
Curso
Conceitos de IA Generativa
2 h
105.1K
A pesquisa vetorial tem ficado cada vez mais popular nos últimos anos, graças a todo o progresso no ecossistema de IA generativa e modelos de linguagem grandes.
A pesquisa vetorial é um jeito de recuperar informações em que os documentos e as consultas são representados como vetores, em vez de texto simples. Essa representação numérica é feita usando uma grande rede neural treinada que consegue transformar dados não estruturados, como textos, imagens e vídeos, em vetores.
Os bancos de dados relacionais tradicionais não são otimizados para lidar com grandes volumes de dados vetoriais. Por isso, surgiram várias bases de dados vetoriais exclusivas, tanto de código aberto quanto proprietárias, nos últimos anos. Mas, talvez não seja a melhor ideia para todas as empresas terem um banco de dados só para vetores, separado do banco de dados principal.
Conheça o pgvector, uma extensão poderosa para o PostgreSQL que traz recursos de pesquisa de similaridade vetorial para um dos bancos de dados relacionais mais populares.
Neste tutorial, vamos explorar os recursos do pgvector e mostrar como ele pode te ajudar no seu trabalho.
O pgvector é uma extensão de código aberto para o PostgreSQL que adiciona suporte para operações vetoriais e pesquisas de similaridade. Ele permite que você armazene, indexe e consulte dados vetoriais diretamente no seu banco de dados PostgreSQL.
Essa integração traz o poder das operações vetoriais para a sua infraestrutura PostgreSQL já existente, tornando-a uma excelente escolha para aplicativos que envolvem incorporações, sistemas de recomendação e pesquisas de similaridade.
As características do pgvector incluem:
Bancos de dados vetoriais são bancos de dados especializados, feitos pra guardar e consultar dados vetoriais multidimensionais. Essa capacidade é importante em aplicações modernas de machine learning, incluindo sistemas de recomendação, recuperação de imagens e casos de uso de processamento de linguagem natural.
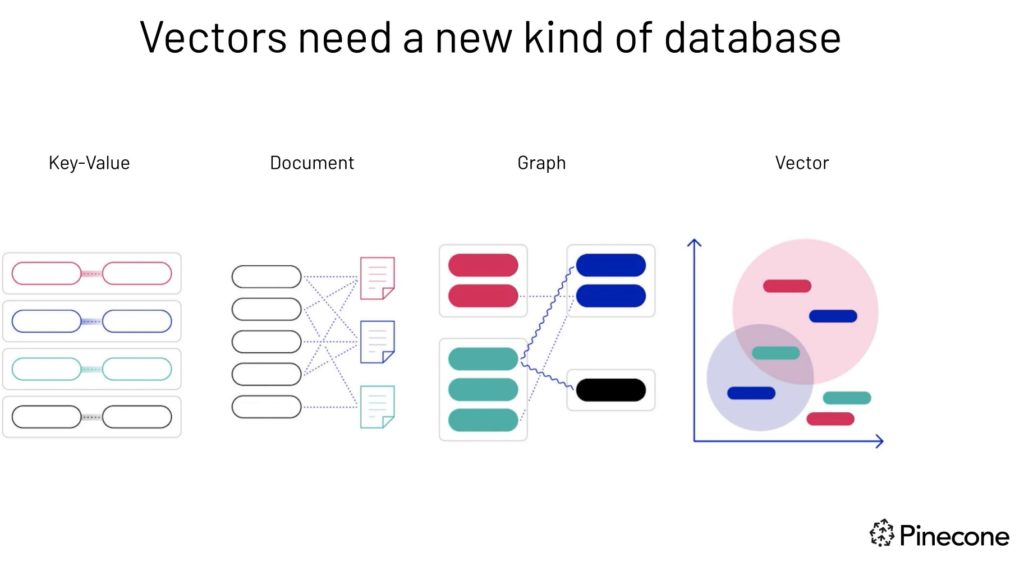
Os vetores precisam de um novo tipo de banco de dados: fonte de imagens.
Os bancos de dados relacionais tradicionais têm dificuldade em lidar com dados de alta dimensão e realizar pesquisas de similaridade de forma eficiente. Os bancos de dados vetoriais, no entanto, são otimizados especificamente para essas tarefas, permitindo a recuperação rápida e precisa de dados com base na proximidade ou semelhança vetorial.
