
Kursus
Konsep Generative AI
2 Hr
110.7K
Pencarian vektor semakin populer dalam beberapa tahun terakhir, berkat kemajuan di ekosistem AI Generatif dan Large Language Model.
Pencarian vektor adalah metode pengambilan informasi di mana dokumen dan kueri direpresentasikan sebagai vektor alih-alih teks biasa. Representasi numerik ini diperoleh dengan menggunakan jaringan saraf besar yang terlatih untuk mengonversi data tidak terstruktur, seperti teks, gambar, dan video, menjadi vektor.
Database relasional tradisional tidak dioptimalkan untuk menangani volume besar data vektor. Karena itu, banyak database vektor open-source dan proprietari bermunculan dalam beberapa tahun terakhir. Namun, tidak ideal bagi semua perusahaan untuk memiliki database khusus hanya untuk vektor yang terpisah dari database utama.
Di sinilah pgvector hadir, sebuah ekstensi kuat untuk PostgreSQL yang menghadirkan kemampuan pencarian kemiripan vektor ke salah satu database relasional paling populer.
Dalam tutorial ini, kita akan mengeksplorasi fitur-fitur pgvector dan menunjukkan bagaimana alat ini dapat membantu pekerjaan Anda.
pgvector adalah ekstensi open-source untuk PostgreSQL yang menambahkan dukungan untuk operasi vektor dan pencarian kemiripan. Ekstensi ini memungkinkan Anda menyimpan, mengindeks, dan melakukan kueri data vektor langsung di dalam database PostgreSQL Anda.
Integrasi ini membawa kekuatan operasi vektor ke infrastruktur PostgreSQL yang sudah ada, menjadikannya pilihan unggul untuk aplikasi yang melibatkan embeddings, sistem rekomendasi, dan pencarian kemiripan.
Fitur pgvector meliputi:
Database vektor adalah database khusus yang dirancang untuk menyimpan dan mengkueri data vektor multi-dimensi. Kemampuan ini relevan dalam aplikasi machine learning modern, termasuk sistem rekomendasi, penelusuran gambar, dan kasus penggunaan pemrosesan bahasa alami.
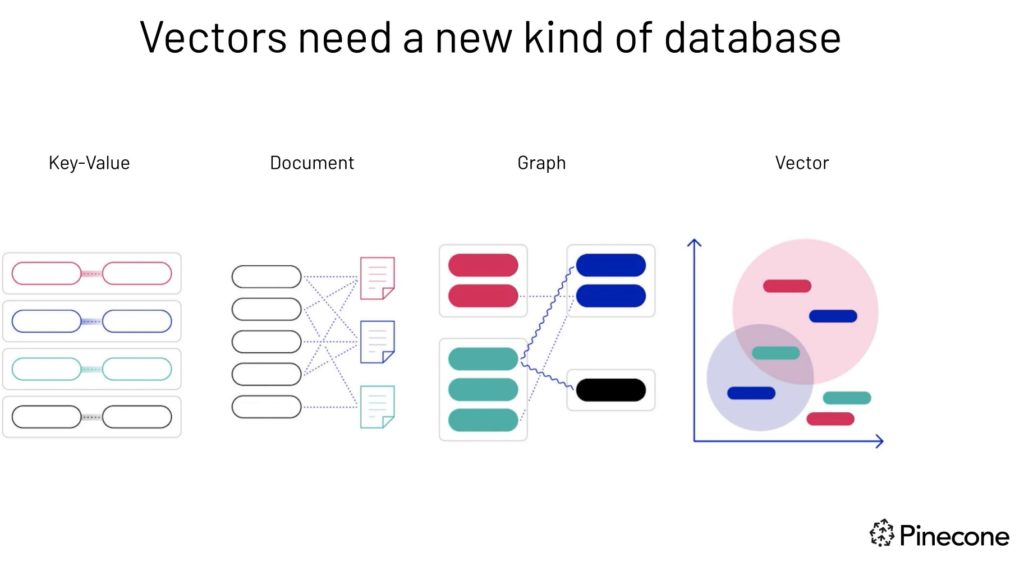
Vektor membutuhkan jenis database baru—sumber gambar.
Database relasional tradisional kesulitan dengan data berdimensi tinggi dan melakukan pencarian kemiripan secara efisien. Sebaliknya, database vektor dioptimalkan khusus untuk tugas-tugas ini, memungkinkan pengambilan data yang cepat dan presisi berdasarkan kedekatan atau kemiripan vektor.
