
Cours
Concepts d'IA générative
2 h
105.1K
La recherche vectorielle est devenue de plus en plus populaire ces dernières années, grâce à tous les progrès réalisés dans l'écosystème de l'IA générative et des grands modèles de langage.
La recherche vectorielle est une méthode de recherche d'informations dans laquelle les documents et les requêtes sont représentés sous forme de vecteurs au lieu de texte brut. Cette représentation numérique est obtenue en utilisant un grand réseau neuronal entraîné qui peut convertir des données non structurées, telles que du texte, des images et des vidéos, en vecteurs.
Les bases de données relationnelles traditionnelles ne sont pas optimisées pour traiter de grands volumes de données vectorielles. C'est pourquoi de nombreuses bases de données vectorielles exclusives, libres ou propriétaires, ont vu le jour ces dernières années. Cependant, il n'est peut-être pas idéal pour toutes les entreprises de disposer d'une base de données dédiée aux vecteurs, séparée de la base de données principale.
Découvrez pgvector, une puissante extension pour PostgreSQL qui apporte des fonctionnalités de recherche de similarités vectorielles à l'une des bases de données relationnelles les plus populaires.
Dans ce tutoriel, nous allons explorer les fonctionnalités de pgvector et montrer comment il peut vous aider dans votre travail.
pgvector est une extension open-source pour PostgreSQL qui ajoute le support des opérations vectorielles et des recherches de similarité. Il vous permet de stocker, d'indexer et d'interroger des données vectorielles directement dans votre base de données PostgreSQL.
Cette intégration apporte la puissance des opérations vectorielles à votre infrastructure PostgreSQL existante, ce qui en fait un excellent choix pour les applications impliquant des encastrements, des systèmes de recommandation et des recherches de similarité.
Les caractéristiques de pgvector sont les suivantes
Les bases de données vectorielles sont des bases de données spécialisées conçues pour stocker et interroger des données vectorielles multidimensionnelles. Cette capacité est utile dans les applications modernes d'apprentissage automatique, notamment les systèmes de recommandation, la recherche d'images et les cas d'utilisation du traitement du langage naturel.
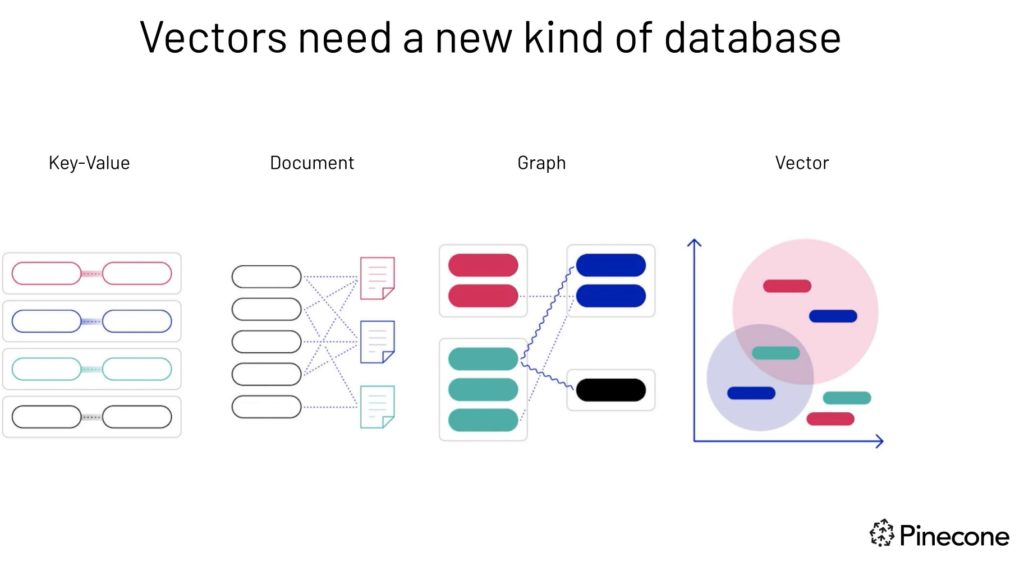
Les vecteurs ont besoin d'un nouveau type de base de données - une source d'images.
