
Curso
Conceptos de la IA generativa
2 h
105.1K
La búsqueda vectorial se ha vuelto cada vez más popular en los últimos años, gracias a todos los avances en el ecosistema de la IA generativa y los modelos de lenguaje grandes.
La búsqueda vectorial es un método de recuperación de información en el que los documentos y las consultas se representan como vectores en lugar de texto sin formato. Esta representación numérica se obtiene mediante el uso de una gran red neuronal entrenada que puede convertir datos no estructurados, como texto, imágenes y vídeos, en vectores.
Las bases de datos relacionales tradicionales no están optimizadas para manejar grandes volúmenes de datos vectoriales. Por lo tanto, en los últimos años han surgido muchas bases de datos vectoriales exclusivas, tanto de código abierto como propietarias. Sin embargo, puede que no sea ideal para todas las empresas tener una base de datos dedicada exclusivamente a los vectores, separada de la base de datos principal.
Te presentamos pgvector, una potente extensión para PostgreSQL que aporta capacidades de búsqueda por similitud vectorial a una de las bases de datos relacionales más populares.
En este tutorial, exploraremos las características de pgvector y demostraremos cómo puede ayudarte en tu trabajo.
pgvector es una extensión de código abierto para PostgreSQL que añade compatibilidad con operaciones vectoriales y búsquedas por similitud. Te permite almacenar, indexar y consultar datos vectoriales directamente en tu base de datos PostgreSQL.
Esta integración aporta la potencia de las operaciones vectoriales a tu infraestructura PostgreSQL existente, lo que la convierte en una opción excelente para aplicaciones que implican incrustaciones, sistemas de recomendación y búsquedas por similitud.
Las características de pgvector incluyen:
Las bases de datos vectoriales son bases de datos especializadas diseñadas para almacenar y consultar datos vectoriales multidimensionales. Esta capacidad es relevante en las aplicaciones modernas de machine learning, incluidos los sistemas de recomendación, la recuperación de imágenes y los casos de uso del procesamiento del lenguaje natural.
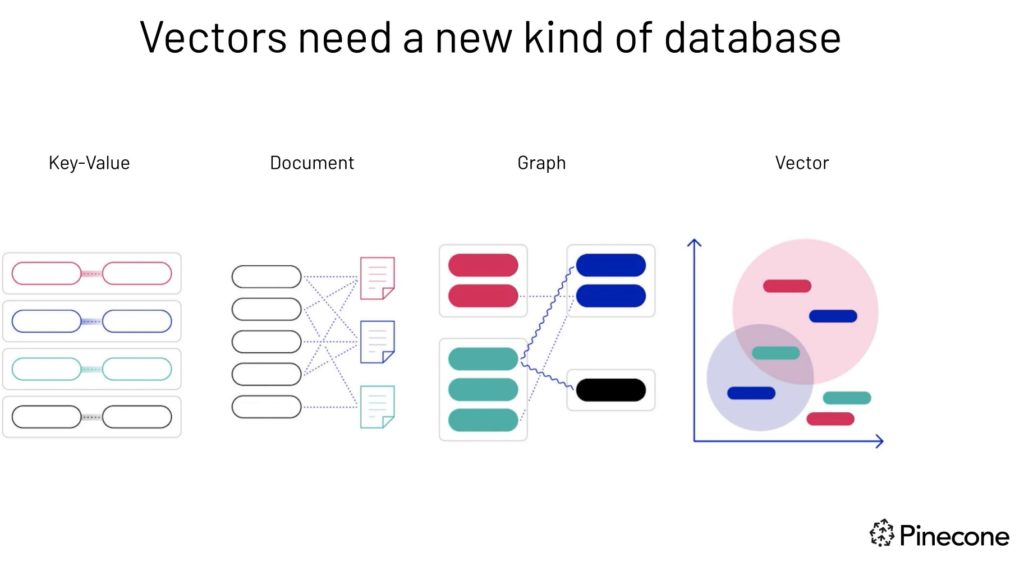
Los vectores necesitan un nuevo tipo de base de datos: fuente de imágenes.
Las bases de datos relacionales tradicionales tienen dificultades para manejar datos de alta dimensión y realizar búsquedas de similitud de manera eficiente. Sin embargo, las bases de datos vectoriales están específicamente optimizadas para estas tareas, lo que permite una recuperación rápida y precisa de los datos basada en la proximidad o similitud vectorial.