Pendekatan ini memungkinkan pencarian yang berakar pada relevansi semantik atau kontekstual, memberikan hasil yang lebih bermakna dibandingkan pencarian exact match pada database konvensional.
Sebagai contoh, sebuah database vektor dapat:
Lalu bagaimana data tidak terstruktur seperti teks atau gambar diubah menjadi angka? Jawabannya adalah embeddings.
Embedding adalah proses yang mentransformasikan data tidak terstruktur menjadi vektor numerik berukuran tetap, yang menangkap semantik dan hubungan yang melekat dalam data. Ini dicapai melalui jaringan saraf besar yang belajar merepresentasikan data dalam ruang vektor kontinu, di mana item yang serupa ditempatkan berdekatan.
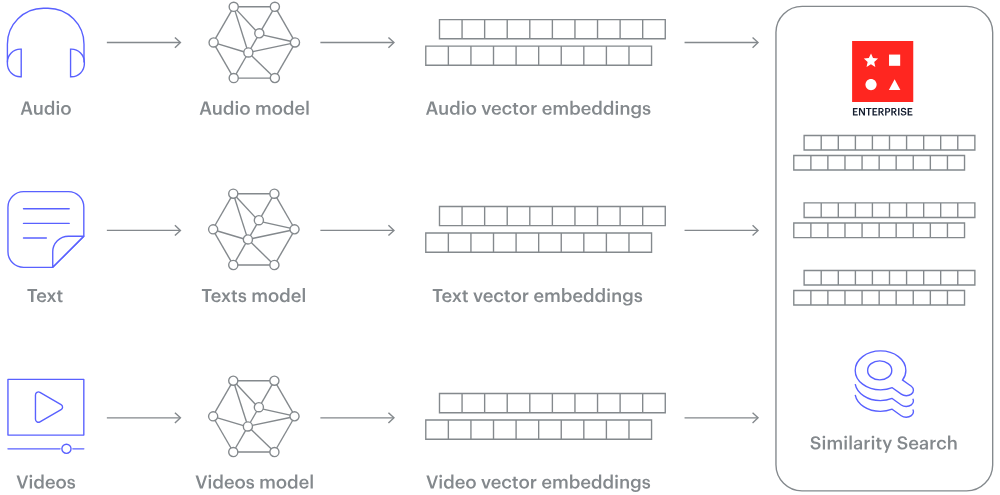
Bagaimana cara kerja database vektor? Sumber gambar.
Pada bagian ini, kita akan membahas penyiapan pgvector, penggunaan fitur dasar, dan membangun aplikasi sederhana dengan mengintegrasikannya dengan OpenAI.
Kita akan membahas instalasi, operasi dasar, pengindeksan, dan integrasi dengan Python serta LangChain.
Untuk mengikuti tutorial ini, Anda sebaiknya memiliki pengetahuan dasar SQL dan PostgreSQL serta familier dengan pemrograman Python.
Sebelum mulai, pastikan Anda memiliki hal-hal berikut:
1. Pertama, pastikan Anda memasang berkas pengembangan PostgreSQL. Di Ubuntu atau Debian, Anda dapat memasangnya dengan:
sudo apt-get install postgresql-server-dev-allJika Anda pengguna Windows, Anda dapat mengunduh installer PostgreSQL dari situs resmi.
2. Kloning repositori GitHub pgvector:
git clone https://github.com/pgvector/pgvector.git3. Build dan pasang ekstensi pgvector:
cd pgvector
make
sudo make installJika Anda pengguna Windows, pastikan dukungan C++ di Visual Studio Code telah terpasang. Dokumentasi instalasi resmi menyediakan langkah-langkahnya.
4. Sambungkan ke database PostgreSQL Anda:
Ada beberapa opsi untuk menyambung dan berinteraksi dengan database PostgreSQL: pgAdmin adalah salah satu antarmuka yang paling umum digunakan. Alternatifnya, Anda dapat menggunakan pSQL (antarmuka baris perintah PostgreSQL) atau bahkan ekstensi VS Code untuk PostgreSQL.
5. Setelah tersambung ke database PostgreSQL Anda, buat ekstensi:
CREATE EXTENSION vector;
Antarmuka pgAdmin
Kini pgvector sudah terpasang, mari jelajahi penggunaan dasarnya.
