
Cursus
Generatieve AI-concepten
2 Hr
110.7K
Vector search is de laatste jaren enorm populair geworden, dankzij alle vooruitgang in het Generative AI- en Large Language Model-ecosysteem.
Vector search is een methode voor informatieopvraging waarbij documenten en zoekopdrachten worden weergegeven als vectors in plaats van platte tekst. Deze numerieke representatie wordt verkregen met een groot, getraind neuraal netwerk dat ongestructureerde data, zoals tekst, afbeeldingen en video’s, kan omzetten in vectors.
Traditionele relationele databases zijn niet geoptimaliseerd om grote hoeveelheden vectordata te verwerken. Daarom zijn er de afgelopen jaren veel open-source en propriëtaire, exclusieve vectordatabases verschenen. Het is echter niet voor alle bedrijven ideaal om een aparte database uitsluitend voor vectors te hebben, los van de hoofddatabase.
Daar komt pgvector om de hoek kijken: een krachtige extensie voor PostgreSQL die mogelijkheden voor gelijkeniszoekopdrachten met vectors toevoegt aan een van de populairste relationele databases.
In deze tutorial verkennen we de features van pgvector en laten we zien hoe het je in je werk kan helpen.
pgvector is een open-source extensie voor PostgreSQL die ondersteuning toevoegt voor vectorbewerkingen en gelijkeniszoekopdrachten. Je kunt vectordata direct in je PostgreSQL-database opslaan, indexeren en opvragen.
Deze integratie brengt de kracht van vectorbewerkingen naar je bestaande PostgreSQL-infrastructuur, waardoor het een uitstekende keuze is voor toepassingen met embeddings, aanbevelingssystemen en gelijkeniszoekopdrachten.
Features van pgvector zijn onder andere:
Vectordatabases zijn gespecialiseerde databases die zijn ontworpen om multidimensionale vectordata op te slaan en te bevragen. Deze capaciteit is relevant in moderne machinelearningtoepassingen, waaronder aanbevelingssystemen, beeldherkenning en natural language processing.
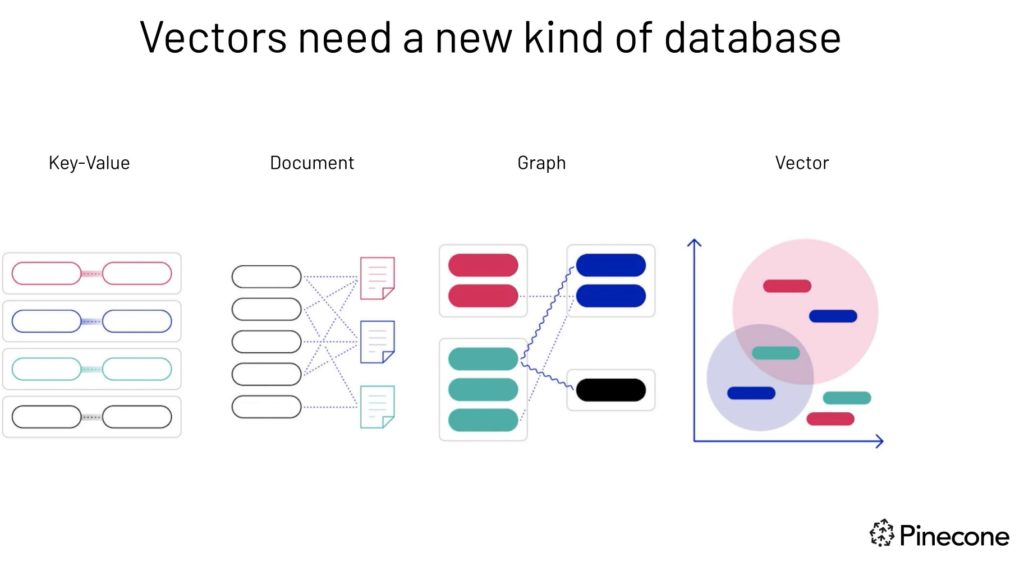
Vectors hebben een nieuw type database nodig—afbeelding bron.
Traditionele relationele databases hebben moeite met hoog-dimensionale data en het efficiënt uitvoeren van gelijkeniszoekopdrachten. Vectordatabases daarentegen zijn specifiek geoptimaliseerd voor deze taken, waardoor snelle en nauwkeurige gegevensopvraging op basis van vectornabijheid of -gelijkenis mogelijk is.
