

Lernpfad
KI-Agent-Grundlagen
6 Std.
Wenn du im Datenbereich arbeitest, erledigst du vermutlich täglich viele wiederkehrende Codieraufgaben. Zum Beispiel das Profiling völlig neuer Datasets, das Aufsetzen von Datenpipelines von Grund auf oder das manuelle Schreiben von Tests für Transformationen. Nötig, aber echte Zeitfresser.
Was aber, wenn dein Terminal all dieses Boilerplate für dich managen und schreiben könnte, während du dich auf Konzeption und Entscheidungen konzentrierst? Genau hier kommt OpenAIs Codex-CLI ins Spiel. Es ist ein sehr leistungsfähiger KI-Coding-Agent, direkt in deine Kommandozeile integriert, und wie wir sehen werden, ideal, um Daten-Workflows zu verschlanken.
In diesem Tutorial zeige ich, wie Data Analysts und Data Scientists Codex-CLI nutzen können, um ihre häufigsten täglichen Aufgaben zu beschleunigen. Wir behandeln alles vom ersten Exploratory Data Analysis über den Aufbau kompletter Datenpipelines bis hin zum Erstellen automatisierter Tests für deine Transformationen – alles direkt im Terminal.
Wenn du mehr über agentische KI-Systeme erfahren willst, empfehle ich dir unseren AI Agent Fundamentals-Lernpfad. Dort findest du alles, was du wissen musst.
Lass uns zuerst klären, was Codex CLI ist. Im Kern ist Codex CLI ein Open-Source, terminalbasierter Coding-Agent, entwickelt von OpenAI.
Er ist in der Programmiersprache Rust gebaut, was ihn schnell und effizient macht. Das Wichtigste: Er arbeitet direkt in deiner Kommandozeile. Dadurch kann er deine Dateien lesen, Code bearbeiten und sogar Befehle lokal auf deiner Maschine ausführen.
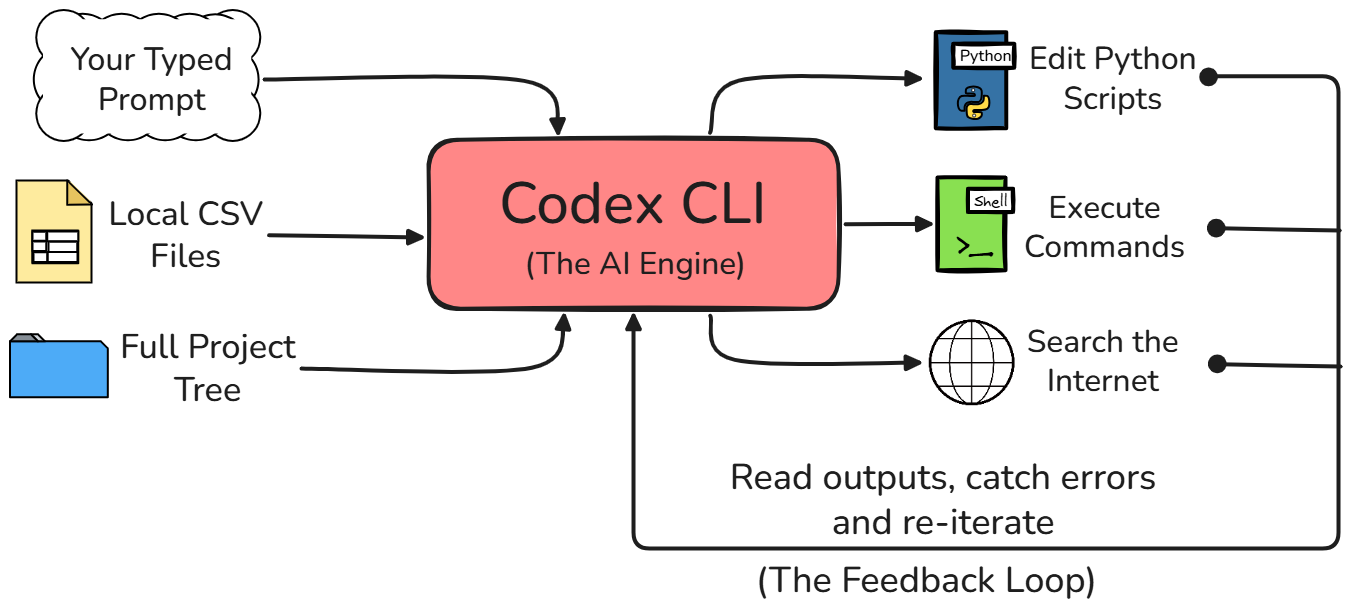
Vielleicht bist du die ChatGPT-Weboberfläche gewohnt. Codex CLI funktioniert jedoch ganz anders. In der Weboberfläche ist das KI-Modell von deiner Arbeitsumgebung komplett getrennt.
