Recurrent Neural Networks (RNNs) for Language Modeling with Keras
BasicSkill Level
4 Hr
16.1K learners
Recurrent neural network (RNN) adalah jenis jaringan saraf tiruan (ANN) yang digunakan pada Siri milik Apple dan penelusuran suara Google. RNN mengingat masukan sebelumnya berkat memori internal, yang bermanfaat untuk memprediksi harga saham, menghasilkan teks, transkripsi, dan penerjemahan mesin.
Pada jaringan saraf tradisional, input dan output saling independen, sedangkan output pada RNN bergantung pada elemen-elemen sebelumnya dalam sebuah urutan. Jaringan berulang juga berbagi parameter di setiap lapisan jaringan. Pada jaringan feedforward, terdapat bobot yang berbeda di setiap node. Sementara itu, RNN berbagi bobot yang sama dalam setiap lapisan jaringan dan selama gradient descent, bobot dan bias disesuaikan secara individual untuk mengurangi loss.
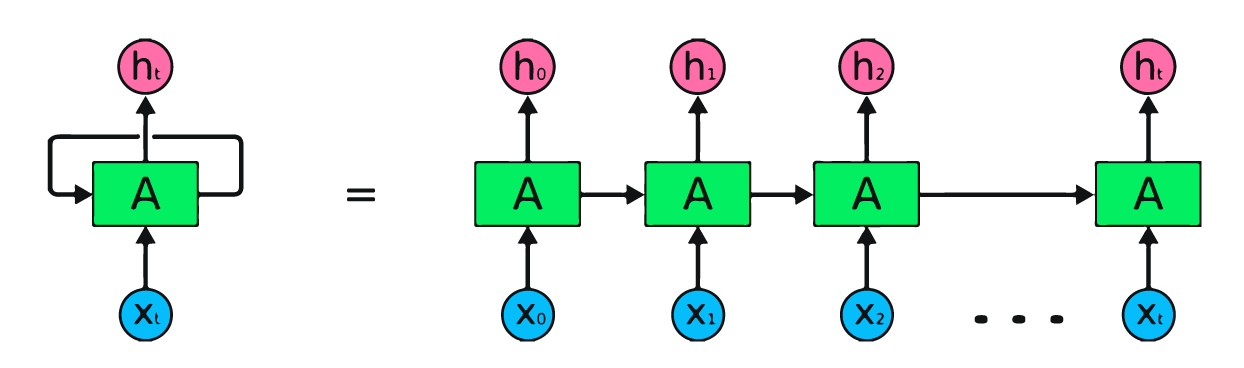
Gambar di atas adalah representasi sederhana dari jaringan saraf berulang. Jika kita melakukan peramalan harga saham menggunakan data sederhana [45,56,45,49,50,…], setiap input dari X0 hingga Xt akan memuat nilai masa lalu. Sebagai contoh, X0 akan bernilai 45, X1 akan bernilai 56, dan nilai-nilai ini digunakan untuk memprediksi angka berikutnya dalam urutan.
Pada RNN, informasi berputar di dalam loop, sehingga output ditentukan oleh input saat ini dan input yang diterima sebelumnya.
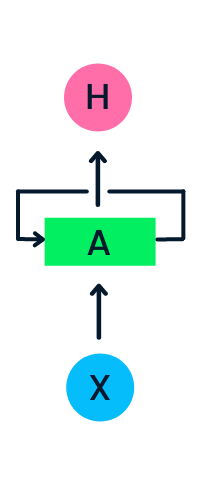
Lapisan input X memproses masukan awal dan meneruskannya ke lapisan tengah A. Lapisan tengah terdiri dari beberapa lapisan tersembunyi, masing-masing dengan fungsi aktivasi, bobot, dan biasnya. Parameter-parameter ini dibuat seragam di seluruh lapisan tersembunyi sehingga alih-alih membuat banyak lapisan tersembunyi, RNN membuat satu dan menjalankannya secara berulang.
Alih-alih menggunakan backpropagation tradisional, jaringan saraf berulang menggunakan algoritma backpropagation through time (BPTT) untuk menentukan gradien. Dalam backpropagation, model menyesuaikan parameter dengan menghitung kesalahan dari output ke lapisan input. BPTT menjumlahkan kesalahan pada setiap langkah waktu karena RNN berbagi parameter di setiap lapisan. Pelajari lebih lanjut tentang RNN dan cara kerjanya di Apa itu Recurrent Neural Networks?.
