
Courses
Các khái niệm về Generative AI
2 giờ
110.7K
Tìm kiếm vector ngày càng phổ biến trong những năm gần đây nhờ những tiến bộ trong hệ sinh thái Trí tuệ nhân tạo sinh (Generative AI) và Mô hình ngôn ngữ lớn.
Tìm kiếm vector là phương pháp truy hồi thông tin trong đó tài liệu và truy vấn được biểu diễn dưới dạng vector thay vì văn bản thuần. Biểu diễn số này được tạo ra bằng cách sử dụng một mạng nơ-ron lớn đã được huấn luyện, có thể chuyển đổi dữ liệu phi cấu trúc như văn bản, hình ảnh và video thành các vector.
Các cơ sở dữ liệu quan hệ truyền thống không được tối ưu để xử lý khối lượng lớn dữ liệu vector. Vì vậy, nhiều cơ sở dữ liệu vector độc quyền và mã nguồn mở đã xuất hiện trong vài năm qua. Tuy nhiên, việc có một cơ sở dữ liệu riêng chỉ cho vector, tách biệt với cơ sở dữ liệu chính, có thể không phù hợp với mọi công ty.
pgvector ra đời, một phần mở rộng mạnh mẽ cho PostgreSQL mang khả năng tìm kiếm tương đồng vector đến một trong những cơ sở dữ liệu quan hệ phổ biến nhất.
Trong hướng dẫn này, chúng ta sẽ khám phá các tính năng của pgvector và minh họa cách nó có thể hỗ trợ bạn trong công việc.
pgvector là một phần mở rộng mã nguồn mở cho PostgreSQL bổ sung hỗ trợ thao tác vector và tìm kiếm tương đồng. Nó cho phép bạn lưu trữ, lập chỉ mục và truy vấn dữ liệu vector trực tiếp trong cơ sở dữ liệu PostgreSQL của mình.
Sự tích hợp này mang sức mạnh của các phép toán vector vào hạ tầng PostgreSQL sẵn có, là lựa chọn tuyệt vời cho các ứng dụng liên quan đến embeddings, hệ thống gợi ý và tìm kiếm tương đồng.
Các tính năng của pgvector bao gồm:
Cơ sở dữ liệu vector là các hệ quản trị chuyên dụng để lưu trữ và truy vấn dữ liệu vector đa chiều. Năng lực này phù hợp với các ứng dụng học máy hiện đại, bao gồm hệ thống gợi ý, truy hồi hình ảnh và các bài toán xử lý ngôn ngữ tự nhiên.
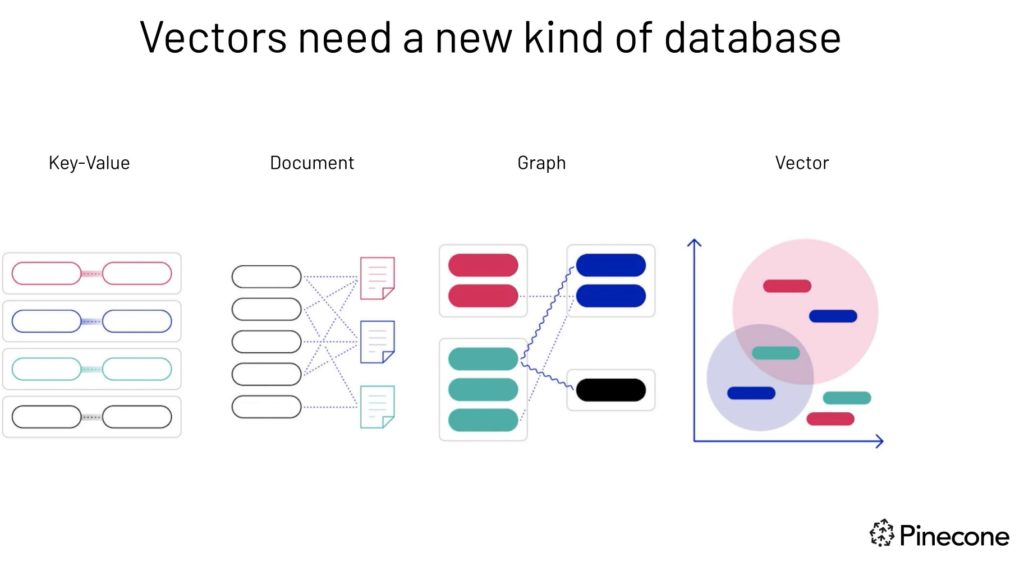
Vector cần một loại cơ sở dữ liệu mới—hình ảnh nguồn.
