Recurrent Neural Networks (RNNs) for Language Modeling with Keras
BeginnerSkill Level
4 h
16.3K learners
Una red neuronal recurrente (RNN) es el tipo de red neuronal artificial (ANN) que se utiliza en Siri de Apple y en la búsqueda por voz de Google. Las RNN recuerdan entradas pasadas gracias a una memoria interna que es útil para predecir los precios de las acciones y generar texto, transcripciones y traducción automática.
En la red neuronal tradicional, las entradas y las salidas son independientes, mientras que la salida en la RNN depende de elementos anteriores dentro de la secuencia. Las redes recurrentes también comparten parámetros entre todas las capas de la red. En las redes prealimentadas, hay distintos pesos en cada nodo. Mientras que la RNN comparte los mismos pesos en todas las capas de la red y durante el descenso del gradiente, los pesos y la base se ajustan individualmente para reducir la pérdida.
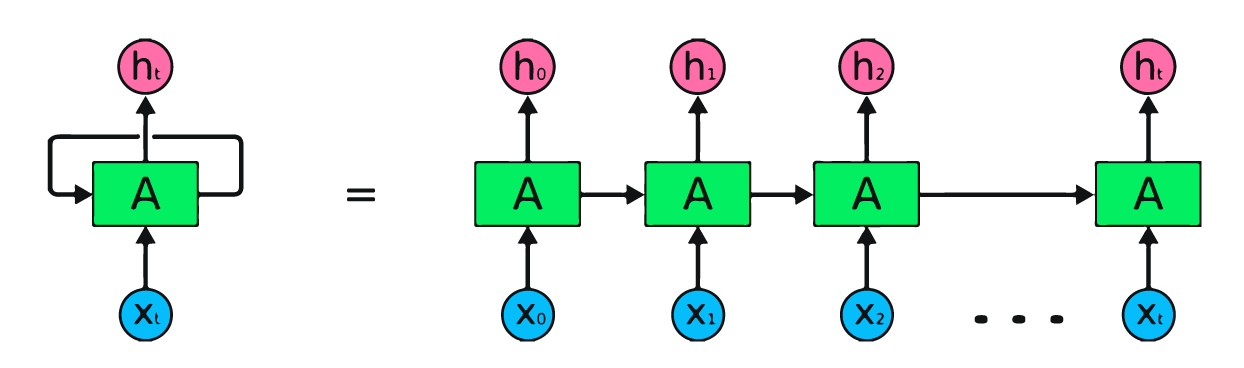
La imagen anterior es una representación sencilla de las redes neuronales recurrentes. Si estamos pronosticando los precios de las acciones utilizando datos sencillos [45,56,45,49,50,...], cada entrada de X0 a Xt contendrá un valor pasado. Por ejemplo, X0 tendrá 45, X1 tendrá 56, y estos valores se utilizan para predecir el siguiente número de una secuencia.
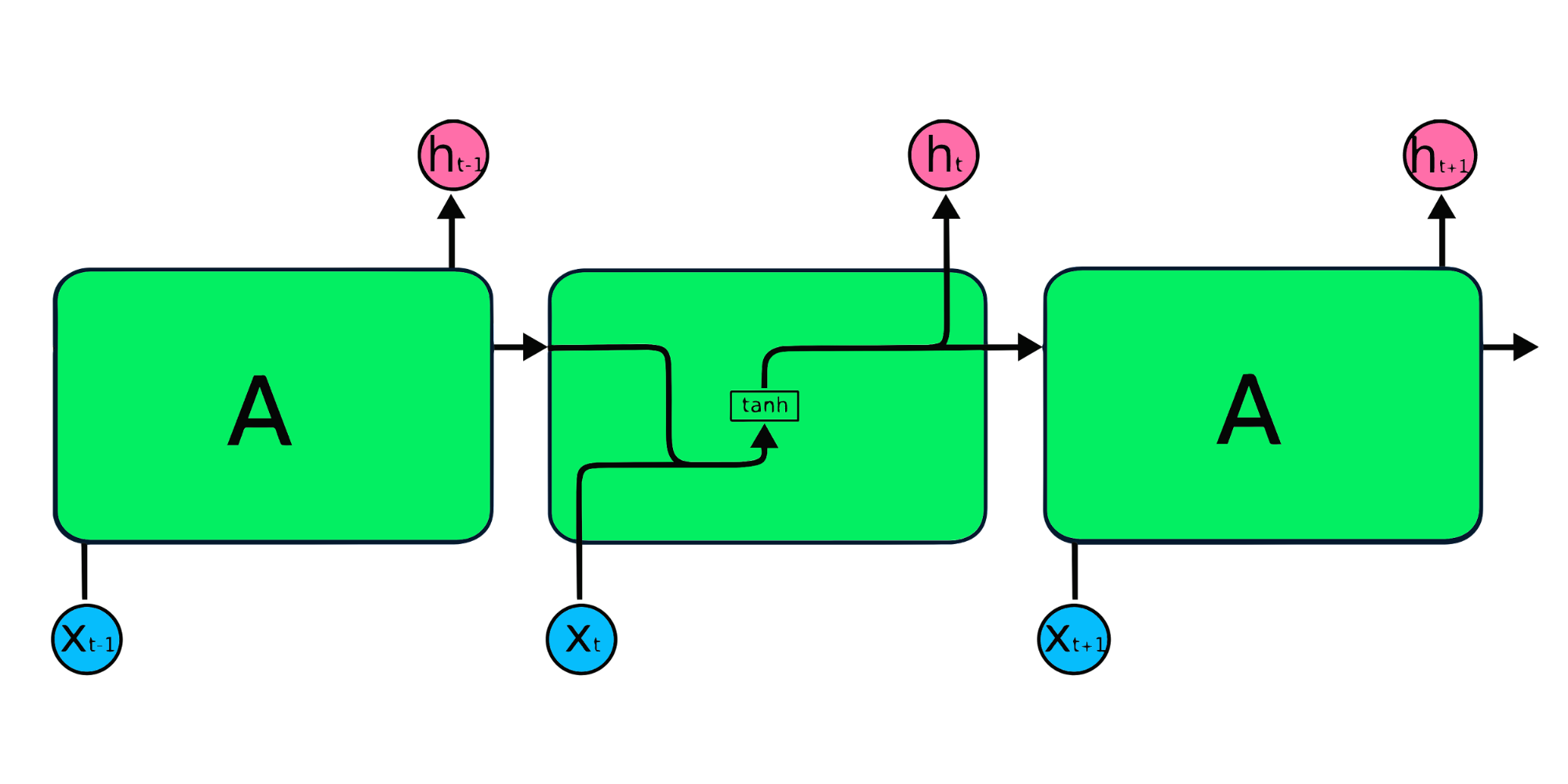
