Mạng Nơ-ron Hồi quy (RNN) cho Mô hình hóa Ngôn ngữ với Keras
BasicSkill Level
4 giờ
16.3K learners
Mạng nơ-ron hồi quy (RNN) là một loại mạng nơ-ron nhân tạo (ANN) được sử dụng trong Siri của Apple và tìm kiếm bằng giọng nói của Google. RNN ghi nhớ các đầu vào trong quá khứ nhờ bộ nhớ bên trong, hữu ích cho việc dự đoán giá cổ phiếu, tạo văn bản, phiên âm và dịch máy.
Trong mạng nơ-ron truyền thống, đầu vào và đầu ra độc lập với nhau, trong khi ở RNN, đầu ra phụ thuộc vào các phần tử trước đó trong chuỗi. Mạng hồi quy cũng chia sẻ tham số giữa các lớp của mạng. Trong mạng truyền thẳng, mỗi nút có trọng số khác nhau. Còn RNN chia sẻ cùng một trọng số trong mỗi lớp của mạng và trong quá trình hạ dốc gradient, các trọng số và bias được điều chỉnh riêng lẻ để giảm hàm mất mát.
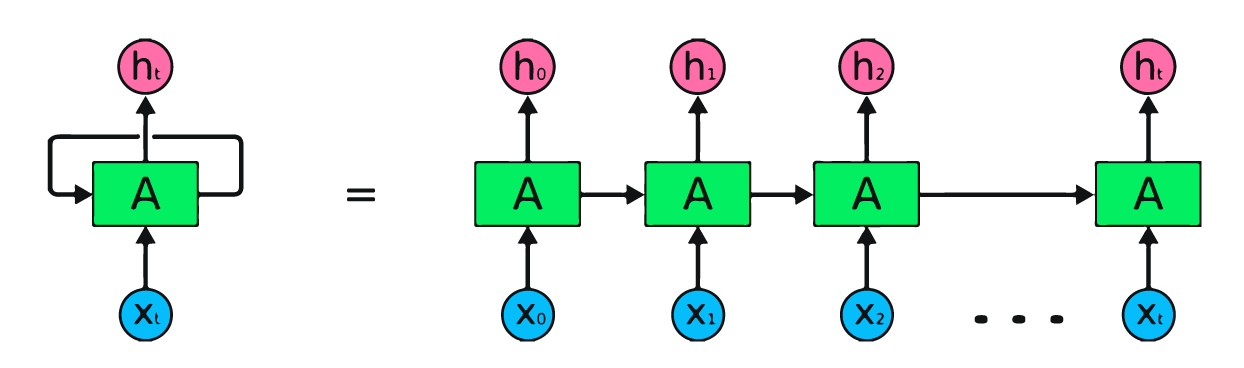
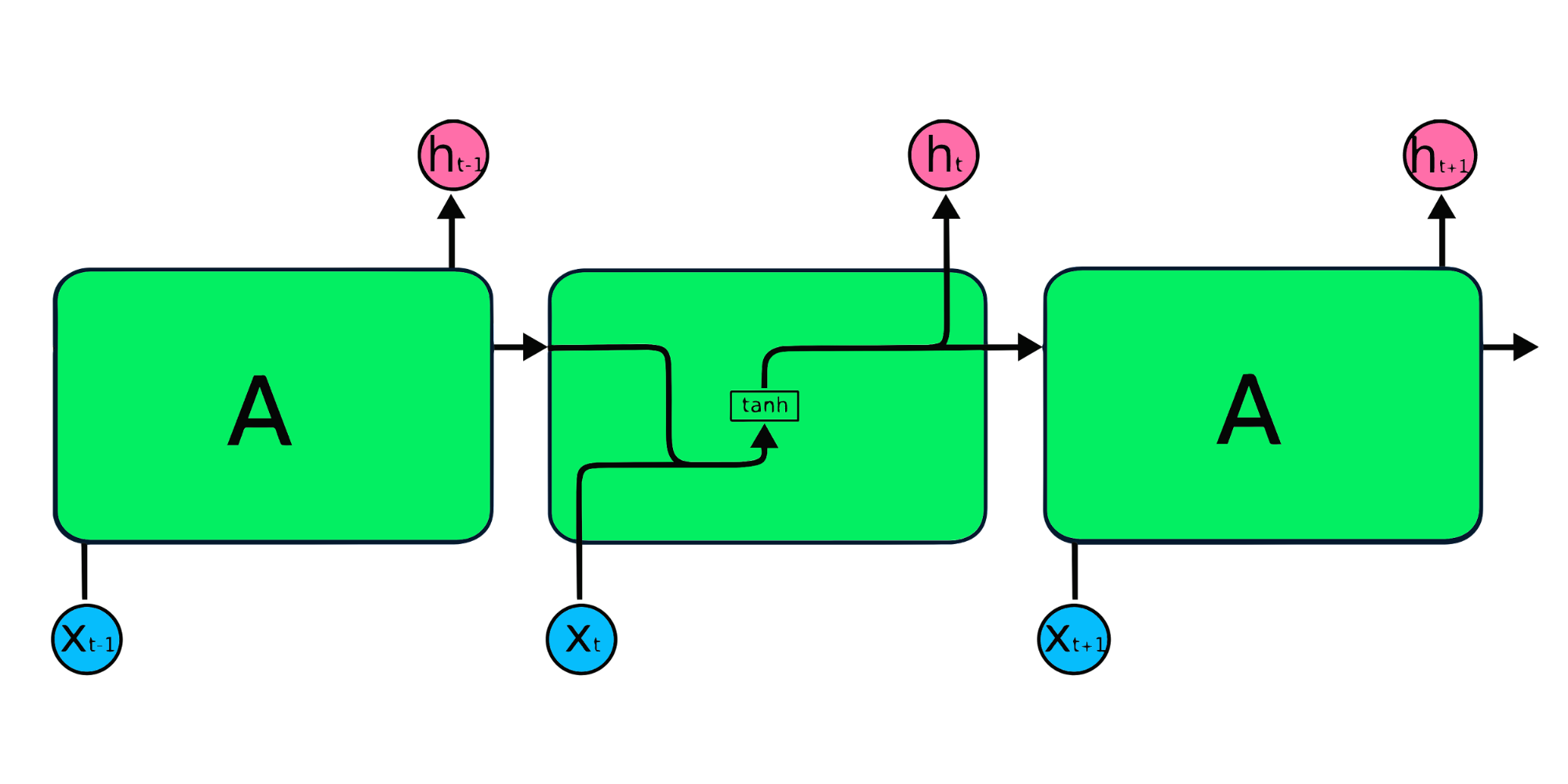
Hình trên là minh họa đơn giản của mạng nơ-ron hồi quy. Nếu chúng ta dự báo giá cổ phiếu bằng dữ liệu đơn giản [45,56,45,49,50,…], mỗi đầu vào từ X0 đến Xt sẽ chứa một giá trị trong quá khứ. Ví dụ, X0 là 45, X1 là 56, và các giá trị này được dùng để dự đoán số tiếp theo trong chuỗi.
Trong RNN, thông tin tuần hoàn qua vòng lặp, vì vậy đầu ra được quyết định bởi đầu vào hiện tại và các đầu vào đã nhận trước đó.
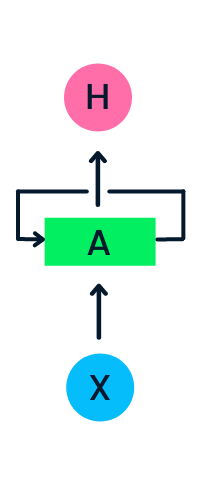
Lớp đầu vào X xử lý đầu vào ban đầu và truyền đến lớp giữa A. Lớp giữa gồm nhiều lớp ẩn, mỗi lớp có hàm kích hoạt, trọng số và bias riêng. Các tham số này được chuẩn hóa trên lớp ẩn để thay vì tạo nhiều lớp ẩn, ta tạo một lớp và lặp nó qua thời gian.