Các cơ sở dữ liệu quan hệ truyền thống gặp khó với dữ liệu có số chiều lớn và việc thực hiện tìm kiếm tương đồng một cách hiệu quả. Ngược lại, các cơ sở dữ liệu vector được tối ưu riêng cho các tác vụ này, cho phép truy hồi dữ liệu nhanh và chính xác dựa trên độ gần hoặc mức độ giống nhau của vector.
Cách tiếp cận này cho phép các tìm kiếm dựa trên mức độ liên quan về ngữ nghĩa hoặc ngữ cảnh, mang lại kết quả ý nghĩa hơn so với các tìm kiếm khớp chính xác của cơ sở dữ liệu truyền thống.
Ví dụ, một cơ sở dữ liệu vector có thể:
Vậy làm thế nào dữ liệu phi cấu trúc như văn bản hoặc hình ảnh có thể được chuyển thành con số? Câu trả lời là embeddings.
Embedding là quá trình chuyển đổi dữ liệu phi cấu trúc thành các vector số có kích thước cố định, nắm bắt ngữ nghĩa và mối quan hệ nội tại trong dữ liệu. Điều này được thực hiện thông qua các mạng nơ-ron lớn học cách biểu diễn dữ liệu trong một không gian vector liên tục, nơi các mục tương tự được đặt gần nhau.
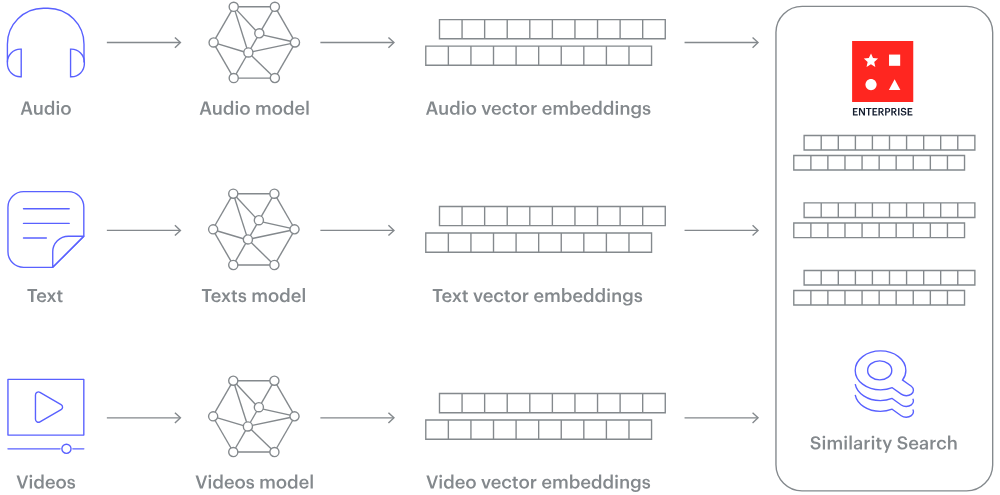
Cơ sở dữ liệu vector hoạt động như thế nào? Hình ảnh nguồn.
Phần này sẽ hướng dẫn thiết lập pgvector, sử dụng các tính năng cơ bản và xây dựng một ứng dụng đơn giản bằng cách tích hợp với OpenAI.
Chúng ta sẽ đề cập đến cài đặt, thao tác cơ bản, lập chỉ mục và tích hợp với Python và LangChain.