En la RNN, la información circula por el bucle, de modo que la salida viene determinada por la entrada actual y las entradas recibidas anteriormente.
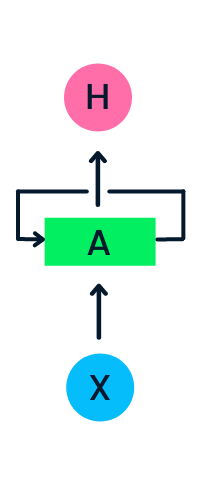
La capa de entrada X procesa la entrada inicial y la pasa a la capa intermedia A. La capa intermedia consta de varias capas ocultas, cada una con sus funciones de activación, sus pesos y sus sesgos. Estos parámetros están estandarizados en toda la capa oculta, de modo que, en lugar de crear varias capas ocultas, creará una y la repetirá en bucle.
En lugar de utilizar la propagación hacia atrás de los errores tradicional, las redes neuronales recurrentes utilizan algoritmos de propagación hacia atrás de los errores a través del tiempo (BPTT) para determinar el gradiente. En la propagación hacia atrás de los errores, el modelo ajusta el parámetro calculando los errores de la capa de salida a la de entrada. La BPTT suma el error en cada paso temporal, ya que la RNN comparte los parámetros en todas las capas. Más información sobre las RNN y su funcionamiento en ¿Qué son las redes neuronales recurrentes?
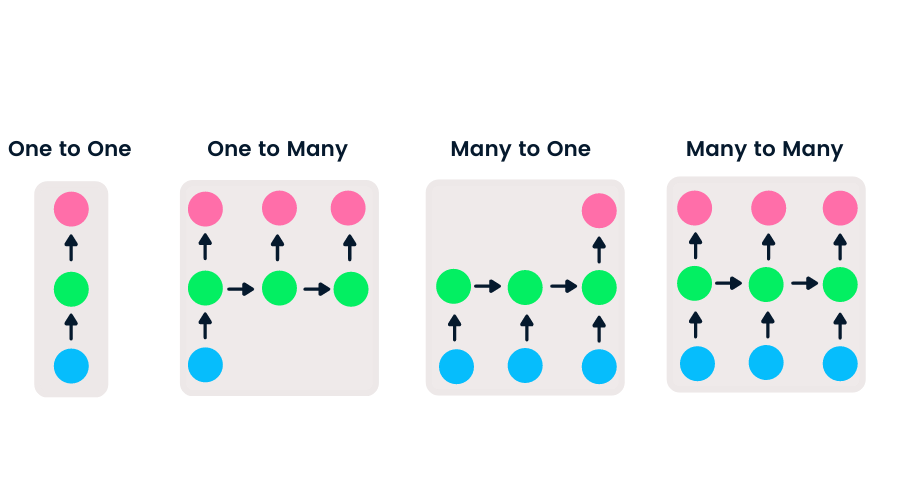
Las redes prealimentadas tienen entrada y salida únicas, mientras que las redes neuronales recurrentes son flexibles, ya que se puede cambiar la longitud de las entradas y las salidas. Esta flexibilidad permite a las RNN generar música, clasificación de sentimiento y traducción automática.