Essa abordagem permite pesquisas baseadas na relevância semântica ou contextual, oferecendo resultados mais significativos em comparação com as pesquisas de correspondência exata dos bancos de dados convencionais.
Por exemplo, um banco de dados vetorial pode:
Então, como é que dados não estruturados, como texto ou imagens, podem ser convertidos em números? A resposta é embeddings.
A incorporação é um processo que transforma dados não estruturados em vetores numéricos de tamanho fixo, capturando a semântica e as relações inerentes aos dados. Isso é feito por meio de grandes redes neurais que aprendem a representar os dados em um espaço vetorial contínuo, onde itens parecidos ficam mais próximos uns dos outros.
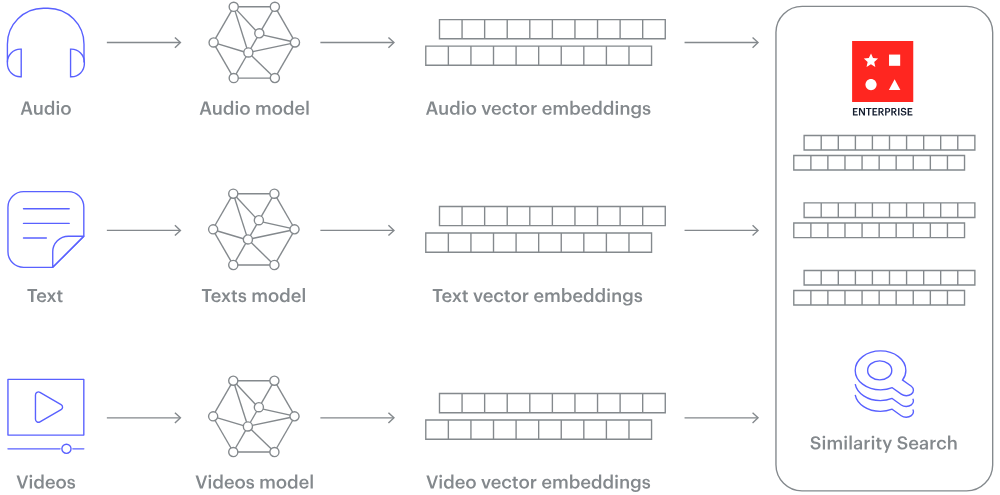
Como funciona um banco de dados vetorial? Fonte da imagem.
Nesta seção, vamos ver como configurar o pgvector, usar seus recursos básicos e criar um aplicativo simples integrando-o ao OpenAI.
Vamos falar sobre instalação, operações básicas, indexação e integração com Python e LangChain.
Pra acompanhar esse tutorial, você precisa ter um conhecimento básico de SQL e PostgreSQL e saber um pouco de programação Python.
Antes de começarmos, certifique-se de que você tem o seguinte:
1. Primeiro, certifique-se de que você tem os arquivos de desenvolvimento do PostgreSQL instalados. No Ubuntu ou Debian, você pode instalá-los com:
sudo apt-get install postgresql-server-dev-allSe você usa Windows, pode baixar o instalador do PostgreSQL no site oficial.
2. Clone o repositório pgvector do GitHub:
git clone https://github.com/pgvector/pgvector.git3. Compile e instale a extensão pgvector:
cd pgvector
make
sudo make installSe você usa Windows, certifique-se de ter o suporte a C++ instalado no Visual Studio Code. A documentação oficial de instalação fornece um processo passo a passo.
4. Conecte-se ao seu banco de dados PostgreSQL:
Você tem várias opções para se conectar e interagir com o banco de dados PostgreSQL: o pgAdmin é uma das interfaces mais usadas. Como alternativa, você pode usar o pSQL (interface de linha de comando do PostgreSQL) ou até mesmo uma extensão do VS Code para o PostgreSQL.
5. Depois de conectar ao seu banco de dados PostgreSQL, crie a extensão:
CREATE EXTENSION vector;
Interface pgAdmin
Agora que já instalamos o pgvector, vamos ver como ele funciona.