Để theo dõi hướng dẫn này, bạn nên có kiến thức cơ bản về SQL và PostgreSQL, cũng như quen thuộc với lập trình Python.
Trước khi bắt đầu, hãy đảm bảo bạn có:
1. Trước tiên, hãy đảm bảo bạn đã cài các tệp phát triển của PostgreSQL. Trên Ubuntu hoặc Debian, bạn có thể cài bằng:
sudo apt-get install postgresql-server-dev-allNếu bạn dùng Windows, có thể tải trình cài đặt PostgreSQL từ trang chính thức.
2. Clone kho GitHub của pgvector:
git clone https://github.com/pgvector/pgvector.git3. Biên dịch và cài đặt phần mở rộng pgvector:
cd pgvector
make
sudo make installNếu bạn dùng Windows, hãy đảm bảo đã cài hỗ trợ C++ trong Visual Studio Code. Tài liệu cài đặt chính thức cung cấp quy trình từng bước.
4. Kết nối tới cơ sở dữ liệu PostgreSQL của bạn:
Bạn có vài lựa chọn để kết nối và tương tác với PostgreSQL: pgAdmin là một trong những giao diện được dùng nhiều nhất. Ngoài ra, bạn có thể dùng pSQL (giao diện dòng lệnh của PostgreSQL) hoặc thậm chí một tiện ích mở rộng PostgreSQL cho VS Code.
5. Sau khi kết nối tới cơ sở dữ liệu PostgreSQL, hãy tạo phần mở rộng:
CREATE EXTENSION vector;
Giao diện pgAdmin
Sau khi cài pgvector, hãy khám phá cách dùng cơ bản.
1. Để thiết lập cơ sở dữ liệu vector đầu tiên trong PostgreSQL bằng phần mở rộng pgvector, hãy tạo một bảng để lưu dữ liệu vector:
CREATE TABLE items (
id SERIAL PRIMARY KEY,
embedding vector(3)
);Lệnh này tạo một bảng tên items với cột id và cột embedding kiểu vector(3), lưu các vector 3 chiều.
2. Bây giờ, hãy chèn một số dữ liệu vào bảng:
INSERT INTO items (embedding) VALUES ('[1,2,3]'), ('[4,5,6]'), ('[1,1,1]');3. Giờ bạn có thể thực hiện các phép toán vector. Ví dụ, để tìm láng giềng gần nhất với vector [2,3,4]:
SELECT * FROM items ORDER BY embedding <-> '[2,3,4]' LIMIT 1;Truy vấn này dùng toán tử <->, tính khoảng cách Euclid giữa các vector.
4. Bạn cũng có thể dùng các thước đo khoảng cách khác, như khoảng cách cosine:
SELECT * FROM items ORDER BY embedding <=> '[2,3,4]' LIMIT 1;Toán tử <=> tính khoảng cách cosine giữa các vector.
Lập chỉ mục trong cơ sở dữ liệu vector, bao gồm pgvector, là cần thiết để nâng cao hiệu năng tìm kiếm, đặc biệt khi bộ dữ liệu của bạn mở rộng.
Tầm quan trọng của lập chỉ mục là không thể xem nhẹ, vì nó mang lại nhiều lợi ích:
Có hai loại chỉ mục cho pgvector: ivfflat và hnsw. Chúng phục vụ các mục đích khác nhau:
Khi nào dùng từng loại chỉ mục:
1. Hãy tạo một chỉ mục ivfflat:
CREATE INDEX ON items USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);Lệnh này tạo chỉ mục bằng thuật toán IVFFlat, phù hợp cho tìm kiếm láng giềng gần nhất chính xác.
2. Với tìm kiếm láng giềng gần nhất xấp xỉ, ta có thể dùng chỉ mục hnsw:
CREATE INDEX ON items USING hnsw (embedding vector_l2_ops) WITH (m = 16, ef_construction = 64);Sau khi tạo chỉ mục, các truy vấn sẽ tự động sử dụng khi phù hợp.