Mit Codex CLI hat der Agent direkten Zugriff auf dein lokales Dateisystem. Er kann Python-Skripte ausführen, Ausgaben oder Fehlermeldungen ansehen und behält die gesamte Projektstruktur im Blick, ohne dass du ihm alles erst erklären musst.
|
Workflow-Schritt / Feature |
ChatGPT (Webbrowser) |
Codex CLI (Terminal) |
|
Zugriff auf Daten |
Du öffnest die CSV manuell und kopierst ein paar Zeilen Rohdaten in den Chat, damit es den Kontext versteht. |
Öffnet und liest eigenständig deine CSV direkt vom lokalen Dateisystem. |
|
Code ausführen |
Du kopierst das generierte Skript, fügst es in deinen Editor ein und führst es selbst aus. |
Schreibt das nötige Python-Skript, führt es aus und zeigt die Ausgabe direkt im Terminal. |
|
Gesamterlebnis |
Viel mühsames Hin und Her sowie Kopieren und Einfügen zwischen Fenstern. |
Alles passiert in einem nahtlosen Flow im Terminal. |
Weil der Codex-Agent Dateien direkt ändern und Befehle auf deiner Maschine ausführen kann, gibt es unterschiedliche Freigabemodi, damit du die Kontrolle behältst. Die drei Modi sind:
Für den Einstieg empfehle ich Read-only und später den Wechsel nach oben, sobald du dem Workflow vertraust.
Du kannst den Freigabemodus in einer laufenden Codex-Session mit /permissions wechseln. So wechselst du am einfachsten von Read-only zu Auto, sobald du dich wohlfühlst.
/permissionsWillst du Codex von Anfang an restriktiver starten, kannst du Sandbox- und Approval-Flags beim Start setzen. Zum Beispiel startet dieser Befehl in einem konservativen Read-only-Setup, das bei Bedarf nachfragt.
codex --sandbox read-only --ask-for-approval on-requestDu brauchst ein paar Voraussetzungen, um dem Tutorial sauber folgen zu können.
Zuerst installierst du die Codex CLI auf deiner Maschine. Öffne dazu dein Terminal und installiere die CLI global mit folgendem Befehl:
npm install -g @openai/codexAls Nächstes authentifizierst du dich, damit das Tool weiß, wer du bist. Du kannst prüfen, ob alles korrekt installiert ist, und den Agenten mit codex erstmals starten. Du siehst dann etwa Folgendes:
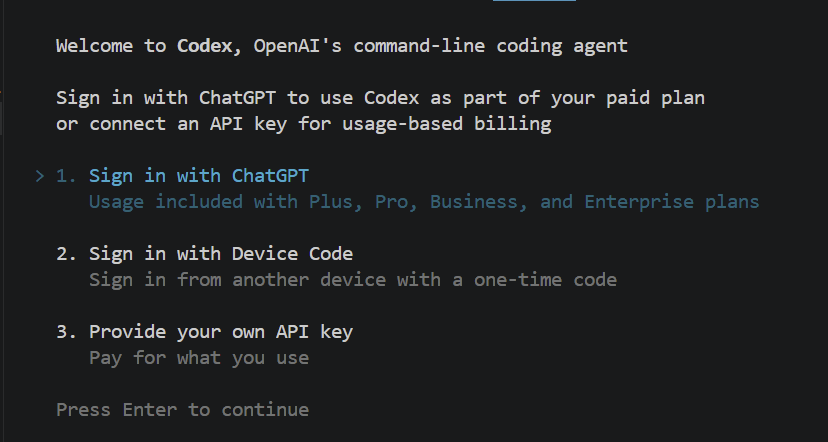
Nach Enter öffnet sich ein Browserfenster, in dem du dich mit deinem ChatGPT-Konto anmeldest. Danach ist das Tool einsatzbereit.