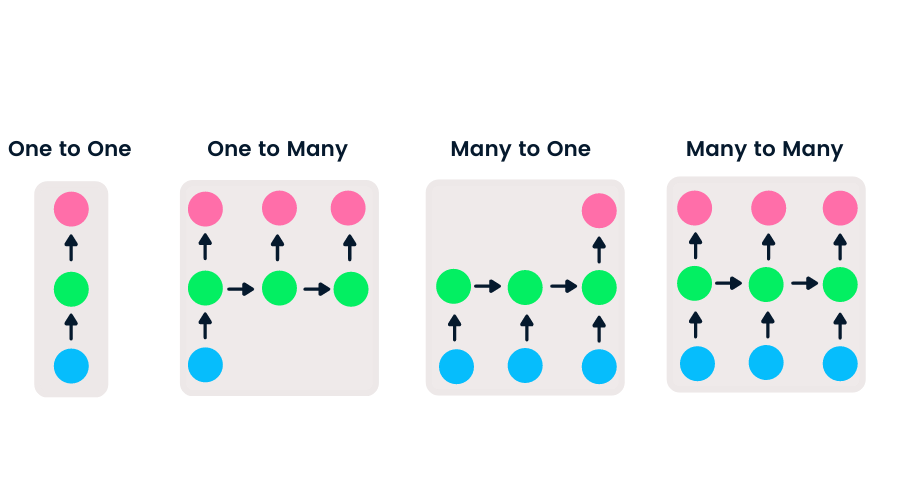
Jaringan feedforward memiliki satu input dan satu output, sedangkan jaringan saraf berulang bersifat fleksibel karena panjang input dan output dapat diubah. Fleksibilitas ini memungkinkan RNN digunakan untuk menghasilkan musik, klasifikasi sentimen, dan penerjemahan mesin.
Ada empat jenis RNN berdasarkan perbedaan panjang input dan output.
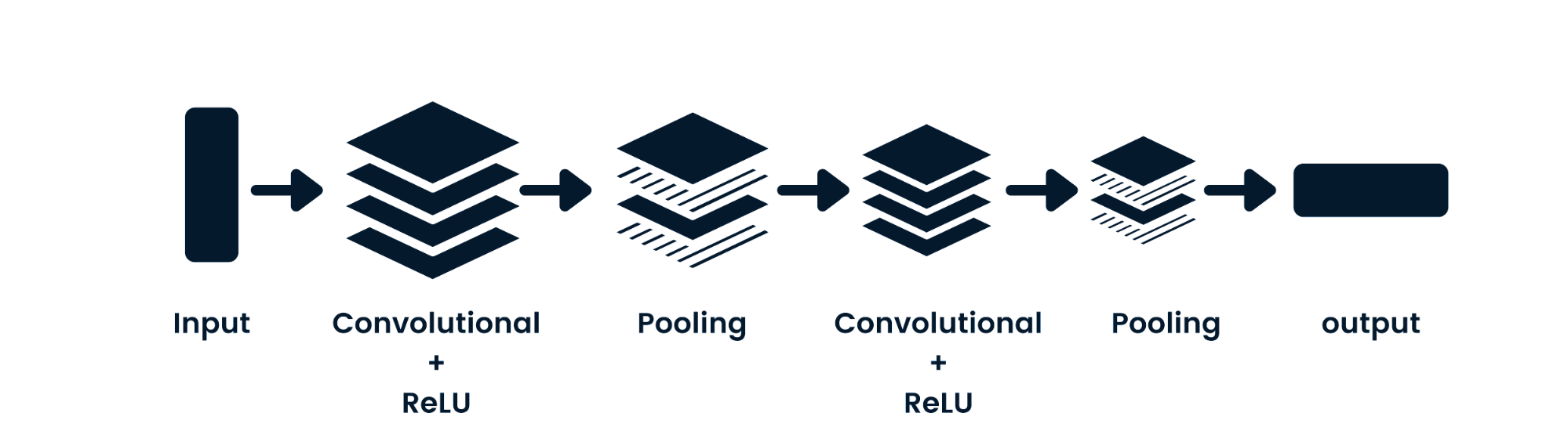
Convolutional neural network (CNN) adalah jaringan saraf feed-forward yang mampu memproses data spasial. Ini umum digunakan untuk aplikasi visi komputer seperti klasifikasi gambar. Jaringan saraf sederhana bagus untuk klasifikasi biner yang sederhana, namun tidak bisa menangani gambar dengan ketergantungan piksel. Arsitektur model CNN terdiri dari lapisan convolutional, lapisan ReLU, lapisan pooling, dan lapisan output yang sepenuhnya terhubung. Anda dapat mempelajari CNN dengan mengerjakan proyek seperti Convolutional Neural Networks in Python.
Model RNN sederhana biasanya menghadapi dua masalah utama. Masalah-masalah ini berkaitan dengan gradien, yaitu kemiringan fungsi loss bersama fungsi error.
Solusi sederhana untuk masalah ini adalah mengurangi jumlah lapisan tersembunyi dalam jaringan saraf, yang akan mengurangi sebagian kompleksitas pada RNN. Masalah-masalah ini juga dapat diatasi dengan menggunakan arsitektur RNN yang lebih maju seperti LSTM dan GRU.