Pgvector hỗ trợ tích hợp với một số framework, giúp tương tác với cơ sở dữ liệu vector dễ dàng hơn. Hãy điểm qua hai công cụ hữu ích: Python và LangChain.
pgvector có thể tích hợp dễ dàng với Python qua thư viện psycopg2. Hãy thiết lập môi trường Python và thực hiện một vài thao tác cơ bản.
1. Trước tiên, cài các thư viện cần thiết:
!pip install psycopg2-binary numpy2. Giờ hãy tạo một script Python để tương tác với cơ sở dữ liệu vector:
import psycopg2
import numpy as np
# Connect to the database
conn = psycopg2.connect("dbname=your_database user=your_username")
cur = conn.cursor()
# Insert a vector
embedding = np.array([1.5, 2.5, 3.5])
cur.execute("INSERT INTO items (embedding) VALUES (%s)", (embedding.tolist(),))
# Perform a similarity search
query_vector = np.array([2, 3, 4])
cur.execute("SELECT * FROM items ORDER BY embedding <-> %s LIMIT 1", (query_vector.tolist(),))
result = cur.fetchone()
print(f"Nearest neighbor: {result}")
conn.commit()
cur.close()
conn.close()Đoạn script này minh họa cách chèn một vector và thực hiện tìm kiếm tương đồng bằng Python.
pgvector cũng có thể tích hợp với LangChain, một framework phổ biến để phát triển ứng dụng với các mô hình ngôn ngữ lớn.
Dưới đây là ví dụ đơn giản về việc dùng pgvector làm kho vector trong LangChain:
from langchain_postgres.vectorstores import PGVector
from langchain.embeddings.openai import OpenAIEmbeddings
# Set up the connection string and embedding function
connection_string = "postgresql://user:pass@localhost:5432/db_name"
embedding_function = OpenAIEmbeddings()
# Create a PGVector instance
vector_store = PGVector.from_documents(
documents,
embedding_function,
connection_string=connection_string
)
# Perform a similarity search
query = "Your query here"
results = vector_store.similarity_search(query)Ví dụ này giả định bạn đã thiết lập embeddings của OpenAI và có danh sách tài liệu để tạo embedding.
Giờ hãy xây dựng một công cụ tìm kiếm ngữ nghĩa đơn giản bằng pgvector và embeddings của OpenAI!
Ứng dụng này cho phép người dùng tìm kiếm trong một tập hợp tài liệu văn bản bằng các truy vấn ngôn ngữ tự nhiên.
import openai
import psycopg2
import numpy as np
# Set up OpenAI API (replace with your actual API key)
openai.api_key = "your_openai_api_key"
# Connect to the database
conn = psycopg2.connect("dbname=your_database user=your_username")
cur = conn.cursor()
# Create a table for our documents
cur.execute("""
CREATE TABLE IF NOT EXISTS documents (
id SERIAL PRIMARY KEY,
content TEXT,
embedding vector(1536)
)
""")
# Function to get embeddings from OpenAI
def get_embedding(text):
response = openai.embeddings.create(input=text, model="text-embedding-ada-002")
return response['data'][0]['embedding']
# Function to add a document
def add_document(content):
embedding = get_embedding(content)
cur.execute("INSERT INTO documents (content, embedding) VALUES (%s, %s)", (content, embedding))
conn.commit()
# Function to search for similar documents
def search_documents(query, limit=5):
query_embedding = get_embedding(query)
cur.execute("""
SELECT content, embedding <-> %s AS distance
FROM documents
ORDER BY distance
LIMIT %s
""", (query_embedding, limit))
return cur.fetchall()
# Add some sample documents
sample_docs = [
"The quick brown fox jumps over the lazy dog.",
"Python is a high-level programming language.",
"Vector databases are essential for modern AI applications.",
"PostgreSQL is a powerful open-source relational database.",
]
for doc in sample_docs:
add_document(doc)
# Perform a search
search_query = "Tell me about programming languages"
results = search_documents(search_query)
print(f"Search results for: '{search_query}'")
for i, (content, distance) in enumerate(results, 1):
print(f"{i}. {content} (Distance: {distance:.4f})")
# Clean up
cur.close()
conn.close()Ứng dụng đơn giản này minh họa cách dùng pgvector để tạo một công cụ tìm kiếm ngữ nghĩa.
