Recurrent Neural Networks (RNNs) for Language Modeling with Keras
BasicSkill Level
4 h
16.3K learners
Una rete neurale ricorrente (RNN) è un tipo di rete neurale artificiale (ANN) usata in Siri di Apple e nella ricerca vocale di Google. Le RNN ricordano gli input passati grazie a una memoria interna, utile per prevedere i prezzi delle azioni, generare testo, trascrizioni e traduzioni automatiche.
Nelle reti neurali tradizionali, input e output sono indipendenti tra loro, mentre nelle RNN l’output dipende dagli elementi precedenti nella sequenza. Le reti ricorrenti condividono anche i parametri tra ciascun livello della rete. Nelle reti feedforward ci sono pesi diversi per ciascun nodo; nelle RNN, invece, gli stessi pesi sono condivisi all’interno di ogni livello della rete e durante la discesa del gradiente, pesi e bias vengono regolati individualmente per ridurre la loss.
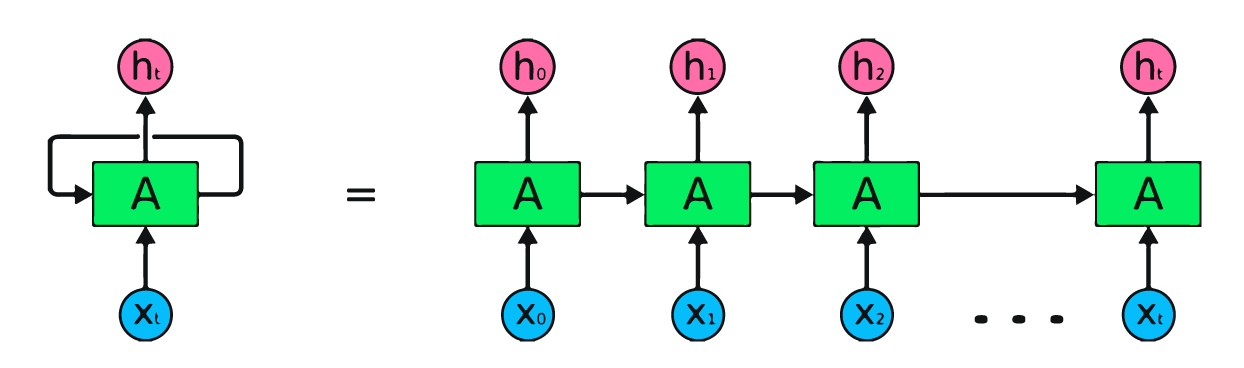
L’immagine sopra rappresenta in modo semplice le reti neurali ricorrenti. Se stiamo prevedendo i prezzi delle azioni usando dati semplici [45,56,45,49,50,…], ogni input da X0 a Xt conterrà un valore passato. Per esempio, X0 avrà 45, X1 avrà 56, e questi valori vengono usati per prevedere il numero successivo in una sequenza.
Nelle RNN, l’informazione scorre in un loop, quindi l’output è determinato dall’input corrente e dagli input ricevuti in precedenza.
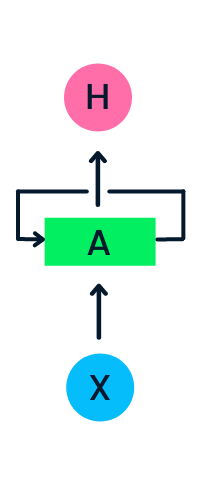
Il livello di input X elabora l’input iniziale e lo passa al livello intermedio A. Il livello intermedio è composto da più livelli nascosti, ciascuno con le proprie funzioni di attivazione, pesi e bias. Questi parametri sono standardizzati nel livello nascosto così che, invece di creare molteplici livelli nascosti, se ne crea uno e lo si itera in loop.
Invece di usare la tradizionale backpropagation, le reti neurali ricorrenti utilizzano algoritmi di backpropagation through time (BPTT) per determinare il gradiente. Nella backpropagation, il modello regola i parametri calcolando gli errori dall’output all’input. La BPTT somma l’errore a ogni passo temporale poiché le RNN condividono i parametri tra i livelli. Scopri di più sulle RNN e su come funzionano in What are Recurrent Neural Networks?.