1. Para configurar nosso primeiro banco de dados vetorial no PostgreSQL usando a extensão pgvector, vamos criar uma tabela para armazenar nossos dados vetoriais:
CREATE TABLE items (
id SERIAL PRIMARY KEY,
embedding vector(3)
);Isso cria uma tabela chamada “ items ” com uma coluna “ id ” e uma coluna “ embedding ” do tipo “ vector(3) ”, que vai guardar vetores tridimensionais.
2. Agora, vamos inserir alguns dados na nossa tabela:
INSERT INTO items (embedding) VALUES ('[1,2,3]'), ('[4,5,6]'), ('[1,1,1]');3. Agora, podemos fazer operações vetoriais. Por exemplo, para encontrar o vizinho mais próximo do vetor [2,3,4]:
SELECT * FROM items ORDER BY embedding <-> '[2,3,4]' LIMIT 1;Essa consulta usa o operador <->, que calcula a distância euclidiana entre vetores.
4. Também podemos usar outras métricas de distância, como a distância coseno:
SELECT * FROM items ORDER BY embedding <=> '[2,3,4]' LIMIT 1;O operador <=> calcula a distância coseno entre vetores.
A indexação em bancos de dados vetoriais, incluindo pgvector, é necessária para melhorar o desempenho da pesquisa, principalmente à medida que seu conjunto de dados cresce.
A importância da indexação não pode ser subestimada, pois ela traz várias vantagens:
Tem dois tipos de índices disponíveis para o pgvector: ivfflat e hnsw. Os dois têm funções diferentes:
Quando usar cada índice:
1. Vamos criar um índice ivfflat:
CREATE INDEX ON items USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);Isso cria um índice usando o algoritmo IVFFlat, que é ideal para pesquisas exatas do vizinho mais próximo.
2. Para pesquisas aproximadas do vizinho mais próximo, podemos usar o índice hnsw:
CREATE INDEX ON items USING hnsw (embedding vector_l2_ops) WITH (m = 16, ef_construction = 64);Depois de criar um índice, nossas consultas vão usá-lo automaticamente quando for necessário.
O Pgvector dá suporte à integração com algumas estruturas, o que facilita a interação com nosso banco de dados vetorial. Vamos ver dois que são bem úteis: Python e LangChain.
O pgvector pode ser facilmente integrado ao Python usando a biblioteca psycopg2. Vamos configurar um ambiente Python e fazer algumas operações básicas.
1. Primeiro, instale as bibliotecas necessárias:
!pip install psycopg2-binary numpy2. Agora, vamos criar um script Python para interagir com nosso banco de dados vetorial:
import psycopg2
import numpy as np
# Connect to the database
conn = psycopg2.connect("dbname=your_database user=your_username")
cur = conn.cursor()
# Insert a vector
embedding = np.array([1.5, 2.5, 3.5])
cur.execute("INSERT INTO items (embedding) VALUES (%s)", (embedding.tolist(),))
# Perform a similarity search
query_vector = np.array([2, 3, 4])
cur.execute("SELECT * FROM items ORDER BY embedding <-> %s LIMIT 1", (query_vector.tolist(),))
result = cur.fetchone()
print(f"Nearest neighbor: {result}")
conn.commit()
cur.close()
conn.close()Esse script mostra como inserir um vetor e fazer uma busca por similaridade usando Python.
O pgvector também pode ser integrado ao LangChain, uma estrutura popular para desenvolver aplicativos com grandes modelos de linguagem.
Aqui vai um exemplo simples de como usar o pgvector como um armazenamento vetorial no LangChain:
from langchain_postgres.vectorstores import PGVector
from langchain.embeddings.openai import OpenAIEmbeddings
# Set up the connection string and embedding function
connection_string = "postgresql://user:pass@localhost:5432/db_name"
embedding_function = OpenAIEmbeddings()
# Create a PGVector instance
vector_store = PGVector.from_documents(
documents,
embedding_function,
connection_string=connection_string
)
# Perform a similarity search
query = "Your query here"
results = vector_store.similarity_search(query)Esse exemplo pressupõe que você já configurou os embeddings do OpenAI e tem uma lista de documentos para incorporar.
Agora, vamos criar um mecanismo de pesquisa semântica simples usando pgvector e embeddings OpenAI!