1. Untuk menyiapkan database vektor pertama kita di PostgreSQL menggunakan ekstensi pgvector, mari buat tabel untuk menyimpan data vektor:
CREATE TABLE items (
id SERIAL PRIMARY KEY,
embedding vector(3)
);Ini membuat tabel bernama items dengan kolom id dan kolom embedding bertipe vector(3), yang akan menyimpan vektor berdimensi 3.
2. Sekarang, mari masukkan beberapa data ke tabel kita:
INSERT INTO items (embedding) VALUES ('[1,2,3]'), ('[4,5,6]'), ('[1,1,1]');3. Kini kita dapat melakukan operasi vektor. Misalnya, untuk menemukan tetangga terdekat dari vektor [2,3,4]:
SELECT * FROM items ORDER BY embedding <-> '[2,3,4]' LIMIT 1;Kueri ini menggunakan operator <->, yang menghitung jarak Euclidean antar vektor.
4. Kita juga dapat menggunakan metrik jarak lainnya, seperti cosine distance:
SELECT * FROM items ORDER BY embedding <=> '[2,3,4]' LIMIT 1;Operator <=> menghitung jarak kosinus antar vektor.
Pengindeksan dalam database vektor, termasuk pgvector, diperlukan untuk meningkatkan performa pencarian, terutama saat dataset Anda berkembang.
Pentingnya pengindeksan tidak bisa dilebih-lebihkan, karena menawarkan beberapa manfaat:
Ada dua jenis indeks yang tersedia untuk pgvector: ivfflat dan hnsw. Keduanya memiliki tujuan berbeda:
Kapan menggunakan masing-masing indeks:
1. Mari buat indeks ivfflat:
CREATE INDEX ON items USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);Ini membuat indeks menggunakan algoritma IVFFlat, yang cocok untuk pencarian tetangga terdekat yang presisi.
2. Untuk pencarian tetangga terdekat pendekatan, kita dapat menggunakan indeks hnsw:
CREATE INDEX ON items USING hnsw (embedding vector_l2_ops) WITH (m = 16, ef_construction = 64);Setelah membuat indeks, kueri kita akan otomatis menggunakannya bila sesuai.
Pgvector mendukung integrasi dengan beberapa framework, yang memudahkan interaksi dengan database vektor kita. Mari tinjau dua yang bermanfaat: Python dan LangChain.
pgvector dapat dengan mudah diintegrasikan dengan Python menggunakan pustaka psycopg2. Mari siapkan lingkungan Python dan melakukan beberapa operasi dasar.
1. Pertama, pasang pustaka yang dibutuhkan:
!pip install psycopg2-binary numpy2. Sekarang, mari buat skrip Python untuk berinteraksi dengan database vektor kita:
import psycopg2
import numpy as np
# Connect to the database
conn = psycopg2.connect("dbname=your_database user=your_username")
cur = conn.cursor()
# Insert a vector
embedding = np.array([1.5, 2.5, 3.5])
cur.execute("INSERT INTO items (embedding) VALUES (%s)", (embedding.tolist(),))
# Perform a similarity search
query_vector = np.array([2, 3, 4])
cur.execute("SELECT * FROM items ORDER BY embedding <-> %s LIMIT 1", (query_vector.tolist(),))
result = cur.fetchone()
print(f"Nearest neighbor: {result}")
conn.commit()
cur.close()
conn.close()Skrip ini menunjukkan cara menyisipkan vektor dan melakukan pencarian kemiripan menggunakan Python.
pgvector juga dapat diintegrasikan dengan LangChain, framework populer untuk mengembangkan aplikasi dengan large language model.
Berikut contoh sederhana cara menggunakan pgvector sebagai vector store di LangChain:
from langchain_postgres.vectorstores import PGVector
from langchain.embeddings.openai import OpenAIEmbeddings
# Set up the connection string and embedding function
connection_string = "postgresql://user:pass@localhost:5432/db_name"
embedding_function = OpenAIEmbeddings()
# Create a PGVector instance
vector_store = PGVector.from_documents(
documents,
embedding_function,
connection_string=connection_string
)
# Perform a similarity search
query = "Your query here"
results = vector_store.similarity_search(query)Contoh ini mengasumsikan Anda telah menyiapkan embeddings OpenAI dan memiliki daftar dokumen untuk di-embed.
Sekarang, mari bangun mesin pencari semantik sederhana menggunakan pgvector dan embeddings OpenAI!