Thay vì dùng lan truyền ngược truyền thống, RNN sử dụng thuật toán lan truyền ngược theo thời gian (BPTT) để xác định gradient. Trong lan truyền ngược, mô hình điều chỉnh tham số bằng cách tính lỗi từ lớp đầu ra về lớp đầu vào. BPTT cộng dồn lỗi ở mỗi bước thời gian vì RNN chia sẻ tham số giữa các lớp. Tìm hiểu thêm về RNN và cách hoạt động tại Mạng Nơ-ron Hồi quy là gì?.
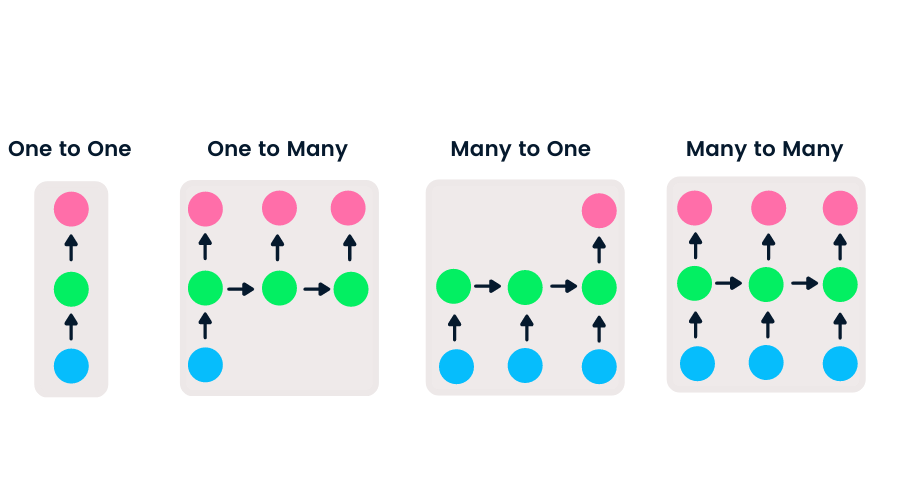
Mạng truyền thẳng có một đầu vào và một đầu ra, trong khi RNN linh hoạt vì độ dài đầu vào và đầu ra có thể thay đổi. Tính linh hoạt này cho phép RNN tạo nhạc, phân loại cảm xúc và dịch máy.
Có bốn loại RNN dựa trên độ dài đầu vào và đầu ra khác nhau.
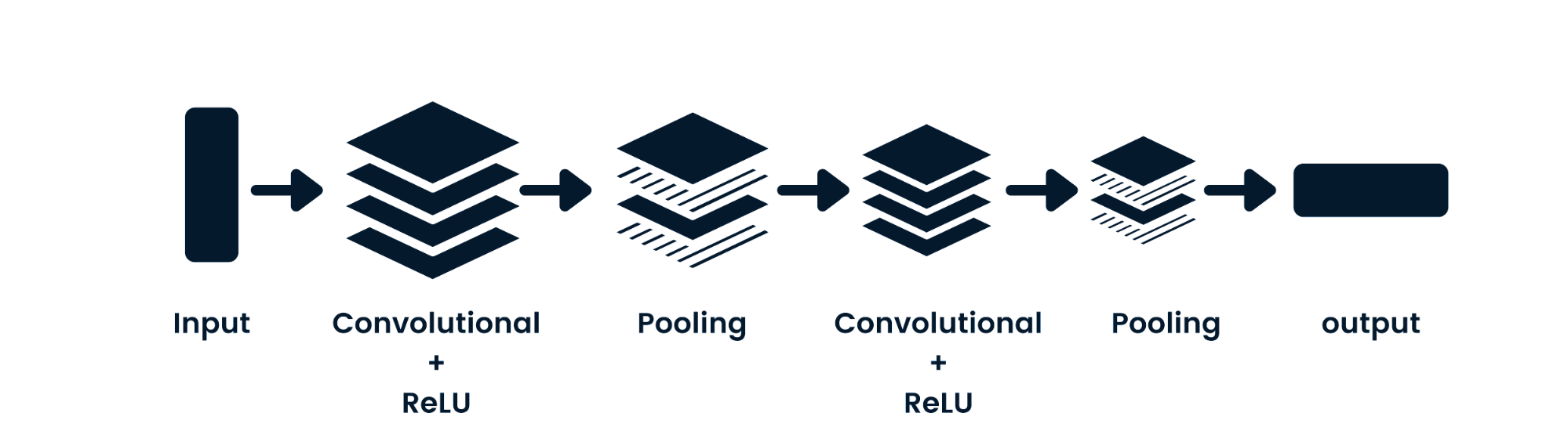