Hay cuatro tipos de RNN basados en diferentes longitudes de entradas y salidas.
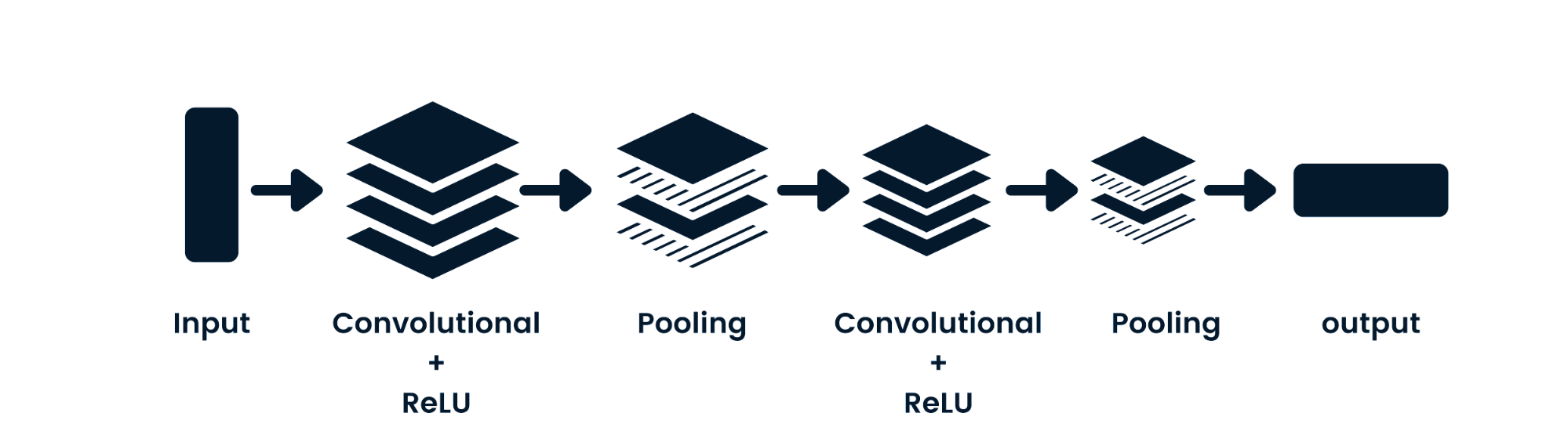
La red neuronal convolucional (CNN) es una red neuronal prealimentada capaz de procesar datos espaciales. Se utiliza habitualmente para aplicaciones de visión artificial, como la clasificación de imágenes. Las redes neuronales sencillas son buenas en clasificaciones binarias sencillas, pero no pueden manejar imágenes con dependencias de píxeles. La arquitectura del modelo CNN consta de capas convolucionales, capas ReLU, capas de pooling y capas de salida totalmente conectadas. Puedes aprender CNN trabajando en un proyecto como Redes neuronales convolucionales en Python.
Los modelos RNN sencillos suelen tener dos problemas principales. Estos problemas están relacionadas con el gradiente, que es la pendiente de la función de pérdida junto con la función de error.
La solución sencilla a estos problemas es reducir el número de capas ocultas de la red neuronal, lo que reducirá la complejidad en las RNN. Estos problemas también pueden resolverse utilizando arquitecturas RNN avanzadas, como LSTM y GRU.
Los módulos de repetición RNN sencillos tienen una estructura básica con una capa tanh única. La estructura sencilla de la RNN adolece de memoria corta, por lo que le cuesta retener la información de pasos temporales anteriores en datos secuenciales más numerosos. Estos problemas pueden resolverse fácilmente mediante la Long short-term memory (LSTM) y la unidad recurrente cerrada (GRU), ya que son capaces de recordar largos periodos de información.
