
Kurs
Konzeptuelle Einführung in generative KI
2 Std.
105.3K
Die Vektorsuche ist in den letzten Jahren immer beliebter geworden, dank der Fortschritte in der generativen KI und im Large Language Model Ökosystem.
Die Vektorsuche ist eine Methode der Informationsbeschaffung, bei der Dokumente und Abfragen als Vektoren und nicht als reiner Text dargestellt werden. Diese numerische Darstellung wird mit Hilfe eines großen, trainierten neuronalen Netzwerks erreicht, das unstrukturierte Daten wie Text, Bilder und Videos in Vektoren umwandeln kann.
Herkömmliche relationale Datenbanken sind nicht für die Verarbeitung großer Mengen von Vektordaten optimiert. Daher sind in den letzten Jahren viele Open-Source- und proprietäre exklusive Vektordatenbanken entstanden. Allerdings ist es vielleicht nicht für alle Unternehmen ideal, eine eigene Datenbank nur für Vektoren zu haben, die von der Hauptdatenbank getrennt ist.
Hier kommt pgvector ins Spiel, eine leistungsstarke Erweiterung für PostgreSQL, die eine der beliebtesten relationalen Datenbanken um die Möglichkeit der vektoriellen Ähnlichkeitssuche erweitert.
In diesem Tutorial werden wir die Funktionen von pgvector erkunden und zeigen, wie es dir bei deiner Arbeit helfen kann.
pgvector ist eine Open-Source-Erweiterung für PostgreSQL, die Unterstützung für Vektoroperationen und Ähnlichkeitssuchen bietet. Damit kannst du Vektordaten direkt in deiner PostgreSQL-Datenbank speichern, indizieren und abfragen.
Diese Integration bringt die Leistungsfähigkeit von Vektoroperationen in deine bestehende PostgreSQL-Infrastruktur und ist damit eine ausgezeichnete Wahl für Anwendungen, die Einbettungen, Empfehlungssysteme und Ähnlichkeitssuchen beinhalten.
Zu den Funktionen von pgvector gehören:
Vektordatenbanken sind spezielle Datenbanken, die für die Speicherung und Abfrage mehrdimensionaler Vektordaten entwickelt wurden. Diese Fähigkeit ist für moderne Anwendungen des maschinellen Lernens von Bedeutung, z. B. für Empfehlungssysteme, Bildabfragen und die Verarbeitung natürlicher Sprache.
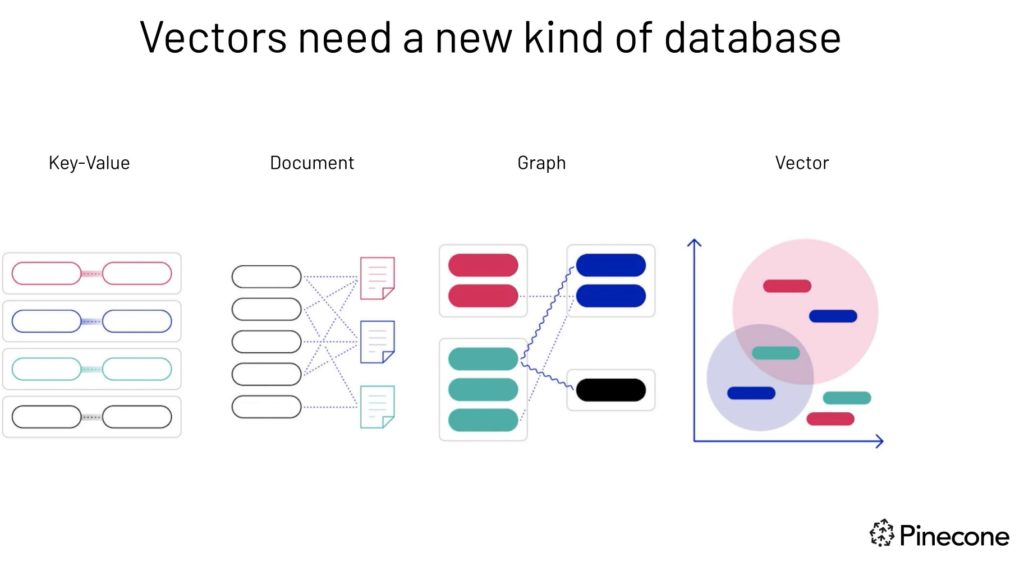
Vektoren brauchen eine neue Art von Datenbank-Bilderquelle.