Mạng nơ-ron tích chập (CNN) là một mạng truyền thẳng có khả năng xử lý dữ liệu không gian. Nó thường được dùng cho các ứng dụng thị giác máy tính như phân loại ảnh. Các mạng nơ-ron đơn giản phù hợp cho bài toán phân loại nhị phân đơn giản, nhưng không thể xử lý ảnh với sự phụ thuộc giữa các điểm ảnh. Kiến trúc mô hình CNN gồm các lớp tích chập, lớp ReLU, lớp gộp, và các lớp đầu ra kết nối đầy đủ. Bạn có thể học CNN thông qua dự án như Mạng Nơ-ron Tích chập trong Python.
Các mô hình RNN đơn giản thường gặp hai vấn đề lớn. Những vấn đề này liên quan đến gradient, tức là độ dốc của hàm mất mát cùng với hàm lỗi.
Giải pháp đơn giản là giảm số lượng lớp ẩn trong mạng nơ-ron, từ đó giảm bớt độ phức tạp của RNN. Các vấn đề này cũng có thể giải quyết bằng các kiến trúc RNN nâng cao như LSTM và GRU.
Các mô-đun lặp lại của RNN đơn giản có cấu trúc cơ bản với một lớp tanh. Cấu trúc đơn giản này gặp hạn chế về bộ nhớ ngắn hạn, khó giữ lại thông tin ở các bước thời gian trước trong dữ liệu tuần tự dài. Những vấn đề này có thể được giải quyết dễ dàng bằng bộ nhớ ngắn-dài hạn (LSTM) và đơn vị hồi quy có cổng (GRU), vì chúng có khả năng ghi nhớ thông tin trong thời gian dài.
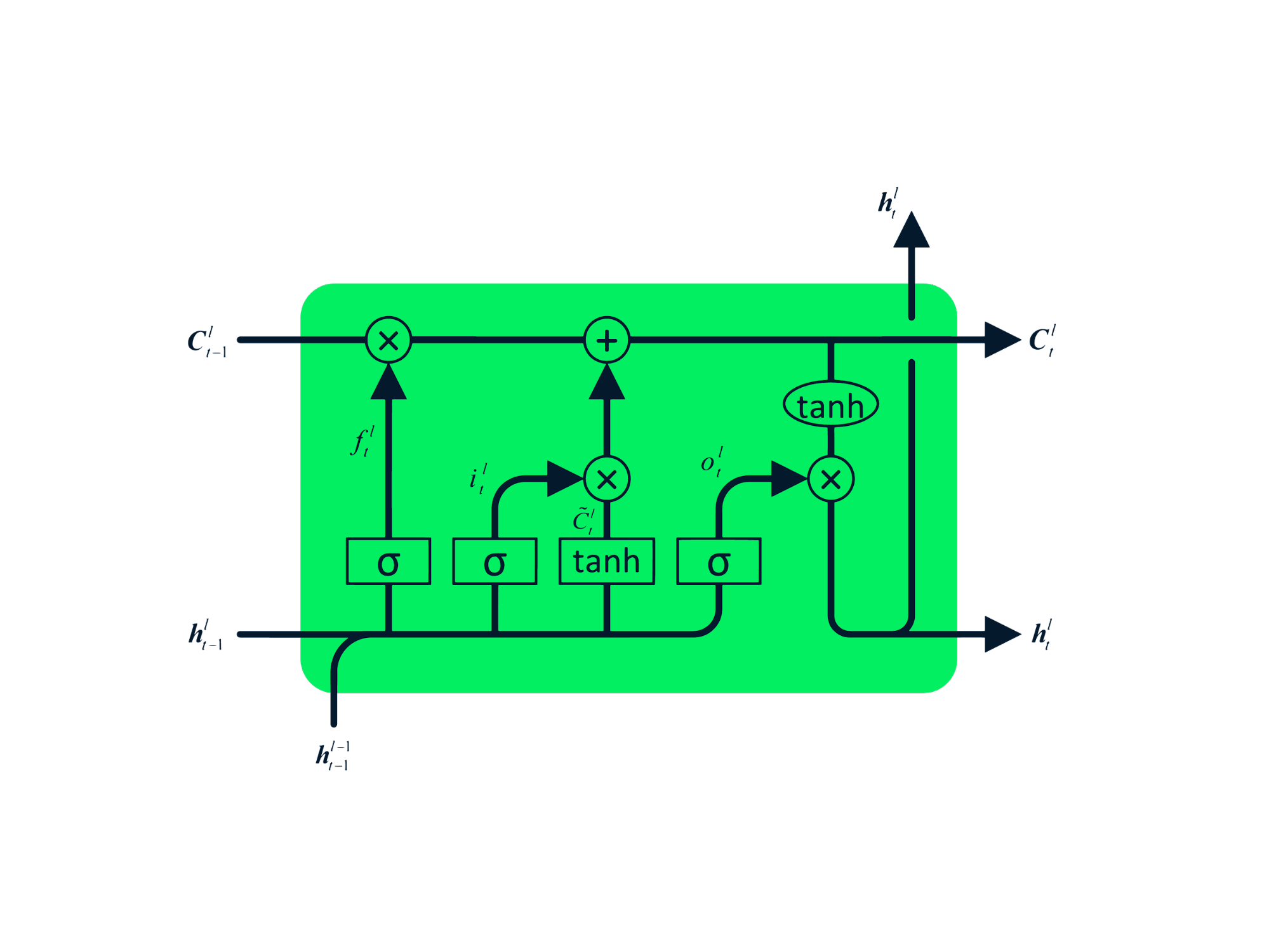
Long Short Term Memory (LSTM) là dạng nâng cao của RNN, được thiết kế để ngăn cả hiện tượng mất dần và nổ gradient. Tương tự RNN, LSTM có các mô-đun lặp lại, nhưng cấu trúc khác biệt. Thay vì một lớp tanh duy nhất, LSTM có bốn lớp tương tác với nhau. Cấu trúc bốn lớp này giúp LSTM giữ bộ nhớ dài hạn và có thể dùng trong nhiều bài toán tuần tự như dịch máy, tổng hợp giọng nói, nhận dạng giọng nói và nhận dạng chữ viết tay. Bạn có thể thực hành LSTM theo hướng dẫn: Python LSTM cho Dự đoán Cổ phiếu.