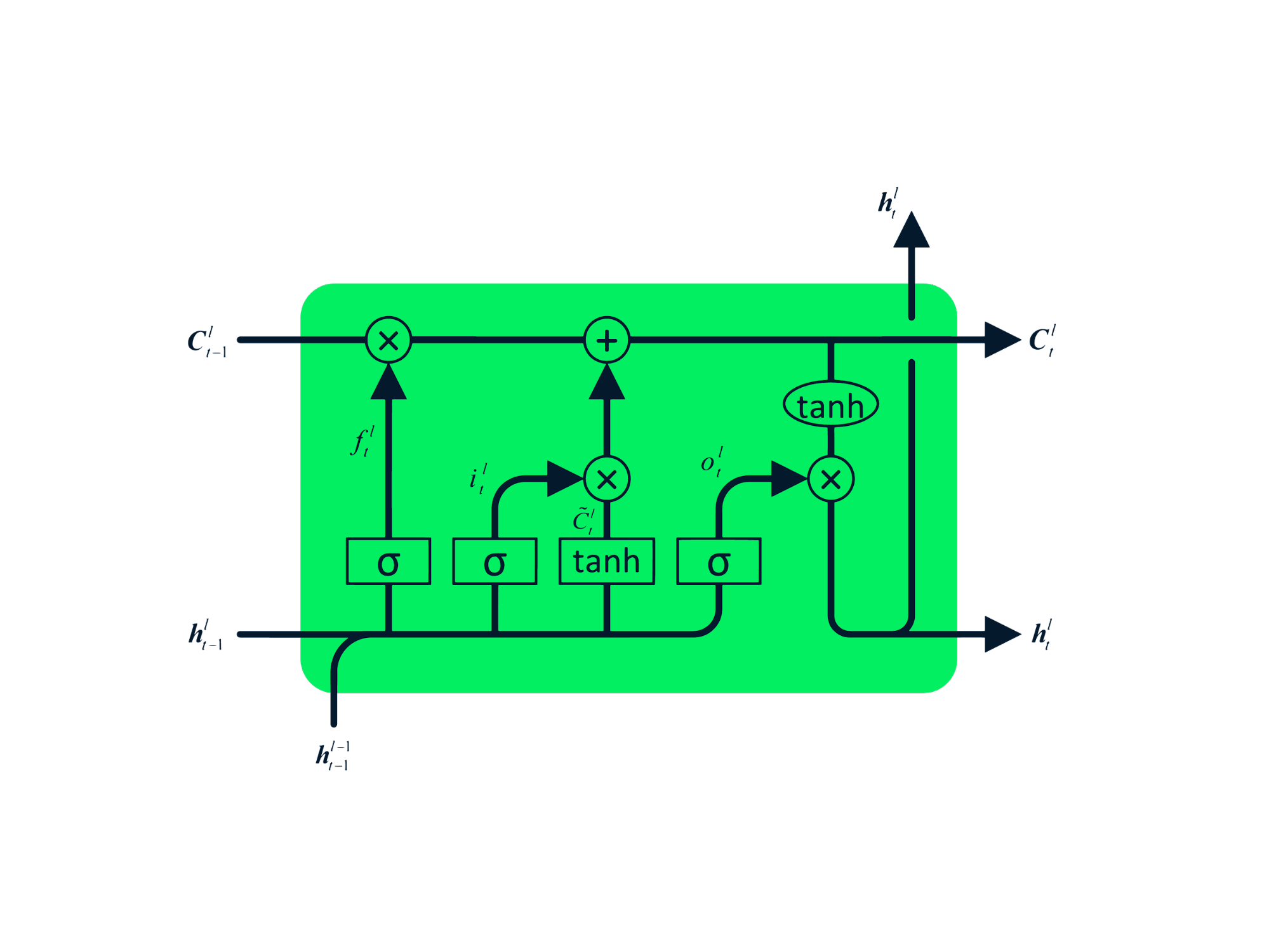
La Long short-term memory (LSTM) es el tipo avanzado de RNN, que se diseñó para evitar tanto los problemas de desvanecimiento como los de explosión de gradiente. Al igual que la RNN, la LSTM tiene módulos que se repiten, pero la estructura es diferente. En lugar de tener una capa única de tanh, la LSTM tiene cuatro capas que interactúan y se comunican. Esta estructura de cuatro capas ayuda a la LSTM a conservar la memoria a largo plazo y puede utilizarse en varios problemas secuenciales, como la traducción automática, la síntesis del habla, el reconocimiento del habla y el reconocimiento de la escritura a mano. Puedes adquirir experiencia práctica en LSTM siguiendo la guía: LSTM Python para predicciones bursátiles.