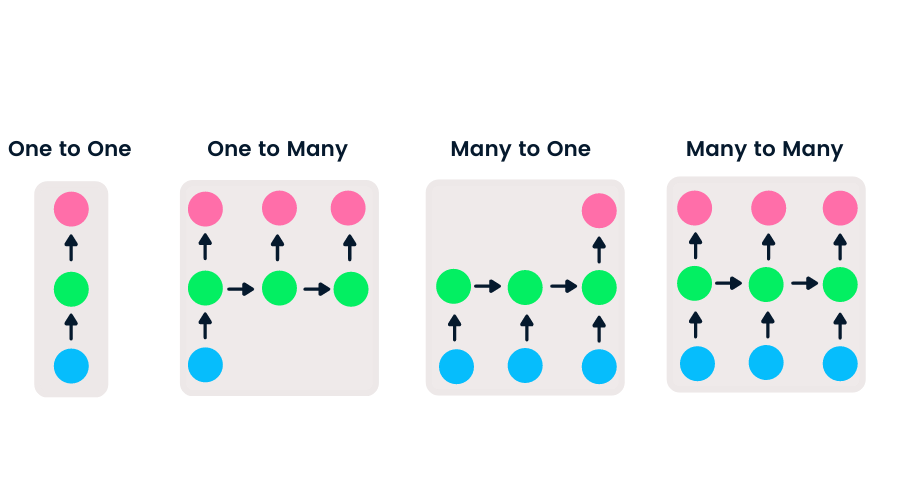
Le reti feedforward hanno un singolo input e un singolo output, mentre le reti neurali ricorrenti sono flessibili perché la lunghezza di input e output può variare. Questa flessibilità permette alle RNN di generare musica, fare classificazione del sentiment e traduzione automatica.
Esistono quattro tipi di RNN basati su diverse lunghezze di input e output.
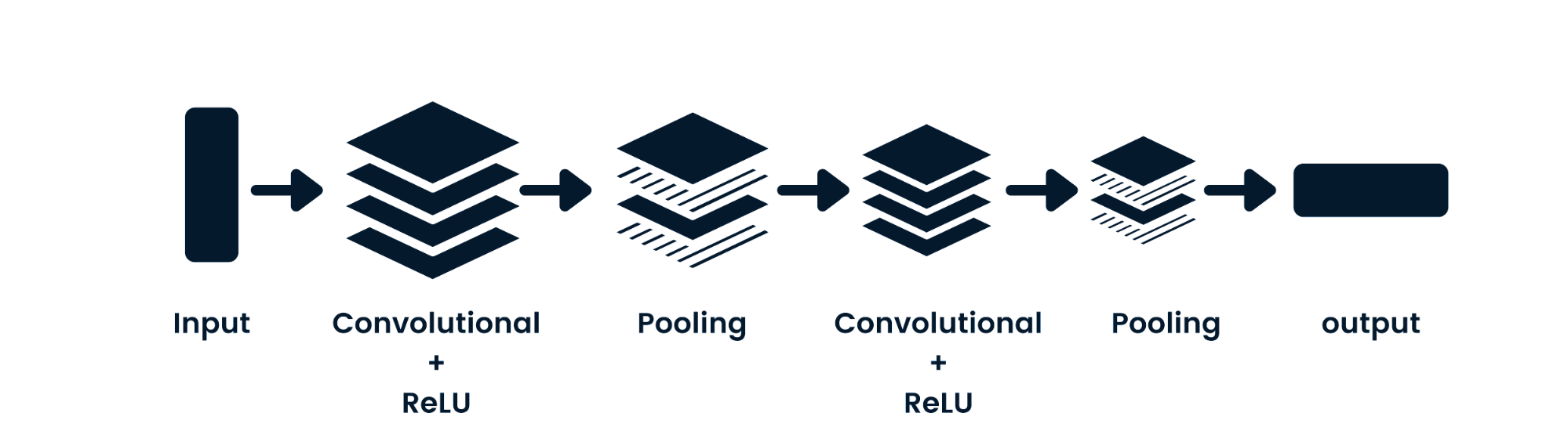
La convolutional neural network (CNN) è una rete neurale feed-forward in grado di elaborare dati spaziali. È comunemente usata per applicazioni di computer vision come la classificazione di immagini. Le semplici reti neurali sono valide per classificazioni binarie elementari, ma non riescono a gestire immagini con dipendenze tra pixel. L’architettura del modello CNN è composta da livelli di convoluzione, livelli ReLU, livelli di pooling e livelli di output completamente connessi. Puoi imparare le CNN lavorando su un progetto come Convolutional Neural Networks in Python.
I modelli RNN semplici incontrano solitamente due problemi principali. Questi problemi sono legati al gradiente, ovvero alla pendenza della funzione di loss assieme alla funzione di errore.
La soluzione semplice a questi problemi è ridurre il numero di livelli nascosti all’interno della rete neurale, riducendo così un po’ la complessità delle RNN. Questi problemi possono anche essere risolti usando architetture RNN avanzate come LSTM e GRU.