Este enfoque permite realizar búsquedas basadas en la relevancia semántica o contextual, lo que proporciona resultados más significativos en comparación con las búsquedas de coincidencia exacta de las bases de datos convencionales.
Por ejemplo, una base de datos vectorial puede:
Entonces, ¿cómo se pueden convertir en números datos no estructurados como texto o imágenes? La respuesta es «incrustaciones».
La incrustación es un proceso que transforma datos no estructurados en vectores numéricos de tamaño fijo, capturando la semántica y las relaciones inherentes a los datos. Esto se logra mediante grandes redes neuronales que aprenden a representar los datos en un espacio vectorial continuo, donde los elementos similares se posicionan más cerca unos de otros.
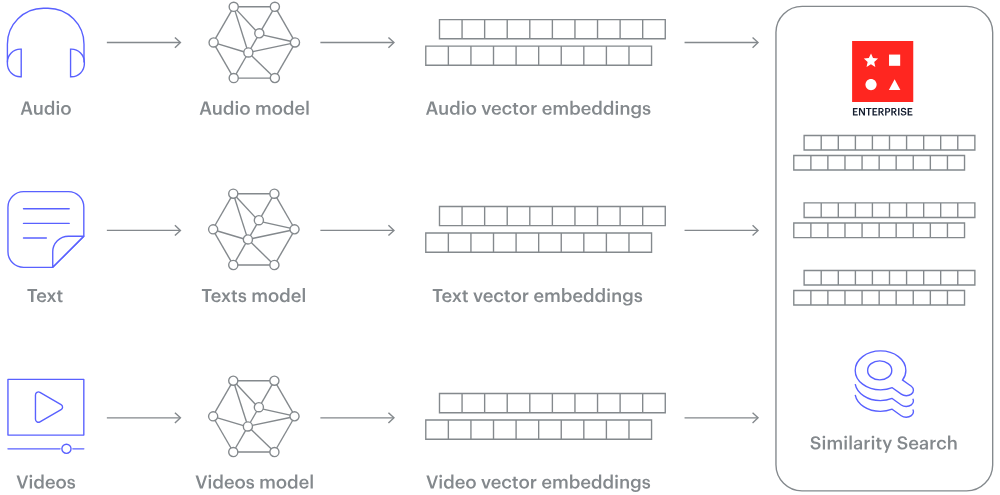
¿Cómo funciona una base de datos vectorial? Fuente de la imagen.
En esta sección, veremos cómo configurar pgvector, utilizar sus funciones básicas y crear una aplicación sencilla integrándola con OpenAI.
Cubriremos la instalación, las operaciones básicas, la indexación y la integración con Python y LangChain.
Para seguir este tutorial, debes tener conocimientos básicos de SQL y PostgreSQL y estar familiarizado con la programación en Python.
Antes de comenzar, asegúrate de que dispones de lo siguiente:
1. En primer lugar, asegúrate de que tienes instalados los archivos de desarrollo de PostgreSQL. En Ubuntu o Debian, puedes instalarlos con:
sudo apt-get install postgresql-server-dev-allSi eres usuario de Windows, puedes descargar el instalador de PostgreSQL desde el sitio web oficial.
2. Clona el repositorio GitHub pgvector:
git clone https://github.com/pgvector/pgvector.git3. Compila e instala la extensión pgvector:
cd pgvector
make
sudo make installSi eres usuario de Windows, asegúrate de tener instalado el soporte para C++ en Visual Studio Code. La documentación oficial de instalación proporciona un proceso paso a paso.
4. Conéctate a tu base de datos PostgreSQL:
Tienes varias opciones para conectarte e interactuar con la base de datos PostgreSQL: pgAdmin es una de las interfaces más utilizadas. Como alternativa, puedes utilizar pSQL (interfaz de línea de comandos de PostgreSQL) o incluso una extensión de VS Code para PostgreSQL.
5. Después de conectarte a tu base de datos PostgreSQL, crea la extensión:
CREATE EXTENSION vector;
pgAdmin Interface
Ahora que ya tenemos pgvector instalado, veamos su uso básico.