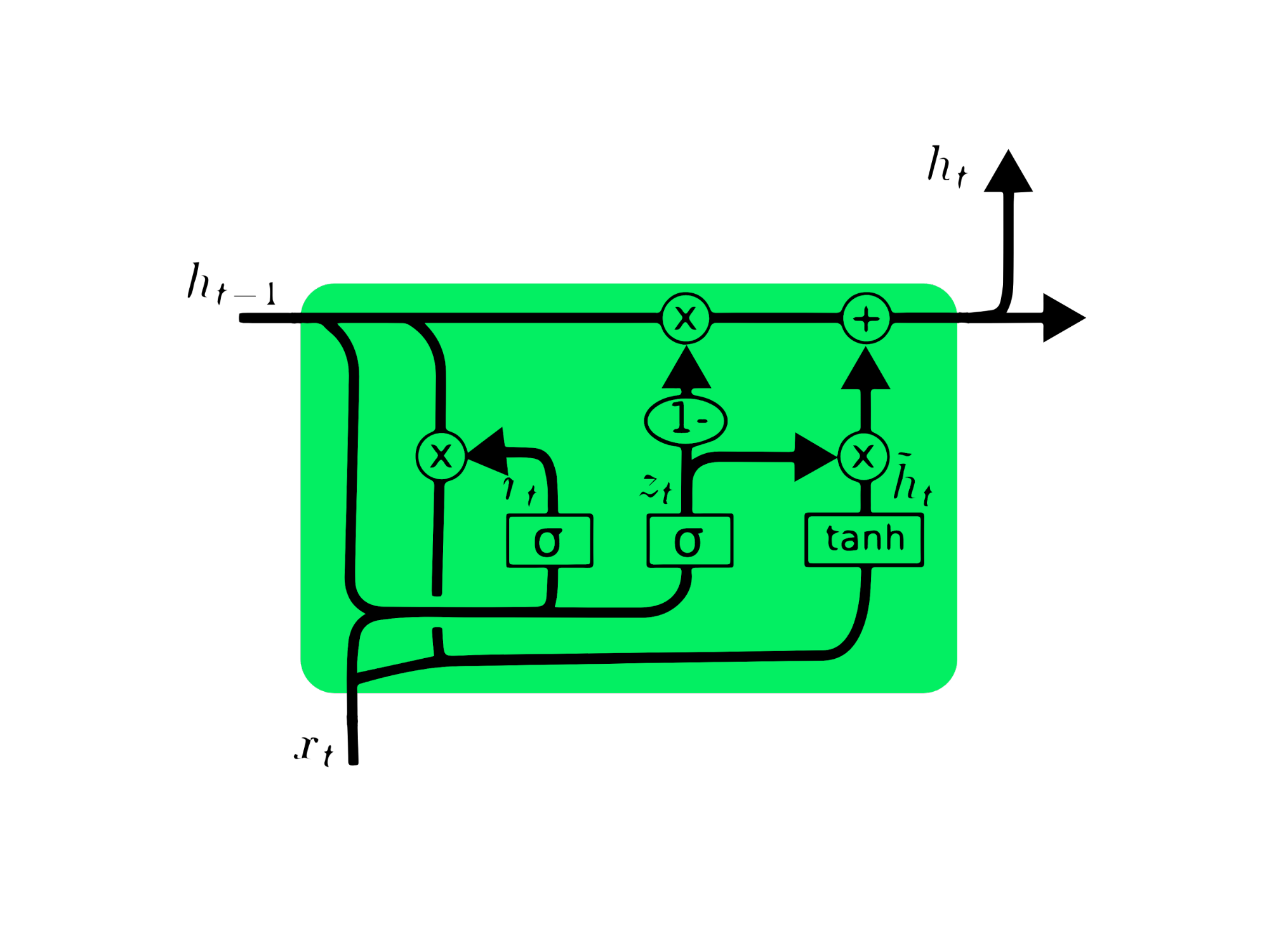
La unidad recurrente cerrada (GRU) es una variación de la LSTM, ya que ambas tienen similitudes de diseño y, en algunos casos, producen resultados parecidos. La GRU utiliza una compuerta de actualización y una compuerta de reinicio para resolver el problema de desvanecimiento de gradiente. Estas compuertas deciden qué información es importante y la pasan a la salida. Las compuertas pueden entrenarse para almacenar información de hace mucho tiempo, sin que se desvanezca con el tiempo y sin eliminar la información irrelevante.
A diferencia de la LSTM, la GRU no tiene estado de celda Ct. Solo tiene un estado oculto ht, y debido a la sencillez de su arquitectura, la GRU tiene un tiempo de entrenamiento menor que los modelos LSTM. La arquitectura GRU es fácil de entender, ya que toma la entrada xt y el estado oculto de la marca temporal anterior ht-1 y da como salida el nuevo estado oculto ht. Puedes obtener información detallada sobre GRU en Comprender las redes GRU.
En este proyecto, vamos a utilizar el conjunto de datos de acciones de MasterCard de Kaggle del 25 de mayo de 2006 al 11 de octubre de 2021 y a entrenar los modelos LSTM y GRU para predecir el precio de las acciones. Se trata de un sencillo tutorial basado en un proyecto en el que analizaremos datos, los preprocesaremos para entrenarlos con modelos RNN avanzados y, por último, evaluaremos los resultados.