Les bases de données relationnelles traditionnelles ont du mal à gérer les données de haute dimension et à effectuer efficacement des recherches de similarité. Les bases de données vectorielles, en revanche, sont spécifiquement optimisées pour ces tâches, permettant une extraction rapide et précise des données sur la base de la proximité ou de la ressemblance des vecteurs.
Cette approche permet d'effectuer des recherches fondées sur la pertinence sémantique ou contextuelle, ce qui donne des résultats plus significatifs que les recherches par correspondance exacte des bases de données conventionnelles.
Par exemple, une base de données vectorielle peut :
Comment convertir en chiffres des données non structurées telles que du texte ou des images ? La réponse est l'intégration.
L'incorporation est un processus qui transforme des données non structurées en vecteurs numériques de taille fixe, capturant la sémantique et les relations inhérentes aux données. Pour ce faire, de grands réseaux neuronaux apprennent à représenter les données dans un espace vectoriel continu, où les éléments similaires sont placés plus près les uns des autres.
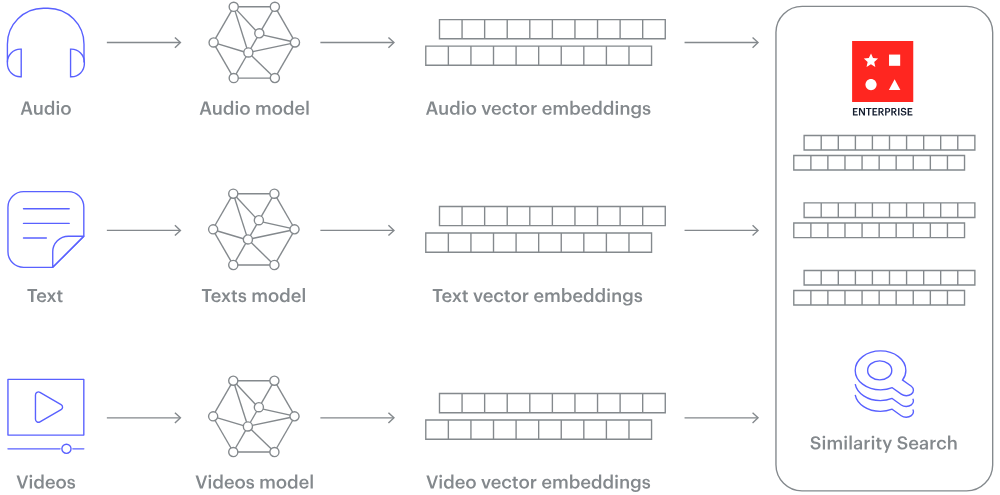
Comment fonctionne une base de données vectorielle ? Source de l'image.
Dans ce tutoriel, nous allons configurer pgvector, utiliser ses fonctionnalités de base et construire une application simple en l'intégrant à OpenAI.
Nous couvrirons l'installation, les opérations de base, l'indexation et l'intégration avec Python et LangChain.
Pour suivre ce tutoriel, vous devez avoir des connaissances de base en SQL et PostgreSQL et être familier avec la programmation Python.
Avant de commencer, assurez-vous que vous disposez des éléments suivants :
1. Tout d'abord, assurez-vous que les fichiers de développement PostgreSQL sont installés. Sur Ubuntu ou Debian, vous pouvez les installer avec :
sudo apt-get install postgresql-server-dev-allSi vous utilisez Windows, vous pouvez télécharger le programme d'installation de PostgreSQL depuis le site officiel.
2. Clonez le dépôt GitHub de pgvector :
git clone https://github.com/pgvector/pgvector.git3. Créez et installez l'extension pgvector:
cd pgvector
make
sudo make installSi vous utilisez Windows, assurez-vous que le support C++ de Visual Studio Code est installé. La documentation d'installation officielle fournit une procédure étape par étape.