1. Para configurar nuestra primera base de datos vectorial en PostgreSQL utilizando la extensión pgvector, creemos una tabla para almacenar nuestros datos vectoriales:
CREATE TABLE items (
id SERIAL PRIMARY KEY,
embedding vector(3)
);Esto crea una tabla llamada « items » con una columna « id » y una columna « embedding » de tipo « vector(3) », que almacenará vectores tridimensionales.
2. Ahora, insertemos algunos datos en nuestra tabla:
INSERT INTO items (embedding) VALUES ('[1,2,3]'), ('[4,5,6]'), ('[1,1,1]');3. Ahora podemos realizar operaciones vectoriales. Por ejemplo, para encontrar el vecino más cercano al vector [2,3,4]:
SELECT * FROM items ORDER BY embedding <-> '[2,3,4]' LIMIT 1;Esta consulta utiliza el operador <->, que calcula la distancia euclídea entre vectores.
4. También podemos utilizar otras métricas de distancia, como la distancia coseno:
SELECT * FROM items ORDER BY embedding <=> '[2,3,4]' LIMIT 1;El operador <=> calcula la distancia coseno entre vectores.
La indexación en bases de datos vectoriales, incluida pgvector, es necesaria para mejorar el rendimiento de las búsquedas, especialmente a medida que tu conjunto de datos se amplía.
No se puede subestimar la importancia de la indexación, ya que ofrece varias ventajas:
Hay dos tipos de índices disponibles para pgvector: ivfflat y hnsw. Ambos tienen fines diferentes:
Cuándo utilizar cada índice:
1. Creemos un índice e ivfflat:
CREATE INDEX ON items USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);Esto crea un índice utilizando el algoritmo IVFFlat, que es adecuado para búsquedas exactas de vecinos más cercanos.
2. Para búsquedas aproximadas del vecino más cercano, podemos utilizar el índice de búsqueda aproximada ( hnsw ):
CREATE INDEX ON items USING hnsw (embedding vector_l2_ops) WITH (m = 16, ef_construction = 64);Después de crear un índice, nuestras consultas lo utilizarán automáticamente cuando sea apropiado.
Pgvector admite la integración con varios marcos, lo que facilita la interacción con nuestra base de datos vectorial. Repasemos dos que son útiles: Python y LangChain.
pgvector se puede integrar fácilmente con Python utilizando la biblioteca psycopg2. Configuremos un entorno Python y realicemos algunas operaciones básicas.
1. En primer lugar, instala las bibliotecas necesarias:
!pip install psycopg2-binary numpy2. Ahora, creemos un script de Python para interactuar con nuestra base de datos vectorial:
import psycopg2
import numpy as np
# Connect to the database
conn = psycopg2.connect("dbname=your_database user=your_username")
cur = conn.cursor()
# Insert a vector
embedding = np.array([1.5, 2.5, 3.5])
cur.execute("INSERT INTO items (embedding) VALUES (%s)", (embedding.tolist(),))
# Perform a similarity search
query_vector = np.array([2, 3, 4])
cur.execute("SELECT * FROM items ORDER BY embedding <-> %s LIMIT 1", (query_vector.tolist(),))
result = cur.fetchone()
print(f"Nearest neighbor: {result}")
conn.commit()
cur.close()
conn.close()Este script muestra cómo insertar un vector y realizar una búsqueda por similitud utilizando Python.
pgvector también se puede integrar con LangChain, un popular marco para desarrollar aplicaciones con grandes modelos de lenguaje.
A continuación, se muestra un ejemplo sencillo de cómo utilizar pgvector como almacén vectorial en LangChain:
from langchain_postgres.vectorstores import PGVector
from langchain.embeddings.openai import OpenAIEmbeddings
# Set up the connection string and embedding function
connection_string = "postgresql://user:pass@localhost:5432/db_name"
embedding_function = OpenAIEmbeddings()
# Create a PGVector instance
vector_store = PGVector.from_documents(
documents,
embedding_function,
connection_string=connection_string
)
# Perform a similarity search
query = "Your query here"
results = vector_store.similarity_search(query)Este ejemplo asume que has configurado las incrustaciones de OpenAI y que tienes una lista de documentos para incrustar.
Ahora, ¡creemos un motor de búsqueda semántica sencillo utilizando pgvector y las incrustaciones de OpenAI!