Modul pengulangan RNN sederhana memiliki struktur dasar dengan satu lapisan tanh. Struktur RNN sederhana mengalami keterbatasan memori pendek, di mana ia kesulitan mempertahankan informasi langkah waktu sebelumnya pada data berurutan yang lebih besar. Masalah ini dapat dengan mudah diatasi oleh long short term memory (LSTM) dan gated recurrent unit (GRU), karena keduanya mampu mengingat informasi dalam jangka panjang.
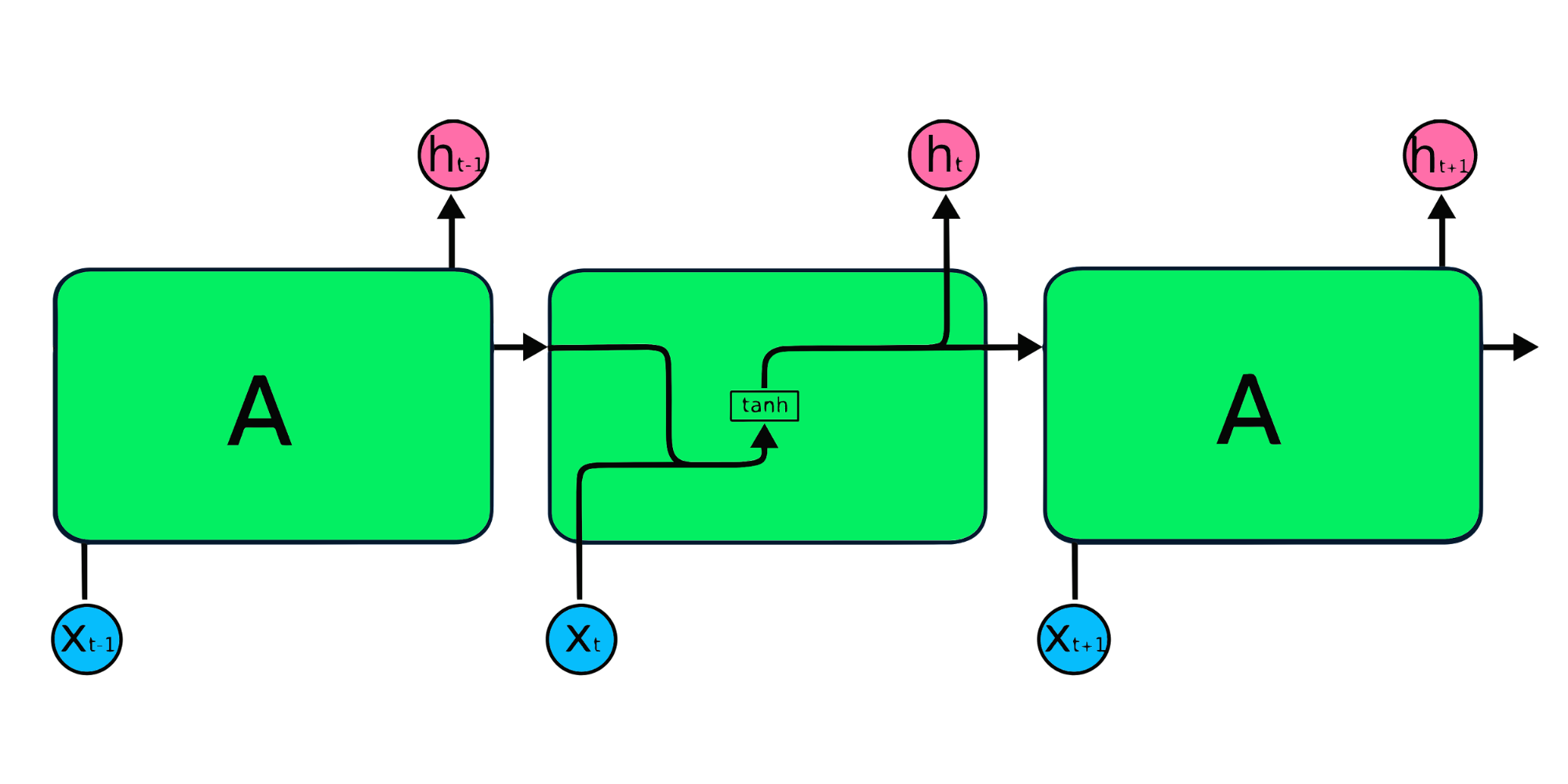
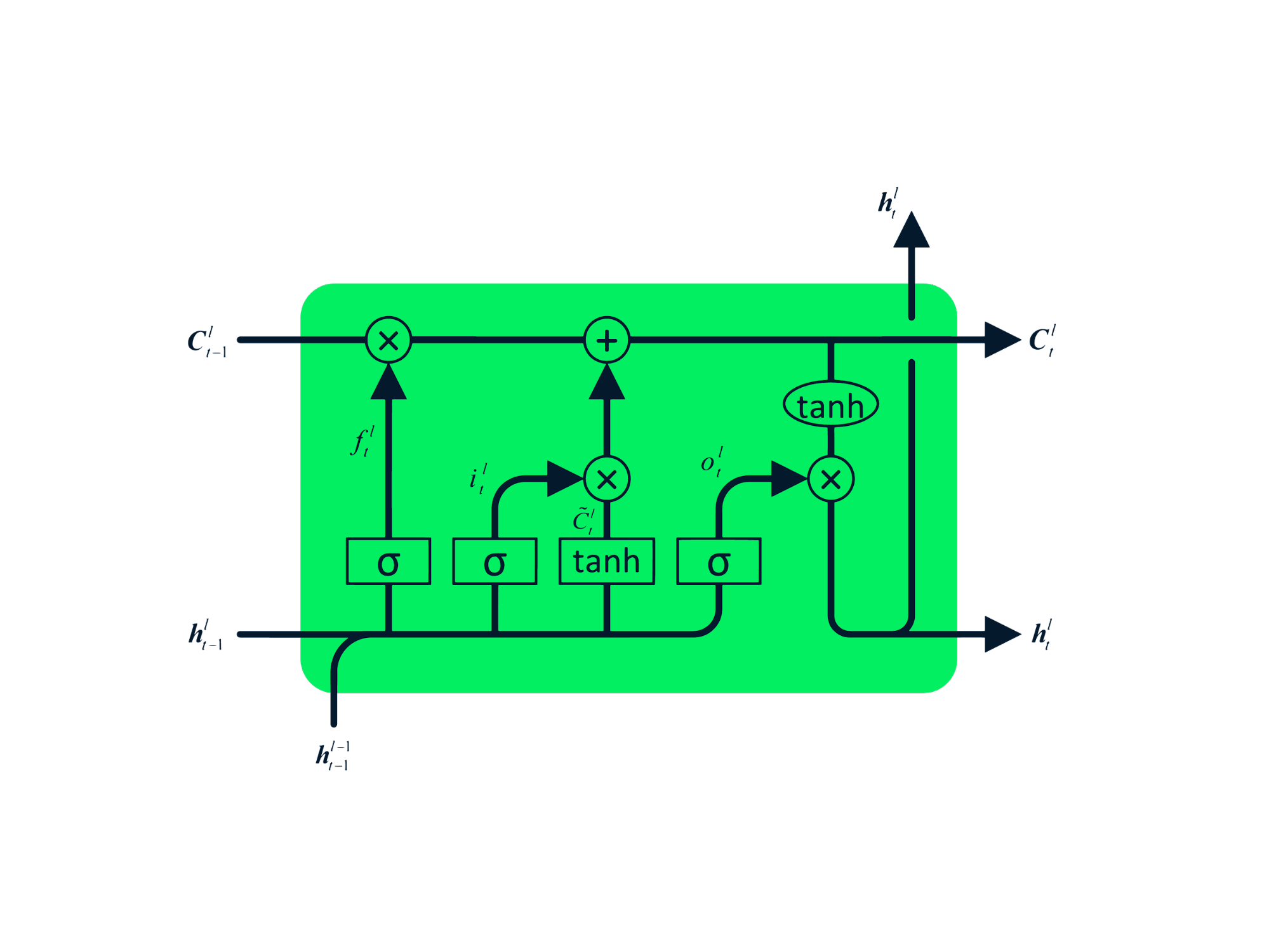
Long Short Term Memory (LSTM) adalah jenis RNN tingkat lanjut yang dirancang untuk mencegah masalah vanishing dan exploding gradient. Sama seperti RNN, LSTM memiliki modul berulang, tetapi strukturnya berbeda. Alih-alih satu lapisan tanh, LSTM memiliki empat lapisan yang saling berinteraksi dan berkomunikasi satu sama lain. Struktur berlapis empat ini membantu LSTM mempertahankan memori jangka panjang dan dapat digunakan dalam berbagai masalah berurutan termasuk penerjemahan mesin, sintesis ucapan, pengenalan ucapan, dan pengenalan tulisan tangan. Anda dapat memperoleh pengalaman langsung dengan LSTM melalui panduan: Python LSTM for Stock Predictions.
