

Programma
Nozioni di base sugli agenti AI
6 h
Se lavori con i dati, probabilmente gestisci ogni giorno molte attività di coding ripetitive. Cose come profilare dataset completamente nuovi, costruire pipeline di dati da zero o scrivere manualmente test per le trasformazioni. Tutto necessario, ma richiede un sacco di tempo.
E se il tuo terminale potesse gestire e scrivere per te tutto quel codice boilerplate ripetitivo, mentre tu concentri le energie su brainstorming e decisioni? È qui che entra in gioco Codex-CLI di OpenAI. È un agente di coding AI molto capace, integrato direttamente nella riga di comando e, come vedremo, è ottimo per snellire i workflow dei dati.
In questo tutorial, vedremo come analisti e scientisti dei dati possono usare Codex-CLI per velocizzare le attività quotidiane più comuni. Copriremo tutto: dall’analisi esplorativa iniziale alla costruzione di pipeline di dati complete, fino alla creazione di test automatici per le trasformazioni, il tutto direttamente dal terminale.
Se vuoi saperne di più sulla costruzione di sistemi di AI agentica, ti consiglio vivamente di iscriverti al nostro skill track AI Agent Fundamentals, che copre tutto ciò che devi sapere.
Partiamo da cosa sia Codex CLI. Alla base, Codex CLI è un agente di coding open‑source basato su terminale, sviluppato da OpenAI.
È costruito in Rust, il che lo rende piuttosto veloce ed efficiente. Ma la cosa più importante da capire è che opera direttamente nella tua riga di comando, il che gli consente di leggere i file, modificare il codice ed eseguire comandi localmente sulla macchina.
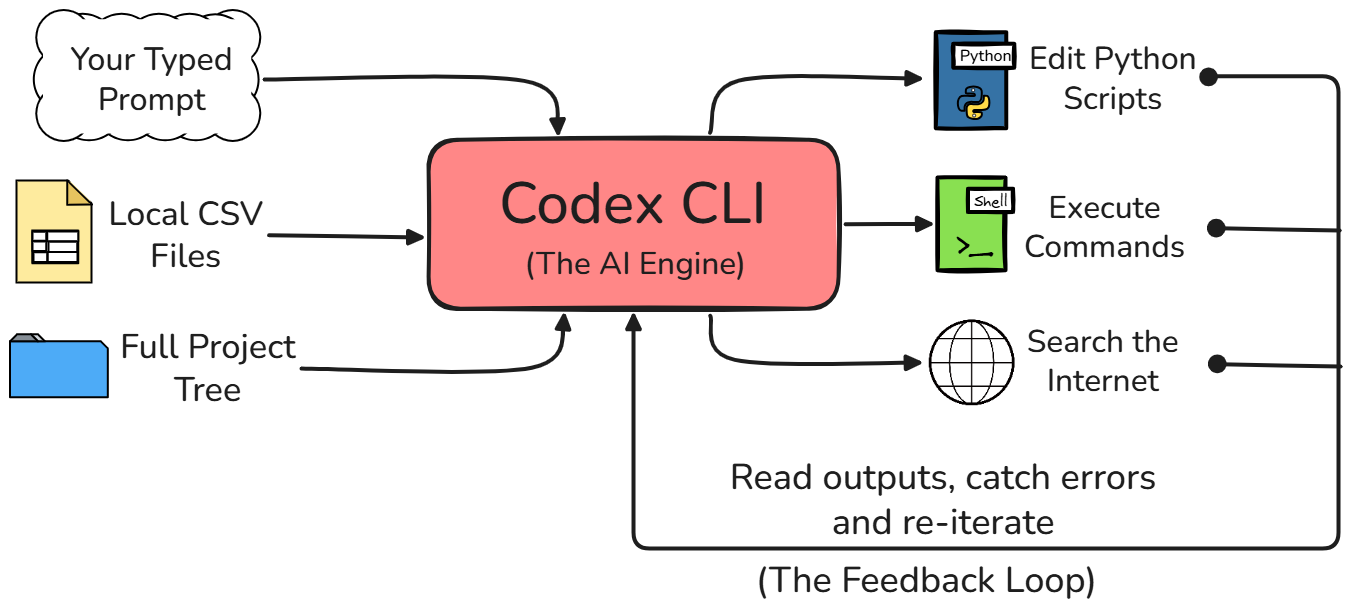
Anche se potresti essere abituato all’interfaccia web standard di ChatGPT per il tuo lavoro, Codex CLI è molto diverso. Quando usi l’interfaccia web, il modello AI è completamente isolato dall’ambiente in cui lavori.