4. Connectez-vous à votre base de données PostgreSQL :
Vous disposez de plusieurs options pour vous connecter et interagir avec la base de données PostgreSQL : pgAdmin est l'une des interfaces les plus utilisées. Vous pouvez également utiliser pSQL (PostgreSQL command line interface) ou même une extension VS Code pour PostgreSQL.
5. Après vous être connecté à votre base de données PostgreSQL, créez l'extension :
CREATE EXTENSION vector;
pgAdmin Interface
Maintenant que pgvector est installé, explorons son utilisation de base.
1. Pour mettre en place notre première base de données vectorielle dans PostgreSQL en utilisant l'extension pgvector, créons un tableau pour stocker nos données vectorielles :
CREATE TABLE items (
id SERIAL PRIMARY KEY,
embedding vector(3)
);Cela crée un tableau nommé items avec une colonne id et une colonne embedding de type vector(3), qui stockera des vecteurs tridimensionnels.
2. Insérons maintenant quelques données dans notre tableau :
INSERT INTO items (embedding) VALUES ('[1,2,3]'), ('[4,5,6]'), ('[1,1,1]');3. Nous pouvons maintenant effectuer des opérations vectorielles. Par exemple, pour trouver le plus proche voisin du vecteur [2,3,4]:
SELECT * FROM items ORDER BY embedding <-> '[2,3,4]' LIMIT 1;Cette requête utilise l'opérateur <->, qui calcule la distance euclidienne entre les vecteurs.
4. Nous pouvons également utiliser d'autres mesures de distance, comme la distance cosinusoïdale :
SELECT * FROM items ORDER BY embedding <=> '[2,3,4]' LIMIT 1;L'opérateur <=> calcule la distance en cosinus entre les vecteurs.
L'indexation dans les bases de données vectorielles, y compris pgvector, est nécessaire pour améliorer les performances de recherche, en particulier lorsque votre ensemble de données s'accroît.
On ne saurait trop insister sur l'importance de l'indexation, qui présente plusieurs avantages :
Deux types d'index sont disponibles pour pgvector : ivfflat et hnsw. Les deux servent des objectifs différents :
Quand utiliser chaque indice :
1. Créons un index ivfflat:
CREATE INDEX ON items USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);Cela permet de créer un index à l'aide de l'algorithme IVFFlat, qui convient aux recherches exactes sur les plus proches voisins.
2. Pour les recherches approximatives du plus proche voisin, nous pouvons utiliser l'index hnsw:
CREATE INDEX ON items USING hnsw (embedding vector_l2_ops) WITH (m = 16, ef_construction = 64);Après avoir créé un index, nos requêtes l'utiliseront automatiquement le cas échéant.
Pgvector supporte l'intégration de quelques frameworks, ce qui facilite l'interaction avec notre base de données vectorielles. Passons en revue deux d'entre elles : Python et LangChain.
pgvector peut être facilement intégré à Python à l'aide de la bibliothèque psycopg2. Mettons en place un environnement Python et effectuons quelques opérations de base.
1. Installez d'abord les bibliothèques nécessaires :
!pip install psycopg2-binary numpy2. Maintenant, créons un script Python pour interagir avec notre base de données vectorielles :
import psycopg2
import numpy as np
# Connect to the database
conn = psycopg2.connect("dbname=your_database user=your_username")
cur = conn.cursor()
# Insert a vector
embedding = np.array([1.5, 2.5, 3.5])
cur.execute("INSERT INTO items (embedding) VALUES (%s)", (embedding.tolist(),))
# Perform a similarity search
query_vector = np.array([2, 3, 4])
cur.execute("SELECT * FROM items ORDER BY embedding <-> %s LIMIT 1", (query_vector.tolist(),))
result = cur.fetchone()
print(f"Nearest neighbor: {result}")
conn.commit()
cur.close()
conn.close()Ce script montre comment insérer un vecteur et effectuer une recherche de similarité à l'aide de Python.
pgvector peut également être intégré à LangChain, un cadre populaire pour le développement d'applications avec de grands modèles de langage.