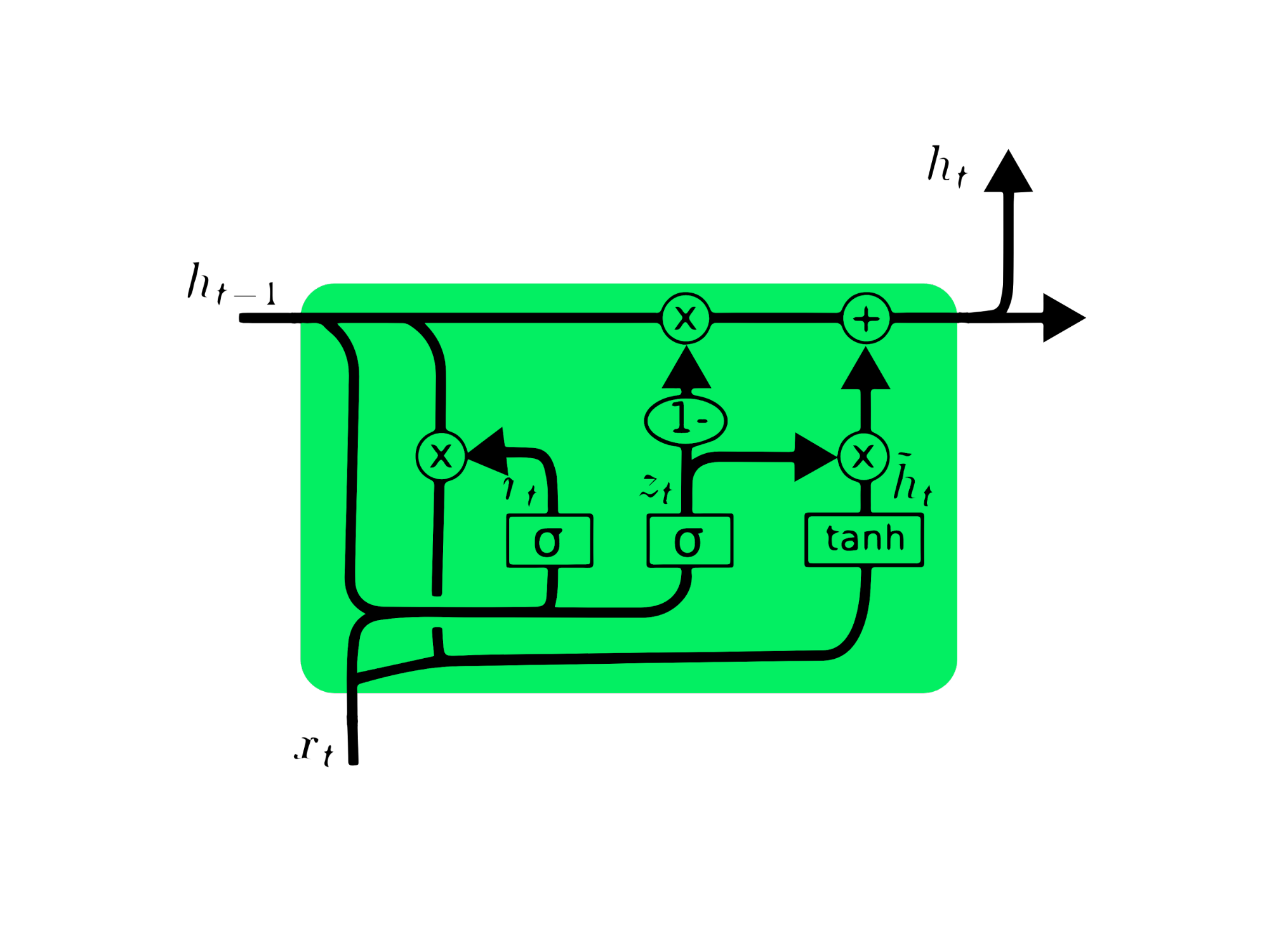
Gated recurrent unit (GRU) adalah variasi dari LSTM karena keduanya memiliki kemiripan desain, dan dalam beberapa kasus menghasilkan hasil yang serupa. GRU menggunakan update gate dan reset gate untuk mengatasi masalah vanishing gradient. Gerbang-gerbang ini menentukan informasi mana yang penting dan meneruskannya ke output. Gerbang dapat dilatih untuk menyimpan informasi sejak lama, tanpa menghilang seiring waktu atau menghapus informasi yang tidak relevan.
Tidak seperti LSTM, GRU tidak memiliki keadaan sel Ct. GRU hanya memiliki keadaan tersembunyi ht, dan karena arsitekturnya yang sederhana, GRU memiliki waktu pelatihan yang lebih singkat dibandingkan model LSTM. Arsitektur GRU mudah dipahami karena menerima input xt dan keadaan tersembunyi dari stempel waktu sebelumnya ht-1 lalu menghasilkan keadaan tersembunyi baru ht. Anda bisa mendapatkan pengetahuan mendalam tentang GRU di Understanding GRU Networks.
Pada proyek ini, kita akan menggunakan dataset saham MasterCard dari Kaggle, mulai 25-Mei-2006 hingga 11-Okt-2021, dan melatih model LSTM dan GRU untuk meramalkan harga saham. Ini adalah tutorial berbasis proyek yang sederhana, di mana kita akan menganalisis data, melakukan prapemrosesan data untuk melatihnya pada model RNN lanjutan, dan akhirnya mengevaluasi hasilnya.