Con Codex CLI, l’agente ha accesso diretto al file system locale. Può eseguire script Python, guardare l’output o eventuali errori restituiti e mantenere piena consapevolezza della struttura dell’intero progetto senza che tu debba spiegargli tutto prima.
|
Fase del workflow / Funzionalità |
ChatGPT (Browser) |
Codex CLI (Terminale) |
|
Accesso ai dati |
Devi aprire manualmente il tuo CSV e copiare‑incollare alcune righe di dati grezzi nella chat per aiutarlo a capire. |
Può aprire e leggere in autonomia il tuo CSV direttamente dal file system locale. |
|
Esecuzione del codice |
Devi copiare lo script generato, incollarlo nel tuo editor locale ed eseguirlo tu. |
Scrive automaticamente lo script Python necessario, lo esegue e ti mostra l’output finale direttamente nel terminale. |
|
Esperienza complessiva |
Comporta un continuo e gravoso copia‑incolla tra finestre. |
Tutto avviene in un unico flusso continuo e senza soluzione di continuità dentro il terminale. |
Ovviamente, poiché l’agente Codex può modificare direttamente i file ed eseguire comandi sulla tua macchina, sono previsti diversi modalità di approvazione per garantirti il controllo. Le tre modalità sono:
Quando inizi, ti consiglio di partire in Sola lettura, poi salire di livello quando ti fidi del workflow.
Puoi cambiare modalità di approvazione in una sessione Codex avviata usando /permissions. È il modo più semplice per passare da Sola lettura ad Auto quando sei a tuo agio.
/permissionsSe vuoi avviare Codex da subito in una modalità più restrittiva, puoi impostare i flag di sandbox e approvazione al lancio. Per esempio, questo avvia una configurazione prudente in sola lettura che comunque chiede quando serve.
codex --sandbox read-only --ask-for-approval on-requestCi sono alcuni prerequisiti che devi avere per seguire correttamente il tutorial.
Per prima cosa, devi installare Codex CLI sulla tua macchina. Per farlo, apri il terminale e installa la CLI globalmente sul sistema con questo comando:
npm install -g @openai/codexIl passo successivo è autenticare il tuo account, così lo strumento sa chi sei. Puoi verificare che sia tutto installato correttamente e avviare l’agente per la prima volta semplicemente digitando codex nel terminale. Ti mostrerà qualcosa del genere:
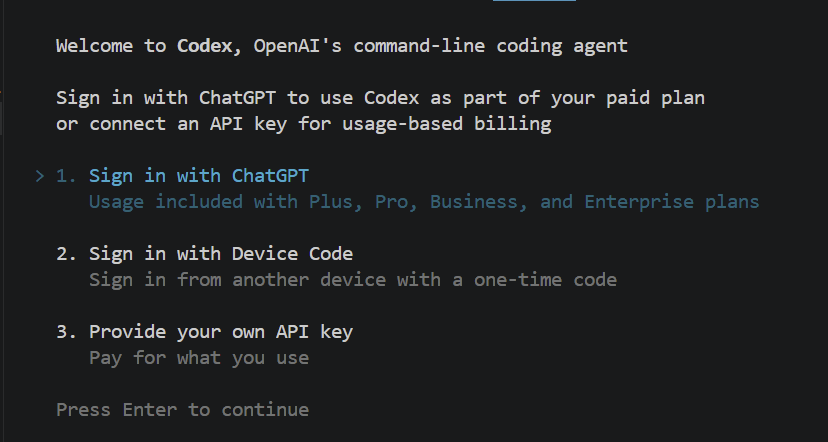
Dopo aver premuto Invio, si aprirà una finestra del browser dove ti verrà chiesto di accedere con l’account ChatGPT. Una volta effettuato l’accesso, sei pronto a usare lo strumento.