I moduli ripetuti delle RNN semplici hanno una struttura di base con un singolo livello tanh. Le RNN semplici soffrono di memoria breve: faticano a mantenere le informazioni dei passi temporali precedenti in dati sequenziali lunghi. Questi problemi possono essere risolti facilmente con le long short-term memory (LSTM) e le gated recurrent unit (GRU), poiché sono in grado di ricordare informazioni per lunghi periodi.
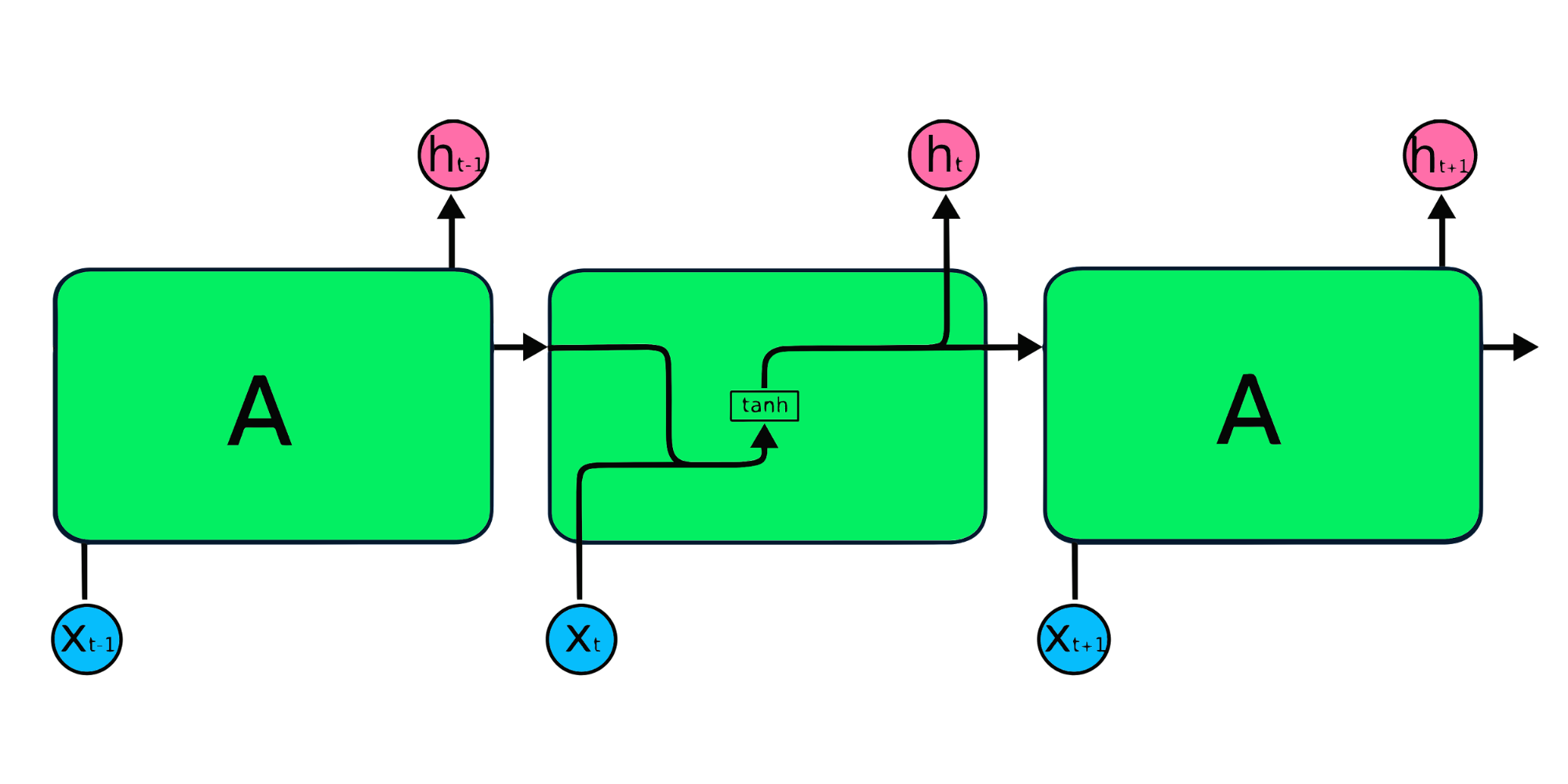
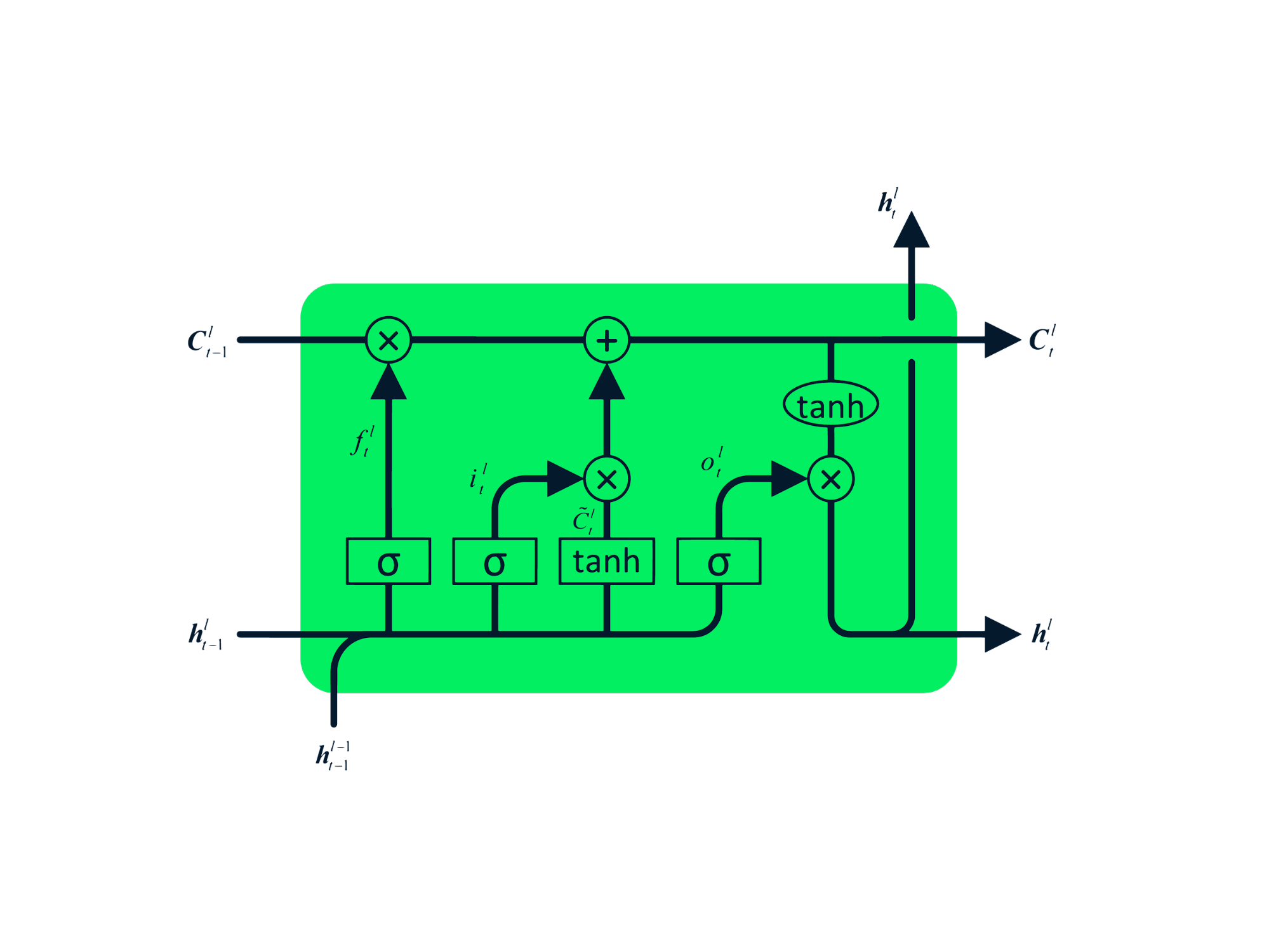
Le Long Short-Term Memory (LSTM) sono un tipo avanzato di RNN, progettato per prevenire sia il decadimento sia l’esplosione del gradiente. Come le RNN, le LSTM hanno moduli ripetuti, ma con una struttura diversa. Invece di un singolo livello tanh, le LSTM hanno quattro livelli che interagiscono e comunicano tra loro. Questa struttura a quattro livelli aiuta le LSTM a mantenere una memoria a lungo termine e può essere usata in diversi problemi sequenziali tra cui traduzione automatica, sintesi vocale, riconoscimento vocale e riconoscimento della scrittura. Puoi fare pratica con le LSTM seguendo la guida: Python LSTM for Stock Predictions.