Ứng dụng mã hóa tài liệu bằng mô hình text embedding của OpenAI và lưu vào cơ sở dữ liệu PostgreSQL với pgvector. Hàm tìm kiếm tìm các tài liệu giống nhất với truy vấn sử dụng độ tương đồng cosine.
Khi ứng dụng mở rộng, bạn sẽ muốn tối ưu hóa pgvector. Dưới đây là một số gợi ý cấp cao:
Triển khai pooling kết nối để giảm chi phí khởi tạo. Dùng PgBouncer hoặc PgPool-II. Đây là những công cụ hữu ích vì chúng duy trì các kết nối cơ sở dữ liệu có thể tái sử dụng.
Điều chỉnh tham số chỉ mục khi chạy. Bạn có thể cân bằng tốc độ và độ chính xác theo nhu cầu.
Với chỉ mục IVFFlat, đặt tham số probes. Dùng 1-5 để ưu tiên tốc độ. Dùng 10-20 để cân bằng.
Với chỉ mục HNSW, tinh chỉnh ef_search. Dùng 20-40 cho tốc độ. Dùng 100-200 cho độ chính xác.
Ngoài ra, bạn có thể dùng EXPLAIN ANALYZE để xác nhận việc sử dụng chỉ mục. Luôn thêm LIMIT trong truy vấn.
Triển khai caching với Redis hoặc Memcached. Cache các vector được truy vấn thường xuyên. Dùng vector truy vấn làm khóa cache. Đặt thời gian hết hạn phù hợp.
Thiết lập các bản sao chỉ đọc của PostgreSQL cho khối lượng công việc đọc nặng. Điều hướng ghi vào cơ sở dữ liệu chính. Điều hướng tìm kiếm vector đến các bản sao. Dùng bộ cân bằng tải để phân phối tự động.
Điều chỉnh các tham số chính cho khối lượng công việc vector:
shared_buffers: Đặt bằng 25% tổng RAM
work_mem: Đặt 64–128MB cho thao tác vector
random_page_cost: Giảm khi dùng lưu trữ SSD
effective_cache_size: Đặt 50–75% tổng RAM
Tái tạo chỉ mục định kỳ vào thời điểm ít lưu lượng. Chạy VACUUM và ANALYZE. Bật autovacuum để tự động bảo trì.
Theo dõi độ trễ truy vấn và số truy vấn mỗi giây. Giám sát mức sử dụng pool kết nối. Kiểm tra tỷ lệ trúng cache. Theo dõi việc sử dụng tài nguyên. Thiết lập cảnh báo cho các vấn đề hiệu năng. Bật pg_stat_statements để xác định truy vấn chậm.
Bây giờ, hãy so sánh pgvector với các cơ sở dữ liệu vector phổ biến khác. Phần so sánh này sẽ giúp bạn hiểu sự khác biệt về tính năng, phương án triển khai, khả năng mở rộng, tích hợp và chi phí giữa pgvector và các giải pháp khác trên thị trường.
Pinecone là cơ sở dữ liệu vector được quản lý hoàn toàn, thiết kế cho khả năng mở rộng cao và dễ sử dụng.
|
Tính năng |
pgvector |
Pinecone |
|
Loại cơ sở dữ liệu |
Phần mở rộng cho PostgreSQL |
Cơ sở dữ liệu vector được quản lý hoàn toàn |
|
Triển khai |
Tự quản |
Dựa trên đám mây |
|
Khả năng mở rộng |
Bị giới hạn bởi PostgreSQL |
Rất mở rộng |
|
Tích hợp |
Hoạt động với stack PostgreSQL sẵn có |
Cần tích hợp riêng |
|
Chi phí |
Miễn phí, mã nguồn mở |
Tính phí theo mức sử dụng |
pgvector là lựa chọn tuyệt vời cho những ai muốn tận dụng hạ tầng PostgreSQL hiện có mà không phát sinh chi phí. Trong khi đó, Pinecone cung cấp giải pháp được quản lý, có khả năng mở rộng cao với mô hình tính phí theo mức sử dụng, dễ tiếp cận.