Se non hai un abbonamento ChatGPT a pagamento e vuoi usare una chiave API, c’è anche l’opzione pay‑per‑use. Puoi ottenere una chiave dalla console di OpenAI.
Prima di chiedere all’AI di fare analisi dei dati, è importante configurare correttamente l’ambiente dati Python. È essenziale perché Codex CLI opera dentro qualunque ambiente in cui viene avviato. Quindi, se l’agente deve scrivere uno script che usa librerie di data science come pandas, scikit-learn o matplotlib, devi assicurarti che siano installate e disponibili.
Possiamo farlo attivando un ambiente virtuale Python prima di lanciare Codex. Ecco uno script di setup di esempio con i comandi esatti da eseguire nel terminale per creare un ambiente virtuale, installare i pacchetti necessari, attivarlo e poi avviare l’agente:
python3 -m venv data_env
source data_env/bin/activate
pip install pandas scikit-learn matplotlib
codexUn altro passaggio importante nel setup del progetto è creare un file chiamato AGENTS.md nella cartella principale. Puoi considerarlo come un insieme di istruzioni persistenti che l’agente Codex legge automaticamente ogni volta che apre il progetto. Dice all’AI come vuoi che si comporti e come vuoi che scriva codice per questo workspace specifico.
Per il lavoro sui dati, vogliamo che il codice generato dall’AI sia pulito, leggibile e professionale. Ecco quindi un file AGENTS.md di esempio, pensato apposta per un progetto dati. Puoi semplicemente creare questo file e incollare il testo:
# Data Project Guidelines
When writing Python code for this project, please strictly follow these rules:
- Enforce PEP 8 formatting standards for all Python code.
- Always use highly descriptive variable names. Do not use generic, lazy names like df, data, x, or y. Instead, use specific names like transaction_data or revenue_series.
- Prefer pandas best practices, such as using vectorized operations instead of iterating through rows.
- Generate clear, descriptive docstrings for every single function.
- Always include Python type hints for function arguments and return values.Poiché questo file verrà letto ogni volta, indipendentemente dal compito, è buona pratica tenerlo conciso e concentrarsi solo su istruzioni che valgono per ogni prompt. Per istruzioni più specifiche, usa invece le skill.
Passiamo ora al lavoro sui dati vero e proprio, iniziando con l’analisi esplorativa, o EDA. Come saprai, è quasi sempre il punto di partenza per qualsiasi nuovo progetto dati. Prima di costruire modelli o pipeline, devi sapere com’è fatto il tuo dataset.
La cosa bella è che, con Codex CLI, un singolo prompt in linguaggio naturale può produrre per te uno script EDA completo e funzionante.
Lo scenario: per gli esempi di oggi, immaginiamo di lavorare con un dataset realistico e sintetico. Diciamo di avere un dataset e‑commerce chiamato transactions.csv proprio nella cartella del progetto. È pieno di dati di business realistici come ID ordine, ID utente, timestamp di acquisto e importi transazione.
Quando ricevi un nuovo file di questo tipo, la prima cosa da fare è profilarlo per capirne la struttura di base. Invece di scrivere tu il boilerplate di pandas, puoi aprire il terminale dove è in esecuzione Codex e digitare un prompt esattamente così:
Profile the transactions.csv file. Show shape, dtypes, missing values, and summary statistics.Premendo Invio, Codex leggerà le prime righe del tuo file transactions.csv direttamente dal file system locale. Genererà quindi uno script Python completo per il profiling e, in modalità “suggest”, ti chiederà se vuoi eseguirlo.
Vedrai subito la forma esatta dei dati, i tipi delle colonne specifiche del tuo e‑commerce e quanti valori mancanti devi gestire (esempio sotto), senza scrivere nemmeno una riga di codice.
I numeri nel terminale sono utili, ma prima o poi devi vedere i dati visivamente. Puoi generare visualizzazioni sorprendentemente complesse descrivendo in semplice inglese ciò che vuoi.