Herkömmliche relationale Datenbanken haben Schwierigkeiten mit hochdimensionalen Daten und der effizienten Durchführung von Ähnlichkeitssuchen. Vektordatenbanken sind jedoch speziell für diese Aufgaben optimiert und ermöglichen ein schnelles und präzises Abrufen von Daten auf der Grundlage von Vektornähe oder Ähnlichkeit.
Dieser Ansatz ermöglicht Suchen, die auf semantischer oder kontextbezogener Relevanz beruhen, und liefert so aussagekräftigere Ergebnisse als die exakte Suche in herkömmlichen Datenbanken.
Eine Vektordatenbank kann zum Beispiel:
Wie können also unstrukturierte Daten wie Text oder Bilder in Zahlen umgewandelt werden? Die Antwort lautet: Einbettungen.
Die Einbettung ist ein Prozess, der unstrukturierte Daten in numerische Vektoren fester Größe umwandelt und die den Daten innewohnende Semantik und Beziehungen erfasst. Dies wird durch große neuronale Netze erreicht, die lernen, die Daten in einem kontinuierlichen Vektorraum darzustellen, in dem ähnliche Elemente näher beieinander liegen.
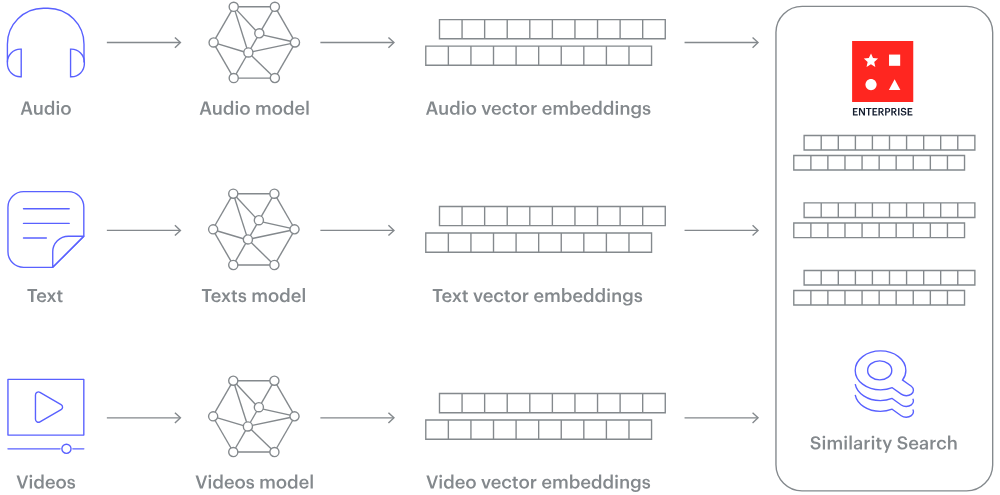
Wie funktioniert eine Vektordatenbank? Bildquelle.
In diesem Tutorial werden wir pgvector einrichten, seine grundlegenden Funktionen nutzen und eine einfache Anwendung erstellen, indem wir es mit OpenAI integrieren.
Wir beschäftigen uns mit der Installation, den grundlegenden Operationen, der Indizierung und der Integration mit Python und LangChain.
Um diesem Tutorial zu folgen, solltest du Grundkenntnisse in SQL und PostgreSQL haben und mit der Programmierung in Python vertraut sein.
Bevor wir beginnen, stelle sicher, dass du die folgenden Dinge hast:
1. Stelle zunächst sicher, dass du die PostgreSQL-Entwicklungsdateien installiert hast. Unter Ubuntu oder Debian kannst du sie mit installieren:
sudo apt-get install postgresql-server-dev-allWenn du ein Windows-Benutzer bist, kannst du den PostgreSQL-Installer von der offiziellen Website herunterladen.
2. Klone das pgvector GitHub Repository:
git clone https://github.com/pgvector/pgvector.git3. Erstelle und installiere die Erweiterung pgvector:
cd pgvector
make
sudo make installWenn du ein Windows-Benutzer bist, stelle sicher, dass du die C++-Unterstützung in Visual Studio Code installiert hast. In der offiziellen Installationsdokumentation findest du eine Schritt-für-Schritt-Anleitung.