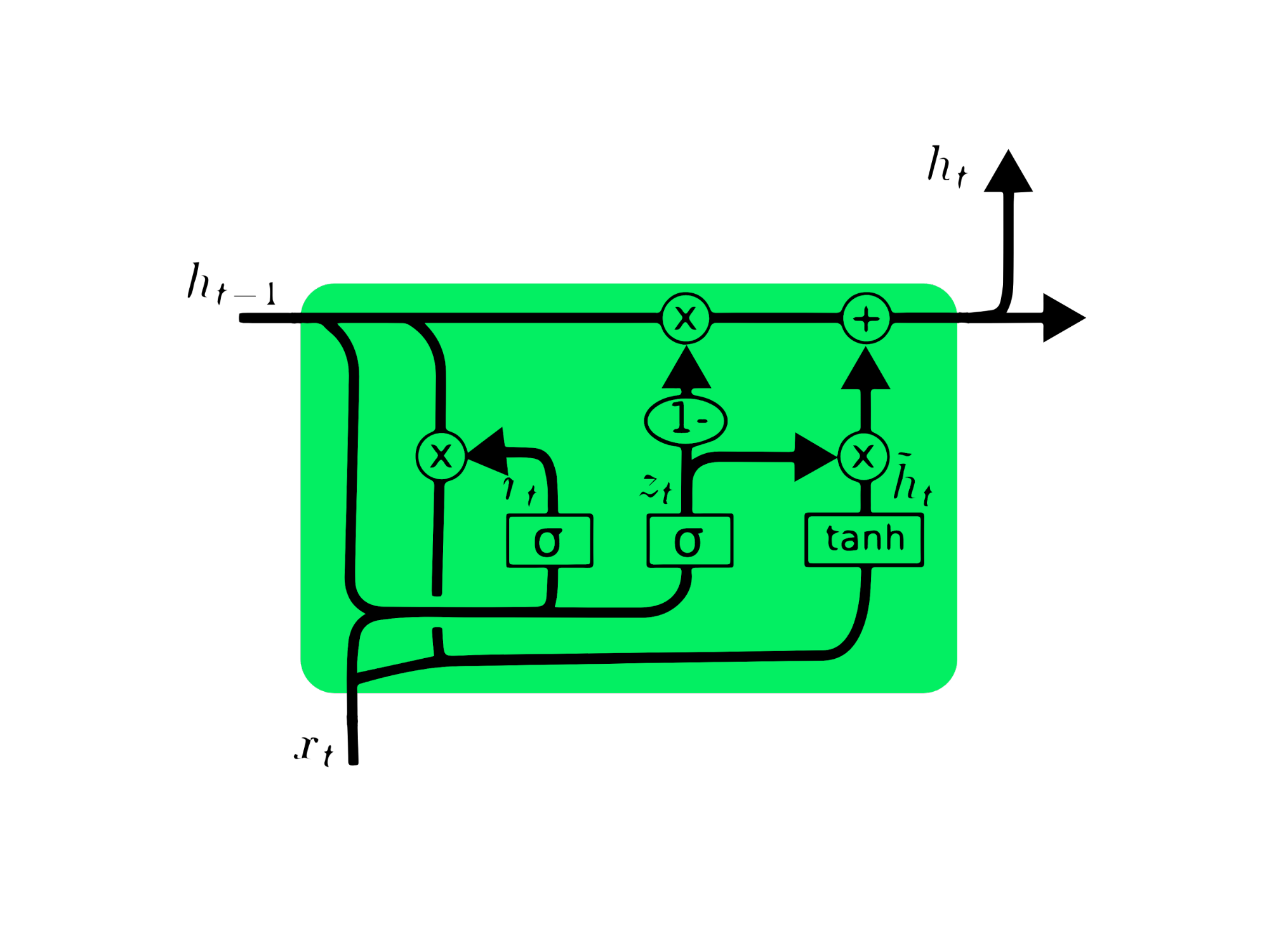
Le gated recurrent unit (GRU) sono una variante delle LSTM, poiché condividono somiglianze progettuali e, in alcuni casi, producono risultati simili. Le GRU usano un update gate e un reset gate per risolvere il problema del vanishing gradient. Questi gate decidono quali informazioni sono importanti e le passano all’output. I gate possono essere addestrati per conservare informazioni molto lontane nel tempo, senza svanire o rimuovere informazioni irrilevanti.
A differenza delle LSTM, le GRU non hanno lo stato di cella Ct. Hanno solo uno stato nascosto ht e, grazie all’architettura più semplice, hanno tempi di addestramento inferiori rispetto ai modelli LSTM. L’architettura GRU è facile da capire: prende l’input xt e lo stato nascosto del timestamp precedente ht-1 e restituisce il nuovo stato nascosto ht. Puoi approfondire le GRU in Understanding GRU Networks.