Per esempio, se vuoi una vista d’insieme del tuo business e‑commerce, potresti dare a Codex un prompt di questo tipo:
Create a matplotlib dashboard with 3 subplots showing revenue by month, product categories ranked by sales, and order distribution by day of week.È una richiesta piuttosto complessa. Ma Codex analizzerà sia il prompt sia il tuo file dati, capirà come raggruppare le date e sommare i ricavi, creerà un piano passo‑passo e lo trasformerà in uno script matplotlib robusto per generare proprio quei sottografici.
E qui c’è un punto cruciale quando lavori con agenti AI: per natura è un processo iterativo. Quando Codex propone la prima versione del codice di visualizzazione, approvala per vedere l’effetto.
Magari la prima versione genera il grafico, ma noti che le etichette sull’asse x si sovrappongono e sono difficili da leggere, o magari i colori sono troppo accesi. Non devi aprire lo script e sistemare a mano i parametri di matplotlib.
Ti basta inviare un prompt di follow‑up, per esempio: «Le etichette in basso si sovrappongono: ruotale di 45 gradi e rendi i colori della legenda più soft». Codex affinerà lo script, lo rieseguirà e ti darà la dashboard aggiornata e rifinita.
Una volta finita l’esplorazione iniziale, prima o poi dovrai allontanarti da script disordinati e ad hoc.
Quello che vuoi davvero è passare a codice reale, riproducibile e modulare. Nel mondo dei dati, questo di solito significa costruire una pipeline ETL (Extract, Transform, Load). È lo standard per acquisire i dati, ripulirli e salvare i risultati per usi successivi.
Per mostrarti come funziona, useremo uno scenario pratico. Vogliamo acquisire gli stessi dati di transazioni e‑commerce dal CSV, ripulire eventuali dati sporchi, calcolare alcune aggregazioni di business e poi salvare i risultati finali in un nuovo file pulito.
Invece di scrivere tu tutta quell’architettura boilerplate, puoi usare Codex CLI per generare l’intero scheletro da una descrizione ad alto livello.
Il primo passo è impostare la struttura del progetto. Una buona pipeline di dati è suddivisa in file separati, così è facile da leggere e manutenere. Puoi chiedere all’agente Codex di fare il lavoro pesante per te. Nel terminale, dagli un prompt come questo:
Create a project layout for an ETL pipeline. I need separate Python modules for extraction, transformation, and loading, plus a main entry point script to run them all.Codex creerà quei file direttamente nella tua directory. Se guardi l’albero dei file dopo aver approvato l’azione, vedrai un’architettura pulita e professionale simile a questa:
etl_pipeline/
├──__init__.py
├── extract.py
├── transformation.py
└── loading.py
– run_etl.pyIl motivo per cui Codex sceglie questa architettura è la separazione delle responsabilità. La logica di lettura dei dati vive separata dalla logica matematica e di business: esattamente come dovrebbero strutturare il lavoro i data engineer.
Descriviamo ora la trasformazione desiderata. Nelle pipeline ETL, la logica di trasformazione è spesso la parte più difficile, ma possiamo chiedere a Codex di occuparsene. Supponiamo di dover ripulire alcuni valori mancanti e calcolare quanto ha generato ciascun ordine.
Puoi digitare direttamente nella CLI un prompt come:
In transformation.py, write a function that takes the transactions data, drops any rows where the user ID is missing, and creates a new derived column called 'revenue' by multiplying the 'quantity' column by the 'unit_price' column.Poiché Codex può leggere il file transactions.csv, conosce i nomi reali delle colonne. Non si limiterà a indovinare scrivendo df['qty'] * df['price'] sperando nel meglio. Guarderà il file, vedrà che le colonne si chiamano quantity e unit_price, e scriverà il codice pandas esatto e corretto per far funzionare lo script.
Dopo aver generato il codice, l’ultimo passo è eseguire la pipeline end‑to‑end per verificare che funzioni. Puoi semplicemente dire a Codex, «Esegui lo script run_etl.py».