Proyek ini memerlukan Pandas dan Numpy untuk manipulasi data, Matplotlib.pyplot untuk visualisasi data, scikit-learn untuk penskalaan dan evaluasi, serta TensorFlow untuk pemodelan. Kita juga akan menetapkan seed agar hasil dapat direproduksi.
# Importing the libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Dropout, GRU, Bidirectional
from tensorflow.keras.optimizers import SGD
from tensorflow.random import set_seed
set_seed(455)
np.random.seed(455)
Pada bagian ini, kita akan mengimpor dataset MasterCard dengan menambahkan kolom Date ke indeks dan mengonversinya ke format DateTime. Kita juga akan menghapus kolom yang tidak relevan dari dataset karena kita hanya tertarik pada harga saham, volume, dan tanggal.
Dataset memiliki Date sebagai indeks dan Open, High, Low, Close, serta Volume sebagai kolom. Tampaknya kita berhasil mengimpor dataset yang sudah dibersihkan.
dataset = pd.read_csv(
"data/Mastercard_stock_history.csv", index_col="Date", parse_dates=["Date"]
).drop(["Dividends", "Stock Splits"], axis=1)
print(dataset.head())
Open High Low Close Volume
Date
2006-05-25 3.748967 4.283869 3.739664 4.279217 395343000
2006-05-26 4.307126 4.348058 4.103398 4.179680 103044000
2006-05-30 4.183400 4.184330 3.986184 4.093164 49898000
2006-05-31 4.125723 4.219679 4.125723 4.180608 30002000
2006-06-01 4.179678 4.474572 4.176887 4.419686 62344000
Fungsi .describe() membantu kita menganalisis data secara mendalam. Mari fokus pada kolom High karena akan kita gunakan untuk melatih model. Kita juga bisa memilih kolom Close atau Open sebagai fitur model, tetapi High lebih masuk akal karena memberi informasi seberapa tinggi nilai saham pada hari tersebut.
Harga saham minimum adalah $4,10, dan yang tertinggi $400,5. Rata-rata berada pada $105,9 dan simpangan baku $107,3, yang berarti saham memiliki varians tinggi.
print(dataset.describe())
Open High Low Close Volume
count 3872.000000 3872.000000 3872.000000 3872.000000 3.872000e+03
mean 104.896814 105.956054 103.769349 104.882714 1.232250e+07
std 106.245511 107.303589 105.050064 106.168693 1.759665e+07
min 3.748967 4.102467 3.739664 4.083861 6.411000e+05
25% 22.347203 22.637997 22.034458 22.300391 3.529475e+06
50% 70.810079 71.375896 70.224002 70.856083 5.891750e+06
75% 147.688448 148.645373 146.822013 147.688438 1.319775e+07
max 392.653890 400.521479 389.747812 394.685730 3.953430e+08
Dengan menggunakan .isna().sum() kita dapat mengetahui nilai yang hilang dalam dataset. Tampaknya dataset tidak memiliki nilai yang hilang.
dataset.isna().sum()
Open 0
High 0
Low 0
Close 0
Volume 0
dtype: int64
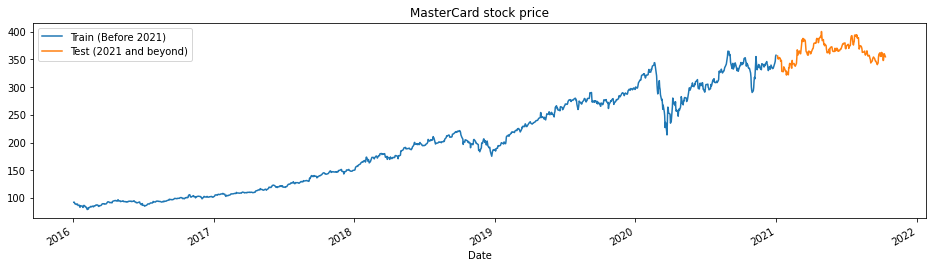
Fungsi train_test_plot menerima tiga argumen: dataset, tstart, dan tend serta membuat plot garis sederhana. tstart dan tend adalah batas waktu dalam tahun. Kita dapat mengubah argumen ini untuk menganalisis periode tertentu. Plot garis dibagi menjadi dua bagian: train dan test. Ini akan membantu kita memutuskan distribusi dataset uji.