Falls du kein bezahltes ChatGPT-Abo hast und stattdessen einen API-Key nutzen willst, gibt es die Pay-per-Use-Option. Einen Key bekommst du in der OpenAI-Konsole.
Bevor wir die KI Daten analysieren lassen, sollten wir die Python-Umgebung korrekt einrichten. Das ist wichtig, weil Codex CLI in der jeweils aktiven Umgebung arbeitet. Wenn der Agent ein Skript mit Bibliotheken wie pandas, scikit-learn oder matplotlib schreiben soll, müssen diese installiert und verfügbar sein.
Das erreichen wir, indem wir vor dem Start von Codex eine Python-virtuelle Umgebung aktivieren. Hier ein Setup-Skript mit konkreten Befehlen, um eine virtuelle Umgebung zu erstellen, Datenpakete zu installieren, sie zu aktivieren und anschließend den Agenten zu starten:
python3 -m venv data_env
source data_env/bin/activate
pip install pandas scikit-learn matplotlib
codexEin weiterer wichtiger Schritt ist eine Datei namens AGENTS.md im Hauptordner deines Projekts. Diese Datei dient als persistente Anleitung, die der Codex-Agent jedes Mal liest, wenn er dein Projekt öffnet. Sie definiert, wie er sich in diesem Workspace verhalten und Code schreiben soll.
Für Datenarbeit wollen wir sauberen, gut lesbaren, professionellen Code. Hier ist eine Beispiel-AGENTS.md speziell für Datenprojekte. Erstelle die Datei und füge diesen Text ein:
# Data Project Guidelines
When writing Python code for this project, please strictly follow these rules:
- Enforce PEP 8 formatting standards for all Python code.
- Always use highly descriptive variable names. Do not use generic, lazy names like df, data, x, or y. Instead, use specific names like transaction_data or revenue_series.
- Prefer pandas best practices, such as using vectorized operations instead of iterating through rows.
- Generate clear, descriptive docstrings for every single function.
- Always include Python type hints for function arguments and return values.Da diese Datei unabhängig von der jeweiligen Aufgabe jedes Mal gelesen wird, halte sie kurz und fokussiere dich auf Anweisungen, die für alle Prompts gelten. Für spezifischere Vorgaben solltest du stattdessen Skills nutzen.
Kommen wir zur eigentlichen Datenarbeit und starten mit Exploratory Data Analysis (EDA). Das ist fast immer der erste Schritt in neuen Datenprojekten. Bevor du Modelle oder Pipelines baust, musst du deine Daten verstehen.
Das Schöne: Mit der Codex CLI kann ein einziger, einfacher Prompt ein komplettes, lauffähiges EDA-Skript erzeugen.
Szenario: Für unsere Beispiele heute nutzen wir ein realistisches, synthetisches Dataset. Nehmen wir an, wir haben ein E‑Commerce-Dataset namens transactions.csv im Projektordner. Es enthält realistische Business-Daten wie Order-IDs, User-IDs, Kaufzeitstempel und Transaktionsbeträge.