Deze aanpak maakt zoekopdrachten mogelijk op basis van semantische of contextuele relevantie, wat betekenisvollere resultaten oplevert dan de exacte-matchzoekopdrachten van conventionele databases.
Een vectordatabase kan bijvoorbeeld:
Hoe wordt ongestructureerde data zoals tekst of afbeeldingen dan omgezet in getallen? Het antwoord is embeddings.
Embedding is een proces waarbij ongestructureerde data wordt omgezet in numerieke vectors met vaste grootte, die de onderliggende semantiek en relaties in de data vastleggen. Dit gebeurt met grote neurale netwerken die leren om de data weer te geven in een continue vectorruimte, waarin vergelijkbare items dichter bij elkaar liggen.
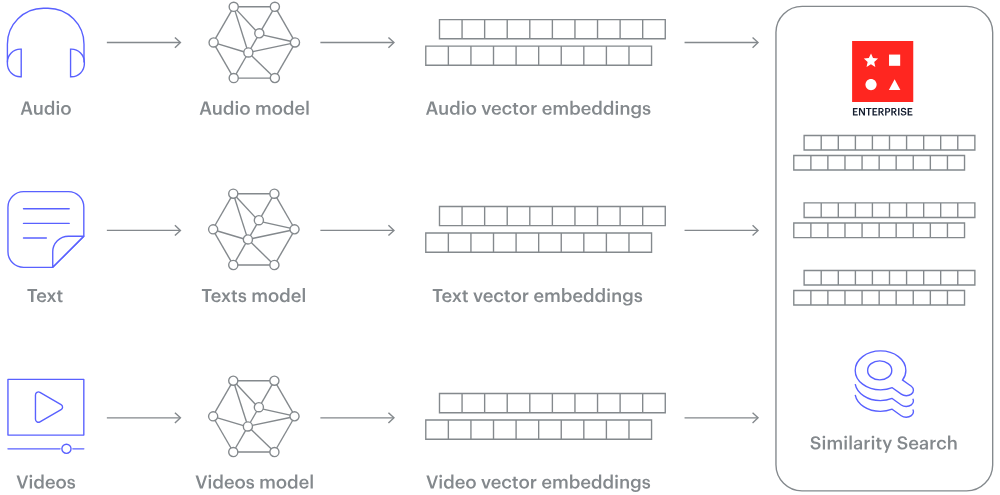
Hoe werkt een vectordatabase? Afbeelding bron.
In dit gedeelte lopen we door het opzetten van pgvector, het gebruik van de basisfeatures en bouwen we een eenvoudige applicatie door het te integreren met OpenAI.
We behandelen installatie, basisoperaties, indexering en integratie met Python en LangChain.
Om deze tutorial te volgen, heb je basiskennis van SQL en PostgreSQL nodig en ben je vertrouwd met programmeren in Python.
Zorg voordat we beginnen dat je het volgende hebt:
1. Zorg eerst dat je de PostgreSQL-ontwikkelbestanden hebt geïnstalleerd. Op Ubuntu of Debian kun je ze installeren met:
sudo apt-get install postgresql-server-dev-allAls je Windows gebruikt, kun je de PostgreSQL-installer downloaden van de officiële website.
2. Clone de pgvector GitHub-repository:
git clone https://github.com/pgvector/pgvector.git3. Bouw en installeer de pgvector-extensie:
cd pgvector
make
sudo make installAls je Windows gebruikt, zorg dan dat C++-ondersteuning in Visual Studio Code is geïnstalleerd. De officiële installatiedocumentatie biedt een stappenplan.
4. Verbind met je PostgreSQL-database:
Je hebt meerdere opties om verbinding te maken en met de PostgreSQL-database te werken: pgAdmin is een van de meest gebruikte interfaces. Je kunt ook pSQL (de PostgreSQL-commandline-interface) gebruiken of zelfs een VS Code-extensie voor PostgreSQL.
5. Maak na het verbinden met je PostgreSQL-database de extensie aan:
CREATE EXTENSION vector;
pgAdmin-interface
Nu we pgvector hebben geïnstalleerd, gaan we het basisgebruik verkennen.