Harga saham MasterCard meningkat sejak 2016. Terjadi penurunan pada kuartal pertama 2020 tetapi kemudian kembali stabil pada paruh kedua tahun tersebut. Dataset uji kita terdiri dari satu tahun, dari 2021 hingga 2022, dan sisanya digunakan untuk pelatihan.
tstart = 2016
tend = 2020
def train_test_plot(dataset, tstart, tend):
dataset.loc[f"{tstart}":f"{tend}", "High"].plot(figsize=(16, 4), legend=True)
dataset.loc[f"{tend+1}":, "High"].plot(figsize=(16, 4), legend=True)
plt.legend([f"Train (Before {tend+1})", f"Test ({tend+1} and beyond)"])
plt.title("MasterCard stock price")
plt.show()
train_test_plot(dataset,tstart,tend)
Fungsi train_test_split membagi dataset menjadi dua subset: training_set dan test_set.
def train_test_split(dataset, tstart, tend):
train = dataset.loc[f"{tstart}":f"{tend}", "High"].values
test = dataset.loc[f"{tend+1}":, "High"].values
return train, test
training_set, test_set = train_test_split(dataset, tstart, tend)
Kita akan menggunakan fungsi MinMaxScaler untuk menstandarkan training set, yang akan membantu menghindari outlier atau anomali. Anda juga dapat mencoba menggunakan StandardScaler atau fungsi penskalaan lain untuk menormalkan data Anda dan meningkatkan kinerja model.
sc = MinMaxScaler(feature_range=(0, 1))
training_set = training_set.reshape(-1, 1)
training_set_scaled = sc.fit_transform(training_set)
Fungsi split_sequence menggunakan dataset pelatihan dan mengonversinya menjadi input (X_train) dan output (y_train).
Misalnya, jika urutannya [1,2,3,4,5,6,7,8,9,10,11,12] dan n_step adalah tiga, maka itu akan mengonversi urutan menjadi tiga cap waktu input dan satu output seperti di bawah ini:
| X | y |
|---|---|
| 1,2,3 | 4 |
| 2,3,4 | 5 |
| 3,4,5 | 6 |
| 4,5,6 | 7 |
| … | … |
Pada proyek ini, kita menggunakan 60 n_steps. Kita juga dapat mengurangi atau menambah jumlah langkah untuk mengoptimalkan kinerja model.
def split_sequence(sequence, n_steps):
X, y = list(), list()
for i in range(len(sequence)):
end_ix = i + n_steps
if end_ix > len(sequence) - 1:
break
seq_x, seq_y = sequence[i:end_ix], sequence[end_ix]
X.append(seq_x)
y.append(seq_y)
return np.array(X), np.array(y)
n_steps = 60
features = 1
# split into samples
X_train, y_train = split_sequence(training_set_scaled, n_steps)
Kita bekerja dengan deret univariat, jadi jumlah fiturnya satu, dan kita perlu mengubah bentuk X_train agar sesuai dengan model LSTM. X_train memiliki bentuk [samples, timesteps], dan akan kita ubah menjadi [samples, timesteps, features].
# Reshaping X_train for model
X_train = X_train.reshape(X_train.shape[0],X_train.shape[1],features)
Model terdiri dari satu lapisan tersembunyi LSTM dan satu lapisan output. Anda dapat bereksperimen dengan jumlah unit, karena lebih banyak unit dapat memberikan hasil yang lebih baik. Untuk eksperimen ini, kita menetapkan unit LSTM sebanyak 125, aktivasi tanh, dan menetapkan ukuran input.
Catatan Penulis: Pustaka TensorFlow ramah pengguna, jadi kita tidak perlu membuat model LSTM atau GRU dari nol. Kita cukup menggunakan modul LSTM atau GRU untuk membangun model.
Terakhir, kita akan mengompilasi model dengan optimizer RMSprop dan mean square error sebagai fungsi loss.
# The LSTM architecture
model_lstm = Sequential()
model_lstm.add(LSTM(units=125, activation="tanh", input_shape=(n_steps, features)))
model_lstm.add(Dense(units=1))
# Compiling the model
model_lstm.compile(optimizer="RMSprop", loss="mse")
model_lstm.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm (LSTM) (None, 125) 63500
_________________________________________________________________
dense (Dense) (None, 1) 126
=================================================================
Total params: 63,626
Trainable params: 63,626
Non-trainable params: 0
_________________________________________________________________
Model akan dilatih selama 50 epoch dengan ukuran batch 32. Anda dapat mengubah hiperparameter untuk mengurangi waktu pelatihan atau meningkatkan hasil. Pelatihan model berhasil diselesaikan dengan loss yang sangat baik.
model_lstm.fit(X_train, y_train, epochs=50, batch_size=32)
Epoch 50/50
38/38 [==============================] - 1s 30ms/step - loss: 3.1642e-04
Kita akan mengulangi prapemrosesan dan menormalkan set uji. Pertama-tama kita akan melakukan transformasi lalu membagi dataset menjadi sampel, mengubah bentuknya, melakukan prediksi, dan menginvers transformasi prediksi ke bentuk standar.
dataset_total = dataset.loc[:,"High"]
inputs = dataset_total[len(dataset_total) - len(test_set) - n_steps :].values
inputs = inputs.reshape(-1, 1)
#scaling
inputs = sc.transform(inputs)
# Split into samples
X_test, y_test = split_sequence(inputs, n_steps)
# reshape
X_test = X_test.reshape(X_test.shape[0], X_test.shape[1], features)
#prediction
predicted_stock_price = model_lstm.predict(X_test)
#inverse transform the values
predicted_stock_price = sc.inverse_transform(predicted_stock_price)
Fungsi plot_predictions akan membuat grafik garis aktual versus prediksi. Ini akan membantu kita memvisualisasikan perbedaan antara nilai aktual dan nilai yang diprediksi.