In questo progetto useremo il dataset azionario di MasterCard di Kaggle dal 25-maggio-2006 all’11-ottobre-2021 e alleneremo i modelli LSTM e GRU per prevedere il prezzo dell’azione. È un tutorial basato su progetto in cui analizzeremo i dati, li preprocesseremo per addestrare modelli RNN avanzati e infine valuteremo i risultati.
Il progetto richiede Pandas e Numpy per la manipolazione dei dati, Matplotlib.pyplot per la visualizzazione, scikit-learn per scaling e valutazione, e TensorFlow per il modeling. Imposteremo anche i seed per la riproducibilità.
# Importing the libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Dropout, GRU, Bidirectional
from tensorflow.keras.optimizers import SGD
from tensorflow.random import set_seed
set_seed(455)
np.random.seed(455)
In questa parte importeremo il dataset di MasterCard aggiungendo la colonna Date all’indice e convertendola in formato DateTime. Rimuoveremo anche le colonne irrilevanti dal dataset, perché ci interessano solo prezzi, volume e data.
Il dataset ha Date come indice e Open, High, Low, Close e Volume come colonne. Sembra che abbiamo importato correttamente un dataset pulito.
dataset = pd.read_csv(
"data/Mastercard_stock_history.csv", index_col="Date", parse_dates=["Date"]
).drop(["Dividends", "Stock Splits"], axis=1)
print(dataset.head())
Open High Low Close Volume
Date
2006-05-25 3.748967 4.283869 3.739664 4.279217 395343000
2006-05-26 4.307126 4.348058 4.103398 4.179680 103044000
2006-05-30 4.183400 4.184330 3.986184 4.093164 49898000
2006-05-31 4.125723 4.219679 4.125723 4.180608 30002000
2006-06-01 4.179678 4.474572 4.176887 4.419686 62344000
La funzione .describe() ci aiuta ad analizzare in profondità i dati. Concentriamoci sulla colonna High perché la useremo per addestrare il modello. Potremmo anche scegliere le colonne Close o Open come feature del modello, ma High ha più senso poiché ci dice quanto in alto è arrivato il valore del titolo in quel giorno.
Il prezzo minimo è $4,10 e il massimo è $400,5. La media è $105,9 e la deviazione standard $107,3, il che indica un’alta varianza del titolo.
print(dataset.describe())
Open High Low Close Volume
count 3872.000000 3872.000000 3872.000000 3872.000000 3.872000e+03
mean 104.896814 105.956054 103.769349 104.882714 1.232250e+07
std 106.245511 107.303589 105.050064 106.168693 1.759665e+07
min 3.748967 4.102467 3.739664 4.083861 6.411000e+05
25% 22.347203 22.637997 22.034458 22.300391 3.529475e+06
50% 70.810079 71.375896 70.224002 70.856083 5.891750e+06
75% 147.688448 148.645373 146.822013 147.688438 1.319775e+07
max 392.653890 400.521479 389.747812 394.685730 3.953430e+08
Usando .isna().sum() possiamo determinare i valori mancanti nel dataset. Sembra che il dataset non abbia valori mancanti.
dataset.isna().sum()
Open 0
High 0
Low 0
Close 0
Volume 0
dtype: int64
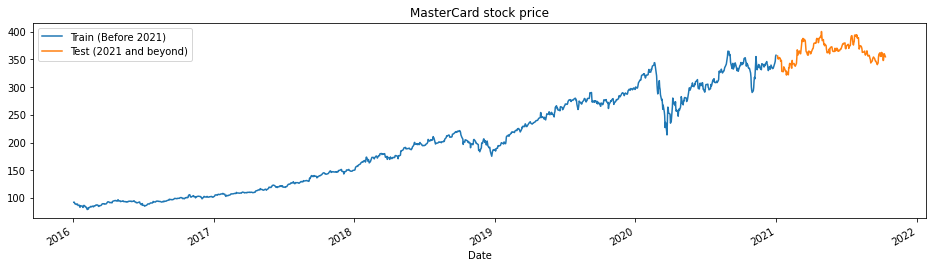
La funzione train_test_plot accetta tre argomenti: dataset, tstart e tend e traccia un semplice grafico a linee. tstart e tend sono limiti temporali in anni. Possiamo modificare questi argomenti per analizzare periodi specifici. Il grafico a linee è diviso in due parti: train e test. Questo ci aiuterà a decidere la distribuzione del dataset di test.