4. Verbinde dich mit deiner PostgreSQL-Datenbank:
Du hast mehrere Möglichkeiten, dich mit der PostgreSQL-Datenbank zu verbinden und mit ihr zu interagieren: pgAdmin ist eine der am häufigsten verwendeten Schnittstellen. Alternativ kannst du auch pSQL (PostgreSQL Command Line Interface) oder sogar eine VS Code-Erweiterung für PostgreSQL verwenden.
5. Nachdem du dich mit deiner PostgreSQL-Datenbank verbunden hast, erstellst du die Erweiterung:
CREATE EXTENSION vector;
pgAdmin Schnittstelle
Jetzt, wo wir pgvector installiert haben, wollen wir seine grundlegende Verwendung erkunden.
1. Um unsere erste Vektordatenbank in PostgreSQL mit der pgvector-Erweiterung einzurichten, legen wir eine Tabelle an, in der wir unsere Vektordaten speichern:
CREATE TABLE items (
id SERIAL PRIMARY KEY,
embedding vector(3)
);Dadurch wird eine Tabelle namens items mit einer Spalte id und einer Spalte embedding vom Typ vector(3) erstellt, in der 3-dimensionale Vektoren gespeichert werden.
2. Fügen wir nun einige Daten in unsere Tabelle ein:
INSERT INTO items (embedding) VALUES ('[1,2,3]'), ('[4,5,6]'), ('[1,1,1]');3. Jetzt können wir Vektoroperationen durchführen. Zum Beispiel, um den nächsten Nachbarn des Vektors [2,3,4] zu finden:
SELECT * FROM items ORDER BY embedding <-> '[2,3,4]' LIMIT 1;Diese Abfrage verwendet den <-> Operator, der den euklidischen Abstand zwischen Vektoren berechnet.
4. Wir können auch andere Abstandsmetriken verwenden, z. B. den Kosinusabstand:
SELECT * FROM items ORDER BY embedding <=> '[2,3,4]' LIMIT 1;Der <=> Operator berechnet den Kosinusabstand zwischen Vektoren.
Die Indizierung in Vektordatenbanken, einschließlich pgvector, ist notwendig, um die Suchleistung zu verbessern, insbesondere wenn dein Datensatz wächst.
Die Bedeutung der Indexierung kann gar nicht hoch genug eingeschätzt werden, denn sie bietet mehrere Vorteile:
Es gibt zwei Arten von Indizes für pgvector: ivfflat und hnsw. Sie dienen beide unterschiedlichen Zwecken:
Wann ist welcher Index zu verwenden?
1. Lass uns einen ivfflat Index erstellen:
CREATE INDEX ON items USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);Dabei wird ein Index mit dem IVFFlat-Algorithmus erstellt, der für die exakte Suche nach den nächsten Nachbarn geeignet ist.
2. Für die ungefähre Suche nach dem nächsten Nachbarn können wir den Index hnsw verwenden:
CREATE INDEX ON items USING hnsw (embedding vector_l2_ops) WITH (m = 16, ef_construction = 64);Nachdem wir einen Index erstellt haben, werden unsere Abfragen ihn bei Bedarf automatisch verwenden.
Pgvector unterstützt die Integration mit einigen Frameworks, was die Interaktion mit unserer Vektordatenbank vereinfacht. Schauen wir uns zwei hilfreiche davon an: Python und LangChain.
pgvector lässt sich mit der Bibliothek psycopg2 leicht in Python integrieren. Richten wir eine Python-Umgebung ein und führen einige grundlegende Operationen durch.
1. Installiere zunächst die erforderlichen Bibliotheken:
!pip install psycopg2-binary numpy2. Nun wollen wir ein Python-Skript erstellen, das mit unserer Vektordatenbank interagiert:
import psycopg2
import numpy as np
# Connect to the database
conn = psycopg2.connect("dbname=your_database user=your_username")
cur = conn.cursor()
# Insert a vector
embedding = np.array([1.5, 2.5, 3.5])
cur.execute("INSERT INTO items (embedding) VALUES (%s)", (embedding.tolist(),))
# Perform a similarity search
query_vector = np.array([2, 3, 4])
cur.execute("SELECT * FROM items ORDER BY embedding <-> %s LIMIT 1", (query_vector.tolist(),))
result = cur.fetchone()
print(f"Nearest neighbor: {result}")
conn.commit()
cur.close()
conn.close()Dieses Skript zeigt, wie man mit Python einen Vektor einfügt und eine Ähnlichkeitssuche durchführt.
pgvector kann auch mit LangChain integriert werden, einem beliebten Framework für die Entwicklung von Anwendungen mit großen Sprachmodellen.