Aplikasi ini akan memungkinkan pengguna menelusuri kumpulan dokumen teks menggunakan kueri bahasa alami.
import openai
import psycopg2
import numpy as np
# Set up OpenAI API (replace with your actual API key)
openai.api_key = "your_openai_api_key"
# Connect to the database
conn = psycopg2.connect("dbname=your_database user=your_username")
cur = conn.cursor()
# Create a table for our documents
cur.execute("""
CREATE TABLE IF NOT EXISTS documents (
id SERIAL PRIMARY KEY,
content TEXT,
embedding vector(1536)
)
""")
# Function to get embeddings from OpenAI
def get_embedding(text):
response = openai.embeddings.create(input=text, model="text-embedding-ada-002")
return response['data'][0]['embedding']
# Function to add a document
def add_document(content):
embedding = get_embedding(content)
cur.execute("INSERT INTO documents (content, embedding) VALUES (%s, %s)", (content, embedding))
conn.commit()
# Function to search for similar documents
def search_documents(query, limit=5):
query_embedding = get_embedding(query)
cur.execute("""
SELECT content, embedding <-> %s AS distance
FROM documents
ORDER BY distance
LIMIT %s
""", (query_embedding, limit))
return cur.fetchall()
# Add some sample documents
sample_docs = [
"The quick brown fox jumps over the lazy dog.",
"Python is a high-level programming language.",
"Vector databases are essential for modern AI applications.",
"PostgreSQL is a powerful open-source relational database.",
]
for doc in sample_docs:
add_document(doc)
# Perform a search
search_query = "Tell me about programming languages"
results = search_documents(search_query)
print(f"Search results for: '{search_query}'")
for i, (content, distance) in enumerate(results, 1):
print(f"{i}. {content} (Distance: {distance:.4f})")
# Clean up
cur.close()
conn.close()Aplikasi sederhana ini menunjukkan cara menggunakan pgvector untuk membuat mesin pencari semantik.
Aplikasi ini melakukan embedding dokumen menggunakan model text embedding dari OpenAI dan menyimpannya di database PostgreSQL dengan pgvector. Fungsi pencarian menemukan dokumen yang paling mirip dengan kueri tertentu menggunakan cosine similarity.
Anda akan ingin mengoptimalkan pgvector seiring skala aplikasi Anda. Berikut beberapa saran tingkat tinggi:
Terapkan connection pooling untuk mengurangi overhead. Gunakan PgBouncer atau PgPool-II. Alat ini penting karena mempertahankan koneksi database yang dapat digunakan kembali.
Sesuaikan parameter indeks saat runtime. Anda dapat menyeimbangkan kecepatan dan akurasi sesuai kebutuhan.
Untuk indeks IVFFlat, atur parameter probes. Gunakan 1-5 untuk kecepatan. Gunakan 10-20 untuk kinerja seimbang.
Untuk indeks HNSW, atur ef_search. Gunakan 20-40 untuk kecepatan. Gunakan 100-200 untuk akurasi.
Selain itu, Anda dapat menggunakan EXPLAIN ANALYZE untuk memverifikasi penggunaan indeks. Selalu sertakan klausa LIMIT dalam kueri.
Terapkan caching dengan Redis atau Memcached. Cache vektor yang sering dikueri. Gunakan vektor kueri sebagai kunci cache. Atur waktu kedaluwarsa yang sesuai.
Siapkan read replica PostgreSQL untuk beban kerja baca yang tinggi. Arahkan penulisan ke database primer. Arahkan pencarian vektor ke replica. Gunakan load balancer untuk distribusi otomatis.
Atur parameter kunci untuk beban kerja vektor:
shared_buffers: Atur ke 25% dari total RAM
work_mem: Atur ke 64-128MB untuk operasi vektor
random_page_cost: Turunkan untuk penyimpanan SSD
effective_cache_size: Atur ke 50-75% dari total RAM
Bangun ulang indeks secara berkala saat lalu lintas rendah. Jalankan VACUUM dan ANALYZE. Aktifkan autovacuum untuk pemeliharaan otomatis.
Lacak latensi kueri dan kueri per detik. Pantau pemanfaatan connection pool. Periksa rasio hit cache. Awasi penggunaan sumber daya. Atur peringatan untuk masalah performa. Aktifkan pg_stat_statements untuk mengidentifikasi kueri lambat.
Sekarang, mari bandingkan pgvector dengan database vektor populer lainnya. Perbandingan ini akan membantu Anda memahami perbedaan fitur, opsi penyebaran, skalabilitas, integrasi, dan biaya antara pgvector dan solusi lain di pasar.