1. Om onze eerste vectordatabase in PostgreSQL met de pgvector-extensie op te zetten, maken we een tabel om onze vectordata op te slaan:
CREATE TABLE items (
id SERIAL PRIMARY KEY,
embedding vector(3)
);Dit maakt een tabel items met een id-kolom en een embedding-kolom van het type vector(3), die 3-dimensionale vectors opslaat.
2. Laten we nu wat data in onze tabel invoegen:
INSERT INTO items (embedding) VALUES ('[1,2,3]'), ('[4,5,6]'), ('[1,1,1]');3. Nu kunnen we vectorbewerkingen uitvoeren. Bijvoorbeeld, om de dichtstbijzijnde buur te vinden van de vector [2,3,4]:
SELECT * FROM items ORDER BY embedding <-> '[2,3,4]' LIMIT 1;Deze query gebruikt de <->-operator, die de Euclidische afstand tussen vectors berekent.
4. We kunnen ook andere afstandsmaatstaven gebruiken, zoals cosine-afstand:
SELECT * FROM items ORDER BY embedding <=> '[2,3,4]' LIMIT 1;De <=>-operator berekent de cosine-afstand tussen vectors.
Indexeren in vectordatabases, waaronder pgvector, is nodig om de zoekprestaties te verbeteren, vooral naarmate je dataset groeit.
Het belang van indexeren kan niet worden overschat, want het biedt verschillende voordelen:
Er zijn twee types indexen beschikbaar voor pgvector: ivfflat en hnsw. Ze dienen elk een ander doel:
Wanneer gebruik je welke index:
1. Laten we een ivfflat-index maken:
CREATE INDEX ON items USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);Dit maakt een index met het IVFFlat-algoritme, geschikt voor exacte nearest neighbor-zoekopdrachten.
2. Voor benaderende nearest neighbor-zoekopdrachten kunnen we de hnsw-index gebruiken:
CREATE INDEX ON items USING hnsw (embedding vector_l2_ops) WITH (m = 16, ef_construction = 64);Na het aanmaken van een index zullen onze queries deze automatisch gebruiken wanneer dat passend is.
Pgvector ondersteunt integratie met een aantal frameworks, wat de interactie met onze vectordatabase makkelijker maakt. Laten we er twee handige bespreken: Python en LangChain.
pgvector kan eenvoudig met Python worden geïntegreerd met de psycopg2-bibliotheek. Laten we een Python-omgeving opzetten en enkele basisbewerkingen uitvoeren.
1. Installeer eerst de vereiste bibliotheken:
!pip install psycopg2-binary numpy2. Maak nu een Python-script om met onze vectordatabase te communiceren:
import psycopg2
import numpy as np
# Connect to the database
conn = psycopg2.connect("dbname=your_database user=your_username")
cur = conn.cursor()
# Insert a vector
embedding = np.array([1.5, 2.5, 3.5])
cur.execute("INSERT INTO items (embedding) VALUES (%s)", (embedding.tolist(),))
# Perform a similarity search
query_vector = np.array([2, 3, 4])
cur.execute("SELECT * FROM items ORDER BY embedding <-> %s LIMIT 1", (query_vector.tolist(),))
result = cur.fetchone()
print(f"Nearest neighbor: {result}")
conn.commit()
cur.close()
conn.close()Dit script laat zien hoe je een vector invoegt en een gelijkeniszoekopdracht uitvoert met Python.
pgvector kan ook worden geïntegreerd met LangChain, een populair framework voor het ontwikkelen van applicaties met large language models.
Hier is een eenvoudig voorbeeld van het gebruik van pgvector als vector store in LangChain:
from langchain_postgres.vectorstores import PGVector
from langchain.embeddings.openai import OpenAIEmbeddings
# Set up the connection string and embedding function
connection_string = "postgresql://user:pass@localhost:5432/db_name"
embedding_function = OpenAIEmbeddings()
# Create a PGVector instance
vector_store = PGVector.from_documents(
documents,
embedding_function,
connection_string=connection_string
)
# Perform a similarity search
query = "Your query here"
results = vector_store.similarity_search(query)Dit voorbeeld gaat ervan uit dat je OpenAI-embeddings hebt ingesteld en een lijst met documenten hebt om te embedden.