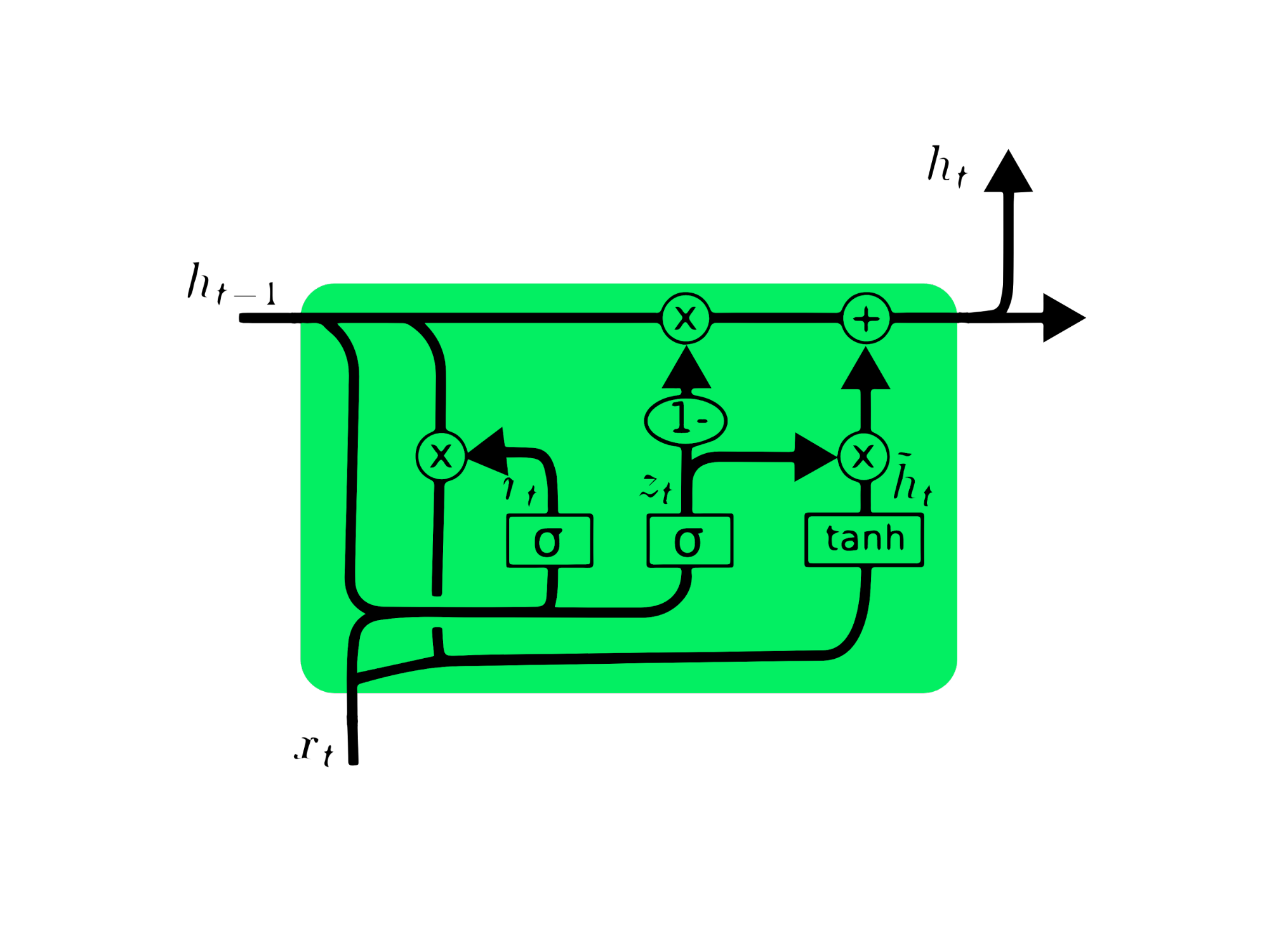
Đơn vị hồi quy có cổng (GRU) là một biến thể của LSTM vì cả hai có nhiều điểm tương đồng về thiết kế và trong một số trường hợp cho kết quả tương tự. GRU dùng cổng cập nhật và cổng đặt lại để giải quyết vấn đề mất dần gradient. Các cổng này quyết định thông tin nào quan trọng và truyền nó đến đầu ra. Chúng có thể được huấn luyện để lưu trữ thông tin từ rất lâu, không bị mất dần theo thời gian hoặc loại bỏ thông tin không liên quan.