Fungsi return_rmse menerima argumen test dan predicted dan menampilkan metrik root mean square error (rmse).
def plot_predictions(test, predicted):
plt.plot(test, color="gray", label="Real")
plt.plot(predicted, color="red", label="Predicted")
plt.title("MasterCard Stock Price Prediction")
plt.xlabel("Time")
plt.ylabel("MasterCard Stock Price")
plt.legend()
plt.show()
def return_rmse(test, predicted):
rmse = np.sqrt(mean_squared_error(test, predicted))
print("The root mean squared error is {:.2f}.".format(rmse))
Menurut plot garis di bawah, model LSTM berlapis tunggal berkinerja baik.
plot_predictions(test_set,predicted_stock_price)
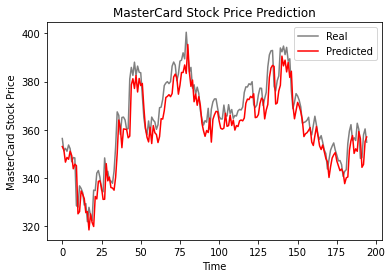
Hasilnya terlihat menjanjikan karena model mendapatkan rmse 6,70 pada dataset uji.
return_rmse(test_set,predicted_stock_price)
>>> The root mean squared error is 6.70.
Kita akan mempertahankan semua yang sama dan hanya mengganti lapisan LSTM dengan lapisan GRU agar bisa membandingkan hasil dengan tepat. Struktur model berisi satu lapisan GRU dengan 125 unit dan satu lapisan output.
model_gru = Sequential()
model_gru.add(GRU(units=125, activation="tanh", input_shape=(n_steps, features)))
model_gru.add(Dense(units=1))
# Compiling the RNN
model_gru.compile(optimizer="RMSprop", loss="mse")
model_gru.summary()
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
gru_4 (GRU) (None, 125) 48000
_________________________________________________________________
dense_5 (Dense) (None, 1) 126
=================================================================
Total params: 48,126
Trainable params: 48,126
Non-trainable params: 0
_________________________________________________________________
Model berhasil dilatih dengan 50 epoch dan ukuran batch 32.
model_gru.fit(X_train, y_train, epochs=50, batch_size=32)
Epoch 50/50
38/38 [==============================] - 1s 29ms/step - loss: 2.6691e-04
Seperti yang terlihat, nilai aktual dan yang diprediksi relatif berdekatan. Grafik garis prediksi hampir sesuai dengan nilai aktual.
GRU_predicted_stock_price = model_gru.predict(X_test)
GRU_predicted_stock_price = sc.inverse_transform(GRU_predicted_stock_price)
plot_predictions(test_set, GRU_predicted_stock_price)
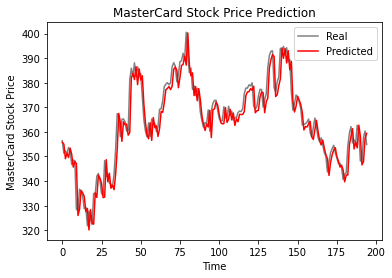
Model GRU memperoleh rmse 5,50 pada dataset uji, yang merupakan peningkatan dibandingkan model LSTM.
return_rmse(test_set,GRU_predicted_stock_price)
>>> The root mean squared error is 5.50.
Dunia bergerak menuju solusi hibrida, di mana data scientist menggunakan jaringan hibrida CNN-RNN dalam bidang pemberian keterangan gambar, deteksi emosi, penulisan teks video, dan pengurutan DNA. Jaringan hibrida menyediakan karakteristik visual dan temporal bagi model. Pelajari lebih lanjut tentang RNN dengan mengikuti kursus: Recurrent Neural Networks for Language Modeling in Python.
Paruh pertama tutorial membahas dasar-dasar jaringan saraf berulang, keterbatasannya, dan solusinya dalam bentuk arsitektur yang lebih maju. Paruh kedua tutorial membahas pengembangan prediksi harga saham MasterCard menggunakan model LSTM dan GRU. Hasilnya jelas menunjukkan bahwa model GRU berkinerja lebih baik daripada LSTM, dengan struktur dan hiperparameter yang serupa.
Proyek ini tersedia di DataCamp workspace.