amarrados por um main.py. Isso fecha a lacuna entre a exploração bagunçada e um software pronto para produção.
Às vezes, você nem quer interagir com a interface de chat. Se você está construindo pipelines automatizados, como checks que rodam antes de compartilhar seu código com o time, precisa que a IA trabalhe em segundo plano, no piloto automático.
É aí que entra o comando codex exec. Ele foi feito para rodar o Codex em scripts e ambientes não interativos, sem pedir permissão a cada passo.
Para um exemplo prático, vamos rodar um teste rápido. Podemos usar o codex exec como um check de CI/CD simulado para detectar/validar dados ruins automaticamente.
No terminal, digite exatamente este comando:
codex exec --skip-git-repo-check "Read transactions.csv. Write and run a quick python script to check if the 'quantity' column contains any negative numbers. If it does, print 'DATA VALIDATION FAILED: Negative quantities detected.' If it is clean, print 'DATA VALIDATION PASSED'." 2> /dev/nullAo pressionar Enter, o Codex roda de forma não interativa. Ele não abre a interface de chat, e o comportamento de aprovação depende dos flags configurados e padrões; você ainda pode precisar permitir certas ações, a menos que desative aprovações. Para mais informações, recomendo ler a documentação do Codex.
Ele vai escrever rapidamente o script de validação, executá-lo contra seu CSV local e, em seguida, imprimir o resultado diretamente no seu terminal — desde que o diretório seja confiável e as aprovações permitam. Você deverá ver algo assim no console:
Esse comando tem muitos usos. Imagine rodá-lo como está em um pre-commit hook ou no GitHub Actions. Se o seu pipeline encontrar dados faltando coluna, com NaN ou qualquer comportamento inesperado, o Codex detecta na hora — sem você precisar escrever PyTest e scripts de validação manualmente.
Ao usar ferramentas de IA para dados, a forma como você interage com o agente muda totalmente a qualidade do código Python que volta. Veja algumas boas práticas para manter seu fluxo suave e profissional.
A primeira coisa para dominar é escrever bons prompts. Não dá para dizer apenas "clean the data" e esperar perfeição. Aqui está como estruturar seus pedidos:
Seja específico: Informe os nomes reais de colunas, os tipos de dados desejados e o formato de saída esperado. Em vez de um pedido vago, diga algo como "cast the 'purchase_date' column to datetime and output a summarized CSV."
Faça referência direta aos arquivos: Um truque útil é referenciar arquivos com a sintaxe @ no prompt. Se você digitar @transactions.csv, o Codex é forçado a ler esse arquivo específico no contexto naquele momento.
Quebre tarefas complexas: O mais importante é dividir tarefas grandes em partes menores, em vez de mandar um mega‑prompt. Usar o modo de plano do Codex para rascunhar e depois executar passo a passo é o caminho para tarefas complexas.
Se quiser levar seus prompts a outro nível, recomendo nosso curso Prompt Engineering with the OpenAI API.
Como mencionamos, a CLI tem modos de aprovação diferentes, e saber quando usar cada um é importante. Veja um guia:
Manter fluxos reprodutíveis é muito importante para qualquer profissional de dados. Uma das maiores regras é sempre rodar o Codex dentro de um repositório Git inicializado. Como o Codex vai escrever e editar arquivos na sua máquina, ter o Git rastreando as mudanças permite ver exatamente o que a IA fez e desfazer se algo der errado.
Também vale muito a pena versionar o arquivo AGENTS.md que criamos, junto com o código do projeto. Assim, se outro cientista de dados clonar seu repositório e abrir o Codex, todo o time se beneficia dos mesmos padrões e instruções.
O mesmo vale para quaisquer agent skills que você definiu para tarefas específicas. Para se inspirar, confira nosso guia com mais de cem top agent skills para o Codex e outras ferramentas agentic de código.
E se você estiver em uma análise pesada por vários dias, não precisa recomeçar toda manhã. É só usar o comando codex resume no terminal para continuar projetos multi‑sessão. Ele carrega sua conversa anterior sem perder o contexto do que você e o agente fizeram ontem.
Se estiver trabalhando em uma análise mais longa, você não precisa recomeçar todo dia. Use o comando codex resume no terminal para continuar projetos multi‑sessão. Ele reabre a última sessão do Codex naquele projeto, para você retomar de onde parou, com a conversa anterior, planos e mudanças de arquivo ainda em contexto (sujeito aos limites normais de modelo e histórico).
Para mais boas práticas de codificação agentic, confira também nosso guia Claude Code Best Practices. Embora Claude Code e Codex sejam diferentes, como mostramos na comparação Codex vs Claude Code, muitos conceitos básicos também se aplicam ao Codex.
Configuramos o Codex CLI especificamente para seu trabalho com dados e seus ambientes locais de Python. A partir daí, percorremos a geração de scripts de análise exploratória do zero, a construção de pipelines ETL reprodutíveis, a escrita de testes automatizados de transformação (que quase sempre são ignorados) e, por fim, formas avançadas de automatizar tarefas repetitivas do dia a dia.
O mais importante: fizemos tudo isso direto na linha de comando, sem ficar alternando com o navegador. O Codex CLI preenche aquela lacuna chata entre a análise exploratória bagunçada e a engenharia de dados com qualidade de produção.
Se você quer aprender a construir um agente mais complexo com o Codex CLI, recomendo nosso tutorial Codex CLI MCP. Ele mostra como criar um agente de dashboard de portfólio financeiro.
Cursos de IA
Programa
Curso
Curso
blog
Javier Canales Luna
9 min
Tutorial
Bex Tuychiev
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Dimitri Didmanidze