Wenn du so eine neue Datei bekommst, willst du sie zuerst profilieren, um die Grundstruktur zu verstehen. Anstatt selbst Boilerplate mit pandas zu schreiben, öffnest du einfach dein Terminal mit der laufenden Codex-Session und gibst einen Prompt wie diesen ein:
Profile the transactions.csv file. Show shape, dtypes, missing values, and summary statistics.Nach Enter liest Codex die ersten Zeilen deiner transactions.csv direkt vom lokalen Dateisystem. Dann generiert es ein vollständiges Python-Skript für das Profiling und fragt im "Vorschlags"-Modus, ob es ausgeführt werden soll.
Du siehst sofort die exakte Form der Daten, die Datentypen deiner E‑Commerce-Spalten und wie viele fehlende Werte es gibt (siehe Beispiel unten) – ohne selbst eine Zeile Code zu schreiben.
Zahlen im Terminal sind gut, aber irgendwann willst du die Daten auch sehen. Du kannst erstaunlich komplexe Visualisierungen erzeugen, indem du schlicht in natürlicher Sprache beschreibst, was du möchtest.
Willst du z. B. einen Überblick über dein E‑Commerce-Business, gib Codex einen Prompt wie:
Create a matplotlib dashboard with 3 subplots showing revenue by month, product categories ranked by sales, and order distribution by day of week.Das ist recht komplex. Codex analysiert Prompt und Datei, gruppiert Datumswerte, summiert Umsätze, erstellt einen Plan und generiert ein robustes matplotlib-Skript mit genau diesen Subplots.
Wichtig bei der Arbeit mit solchen KI‑Agenten: Der Prozess ist iterativ. Wenn Codex die erste Version des Codes vorschlägt, genehmige sie und schau dir das Ergebnis an.
Vielleicht überlappen sich die x‑Achsenbeschriftungen oder die Farben sind zu grell. Du musst nicht manuell im Skript matplotlib-Parameter ändern.
Antwort einfach mit einem Folgeprompt wie: "Die unteren Labels überlappen, bitte um 45 Grad drehen und die Legendenfarben dezenter machen." Codex verfeinert das Skript, führt es erneut aus und liefert dir ein poliertes Dashboard.
Nach dem spielerischen Erkunden der Daten brauchst du etwas Reproduzierbares und Modulares. In der Datenwelt heißt das meistens: eine ETL‑Pipeline (Extract, Transform, Load) aufbauen. Der Standard, um Daten einzulesen, zu bereinigen und für die Weiterverwendung zu speichern.
Als praktisches Beispiel: Wir lesen dieselben E‑Commerce-Transaktionsdaten aus der CSV ein, bereinigen sie, berechnen Business-Aggregationen und speichern das Ergebnis in einer neuen, sauberen Datei.
Statt die gesamte Boilerplate-Architektur selbst zu schreiben, kannst du die Codex CLI die Struktur aus einer High-Level-Beschreibung heraus erzeugen lassen.
Als Erstes legen wir die Projektstruktur an. Eine gute Pipeline ist in separate Dateien gegliedert, damit sie später leicht zu lesen und zu warten ist. Bitte den Codex-Agenten einfach darum. Im Terminal etwa so:
Create a project layout for an ETL pipeline. I need separate Python modules for extraction, transformation, and loading, plus a main entry point script to run them all.Codex erstellt diese Dateien im Verzeichnis. Nach Freigabe siehst du einen sauberen, professionellen Aufbau wie diesen:
etl_pipeline/
├──__init__.py
├── extract.py
├── transformation.py
└── loading.py
– run_etl.pyDiese Architektur trennt Verantwortlichkeiten: Das Einlesen ist getrennt von der Business- und Logikschicht – so sollten Data Engineers arbeiten.
Beschreiben wir nun die gewünschte Transformation. In ETL ist die Transformation oft der schwierigste Teil, aber wir können Codex die Details überlassen. Sagen wir, wir wollen fehlende Werte bereinigen und den Umsatz je Bestellung berechnen.