I prezzi delle azioni MasterCard sono in crescita dal 2016. Hanno avuto un calo nel primo trimestre del 2020, ma hanno raggiunto una posizione stabile nella seconda metà dell’anno. Il nostro dataset di test comprende un anno, dal 2021 al 2022, e il resto del dataset è usato per l’addestramento.
tstart = 2016
tend = 2020
def train_test_plot(dataset, tstart, tend):
dataset.loc[f"{tstart}":f"{tend}", "High"].plot(figsize=(16, 4), legend=True)
dataset.loc[f"{tend+1}":, "High"].plot(figsize=(16, 4), legend=True)
plt.legend([f"Train (Before {tend+1})", f"Test ({tend+1} and beyond)"])
plt.title("MasterCard stock price")
plt.show()
train_test_plot(dataset,tstart,tend)
La funzione train_test_split divide il dataset in due sottoinsiemi: training_set e test_set.
def train_test_split(dataset, tstart, tend):
train = dataset.loc[f"{tstart}":f"{tend}", "High"].values
test = dataset.loc[f"{tend+1}":, "High"].values
return train, test
training_set, test_set = train_test_split(dataset, tstart, tend)
Useremo la funzione MinMaxScaler per standardizzare il training set, così da evitare outlier o anomalie. Puoi anche provare a usare StandardScaler o altri scaler per normalizzare i dati e migliorare le prestazioni del modello.
sc = MinMaxScaler(feature_range=(0, 1))
training_set = training_set.reshape(-1, 1)
training_set_scaled = sc.fit_transform(training_set)
La funzione split_sequence usa un dataset di training e lo converte in input (X_train) e output (y_train).
Per esempio, se la sequenza è [1,2,3,4,5,6,7,8,9,10,11,12] e n_step è tre, allora convertirà la sequenza in tre timestamp di input e un output come mostrato sotto:
| X | y |
|---|---|
| 1,2,3 | 4 |
| 2,3,4 | 5 |
| 3,4,5 | 6 |
| 4,5,6 | 7 |
| … | … |
In questo progetto stiamo usando 60 n_steps. Possiamo anche ridurre o aumentare il numero di step per ottimizzare le prestazioni del modello.
def split_sequence(sequence, n_steps):
X, y = list(), list()
for i in range(len(sequence)):
end_ix = i + n_steps
if end_ix > len(sequence) - 1:
break
seq_x, seq_y = sequence[i:end_ix], sequence[end_ix]
X.append(seq_x)
y.append(seq_y)
return np.array(X), np.array(y)
n_steps = 60
features = 1
# split into samples
X_train, y_train = split_sequence(training_set_scaled, n_steps)
Stiamo lavorando con serie univariate, quindi il numero di feature è uno, e dobbiamo rimodellare X_train per adattarlo al modello LSTM. X_train ha forma [samples, timesteps] e lo rimodelleremo in [samples, timesteps, features].
# Reshaping X_train for model
X_train = X_train.reshape(X_train.shape[0],X_train.shape[1],features)
Il modello consiste in un singolo livello nascosto LSTM e in un livello di output. Puoi sperimentare con il numero di unità: più unità possono dare risultati migliori. In questo esperimento imposteremo le unità LSTM a 125, tanh come attivazione e definiremo la dimensione dell’input.
Nota dell’autore: La libreria TensorFlow è user-friendly, quindi non dobbiamo creare modelli LSTM o GRU da zero. Useremo semplicemente i moduli LSTM o GRU per costruire il modello.
Infine, compileremo il modello con un ottimizzatore RMSprop e la mean square error come funzione di loss.
# The LSTM architecture
model_lstm = Sequential()
model_lstm.add(LSTM(units=125, activation="tanh", input_shape=(n_steps, features)))
model_lstm.add(Dense(units=1))
# Compiling the model
model_lstm.compile(optimizer="RMSprop", loss="mse")
model_lstm.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm (LSTM) (None, 125) 63500
_________________________________________________________________
dense (Dense) (None, 1) 126
=================================================================
Total params: 63,626
Trainable params: 63,626
Non-trainable params: 0
_________________________________________________________________
Il modello verrà addestrato per 50 epoche con batch size di 32. Puoi modificare gli iperparametri per ridurre i tempi di training o migliorare i risultati. L’addestramento è stato completato con la migliore loss possibile.
model_lstm.fit(X_train, y_train, epochs=50, batch_size=32)
Epoch 50/50
38/38 [==============================] - 1s 30ms/step - loss: 3.1642e-04
Ripeteremo il preprocessing e normalizzeremo il set di test. Per prima cosa trasformeremo, poi suddivideremo il dataset in campioni, lo rimodelleremo, effettueremo la previsione e infine applicheremo l’inverse transform alle previsioni per riportarle in scala standard.
dataset_total = dataset.loc[:,"High"]
inputs = dataset_total[len(dataset_total) - len(test_set) - n_steps :].values
inputs = inputs.reshape(-1, 1)
#scaling
inputs = sc.transform(inputs)
# Split into samples
X_test, y_test = split_sequence(inputs, n_steps)
# reshape
X_test = X_test.reshape(X_test.shape[0], X_test.shape[1], features)
#prediction
predicted_stock_price = model_lstm.predict(X_test)
#inverse transform the values
predicted_stock_price = sc.inverse_transform(predicted_stock_price)
La funzione plot_predictions traccerà un grafico a linee reale vs previsto. Questo ci aiuterà a visualizzare la differenza tra valori effettivi e previsti.