Quando verrà eseguito, vedrai tutto l’output del terminale stampato davanti a te, e potrebbe essere così:
Il nuovo processed_transactions.csv dovrebbe apparire così:
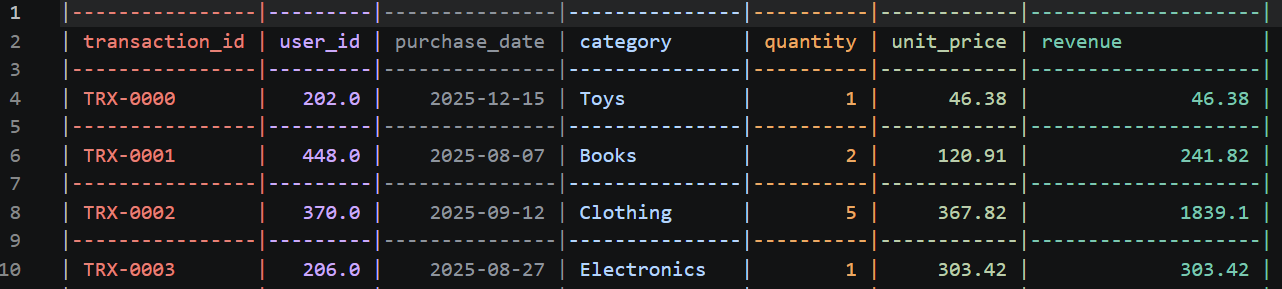
Nel mondo reale, le cose si rompono. Magari c’era una stringa strana nascosta in una colonna numerica, causando un TypeError. Se succede, non devi andare nel panico o copiare‑incollare l’errore nel browser. Codex CLI intercetterà automaticamente l’errore, leggerà il traceback di Python e spesso si autocorreggerà proponendo una fix sul momento.
Questo mette davvero in luce il ciclo iterativo di lavoro con un agente di coding AI:
È un loop continuo e collaborativo che costruisce software funzionante molto più velocemente che digitando tutto a mano.
Testare il codice è fondamentale per non rompere accidentalmente la produzione, ma è lo step che viene saltato più spesso.
Scrivere test è tedioso, soprattutto quando vuoi solo insight rapidi da un nuovo dataset; fermarsi a scrivere unit test sembra un’enorme scocciatura. Ma avere Codex CLI lì nel terminale elimina di fatto questa barriera.
Se vuoi generare test per la logica di trasformazione scritta nella sezione precedente, non devi nemmeno lasciare il terminale o aprire un file vuoto. Possiamo usare un framework standard come pytest. Fallo dando a Codex un semplice prompt come:
Write high-quality, maintainable pytest tests for the transform module. Test null handling, extreme edge cases like zeroes or negative values, type casting, and revenue calculation.Codex tornerà a guardare il file transformation.py creato prima. Legge la tua logica, capisce cosa dovrebbero fare le funzioni e genera un nuovo file di test per te. Qui sotto c’è cosa potresti vedere nel terminale dopo la generazione dei test.
Nel mio caso, ha generato un nuovo script test_transformation.py dentro una nuova cartella tests, con il compito di verificare che le funzioni designate di trasformazione facciano correttamente il loro lavoro.
Codex non scrive solo asserzioni generiche, ma crea input piccoli e sintetici molto realistici (chiamati fixture) da dare in pasto alle funzioni per metterle sotto stress. Crea intenzionalmente edge case, come righe con ID utente completamente mancanti o quantità di acquisto negative, per assicurarsi che la logica di trasformazione gestisca in modo robusto e corretto scenari strani o rotti.
Testare il codice Python è una cosa, ma come professionisti dei dati dobbiamo anche testare i dati che scorrono in quel codice. Di solito si parla di data validation. Vuoi generare vere asserzioni che controllino la qualità complessiva dei dati prima di passarli agli stakeholder o caricarli in una dashboard.