Gib in der CLI z. B. ein:
In transformation.py, write a function that takes the transactions data, drops any rows where the user ID is missing, and creates a new derived column called 'revenue' by multiplying the 'quantity' column by the 'unit_price' column.Da Codex deine transactions.csv lesen kann, kennt es die echten Spaltennamen. Es rät nicht blind df['qty'] * df['price'], sondern sieht, dass die Spalten quantity und unit_price heißen, und schreibt den korrekten pandas-Code.
Nachdem der Code generiert ist, führst du die Pipeline Ende-zu-Ende aus. Sag Codex einfach, "Run the run_etl.py script."
Bei der Ausführung siehst du alle Terminalausgaben direkt vor dir, z. B. so:
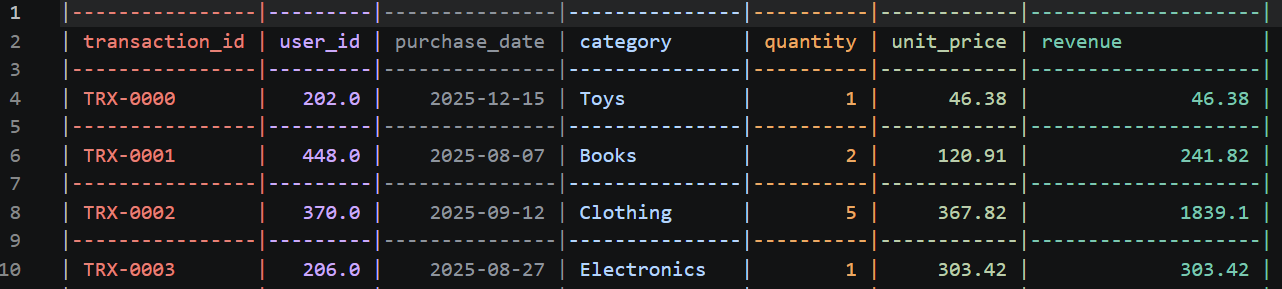
Die neue processed_transactions.csv sieht etwa so aus:
In der Praxis geht auch mal etwas schief. Vielleicht steckt ein String in einer numerischen Spalte und verursacht einen TypeError. Keine Panik und kein Copy-Paste in den Browser nötig: Codex CLI fängt den Fehler ab, liest den Python-Traceback und schlägt oft direkt eine Korrektur vor.
Das zeigt den Kern des iterativen Loops mit einem KI‑Coding-Agenten:
Dieser kontinuierliche, kollaborative Loop liefert funktionierende Software deutlich schneller als Tippen per Hand.
Tests sind essenziell, damit du in Produktion nichts zerschießt – werden aber dennoch oft weggelassen.
Tests zu schreiben ist mühsam, vor allem wenn du aus einem neuen Dataset nur schnelle Insights willst. Mit Codex CLI direkt im Terminal fällt diese Hürde praktisch weg.
Für die Transformation aus dem vorherigen Abschnitt musst du nicht mal den Editor öffnen. Wir nutzen pytest. Gib Codex z. B. diesen Prompt:
Write high-quality, maintainable pytest tests for the transform module. Test null handling, extreme edge cases like zeroes or negative values, type casting, and revenue calculation.Codex schaut sich die zuvor erstellte transformation.py an, versteht die Logik und generiert eine neue Testdatei. So etwas siehst du danach im Terminal.
In meinem Fall wurde ein neues Skript test_transformation.py im Ordner tests erzeugt, das prüft, ob die Transformationsfunktionen korrekt arbeiten.
Codex schreibt nicht nur generische Assertions, sondern erzeugt realistische, kleine synthetische Daten (Fixtures), mit denen deine Funktionen gezielt gestresst werden. Es baut bewusst Edge Cases ein, etwa komplett fehlende User-IDs oder negative Mengen, damit deine Logik robuste und korrekte Ergebnisse liefert.