Esta aplicación permitirá a los usuarios realizar búsquedas en una colección de documentos de texto utilizando consultas en lenguaje natural.
import openai
import psycopg2
import numpy as np
# Set up OpenAI API (replace with your actual API key)
openai.api_key = "your_openai_api_key"
# Connect to the database
conn = psycopg2.connect("dbname=your_database user=your_username")
cur = conn.cursor()
# Create a table for our documents
cur.execute("""
CREATE TABLE IF NOT EXISTS documents (
id SERIAL PRIMARY KEY,
content TEXT,
embedding vector(1536)
)
""")
# Function to get embeddings from OpenAI
def get_embedding(text):
response = openai.embeddings.create(input=text, model="text-embedding-ada-002")
return response['data'][0]['embedding']
# Function to add a document
def add_document(content):
embedding = get_embedding(content)
cur.execute("INSERT INTO documents (content, embedding) VALUES (%s, %s)", (content, embedding))
conn.commit()
# Function to search for similar documents
def search_documents(query, limit=5):
query_embedding = get_embedding(query)
cur.execute("""
SELECT content, embedding <-> %s AS distance
FROM documents
ORDER BY distance
LIMIT %s
""", (query_embedding, limit))
return cur.fetchall()
# Add some sample documents
sample_docs = [
"The quick brown fox jumps over the lazy dog.",
"Python is a high-level programming language.",
"Vector databases are essential for modern AI applications.",
"PostgreSQL is a powerful open-source relational database.",
]
for doc in sample_docs:
add_document(doc)
# Perform a search
search_query = "Tell me about programming languages"
results = search_documents(search_query)
print(f"Search results for: '{search_query}'")
for i, (content, distance) in enumerate(results, 1):
print(f"{i}. {content} (Distance: {distance:.4f})")
# Clean up
cur.close()
conn.close()Esta sencilla aplicación muestra cómo utilizar pgvector para crear un motor de búsqueda semántica.
Incrustas documentos utilizando el modelo de incrustación de texto de OpenAI y los almacenas en una base de datos PostgreSQL con pgvector. La función de búsqueda encuentra los documentos más similares a una consulta determinada utilizando la similitud coseno.
Querrás optimizar pgvector a medida que tu aplicación crezca. Aquí tienes algunas sugerencias generales:
Implementa el agrupamiento de conexiones para reducir la sobrecarga. Utiliza PgBouncer o PgPool-II. Es bueno conocer estas herramientas porque mantienen conexiones de base de datos reutilizables.
Ajusta los parámetros del índice en tiempo de ejecución. Puedes equilibrar la velocidad y la precisión en función de tus necesidades.
Para los índices IVFFlat, configura el parámetro probes. Utiliza del 1 al 5 para la velocidad. Utiliza 10-20 para obtener un rendimiento equilibrado.
Para los índices HNSW, sintoniza ef_search. Usa 20-40 para la velocidad. Utiliza 100-200 para mayor precisión.
Además, puedes utilizar EXPLAIN ANALYZE para verificar el uso del índice. Incluye siempre cláusulas « LIMIT » en las consultas.
Implementa el almacenamiento en caché con Redis o Memcached. Almacenar en caché los vectores consultados con frecuencia. Utiliza el vector de consulta como clave de caché. Establece tiempos de caducidad adecuados.
Configura réplicas de lectura de PostgreSQL para cargas de trabajo con un uso intensivo de lectura. La ruta escribe en la base de datos principal. Dirige las búsquedas de vectores a las réplicas. Utiliza equilibradores de carga para la distribución automática.
Ajusta los parámetros clave para las cargas de trabajo vectoriales:
shared_buffers: Establecer en el 25 % de la RAM total.
work_mem: Configura entre 64 y 128 MB para operaciones vectoriales.
random_page_cost: Menor para almacenamiento SSD
effective_cache_size: Configura entre el 50 y el 75 % de la RAM total.
Reconstruye los índices periódicamente durante los periodos de poco tráfico. Ejecuta VACUUM y ANALYZE. Habilita autovacuum para el mantenimiento automático.
Programa el seguimiento de la latencia de las consultas y las consultas por segundo. Supervisa la utilización del grupo de conexiones. Comprueba los índices de aciertos de la caché. Controla el uso de los recursos. Configura alertas para problemas de rendimiento. Habilita pg_stat_statements para identificar consultas lentas.