Laten we nu een eenvoudige semantische zoekmachine bouwen met pgvector en OpenAI-embeddings!
Met deze applicatie kunnen gebruikers door een collectie tekstdocumenten zoeken met natuurlijke taalqueries.
import openai
import psycopg2
import numpy as np
# Set up OpenAI API (replace with your actual API key)
openai.api_key = "your_openai_api_key"
# Connect to the database
conn = psycopg2.connect("dbname=your_database user=your_username")
cur = conn.cursor()
# Create a table for our documents
cur.execute("""
CREATE TABLE IF NOT EXISTS documents (
id SERIAL PRIMARY KEY,
content TEXT,
embedding vector(1536)
)
""")
# Function to get embeddings from OpenAI
def get_embedding(text):
response = openai.embeddings.create(input=text, model="text-embedding-ada-002")
return response['data'][0]['embedding']
# Function to add a document
def add_document(content):
embedding = get_embedding(content)
cur.execute("INSERT INTO documents (content, embedding) VALUES (%s, %s)", (content, embedding))
conn.commit()
# Function to search for similar documents
def search_documents(query, limit=5):
query_embedding = get_embedding(query)
cur.execute("""
SELECT content, embedding <-> %s AS distance
FROM documents
ORDER BY distance
LIMIT %s
""", (query_embedding, limit))
return cur.fetchall()
# Add some sample documents
sample_docs = [
"The quick brown fox jumps over the lazy dog.",
"Python is a high-level programming language.",
"Vector databases are essential for modern AI applications.",
"PostgreSQL is a powerful open-source relational database.",
]
for doc in sample_docs:
add_document(doc)
# Perform a search
search_query = "Tell me about programming languages"
results = search_documents(search_query)
print(f"Search results for: '{search_query}'")
for i, (content, distance) in enumerate(results, 1):
print(f"{i}. {content} (Distance: {distance:.4f})")
# Clean up
cur.close()
conn.close()Deze eenvoudige applicatie laat zien hoe je pgvector gebruikt om een semantische zoekmachine te maken.
Hij embedt documenten met het text embedding-model van OpenAI en slaat ze op in een PostgreSQL-database met pgvector. De zoekfunctie vindt de meest vergelijkbare documenten bij een gegeven query met behulp van cosine similarity.
Je wilt pgvector optimaliseren naarmate je applicatie schaalt. Hier zijn enkele suggesties op hoofdlijnen:
Implementeer connection pooling om overhead te verminderen. Gebruik PgBouncer of PgPool-II. Deze tools zijn handig omdat ze herbruikbare databaseverbindingen in stand houden.
Pas indexparameters tijdens runtime aan. Je kunt snelheid en nauwkeurigheid balanceren op basis van je behoeften.
Voor IVFFlat-indexen stel je de parameter probes in. Gebruik 1–5 voor snelheid. Gebruik 10–20 voor gebalanceerde performance.
Voor HNSW-indexen tune je ef_search. Gebruik 20–40 voor snelheid. Gebruik 100–200 voor nauwkeurigheid.
Je kunt ook EXPLAIN ANALYZE gebruiken om indexgebruik te verifiëren. Voeg altijd LIMIT-clausules toe aan queries.
Implementeer caching met Redis of Memcached. Cache vectors waar vaak naar wordt gevraagd. Gebruik de queryvector als cachekey. Stel geschikte vervaltijden in.
Stel PostgreSQL read-replica’s in voor leesintensieve workloads. Leid writes naar de primaire database. Leid vectorzoekopdrachten naar replica’s. Gebruik load balancers voor automatische verdeling.
Stel belangrijke parameters af voor vectorworkloads:
shared_buffers: Stel in op 25% van het totale RAM
work_mem: Stel in op 64–128 MB voor vectorbewerkingen
random_page_cost: Lager instellen voor SSD-opslag
effective_cache_size: Stel in op 50–75% van het totale RAM
Bouw indexen periodiek opnieuw op tijdens daluren. Voer VACUUM en ANALYZE uit. Schakel autovacuum in voor geautomatiseerd onderhoud.
Volg querylatency en queries per seconde. Monitor de benutting van de connection pool. Controleer cache-hitratio’s. Houd resourcegebruik in de gaten. Stel alerts in voor performanceproblemen. Schakel pg_stat_statements in om trage queries te identificeren.