Puoi dimostrarlo chiedendo a Codex di generare uno specifico script di validazione dei dati. Scrivi un prompt del tipo:
Create a data validation script that runs after the very end of the pipeline. It should check that the schema matches our expectations, ensure the null-percentage for user_id is exactly 0%, and verify that all revenue values are greater than or equal to zero.Codex produrrà quindi uno script di validazione dedicato che funge da rete di sicurezza finale per il tuo progetto. Puoi configurarlo facilmente per l’esecuzione come step conclusivo della pipeline.
Così, se domani la struttura del CSV grezzo cambia improvvisamente, o un glitch fa apparire valori di ricavo negativi dal nulla, questo script lo intercetterà e lancerà subito un errore. Garantisce che la pipeline non faccia passare silenziosamente dati errati agli utenti business.
Finora abbiamo visto come usare Codex CLI in modo interattivo, scrivendo avanti e indietro. Ma per i professionisti dei dati che vogliono integrare davvero questo strumento nel flusso di lavoro quotidiano, ci sono pattern d’uso avanzati che possono mettere in pilota automatico il lavoro noioso.
Jupyter Notebook sono fantastici per esplorare i dati inizialmente, ma sono pessimi quando è il momento di eseguire quel codice affidabilmente in produzione. Di solito passi ore a copiare celle, incollarle in file Python e sistemare tutte le strane variabili globali.
Con Codex CLI, puoi letteralmente puntare l’agente al tuo notebook e chiedergli di fare il lavoro pesante. Apri il terminale e digita un prompt esattamente così:
Refactor analysis.ipynb into a modular Python package with separate files for data loading, transformation, visualization, and a main.py entry point.Una volta approvato, Codex legge la struttura JSON del notebook, estrae il codice Python reale, ignora i log di output casuali e riorganizza tutto.
Se guardi le strutture prima e dopo, sono molto diverse. Prima avevi un unico grande file analysis.ipynb dove tutto era intrecciato.
Dopo il lavoro di Codex, vedrai una cartella pulita e professionale con file separati come data_loader.py, transformer.py e visualizer.py (i nomi potrebbero variare), tutti collegati in modo ordinato da uno script main.py. Colma all’istante il divario tra la tua EDA disordinata e l’ingegneria del software pronta per la produzione.
A volte non vuoi interagire affatto con l’interfaccia di chat. Se stai costruendo pipeline automatizzate, come i controlli che girano prima di condividere il codice con il team, ti serve che l’AI faccia il suo lavoro in background, in totale autopilota.
È proprio qui che entra in gioco il comando codex exec. È progettato specificamente per eseguire Codex in script e ambienti non interattivi senza chiederti permesso a ogni singolo passaggio.
Per un esempio pratico, facciamo un test rapido. Possiamo usare codex exec come controllo CI/CD simulato per intercettare/validare automaticamente dati errati.
Apri il terminale e digita esattamente questo comando:
codex exec --skip-git-repo-check "Read transactions.csv. Write and run a quick python script to check if the 'quantity' column contains any negative numbers. If it does, print 'DATA VALIDATION FAILED: Negative quantities detected.' If it is clean, print 'DATA VALIDATION PASSED'." 2> /dev/nullPremendo Invio, Codex verrà eseguito in modo non interattivo. Non aprirà la solita interfaccia di chat, e il comportamento delle approvazioni dipende dai flag e dai default configurati; potresti comunque dover consentire alcune azioni a meno che tu non disabiliti le approvazioni. Per maggiori informazioni, ti consiglio di leggere la Documentazione di Codex.
Scriverà rapidamente lo script di validazione, lo eseguirà sul tuo CSV locale e poi sputerà il risultato finale direttamente sull’output standard del terminale purché la directory sia considerata attendibile e le approvazioni siano configurate per consentirlo. Dovresti vedere un output stampato in console simile a questo:
Questa istruzione ha molti casi d’uso. Immagina di usare questo comando così com’è in un pre‑commit hook o in un workflow di GitHub Actions. Se la tua pipeline incontra mai dati a cui manca una colonna, contiene valori NaN o presenta comportamenti inattesi, Codex può intercettarlo sul momento, senza che tu debba scrivere a mano tutti quegli script PyTest e di validazione.
Quando usi strumenti di AI per il lavoro sui dati, il modo in cui interagisci con l’agente cambia completamente la qualità del codice Python che ottieni. Vediamo alcune best practice per mantenere il workflow fluido e professionale.