El proyecto requiere Pandas y Numpy para la manipulación de datos, Matplotlib.pyplot para la visualización de datos, scikit-learn para el escalado y la evaluación y TensorFlow para la modelación. También pondremos semillas de reproducibilidad.
# Importing the libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Dropout, GRU, Bidirectional
from tensorflow.keras.optimizers import SGD
from tensorflow.random import set_seed
set_seed(455)
np.random.seed(455)
En esta parte, importaremos el conjunto de datos MasterCard añadiendo la columna Date al índice y convirtiéndola al formato DateTime. También eliminaremos las columnas irrelevantes del conjunto de datos, ya que solo nos interesan los precios de las acciones, el volumen y la fecha.
El conjunto de datos tiene Date como índice y Open, High, Low, Close y Volume como columnas. Parece que hemos importado correctamente un conjunto de datos limpio.
dataset = pd.read_csv(
"data/Mastercard_stock_history.csv", index_col="Date", parse_dates=["Date"]
).drop(["Dividends", "Stock Splits"], axis=1)
print(dataset.head())
Open High Low Close Volume
Date
2006-05-25 3.748967 4.283869 3.739664 4.279217 395343000
2006-05-26 4.307126 4.348058 4.103398 4.179680 103044000
2006-05-30 4.183400 4.184330 3.986184 4.093164 49898000
2006-05-31 4.125723 4.219679 4.125723 4.180608 30002000
2006-06-01 4.179678 4.474572 4.176887 4.419686 62344000
La función .describe() nos ayuda a analizar los datos en profundidad. Vamos a centrarnos en la columna High, ya que vamos a utilizarla para entrenar el modelo. También podemos elegir las columnas Close u Open para una característica del modelo, pero High tiene más sentido, ya que nos proporciona información de lo alto que subieron los valores de la acción en un día determinado.
El precio mínimo de las acciones es de 4,10 $ y el máximo es de 400,5 $. La media está en 105,9 $ y la desviación típica, en 107,3 $, lo que significa que las acciones tienen una varianza elevada.
print(dataset.describe())
Open High Low Close Volume
count 3872.000000 3872.000000 3872.000000 3872.000000 3.872000e+03
mean 104.896814 105.956054 103.769349 104.882714 1.232250e+07
std 106.245511 107.303589 105.050064 106.168693 1.759665e+07
min 3.748967 4.102467 3.739664 4.083861 6.411000e+05
25% 22.347203 22.637997 22.034458 22.300391 3.529475e+06
50% 70.810079 71.375896 70.224002 70.856083 5.891750e+06
75% 147.688448 148.645373 146.822013 147.688438 1.319775e+07
max 392.653890 400.521479 389.747812 394.685730 3.953430e+08
Utilizando .isna().sum() podemos determinar los valores que faltan en el conjunto de datos. Parece que en el conjunto de datos no falta ningún valor.
dataset.isna().sum()
Open 0
High 0
Low 0
Close 0
Volume 0
dtype: int64
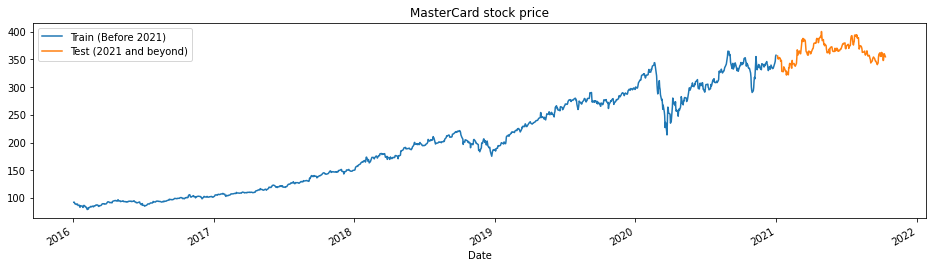
La función train_test_plot toma tres argumentos: dataset, tstart y tend, y traza un gráfico de líneas sencillo. tstart y tend son límites de tiempo en años. Podemos cambiar estos argumentos para analizar periodos concretos. El gráfico de líneas se divide en dos partes: entrenamiento y prueba. Esto nos permitirá decidir la distribución del conjunto de datos de prueba.