Voici un exemple simple de l'utilisation de pgvector comme magasin de vecteurs dans LangChain :
from langchain_postgres.vectorstores import PGVector
from langchain.embeddings.openai import OpenAIEmbeddings
# Set up the connection string and embedding function
connection_string = "postgresql://user:pass@localhost:5432/db_name"
embedding_function = OpenAIEmbeddings()
# Create a PGVector instance
vector_store = PGVector.from_documents(
documents,
embedding_function,
connection_string=connection_string
)
# Perform a similarity search
query = "Your query here"
results = vector_store.similarity_search(query)Cet exemple suppose que vous avez mis en place les embeddings OpenAI et que vous disposez d'une liste de documents à intégrer.
Construisons maintenant un moteur de recherche sémantique simple en utilisant pgvector et les embeddings OpenAI !
Cette application permettra aux utilisateurs d'effectuer des recherches dans une collection de documents textuels à l'aide de requêtes en langage naturel.
import openai
import psycopg2
import numpy as np
# Set up OpenAI API (replace with your actual API key)
openai.api_key = "your_openai_api_key"
# Connect to the database
conn = psycopg2.connect("dbname=your_database user=your_username")
cur = conn.cursor()
# Create a table for our documents
cur.execute("""
CREATE TABLE IF NOT EXISTS documents (
id SERIAL PRIMARY KEY,
content TEXT,
embedding vector(1536)
)
""")
# Function to get embeddings from OpenAI
def get_embedding(text):
response = openai.embeddings.create(input=text, model="text-embedding-ada-002")
return response['data'][0]['embedding']
# Function to add a document
def add_document(content):
embedding = get_embedding(content)
cur.execute("INSERT INTO documents (content, embedding) VALUES (%s, %s)", (content, embedding))
conn.commit()
# Function to search for similar documents
def search_documents(query, limit=5):
query_embedding = get_embedding(query)
cur.execute("""
SELECT content, embedding <-> %s AS distance
FROM documents
ORDER BY distance
LIMIT %s
""", (query_embedding, limit))
return cur.fetchall()
# Add some sample documents
sample_docs = [
"The quick brown fox jumps over the lazy dog.",
"Python is a high-level programming language.",
"Vector databases are essential for modern AI applications.",
"PostgreSQL is a powerful open-source relational database.",
]
for doc in sample_docs:
add_document(doc)
# Perform a search
search_query = "Tell me about programming languages"
results = search_documents(search_query)
print(f"Search results for: '{search_query}'")
for i, (content, distance) in enumerate(results, 1):
print(f"{i}. {content} (Distance: {distance:.4f})")
# Clean up
cur.close()
conn.close()Cette application simple montre comment utiliser pgvector pour créer un moteur de recherche sémantique.
Il incorpore des documents en utilisant le modèle d' incorporation de texte d'OpenAI et les stocke dans une base de données PostgreSQL avec pgvector. La fonction de recherche permet de trouver les documents les plus similaires à une requête donnée en utilisant la similarité cosinusoïdale.
Comparons pgvector avec d'autres bases de données vectorielles populaires. Cette comparaison vous aidera à comprendre les différences de fonctionnalités, d'options de déploiement, d'évolutivité, d'intégration et de coût entre pgvector et d'autres solutions disponibles sur le marché.
Pinecone est une base de données vectorielle entièrement gérée, conçue pour une grande évolutivité et une grande facilité d'utilisation.
|
Fonctionnalité |
pgvector |
Pomme de pin |
|
Type de base de données |
Extension pour PostgreSQL |
Base de données vectorielles entièrement gérée |
|
Déploiement |
Auto-hébergé |
Basé sur le cloud |
|
Évolutivité |
Limité par PostgreSQL |
Hautement modulable |
|
Integration |
Fonctionne avec la pile PostgreSQL existante |
Nécessite une intégration séparée |
|
Coût |
Gratuit, open-source |
Tarification à la carte |
pgvector est un excellent choix pour ceux qui veulent tirer parti de leur infrastructure PostgreSQL existante sans coûts supplémentaires. En même temps, Pinecone fournit une solution gérée et hautement évolutive avec une tarification à la carte pour une plus grande facilité d'utilisation.