Pinecone adalah database vektor terkelola penuh yang dirancang untuk skalabilitas tinggi dan kemudahan penggunaan.
|
Fitur |
pgvector |
Pinecone |
|
Jenis database |
Ekstensi untuk PostgreSQL |
Database vektor terkelola penuh |
|
Penyebaran |
Self-hosted |
Berbasis cloud |
|
Skalabilitas |
Dibatasi oleh PostgreSQL |
Sangat skalabel |
|
Integrasi |
Bekerja dengan tumpukan PostgreSQL yang ada |
Memerlukan integrasi terpisah |
|
Biaya |
Gratis, open-source |
Harga pay-as-you-go |
pgvector adalah pilihan yang sangat baik bagi mereka yang ingin memanfaatkan infrastruktur PostgreSQL yang sudah ada tanpa biaya tambahan. Sementara itu, Pinecone menyediakan solusi terkelola yang sangat skalabel dengan harga pay-as-you-go untuk kemudahan penggunaan.
Milvus adalah database vektor khusus yang menawarkan fitur canggih dan skalabilitas tinggi.
|
Fitur |
pgvector |
Milvus |
|
Jenis database |
Ekstensi untuk PostgreSQL |
Database vektor khusus |
|
Penyebaran |
Self-hosted |
Self-hosted atau cloud |
|
Skalabilitas |
Dibatasi oleh PostgreSQL |
Sangat skalabel |
|
Integrasi |
Bekerja dengan tumpukan PostgreSQL yang ada |
Memerlukan integrasi terpisah |
|
Kumpulan fitur |
Operasi vektor dasar |
Fitur lanjutan seperti skema dinamis |
Sementara pgvector menyediakan operasi vektor dasar dalam lingkungan PostgreSQL yang familier, Milvus menawarkan solusi yang lebih kaya fitur dan skalabel khusus untuk menangani data vektor skala besar.
Weaviate adalah database vektor dengan penyimpanan objek terintegrasi, menawarkan pemodelan data yang fleksibel dan skalabilitas.
|
Fitur |
pgvector |
Weaviate |
|
Jenis database |
Ekstensi untuk PostgreSQL |
Database vektor dengan penyimpanan objek |
|
Penyebaran |
Self-hosted |
Self-hosted atau cloud |
|
Skalabilitas |
Dibatasi oleh PostgreSQL |
Dirancang untuk skalabilitas |
|
Integrasi |
Bekerja dengan tumpukan PostgreSQL yang ada |
Memerlukan integrasi terpisah |
|
Model data |
Hanya vektor |
Objek dengan vektor dan properti |
Kesederhanaan pgvector dan integrasinya dengan PostgreSQL menjadikannya cocok bagi pengguna yang membutuhkan fungsi vektor dasar. Sebaliknya, model data Weaviate yang lebih canggih dan skalabilitasnya sesuai untuk aplikasi kompleks yang memerlukan penyimpanan objek bersama vektor.
pgvector menghadirkan kemampuan pencarian kemiripan vektor yang kuat ke PostgreSQL, menjadikannya pilihan unggul bagi pengembang yang ingin menambahkan fitur bertenaga AI ke aplikasi berbasis PostgreSQL yang sudah ada.
Dalam tutorial ini, kita telah membahas instalasi, penggunaan dasar, kemampuan pengindeksan, dan integrasi dengan Python serta LangChain.
Meskipun pgvector mungkin tidak menawarkan skalabilitas dan fitur khusus yang sama seperti database vektor khusus seperti Pinecone atau Milvus, integrasinya yang mulus dengan PostgreSQL menjadikannya opsi menarik untuk banyak kasus penggunaan.
Ini sangat cocok untuk proyek yang sudah menggunakan PostgreSQL dan perlu menambahkan kemampuan pencarian vektor tanpa memperkenalkan sistem database baru.
Kami mendorong Anda untuk mencoba pgvector dalam proyek Anda sendiri. Baik Anda membangun sistem rekomendasi, mesin pencari semantik, atau aplikasi lain yang memerlukan pencarian kemiripan, pgvector dapat menjadi alat berharga dalam perangkat data science Anda.
Untuk pembelajaran lebih lanjut, jelajahi kursus kami:
Pelajari lebih lanjut tentang machine learning dan AI dengan kursus-kursus ini!
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Javier Canales Luna
14 mnt