Tests für Python-Code sind das eine, aber als Datenprofis prüfen wir auch die Daten selbst. Das ist Datenvalidierung. Du willst echte Assertions, die die Datenqualität vor Übergabe an Stakeholder oder fürs Dashboard sicherstellen.
Bitte Codex, ein Validierungsskript zu generieren. Zum Beispiel mit:
Create a data validation script that runs after the very end of the pipeline. It should check that the schema matches our expectations, ensure the null-percentage for user_id is exactly 0%, and verify that all revenue values are greater than or equal to zero.Codex gibt dann ein eigenes Validierungsskript aus – dein letztes Sicherheitsnetz. Du kannst es als finalen Schritt am Pipeline-Ende ausführen lassen.
Ändert sich morgen plötzlich die Struktur der Rohdaten oder tauchen negative Umsätze auf, fängt dieses Skript es ab und wirft sofort einen Fehler. So verhinderst du, dass schlechte Daten unbemerkt weitergereicht werden.
Bisher haben wir Codex CLI vor allem interaktiv genutzt. Wer das Tool in den täglichen Workflow integrieren will, kann noch weitergehen – bis hin zum Autopiloten für lästige Routinearbeiten.
Jupyter Notebooks sind großartig für das explorative Arbeiten, aber schwach, wenn es um zuverlässigen Produktionsbetrieb geht. Meist kopierst du stundenlang Zellen, fügst sie in .py-Dateien ein und begradigst globale Variablen.
Mit Codex CLI zeigst du dem Agenten einfach dein Notebook und lässt ihn die Schwerstarbeit übernehmen. Tippe im Terminal etwa:
Refactor analysis.ipynb into a modular Python package with separate files for data loading, transformation, visualization, and a main.py entry point.Nach Freigabe liest Codex die JSON-Struktur des Notebooks, zieht den Python-Code heraus, ignoriert zufällige Ausgaben und organisiert alles neu.
Vorher hattest du eine einzige große analysis.ipynb, in der alles verheddert war.
Nach Codex siehst du einen sauberen Ordner mit separaten Dateien wie data_loader.py, transformer.py und visualizer.py (Namen können variieren), zusammengeführt über main.py. So schließt du die Lücke zwischen explorativer Analyse und produktionsreifer Software.
Manchmal willst du gar nicht chatten. Für automatisierte Pipelines, etwa Checks vor dem Teilen deines Codes, soll die KI im Hintergrund laufen – komplett im Autopilot.
Dafür gibt es den Befehl codex exec. Er ist für Skripte und nicht-interaktive Umgebungen gedacht, ohne bei jedem Schritt nach Erlaubnis zu fragen.
Ein praktisches Beispiel: Wir lassen codex exec als simulierten CI/CD‑Check laufen, um fehlerhafte Daten automatisch zu erkennen.
Öffne dein Terminal und tippe exakt:
codex exec --skip-git-repo-check "Read transactions.csv. Write and run a quick python script to check if the 'quantity' column contains any negative numbers. If it does, print 'DATA VALIDATION FAILED: Negative quantities detected.' If it is clean, print 'DATA VALIDATION PASSED'." 2> /dev/nullNach Enter läuft Codex nicht-interaktiv. Es öffnet nicht die Chatoberfläche, und das Freigabeverhalten hängt von den konfigurierten Flags/Defaults ab; ggf. musst du Aktionen erlauben, sofern Approvals nicht deaktiviert sind. Mehr Infos findest du in der Codex-Dokumentation.
Codex schreibt rasch das Validierungsskript, führt es gegen deine lokale CSV aus und gibt das Ergebnis direkt im Terminal aus – vorausgesetzt, das Verzeichnis ist vertrauenswürdig und die Approvals erlauben dies. Du solltest eine Ausgabe wie diese sehen:
Dieser Ansatz hat viele Use Cases. Nutze den Befehl z. B. unverändert in einem Pre-Commit-Hook oder GitHub Actions Workflow. Wenn deiner Pipeline je eine Spalte fehlt, NaN-Werte auftreten oder sich anderes Unerwartetes zeigt, erkennt Codex es sofort – ohne dass du PyTest- oder Validierungsskripte selbst schreiben musst.