Ahora, comparemos pgvector con otras bases de datos vectoriales populares. Esta comparación te ayudará a comprender las diferencias en cuanto a características, opciones de implementación, escalabilidad, integración y coste entre pgvector y otras soluciones disponibles en el mercado.
Pinecone es una base de datos vectorial totalmente gestionada, diseñada para ofrecer una alta escalabilidad y facilidad de uso.
|
Característica |
pgvector |
Piña |
|
Tipo de base de datos |
Extensión para PostgreSQL |
Base de datos vectorial totalmente gestionada |
|
Implementación |
Autoalojado |
Basado en la nube |
|
Escalabilidad |
Limitado por PostgreSQL |
Altamente escalable |
|
Integración |
Funciona con la pila PostgreSQL existente. |
Requiere integración por separado. |
|
Coste |
Gratuito, de código abierto |
Precios de pago por uso |
pgvector es una excelente opción para quienes desean aprovechar su infraestructura PostgreSQL existente sin costes adicionales. Al mismo tiempo, Pinecone ofrece una solución gestionada y altamente escalable con precios de pago por uso para facilitar su uso.
Milvus es una base de datos vectorial especializada que ofrece funciones avanzadas y una gran escalabilidad.
|
Característica |
pgvector |
Milvus |
|
Tipo de base de datos |
Extensión para PostgreSQL |
Base de datos vectorial dedicada |
|
Implementación |
Autoalojado |
Autoalojado o en la nube |
|
Escalabilidad |
Limitado por PostgreSQL |
Altamente escalable |
|
Integración |
Funciona con la pila PostgreSQL existente. |
Requiere integración por separado. |
|
Conjunto de funciones |
Operaciones vectoriales básicas |
Funciones avanzadas como el esquema dinámico |
Mientras que pgvector proporciona operaciones vectoriales básicas dentro del entorno familiar de PostgreSQL, Milvus ofrece una solución más rica en funciones y escalable, específica para manejar datos vectoriales a gran escala.
Weaviate es una base de datos vectorial con almacenamiento de objetos integrado que ofrece un modelado de datos flexible y escalabilidad.
|
Característica |
pgvector |
Weaviate |
|
Tipo de base de datos |
Extensión para PostgreSQL |
Base de datos vectorial con almacenamiento de objetos |
|
Implementación |
Autoalojado |
Autoalojado o en la nube |
|
Escalabilidad |
Limitado por PostgreSQL |
Diseñado para ser escalable |
|
Integración |
Funciona con la pila PostgreSQL existente. |
Requiere integración por separado. |
|
Modelo de datos |
Solo vectores |
Objetos con vectores y propiedades |
La simplicidad de pgvector y su integración con PostgreSQL lo convierten en una buena opción para los usuarios actuales que necesitan funcionalidades vectoriales básicas. Por el contrario, el modelo de datos más sofisticado y la escalabilidad de Weaviate son adecuados para aplicaciones complejas que requieren almacenamiento de objetos junto con vectores.
pgvector aporta potentes capacidades de búsqueda por similitud vectorial a PostgreSQL, lo que lo convierte en una excelente opción para los programadores que desean añadir funciones basadas en inteligencia artificial a sus aplicaciones existentes basadas en PostgreSQL.
En este tutorial, hemos explorado su instalación, uso básico, capacidades de indexación e integración con Python y LangChain.
Aunque pgvector puede no ofrecer la misma escalabilidad y características especializadas que las bases de datos vectoriales dedicadas como Pinecone o Milvus, su perfecta integración con PostgreSQL lo convierte en una opción atractiva para muchos casos de uso.
Es especialmente adecuado para proyectos que ya utilizan PostgreSQL y necesitan añadir capacidades de búsqueda vectorial sin introducir un nuevo sistema de base de datos.
Te animamos a que pruebes pgvector en tus propios proyectos. Tanto si estás creando un sistema de recomendaciones, un motor de búsqueda semántica o cualquier otra aplicación que requiera búsquedas por similitud, pgvector puede ser una herramienta muy valiosa en tu kit de herramientas de ciencia de datos.
Para seguir aprendiendo, explora nuestros cursos:
¡Aprende más sobre el machine learning y la inteligencia artificial con estos cursos!
Curso
Curso
Curso
blog
Moez Ali
14 min
blog
Tutorial
Avinash Navlani
Tutorial
Javier Canales Luna
Tutorial
Arunn Thevapalan
Tutorial