Hier ist ein einfaches Beispiel, wie du pgvector als Vektorspeicher in LangChain verwenden kannst:
from langchain_postgres.vectorstores import PGVector
from langchain.embeddings.openai import OpenAIEmbeddings
# Set up the connection string and embedding function
connection_string = "postgresql://user:pass@localhost:5432/db_name"
embedding_function = OpenAIEmbeddings()
# Create a PGVector instance
vector_store = PGVector.from_documents(
documents,
embedding_function,
connection_string=connection_string
)
# Perform a similarity search
query = "Your query here"
results = vector_store.similarity_search(query)In diesem Beispiel wird davon ausgegangen, dass du die OpenAI-Einbettungen eingerichtet hast und eine Liste von Dokumenten hast, die du einbetten möchtest.
Lass uns jetzt eine einfache semantische Suchmaschine mit pgvector und OpenAI Embeddings bauen!
Diese Anwendung ermöglicht es den Nutzern, eine Sammlung von Textdokumenten mit natürlichsprachlichen Abfragen zu durchsuchen.
import openai
import psycopg2
import numpy as np
# Set up OpenAI API (replace with your actual API key)
openai.api_key = "your_openai_api_key"
# Connect to the database
conn = psycopg2.connect("dbname=your_database user=your_username")
cur = conn.cursor()
# Create a table for our documents
cur.execute("""
CREATE TABLE IF NOT EXISTS documents (
id SERIAL PRIMARY KEY,
content TEXT,
embedding vector(1536)
)
""")
# Function to get embeddings from OpenAI
def get_embedding(text):
response = openai.embeddings.create(input=text, model="text-embedding-ada-002")
return response['data'][0]['embedding']
# Function to add a document
def add_document(content):
embedding = get_embedding(content)
cur.execute("INSERT INTO documents (content, embedding) VALUES (%s, %s)", (content, embedding))
conn.commit()
# Function to search for similar documents
def search_documents(query, limit=5):
query_embedding = get_embedding(query)
cur.execute("""
SELECT content, embedding <-> %s AS distance
FROM documents
ORDER BY distance
LIMIT %s
""", (query_embedding, limit))
return cur.fetchall()
# Add some sample documents
sample_docs = [
"The quick brown fox jumps over the lazy dog.",
"Python is a high-level programming language.",
"Vector databases are essential for modern AI applications.",
"PostgreSQL is a powerful open-source relational database.",
]
for doc in sample_docs:
add_document(doc)
# Perform a search
search_query = "Tell me about programming languages"
results = search_documents(search_query)
print(f"Search results for: '{search_query}'")
for i, (content, distance) in enumerate(results, 1):
print(f"{i}. {content} (Distance: {distance:.4f})")
# Clean up
cur.close()
conn.close()Diese einfache Anwendung zeigt, wie du mit pgvector eine semantische Suchmaschine erstellen kannst.
Es bettet Dokumente mit dem Texteinbettungsmodell von OpenAI ein und speichert sie in einer PostgreSQL-Datenbank mit pgvector. Die Suchfunktion findet die ähnlichsten Dokumente zu einer bestimmten Abfrage mithilfe der Kosinusähnlichkeit.
Vergleichen wir pgvector mit anderen beliebten Vektordatenbanken. Dieser Vergleich hilft dir, die Unterschiede in Bezug auf Funktionen, Einsatzmöglichkeiten, Skalierbarkeit, Integration und Kosten zwischen pgvector und anderen auf dem Markt verfügbaren Lösungen zu verstehen.
Pinecone ist eine vollständig verwaltete Vektordatenbank, die für hohe Skalierbarkeit und Benutzerfreundlichkeit entwickelt wurde.
|
Feature |
pgvector |
Kiefernzapfen |
|
Datenbank-Typ |
Erweiterung für PostgreSQL |
Vollständig verwaltete Vektordatenbank |
|
Einsatz |
Selbstgehostet |
Cloud-basiert |
|
Skalierbarkeit |
Begrenzt durch PostgreSQL |
Hochgradig skalierbar |
|
Integration |
Arbeitet mit bestehendem PostgreSQL-Stack |
Erfordert separate Integration |
|
Kosten |
Frei, Open-Source |
Preisgestaltung nach dem Umlageverfahren |
pgvector ist eine ausgezeichnete Wahl für alle, die ihre bestehende PostgreSQL-Infrastruktur ohne zusätzliche Kosten nutzen wollen. Gleichzeitig bietet Pinecone eine hochgradig skalierbare, verwaltete Lösung mit nutzungsabhängigen Preisen.