La funzione return_rmse accetta test e predicted come argomenti e stampa la metrica root mean square error (rmse).
def plot_predictions(test, predicted):
plt.plot(test, color="gray", label="Real")
plt.plot(predicted, color="red", label="Predicted")
plt.title("MasterCard Stock Price Prediction")
plt.xlabel("Time")
plt.ylabel("MasterCard Stock Price")
plt.legend()
plt.show()
def return_rmse(test, predicted):
rmse = np.sqrt(mean_squared_error(test, predicted))
print("The root mean squared error is {:.2f}.".format(rmse))
Dal grafico sottostante, il modello LSTM a singolo livello ha performato bene.
plot_predictions(test_set,predicted_stock_price)
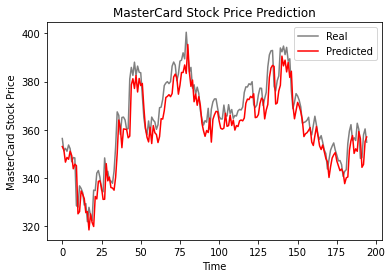
I risultati sono promettenti: il modello ha ottenuto un rmse di 6,70 sul dataset di test.
return_rmse(test_set,predicted_stock_price)
>>> The root mean squared error is 6.70.
Terremo tutto invariato e sostituiremo solamente il livello LSTM con il livello GRU per confrontare correttamente i risultati. La struttura del modello contiene un singolo livello GRU con 125 unità e un livello di output.
model_gru = Sequential()
model_gru.add(GRU(units=125, activation="tanh", input_shape=(n_steps, features)))
model_gru.add(Dense(units=1))
# Compiling the RNN
model_gru.compile(optimizer="RMSprop", loss="mse")
model_gru.summary()
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
gru_4 (GRU) (None, 125) 48000
_________________________________________________________________
dense_5 (Dense) (None, 1) 126
=================================================================
Total params: 48,126
Trainable params: 48,126
Non-trainable params: 0
_________________________________________________________________
Il modello è stato addestrato con successo per 50 epoche e batch size di 32.
model_gru.fit(X_train, y_train, epochs=50, batch_size=32)
Epoch 50/50
38/38 [==============================] - 1s 29ms/step - loss: 2.6691e-04
Come possiamo vedere, i valori reali e previsti sono relativamente vicini. Il grafico della linea prevista si adatta quasi ai valori effettivi.
GRU_predicted_stock_price = model_gru.predict(X_test)
GRU_predicted_stock_price = sc.inverse_transform(GRU_predicted_stock_price)
plot_predictions(test_set, GRU_predicted_stock_price)
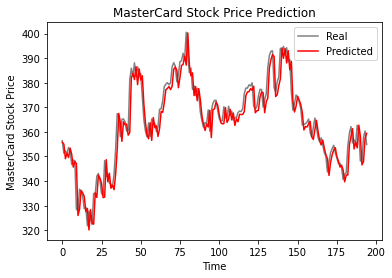
Il modello GRU ha ottenuto un rmse di 5,50 sul dataset di test, un miglioramento rispetto al modello LSTM.
return_rmse(test_set,GRU_predicted_stock_price)
>>> The root mean squared error is 5.50.
Il mondo si sta muovendo verso soluzioni ibride, in cui i data scientist usano reti ibride CNN-RNN nei campi della generazione di didascalie per immagini, rilevamento delle emozioni, sottotitolazione dei video e sequenziamento del DNA. Le reti ibride forniscono al modello caratteristiche sia visive sia temporali. Approfondisci le RNN seguendo il corso: Recurrent Neural Networks for Language Modeling in Python.
La prima metà del tutorial copre le basi delle reti neurali ricorrenti, le loro limitazioni e le soluzioni sotto forma di architetture più avanzate. La seconda metà del tutorial riguarda lo sviluppo di previsioni sul prezzo delle azioni MasterCard usando modelli LSTM e GRU. I risultati mostrano chiaramente che il modello GRU ha performato meglio dell’LSTM, con struttura e iperparametri simili.
Questo progetto è disponibile sul DataCamp workspace.
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