La prima cosa da padroneggiare è scrivere prompt efficaci. Non puoi dire all’AI di «ripulire i dati» e aspettarti risultati perfetti. Ecco come dovresti strutturare le richieste:
Sii specifico: Devi essere specifico sui nomi reali delle colonne, i tipi di dati desiderati e il formato di output atteso. Per esempio, invece di una richiesta vaga, di’ esplicitamente qualcosa come: «casta la colonna 'purchase_date' a datetime e produci un CSV riassuntivo».
Riferisci i file direttamente: Un trucco molto utile è riferirti ai file direttamente con la sintassi @ nel prompt. Se digiti @transactions.csv, costringi Codex a leggere subito quello specifico file nel suo contesto.
Scomponi i compiti complessi: Soprattutto, prova a scomporre i task in unità più piccole invece di lasciare che Codex agisca su un mega‑prompt unico. Usare la modalità di pianificazione di Codex per creare prima una bozza e poi agire passo‑passo è la strada giusta per i compiti complessi.
Se vuoi portare il prompting al livello successivo, ti consiglio il nostro corso Prompt Engineering with the OpenAI API.
Come accennato, la CLI ha diverse modalità di approvazione, e sapere quando usare ciascuna è importante. Ecco una guida su quando usare quale modalità:
Infine, mantenere riproducibili i workflow è importantissimo per chi lavora con i dati. Una delle grandi regole è eseguire sempre Codex dentro un repository Git inizializzato. Poiché Codex scriverà e modificherà file sulla tua macchina, avere Git che traccia quei cambiamenti significa poter vedere facilmente cosa ha fatto l’AI e annullarlo se qualcosa va storto.
Assicurati anche di fare commit del file AGENTS.md creato prima insieme al codice del progetto. Così, se un altro data scientist del team clona il repository e apre Codex, tutto il team beneficia degli stessi standard e istruzioni.
Lo stesso vale per le eventuali skill degli agenti definite per singoli task. Per ispirazione, consulta la nostra guida con oltre cento top agent skills per Codex e altri strumenti di coding agentico.
E se stai lavorando a un’analisi pesante per diversi giorni, non devi ricominciare ogni mattina. Puoi semplicemente usare il comando codex resume nel terminale per continuare progetti dati multi‑sessione. Ricarica la chat precedente senza perdere il prezioso contesto di ciò che tu e l’agente stavate facendo ieri.
Se stai lavorando a un’analisi pesante per diversi giorni, non devi ricominciare ogni mattina. Puoi semplicemente usare il comando codex resume nel terminale per continuare progetti multi‑sessione. Riapre l’ultima sessione di Codex in quel progetto, così puoi riprendere da dove avevi lasciato, con conversazione, piani e modifiche ai file ancora in contesto (nei limiti normali del modello e della cronologia).
Per altre best practice di coding agentico, dai un’occhiata anche alla nostra guida Claude Code Best Practices. Sebbene Claude Code e Codex differiscano, come evidenziato nel nostro confronto Codex vs Claude Code, molti concetti di base si applicano anche a Codex.
Abbiamo configurato Codex CLI specificamente per il lavoro sui dati e per i tuoi ambienti Python locali. Da lì, abbiamo visto come generare da zero script di analisi esplorativa, costruire pipeline ETL riproducibili, scrivere test automatici per le trasformazioni (troppo spesso saltati) e, infine, esplorare modi avanzati per automatizzare le attività quotidiane più ripetitive.
La cosa più importante da ricordare è che abbiamo fatto tutto direttamente dalla riga di comando, senza saltare avanti e indietro tra browser e terminale. Codex CLI colma effettivamente quel fastidioso divario tra analisi esplorativa disordinata e vera data engineering di qualità produttiva.
Se ti interessa imparare a costruire un agente più complesso con Codex CLI, ti consiglio la nostra Codex CLI MCP Tutorial. Ti guida nella creazione di un agente per una dashboard di portafoglio finanziario.
Corsi di AI
Programma
Corso
Corso