Milvus ist eine spezielle Vektordatenbank, die erweiterte Funktionen und hohe Skalierbarkeit bietet.
|
Feature |
pgvector |
Milvus |
|
Datenbank-Typ |
Erweiterung für PostgreSQL |
Dedizierte Vektordatenbank |
|
Einsatz |
Selbstgehostet |
Selbstgehostet oder Cloud |
|
Skalierbarkeit |
Begrenzt durch PostgreSQL |
Hochgradig skalierbar |
|
Integration |
Arbeitet mit bestehendem PostgreSQL-Stack |
Erfordert separate Integration |
|
Merkmalsset |
Grundlegende Vektoroperationen |
Erweiterte Funktionen wie dynamische Schemata |
Während pgvector grundlegende Vektoroperationen in der vertrauten PostgreSQL-Umgebung bereitstellt, bietet Milvus eine funktionsreichere und skalierbarere Lösung speziell für die Verarbeitung großer Vektordaten.
Weaviate ist eine Vektordatenbank mit integriertem Objektspeicher, die flexible Datenmodellierung und Skalierbarkeit bietet.
|
Feature |
pgvector |
Weaviate |
|
Datenbank-Typ |
Erweiterung für PostgreSQL |
Vektordatenbank mit Objektspeicherung |
|
Einsatz |
Selbstgehostet |
Selbstgehostet oder Cloud |
|
Skalierbarkeit |
Begrenzt durch PostgreSQL |
Entwickelt für Skalierbarkeit |
|
Integration |
Arbeitet mit bestehendem PostgreSQL-Stack |
Erfordert separate Integration |
|
Datenmodell |
Nur Vektoren |
Objekte mit Vektoren und Eigenschaften |
Die Einfachheit von pgvector und seine Integration in PostgreSQL machen es zu einer guten Lösung für Benutzer, die grundlegende Vektor-Funktionen benötigen. Im Gegensatz dazu eignen sich das ausgefeiltere Datenmodell und die Skalierbarkeit von Weaviate für komplexe Anwendungen, die neben Vektoren auch Objektspeicher benötigen.
pgvector bringt leistungsstarke Funktionen für die Suche nach Vektorähnlichkeiten in PostgreSQL und ist damit eine ausgezeichnete Wahl für Entwickler, die ihre bestehenden PostgreSQL-basierten Anwendungen um KI-Funktionen erweitern möchten.
In diesem Tutorial haben wir uns mit der Installation, der grundlegenden Nutzung, den Indexierungsfunktionen und der Integration mit Python und LangChain beschäftigt.
Auch wenn pgvector nicht die gleiche Skalierbarkeit und die gleichen speziellen Funktionen wie spezielle Vektordatenbanken wie Pinecone oder Milvus bietet, macht es seine nahtlose Integration in PostgreSQL zu einer attraktiven Option für viele Anwendungsfälle.
Es eignet sich besonders gut für Projekte, die bereits PostgreSQL verwenden und Vektorsuchfunktionen hinzufügen möchten, ohne ein neues Datenbanksystem einzuführen.
Wir ermutigen dich, pgvector in deinen eigenen Projekten auszuprobieren. Egal, ob du ein Empfehlungssystem, eine semantische Suchmaschine oder eine andere Anwendung entwickelst, die eine Ähnlichkeitssuche erfordert, pgvector kann ein wertvolles Werkzeug in deinem Data Science Toolkit sein.
Wenn du dich weiterbilden möchtest, solltest du diese kostenlosen DataCamp-Kurse ausprobieren:
Diese Kurse werden dir helfen, dein Verständnis von Datenbanken und modernen LLM-Anwendungen zu vertiefen.
Lerne mehr über maschinelles Lernen und KI mit diesen Kursen!
Kurs
Kurs
Kurs
Tutorial
DataCamp Team
Tutorial
Sejal Jaiswal
Tutorial
Javier Canales Luna
Tutorial
Allan Ouko
Tutorial
DataCamp Team
Tutorial
Laiba Siddiqui