Milvus là cơ sở dữ liệu vector chuyên dụng, cung cấp các tính năng nâng cao và khả năng mở rộng cao.
|
Tính năng |
pgvector |
Milvus |
|
Loại cơ sở dữ liệu |
Phần mở rộng cho PostgreSQL |
Cơ sở dữ liệu vector chuyên dụng |
|
Triển khai |
Tự quản |
Tự quản hoặc đám mây |
|
Khả năng mở rộng |
Bị giới hạn bởi PostgreSQL |
Rất mở rộng |
|
Tích hợp |
Hoạt động với stack PostgreSQL sẵn có |
Cần tích hợp riêng |
|
Tập tính năng |
Các thao tác vector cơ bản |
Tính năng nâng cao như schema động |
Trong khi pgvector cung cấp các thao tác vector cơ bản trong môi trường PostgreSQL quen thuộc, Milvus mang lại giải pháp giàu tính năng và có khả năng mở rộng cao, chuyên cho xử lý dữ liệu vector quy mô lớn.
Weaviate là cơ sở dữ liệu vector tích hợp lưu trữ đối tượng, cung cấp mô hình dữ liệu linh hoạt và khả năng mở rộng.
|
Tính năng |
pgvector |
Weaviate |
|
Loại cơ sở dữ liệu |
Phần mở rộng cho PostgreSQL |
Cơ sở dữ liệu vector với lưu trữ đối tượng |
|
Triển khai |
Tự quản |
Tự quản hoặc đám mây |
|
Khả năng mở rộng |
Bị giới hạn bởi PostgreSQL |
Thiết kế để mở rộng |
|
Tích hợp |
Hoạt động với stack PostgreSQL sẵn có |
Cần tích hợp riêng |
|
Mô hình dữ liệu |
Chỉ vector |
Đối tượng với vector và thuộc tính |
Sự đơn giản và khả năng tích hợp với PostgreSQL khiến pgvector phù hợp với người dùng hiện tại cần chức năng vector cơ bản. Trong khi đó, mô hình dữ liệu tinh vi và khả năng mở rộng của Weaviate phù hợp với các ứng dụng phức tạp đòi hỏi lưu trữ đối tượng cùng với vector.
pgvector mang đến khả năng tìm kiếm tương đồng vector mạnh mẽ cho PostgreSQL, là lựa chọn tuyệt vời cho các nhà phát triển muốn bổ sung tính năng chạy bằng AI vào các ứng dụng dựa trên PostgreSQL hiện có.
Trong hướng dẫn này, chúng ta đã tìm hiểu cài đặt, cách dùng cơ bản, khả năng lập chỉ mục và tích hợp với Python cùng LangChain.
Dù pgvector có thể không mang lại khả năng mở rộng và các tính năng chuyên sâu như những cơ sở dữ liệu vector chuyên dụng như Pinecone hay Milvus, sự tích hợp liền mạch với PostgreSQL khiến nó hấp dẫn cho nhiều trường hợp sử dụng.
Nó đặc biệt phù hợp với các dự án đã dùng PostgreSQL và cần bổ sung khả năng tìm kiếm vector mà không phải đưa thêm một hệ quản trị cơ sở dữ liệu mới.
Chúng tôi khuyến khích bạn thử pgvector trong chính dự án của mình. Dù bạn xây dựng hệ thống gợi ý, công cụ tìm kiếm ngữ nghĩa hay bất kỳ ứng dụng nào cần tìm kiếm tương đồng, pgvector có thể là công cụ giá trị trong bộ công cụ khoa học dữ liệu của bạn.
Để học thêm, hãy khám phá các khóa học của chúng tôi:
Tìm hiểu thêm về machine learning và AI với các khóa học này!
Courses
Courses
Courses