El precio de las acciones de MasterCard lleva subiendo desde 2016. Tuvo un bajón en el primer trimestre de 2020, pero se estabilizó en la segunda mitad del año. Nuestro conjunto de datos de prueba consta de un año, de 2021 a 2022, y el resto del conjunto de datos se utiliza para el entrenamiento.
tstart = 2016
tend = 2020
def train_test_plot(dataset, tstart, tend):
dataset.loc[f"{tstart}":f"{tend}", "High"].plot(figsize=(16, 4), legend=True)
dataset.loc[f"{tend+1}":, "High"].plot(figsize=(16, 4), legend=True)
plt.legend([f"Train (Before {tend+1})", f"Test ({tend+1} and beyond)"])
plt.title("MasterCard stock price")
plt.show()
train_test_plot(dataset,tstart,tend)
La función train_test_split divide el conjunto de datos en dos subconjuntos: training_set y test_set.
def train_test_split(dataset, tstart, tend):
train = dataset.loc[f"{tstart}":f"{tend}", "High"].values
test = dataset.loc[f"{tend+1}":, "High"].values
return train, test
training_set, test_set = train_test_split(dataset, tstart, tend)
Utilizaremos la función MinMaxScaler para estandarizar nuestro conjunto de entrenamiento, lo que nos ayudará a evitar los valores atípicos o anomalías. También puedes probar a utilizar StandardScaler o cualquier otra función escalar para normalizar tus datos y mejorar el rendimiento del modelo.
sc = MinMaxScaler(feature_range=(0, 1))
training_set = training_set.reshape(-1, 1)
training_set_scaled = sc.fit_transform(training_set)
La función split_sequence utiliza un conjunto de datos de entrenamiento y lo convierte en entradas (X_train) y salidas (y_train).
Por ejemplo, si la secuencia es [1,2,3,4,5,6,7,8,9,10,11,12] y el n_step es tres, convertirá la secuencia en tres marcas de tiempo de entrada y una salida, como se muestra a continuación:
| X | y |
|---|---|
| 1,2,3 | 4 |
| 2,3,4 | 5 |
| 3,4,5 | 6 |
| 4,5,6 | 7 |
| … | … |
En este proyecto, utilizamos 60 n_steps. También podemos reducir o aumentar el número de pasos para optimizar el rendimiento del modelo.
def split_sequence(sequence, n_steps):
X, y = list(), list()
for i in range(len(sequence)):
end_ix = i + n_steps
if end_ix > len(sequence) - 1:
break
seq_x, seq_y = sequence[i:end_ix], sequence[end_ix]
X.append(seq_x)
y.append(seq_y)
return np.array(X), np.array(y)
n_steps = 60
features = 1
# split into samples
X_train, y_train = split_sequence(training_set_scaled, n_steps)
Trabajamos con series univariadas, por lo que el número de características es uno, y necesitamos remodelar X_train para que se ajuste al modelo LSTM. X_train tiene [samples, timesteps], y lo remodelaremos a [samples, timesteps, features].
# Reshaping X_train for model
X_train = X_train.reshape(X_train.shape[0],X_train.shape[1],features)
El modelo consta de una capa oculta única de LSTM y una capa de salida. Puedes experimentar con el número de unidades, ya que con más unidades obtendrás mejores resultados. Para este experimento, fijaremos las unidades LSTM en 125, tanh como activación y fijaremos el tamaño de entrada.
Nota del autor: La biblioteca Tensorflow es fácil de usar, por lo que no tenemos que crear modelos LSTM o GRU desde cero. Utilizaremos simplemente los módulos LSTM o GRU para construir el modelo.
Por último, compilaremos el modelo con un optimizador RMSprop y el error cuadrático medio como función de pérdida.
# The LSTM architecture
model_lstm = Sequential()
model_lstm.add(LSTM(units=125, activation="tanh", input_shape=(n_steps, features)))
model_lstm.add(Dense(units=1))
# Compiling the model
model_lstm.compile(optimizer="RMSprop", loss="mse")
model_lstm.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm (LSTM) (None, 125) 63500
_________________________________________________________________
dense (Dense) (None, 1) 126
=================================================================
Total params: 63,626
Trainable params: 63,626
Non-trainable params: 0
_________________________________________________________________
El modelo se entrenará en 50 epochs con 32 tamaños de lote. Puedes cambiar los hiperparámetros para reducir el tiempo de entrenamiento o mejorar los resultados. El entrenamiento del modelo se ha completado correctamente con la mejor pérdida posible.
model_lstm.fit(X_train, y_train, epochs=50, batch_size=32)
Epoch 50/50
38/38 [==============================] - 1s 30ms/step - loss: 3.1642e-04
Vamos a repetir el preprocesamiento y a normalizar el conjunto de prueba. En primer lugar, transformaremos el conjunto de datos y, a continuación, lo dividiremos en muestras, le daremos nueva forma, predeciremos y aplicaremos el método de la transformada inversa a las predicciones para darles forma estándar.
dataset_total = dataset.loc[:,"High"]
inputs = dataset_total[len(dataset_total) - len(test_set) - n_steps :].values
inputs = inputs.reshape(-1, 1)
#scaling
inputs = sc.transform(inputs)
# Split into samples
X_test, y_test = split_sequence(inputs, n_steps)
# reshape
X_test = X_test.reshape(X_test.shape[0], X_test.shape[1], features)
#prediction
predicted_stock_price = model_lstm.predict(X_test)
#inverse transform the values
predicted_stock_price = sc.inverse_transform(predicted_stock_price)
La función plot_predictions trazará un gráfico de líneas de valores reales frente a valores previstos. Esto nos ayudará a visualizar la diferencia entre los valores reales y los previstos.