Milvus est une base de données vectorielle dédiée qui offre des fonctionnalités avancées et une grande évolutivité.
|
Fonctionnalité |
pgvector |
Milvus |
|
Type de base de données |
Extension pour PostgreSQL |
Base de données vectorielle dédiée |
|
Déploiement |
Auto-hébergé |
Auto-hébergé ou cloud |
|
Évolutivité |
Limité par PostgreSQL |
Hautement modulable |
|
Integration |
Fonctionne avec la pile PostgreSQL existante |
Nécessite une intégration séparée |
|
Ensemble de caractéristiques |
Opérations vectorielles de base |
Fonctionnalités avancées telles que le schéma dynamique |
Alors que pgvector fournit des opérations vectorielles de base dans l'environnement familier de PostgreSQL, Milvus offre une solution plus riche en fonctionnalités et plus évolutive, spécifiquement pour traiter des données vectorielles à grande échelle.
Weaviate est une base de données vectorielle avec stockage d'objets intégré, offrant une modélisation flexible des données et une grande évolutivité.
|
Fonctionnalité |
pgvector |
Weaviate |
|
Type de base de données |
Extension pour PostgreSQL |
Base de données vectorielle avec stockage d'objets |
|
Déploiement |
Auto-hébergé |
Auto-hébergé ou cloud |
|
Évolutivité |
Limité par PostgreSQL |
Conçu pour l'évolutivité |
|
Integration |
Fonctionne avec la pile PostgreSQL existante |
Nécessite une intégration séparée |
|
Modèle de données |
Vecteurs uniquement |
Objets avec vecteurs et propriétés |
La simplicité de pgvector et son intégration avec PostgreSQL en font un outil adapté aux utilisateurs existants qui ont besoin de fonctionnalités vectorielles de base. En revanche, le modèle de données plus sophistiqué et l'évolutivité de Weaviate conviennent aux applications complexes nécessitant un stockage d'objets et de vecteurs.
pgvector apporte de puissantes capacités de recherche de similarités vectorielles à PostgreSQL, ce qui en fait un excellent choix pour les développeurs qui souhaitent ajouter des fonctionnalités d'IA à leurs applications existantes basées sur PostgreSQL.
Dans ce tutoriel, nous avons exploré son installation, son utilisation de base, ses capacités d'indexation et son intégration avec Python et LangChain.
Bien que pgvector n'offre pas la même évolutivité et les mêmes fonctionnalités spécialisées que les bases de données vectorielles dédiées comme Pinecone ou Milvus, son intégration transparente avec PostgreSQL en fait une option attrayante pour de nombreux cas d'utilisation.
Il est particulièrement adapté aux projets qui utilisent déjà PostgreSQL et qui ont besoin d'ajouter des fonctionnalités de recherche vectorielle sans introduire un nouveau système de base de données.
Nous vous encourageons à essayer pgvector dans vos propres projets. Que vous construisiez un système de recommandation, un moteur de recherche sémantique ou toute autre application nécessitant des recherches de similarité, pgvector peut être un outil précieux dans votre boîte à outils de science des données.
Pour approfondir votre apprentissage, pensez à explorer ces cours gratuits de DataCamp :
Ces cours vous aideront à approfondir votre compréhension des bases de données et des applications modernes du LLM.
Apprenez-en plus sur l'apprentissage automatique et l'IA grâce à ces cours !
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
blog
Kurtis Pykes
9 min
Tutoriel
Tutoriel
DataCamp Team
Tutoriel
Sejal Jaiswal
Tutoriel
Aditya Sharma