Esse aplicativo vai deixar os usuários pesquisarem em uma coleção de documentos de texto usando consultas em linguagem natural.
import openai
import psycopg2
import numpy as np
# Set up OpenAI API (replace with your actual API key)
openai.api_key = "your_openai_api_key"
# Connect to the database
conn = psycopg2.connect("dbname=your_database user=your_username")
cur = conn.cursor()
# Create a table for our documents
cur.execute("""
CREATE TABLE IF NOT EXISTS documents (
id SERIAL PRIMARY KEY,
content TEXT,
embedding vector(1536)
)
""")
# Function to get embeddings from OpenAI
def get_embedding(text):
response = openai.embeddings.create(input=text, model="text-embedding-ada-002")
return response['data'][0]['embedding']
# Function to add a document
def add_document(content):
embedding = get_embedding(content)
cur.execute("INSERT INTO documents (content, embedding) VALUES (%s, %s)", (content, embedding))
conn.commit()
# Function to search for similar documents
def search_documents(query, limit=5):
query_embedding = get_embedding(query)
cur.execute("""
SELECT content, embedding <-> %s AS distance
FROM documents
ORDER BY distance
LIMIT %s
""", (query_embedding, limit))
return cur.fetchall()
# Add some sample documents
sample_docs = [
"The quick brown fox jumps over the lazy dog.",
"Python is a high-level programming language.",
"Vector databases are essential for modern AI applications.",
"PostgreSQL is a powerful open-source relational database.",
]
for doc in sample_docs:
add_document(doc)
# Perform a search
search_query = "Tell me about programming languages"
results = search_documents(search_query)
print(f"Search results for: '{search_query}'")
for i, (content, distance) in enumerate(results, 1):
print(f"{i}. {content} (Distance: {distance:.4f})")
# Clean up
cur.close()
conn.close()Esse aplicativo simples mostra como usar o pgvector pra criar um mecanismo de busca semântica.
Ele incorpora documentos usando o modelo de incorporação de texto da OpenAI e os armazena em um banco de dados PostgreSQL com pgvector. A função de pesquisa encontra os documentos mais parecidos com uma determinada consulta usando a similaridade coseno.
Você vai querer otimizar o pgvector conforme sua aplicação for crescendo. Aqui estão algumas sugestões gerais:
Use o pool de conexões pra diminuir a sobrecarga. Use o PgBouncer ou o PgPool-II. É bom saber sobre essas ferramentas porque elas mantêm conexões de banco de dados reutilizáveis.
Ajuste os parâmetros do índice durante a execução. Você pode equilibrar velocidade e precisão de acordo com suas necessidades.
Para índices IVFFlat, defina o parâmetro probes. Use 1-5 para a velocidade. Use 10-20 para um desempenho equilibrado.
Para os índices HNSW, ajuste ef_search. Use 20-40 para velocidade. Use 100-200 para precisão.
Além disso, você pode usar EXPLAIN ANALYZE para verificar o uso do índice. Sempre inclua cláusulas " LIMIT " nas consultas.
Implementar cache com Redis ou Memcached. Armazene em cache os vetores consultados com frequência. Use o vetor de consulta como chave do cache. Defina prazos de validade adequados.
Configure réplicas de leitura do PostgreSQL para cargas de trabalho com muitas leituras. A rota grava no banco de dados principal. Direcione as pesquisas de vetor para réplicas. Use balanceadores de carga para distribuição automática.
Ajuste os parâmetros-chave para cargas de trabalho vetoriais:
shared_buffers: Defina para 25% da RAM total
work_mem: Defina para 64-128 MB para operações vetoriais
random_page_cost: Menor para armazenamento SSD
effective_cache_size: Defina para 50-75% da RAM total
Reconstrua os índices de vez em quando, quando não tiver muito movimento. Acesse VACUUM e ANALYZE. Ative o autovacuum para manutenção automática.
Programe a latência das consultas e as consultas por segundo. Fica de olho na utilização do pool de conexões. Verifique as taxas de acerto do cache. Fique de olho no uso dos recursos. Configure alertas para problemas de desempenho. Ative o recurso “ pg_stat_statements ” para identificar consultas lentas.
Agora, vamos comparar o pgvector com outros bancos de dados vetoriais populares. Essa comparação vai te ajudar a entender as diferenças em recursos, opções de implantação, escalabilidade, integração e custo entre o pgvector e outras soluções disponíveis no mercado.