La función return_rmse toma argumentos de prueba y predicción e imprime el parámetro de raíz del error cuadrático medio (rmse).
def plot_predictions(test, predicted):
plt.plot(test, color="gray", label="Real")
plt.plot(predicted, color="red", label="Predicted")
plt.title("MasterCard Stock Price Prediction")
plt.xlabel("Time")
plt.ylabel("MasterCard Stock Price")
plt.legend()
plt.show()
def return_rmse(test, predicted):
rmse = np.sqrt(mean_squared_error(test, predicted))
print("The root mean squared error is {:.2f}.".format(rmse))
Según el gráfico de líneas que aparece a continuación, el modelo LSTM de capa única ha funcionado bien.
plot_predictions(test_set,predicted_stock_price)
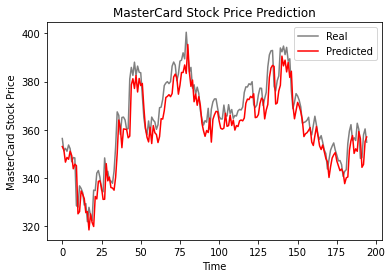
Los resultados parecen prometedores, ya que el modelo obtuvo 6,70 rmse en el conjunto de datos de prueba.
return_rmse(test_set,predicted_stock_price)
>>> The root mean squared error is 6.70.
Vamos a mantener todo igual y solo vamos a sustituir la capa LSTM por la capa GRU para comparar adecuadamente los resultados. La estructura del modelo contiene una capa GRU única con 125 unidades y una capa de salida.
model_gru = Sequential()
model_gru.add(GRU(units=125, activation="tanh", input_shape=(n_steps, features)))
model_gru.add(Dense(units=1))
# Compiling the RNN
model_gru.compile(optimizer="RMSprop", loss="mse")
model_gru.summary()
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
gru_4 (GRU) (None, 125) 48000
_________________________________________________________________
dense_5 (Dense) (None, 1) 126
=================================================================
Total params: 48,126
Trainable params: 48,126
Non-trainable params: 0
_________________________________________________________________
El modelo se ha entrenado correctamente con 50 epochs y un tamaño de lote de 32.
model_gru.fit(X_train, y_train, epochs=50, batch_size=32)
Epoch 50/50
38/38 [==============================] - 1s 29ms/step - loss: 2.6691e-04
Como vemos, los valores reales y previstos están relativamente próximos. El gráfico de líneas con los valores previstos casi se ajusta a los valores reales.
GRU_predicted_stock_price = model_gru.predict(X_test)
GRU_predicted_stock_price = sc.inverse_transform(GRU_predicted_stock_price)
plot_predictions(test_set, GRU_predicted_stock_price)
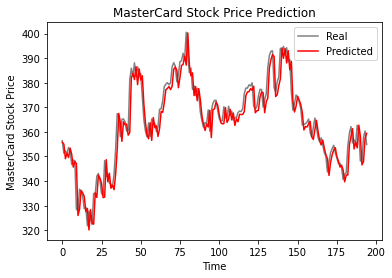
El modelo GRU obtuvo 5,50 rmse en el conjunto de datos de prueba, lo que supone una mejora respecto al modelo LSTM.
return_rmse(test_set,GRU_predicted_stock_price)
>>> The root mean squared error is 5.50.
El mundo avanza hacia soluciones híbridas en las que los científicos de datos utilizan redes híbridas CNN-RNN en el campo de los pies de foto, la detección de emociones, el subtitulado de vídeos y la secuenciación del ADN. Las redes híbridas proporcionan al modelo características visuales y temporales. Aprende más sobre RNN haciendo el curso: Redes neuronales recurrentes para modelación del lenguaje en Python.
La primera mitad del tutorial abarca los fundamentos de las redes neuronales recurrentes, sus limitaciones y las soluciones en forma de arquitectura más avanzada. La segunda mitad del tutorial trata sobre el desarrollo de predicciones del precio de las acciones de MasterCard utilizando modelos LSTM y GRU. Los resultados muestran claramente que el modelo GRU funcionó mejor que la LSTM, con una estructura y unos hiperparámetros similares.
Este proyecto está disponible en DataCamp Workspace.
blog
Natassha Selvaraj
15 min
Tutorial
Abid Ali Awan
Tutorial
Bharath K
Tutorial
Zoumana Keita
Tutorial
Thushan Ganegedara
Tutorial
Abid Ali Awan