Laten we pgvector nu vergelijken met andere populaire vectordatabases. Deze vergelijking helpt je de verschillen te begrijpen in features, implementatieopties, schaalbaarheid, integratie en kosten tussen pgvector en andere oplossingen op de markt.
Pinecone is een volledig beheerde vectordatabase die is ontworpen voor hoge schaalbaarheid en gebruiksgemak.
|
Feature |
pgvector |
Pinecone |
|
Databasetype |
Extensie voor PostgreSQL |
Volledig beheerde vectordatabase |
|
Implementatie |
Self-hosted |
Cloudgebaseerd |
|
Schaalbaarheid |
Beperkt door PostgreSQL |
Zeer schaalbaar |
|
Integratie |
Werkt met bestaande PostgreSQL-stack |
Vereist aparte integratie |
|
Kosten |
Gratis, open-source |
Pay-as-you-go-prijzen |
pgvector is een uitstekende keuze voor wie de bestaande PostgreSQL-infrastructuur wil benutten zonder extra kosten. Tegelijkertijd biedt Pinecone een zeer schaalbare, beheerde oplossing met pay-as-you-go-prijzen voor gebruiksgemak.
Milvus is een dedicated vectordatabase met geavanceerde features en hoge schaalbaarheid.
|
Feature |
pgvector |
Milvus |
|
Databasetype |
Extensie voor PostgreSQL |
Dedicated vectordatabase |
|
Implementatie |
Self-hosted |
Self-hosted of cloud |
|
Schaalbaarheid |
Beperkt door PostgreSQL |
Zeer schaalbaar |
|
Integratie |
Werkt met bestaande PostgreSQL-stack |
Vereist aparte integratie |
|
Featureset |
Basale vectorbewerkingen |
Geavanceerde features zoals dynamisch schema |
Waar pgvector basale vectorbewerkingen biedt binnen de vertrouwde PostgreSQL-omgeving, levert Milvus een uitgebreidere en schaalbaardere oplossing die specifiek is bedoeld voor grootschalige vectordata.
Weaviate is een vectordatabase met geïntegreerde objectopslag, met flexibel datamodel en schaalbaarheid.
|
Feature |
pgvector |
Weaviate |
|
Databasetype |
Extensie voor PostgreSQL |
Vectordatabase met objectopslag |
|
Implementatie |
Self-hosted |
Self-hosted of cloud |
|
Schaalbaarheid |
Beperkt door PostgreSQL |
Ontworpen voor schaalbaarheid |
|
Integratie |
Werkt met bestaande PostgreSQL-stack |
Vereist aparte integratie |
|
Datamodel |
Alleen vectors |
Objecten met vectors en eigenschappen |
De eenvoud van pgvector en de integratie met PostgreSQL maken het geschikt voor bestaande gebruikers die basisfunctionaliteit voor vectors nodig hebben. Weaviate’s geavanceerdere datamodel en schaalbaarheid zijn daarentegen geschikt voor complexe applicaties die naast vectors ook objectopslag vereisen.
pgvector brengt krachtige mogelijkheden voor gelijkeniszoekopdrachten met vectors naar PostgreSQL, waardoor het een uitstekende keuze is voor developers die AI-features willen toevoegen aan hun bestaande PostgreSQL-gebaseerde applicaties.
In deze tutorial hebben we installatie, basisgebruik, indexeringsmogelijkheden en integratie met Python en LangChain verkend.
Hoewel pgvector niet dezelfde schaalbaarheid en gespecialiseerde features biedt als dedicated vectordatabases zoals Pinecone of Milvus, maakt de naadloze integratie met PostgreSQL het voor veel use cases een aantrekkelijke optie.
Het is vooral geschikt voor projecten die al PostgreSQL gebruiken en vector search-functionaliteit willen toevoegen zonder een nieuw databasesysteem te introduceren.
We moedigen je aan om pgvector in je eigen projecten te proberen. Of je nu een aanbevelingssysteem bouwt, een semantische zoekmachine of een andere applicatie die gelijkeniszoekopdrachten vereist, pgvector kan een waardevolle tool zijn in je data science-toolkit.
Voor verdere verdieping, bekijk onze cursussen:
Leer meer over machine learning en AI met deze cursussen!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