O Pinecone é um banco de dados vetorial totalmente gerenciado, feito pra ser super escalável e fácil de usar.
|
Recurso |
pgvector |
Pinhão |
|
Tipo de banco de dados |
Extensão para PostgreSQL |
Banco de dados vetorial totalmente gerenciado |
|
Implantação |
Auto-hospedado |
Baseado na nuvem |
|
Escalabilidade |
Limitado pelo PostgreSQL |
Altamente escalável |
|
Integração |
Funciona com a pilha PostgreSQL já existente |
Precisa de integração separada |
|
Custo |
Gratuito, código aberto |
Preços pré-pagos |
O pgvector é uma escolha excelente pra quem quer aproveitar a infraestrutura PostgreSQL que já tem sem custos extras. Ao mesmo tempo, a Pinecone oferece uma solução gerenciada e super escalável, com preços pré-pagos para facilitar o uso.
O Milvus é um banco de dados vetorial dedicado que oferece recursos avançados e alta escalabilidade.
|
Recurso |
pgvector |
Milvus |
|
Tipo de banco de dados |
Extensão para PostgreSQL |
Banco de dados vetorial dedicado |
|
Implantação |
Auto-hospedado |
Auto-hospedado ou na nuvem |
|
Escalabilidade |
Limitado pelo PostgreSQL |
Altamente escalável |
|
Integração |
Funciona com a pilha PostgreSQL já existente |
Precisa de integração separada |
|
Conjunto de recursos |
Operações vetoriais básicas |
Recursos avançados, como esquema dinâmico |
Enquanto o pgvector oferece operações vetoriais básicas no ambiente familiar do PostgreSQL, o Milvus traz uma solução mais completa e escalável, feita especialmente para lidar com dados vetoriais em grande escala.
O Weaviate é um banco de dados vetorial com armazenamento de objetos integrado, que oferece modelagem de dados flexível e escalabilidade.
|
Recurso |
pgvector |
Weaviate |
|
Tipo de banco de dados |
Extensão para PostgreSQL |
Banco de dados vetorial com armazenamento de objetos |
|
Implantação |
Auto-hospedado |
Auto-hospedado ou na nuvem |
|
Escalabilidade |
Limitado pelo PostgreSQL |
Feito pra ser escalável |
|
Integração |
Funciona com a pilha PostgreSQL já existente |
Precisa de integração separada |
|
Modelo de dados |
Só vetores |
Objetos com vetores e propriedades |
A simplicidade do pgvector e sua integração com o PostgreSQL fazem dele uma boa opção para usuários que precisam de funcionalidades vetoriais básicas. Por outro lado, o modelo de dados mais sofisticado e a escalabilidade do Weaviate são perfeitos para aplicações complexas que precisam de armazenamento de objetos junto com vetores.
O pgvector traz recursos poderosos de pesquisa de similaridade vetorial para o PostgreSQL, tornando-o uma excelente opção para desenvolvedores que querem adicionar recursos baseados em IA às suas aplicações existentes baseadas em PostgreSQL.
Neste tutorial, a gente explorou a instalação, o uso básico, os recursos de indexação e a integração com Python e LangChain.
Embora o pgvector possa não oferecer a mesma escalabilidade e recursos especializados que bancos de dados vetoriais dedicados, como Pinecone ou Milvus, sua integração perfeita com o PostgreSQL o torna uma opção atraente para muitos casos de uso.
É especialmente bom para projetos que já usam o PostgreSQL e precisam adicionar recursos de pesquisa vetorial sem ter que começar um novo sistema de banco de dados.
A gente recomenda que você experimente o pgvector nos seus próprios projetos. Se você está criando um sistema de recomendações, um mecanismo de busca semântica ou qualquer outro aplicativo que precise de buscas por similaridade, o pgvector pode ser uma ferramenta valiosa no seu kit de ferramentas de ciência de dados.
Para saber mais, dá uma olhada nos nossos cursos:
Aprenda mais sobre machine learning e IA com esses cursos!
Curso
Curso
Curso
blog
Moez Ali
14 min
blog
blog
Matt Crabtree
10 min
blog
Javier Canales Luna
15 min
Tutorial
Javier Canales Luna
Tutorial
Abid Ali Awan