Bei KI-Tools für Datenarbeit bestimmt deine Interaktion mit dem Agenten die Qualität des Python-Codes maßgeblich. Hier sind Best Practices für einen reibungslosen, professionellen Workflow.
Der erste Hebel sind gute Prompts. Nur "Daten bereinigen" reicht nicht. So solltest du Anfragen strukturieren:
Sei spezifisch: Nenne exakte Spaltennamen, gewünschte Datentypen und das erwartete Ausgabeformat. Statt vager Wünsche lieber konkret: "Cast die Spalte 'purchase_date' zu datetime und exportiere eine aggregierte CSV."
Dateien direkt referenzieren: Nutze das @-Syntax-Feature. Mit @transactions.csv zwingst du Codex, genau diese Datei sofort in den Kontext zu laden.
Komplexes herunterbrechen: Teile große Aufgaben in Schritte. Nutze den Plan-Modus von Codex, um erst einen Plan zu erstellen und ihn dann Schritt für Schritt auszuführen – statt eines einzigen Mega-Prompts.
Wenn du dein Prompting weiter ausbauen willst, empfehle ich unseren Kurs Prompt Engineering with the OpenAI API.
Wie erwähnt gibt es verschiedene Freigabemodi. So wählst du den richtigen:
Reproduzierbarkeit ist entscheidend. Eine Grundregel: Führe Codex immer in einem initialisierten Git-Repository aus. Da Codex Dateien schreibt und ändert, siehst du mit Git genau, was die KI getan hat, und kannst es rückgängig machen.
Committe außerdem die AGENTS.md gleich mit. Klont jemand aus deinem Team das Repo und öffnet Codex, profitiert die ganze Mannschaft von denselben Standards und Anweisungen.
Gleiches gilt für definierte Agent Skills für Einzeltasks. Inspiration findest du in unserem Guide mit über hundert Top-Agent-Skills für Codex und andere agentische Coding-Tools.
Wenn du mehrere Tage an einer Analyse arbeitest, musst du nicht jeden Morgen neu anfangen. Nutze den Befehl codex resume im Terminal, um mehrteilige Projekte fortzusetzen. Er lädt deine letzte Session mit dem bisherigen Kontext von Unterhaltungen, Plänen und Dateiänderungen (im Rahmen der üblichen Modell-/Historiengrenzen).
Weitere Best Practices für agentisches Coden findest du in unserem Guide Claude Code Best Practices. Auch wenn sich Claude Code und Codex unterscheiden, wie im Vergleich Codex vs Claude Code beschrieben, gelten viele Grundlagen auch für Codex.
Wir haben Codex CLI für deine Datenarbeit und lokale Python-Umgebungen eingerichtet. Danach haben wir aus dem Nichts EDA-Skripte generiert, reproduzierbare ETL‑Pipelines gebaut, automatisierte Transformationstests (die viel zu oft fehlen) geschrieben und schließlich fortgeschrittene Wege gezeigt, tägliche Routineaufgaben zu automatisieren.
Das Wichtigste: Wir haben all das in der Kommandozeile getan, ohne ständiges Hin‑ und Herspringen in den Browser. Codex CLI schließt effektiv die frustrierende Lücke zwischen explorativer Datenanalyse und produktionsreifer Data Engineering.
Wenn du lernen willst, wie du mit Codex CLI einen komplexeren Agenten baust, empfehle ich unser Codex CLI MCP Tutorial. Es führt dich Schritt für Schritt zu einem Agenten für ein Finanzportfoliodashboard.
KI-Kurse
Lernpfad
Kurs
Kurs
Blog
Tutorial
Matt Crabtree
Tutorial
Mark Pedigo
Tutorial
Sejal Jaiswal
Tutorial
Derrick Mwiti