Không giống LSTM, GRU không có trạng thái ô Ct. Nó chỉ có trạng thái ẩn ht, và nhờ kiến trúc đơn giản nên thời gian huấn luyện GRU thấp hơn so với các mô hình LSTM. Kiến trúc GRU dễ hiểu: nhận đầu vào xt và trạng thái ẩn ở mốc thời gian trước ht-1, rồi xuất ra trạng thái ẩn mới ht. Bạn có thể tìm hiểu sâu về GRU tại Understanding GRU Networks.
Trong dự án này, chúng ta sẽ sử dụng bộ dữ liệu cổ phiếu MasterCard của Kaggle từ 25-05-2006 đến 11-10-2021 và huấn luyện các mô hình LSTM và GRU để dự báo giá cổ phiếu. Đây là hướng dẫn dựa trên dự án, nơi chúng ta sẽ phân tích dữ liệu, tiền xử lý để huấn luyện trên các mô hình RNN nâng cao, và cuối cùng đánh giá kết quả.
Dự án yêu cầu Pandas và Numpy để xử lý dữ liệu, Matplotlib.pyplot để trực quan hóa, scikit-learn để chuẩn hóa và đánh giá, và TensorFlow để xây dựng mô hình. Chúng ta cũng sẽ đặt seed để tái lập kết quả.
# Importing the libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Dropout, GRU, Bidirectional
from tensorflow.keras.optimizers import SGD
from tensorflow.random import set_seed
set_seed(455)
np.random.seed(455)
Trong phần này, chúng ta sẽ nhập bộ dữ liệu MasterCard bằng cách đưa cột Date vào chỉ mục và chuyển đổi sang định dạng DateTime. Chúng ta cũng loại bỏ các cột không liên quan vì chỉ quan tâm đến giá cổ phiếu, khối lượng và ngày.
Bộ dữ liệu có Date làm chỉ mục và các cột Open, High, Low, Close và Volume. Có vẻ chúng ta đã nhập thành công một bộ dữ liệu sạch.
dataset = pd.read_csv(
"data/Mastercard_stock_history.csv", index_col="Date", parse_dates=["Date"]
).drop(["Dividends", "Stock Splits"], axis=1)
print(dataset.head())
Open High Low Close Volume
Date
2006-05-25 3.748967 4.283869 3.739664 4.279217 395343000
2006-05-26 4.307126 4.348058 4.103398 4.179680 103044000
2006-05-30 4.183400 4.184330 3.986184 4.093164 49898000
2006-05-31 4.125723 4.219679 4.125723 4.180608 30002000
2006-06-01 4.179678 4.474572 4.176887 4.419686 62344000
Hàm .describe() giúp chúng ta phân tích dữ liệu sâu hơn. Hãy tập trung vào cột High vì chúng ta sẽ dùng nó để huấn luyện mô hình. Ta cũng có thể chọn các cột Close hoặc Open làm đặc trưng mô hình, nhưng High hợp lý hơn vì cung cấp thông tin mức giá cao nhất trong ngày.
Giá cổ phiếu thấp nhất là $4,10 và cao nhất là $400,5. Giá trị trung bình là $105,9 và độ lệch chuẩn $107,3, cho thấy cổ phiếu có phương sai cao.
print(dataset.describe())
Open High Low Close Volume
count 3872.000000 3872.000000 3872.000000 3872.000000 3.872000e+03
mean 104.896814 105.956054 103.769349 104.882714 1.232250e+07
std 106.245511 107.303589 105.050064 106.168693 1.759665e+07
min 3.748967 4.102467 3.739664 4.083861 6.411000e+05
25% 22.347203 22.637997 22.034458 22.300391 3.529475e+06
50% 70.810079 71.375896 70.224002 70.856083 5.891750e+06
75% 147.688448 148.645373 146.822013 147.688438 1.319775e+07
max 392.653890 400.521479 389.747812 394.685730 3.953430e+08
Bằng cách dùng .isna().sum() chúng ta có thể xác định giá trị thiếu trong bộ dữ liệu. Có vẻ bộ dữ liệu không có giá trị thiếu.
dataset.isna().sum()
Open 0
High 0
Low 0
Close 0
Volume 0
dtype: int64
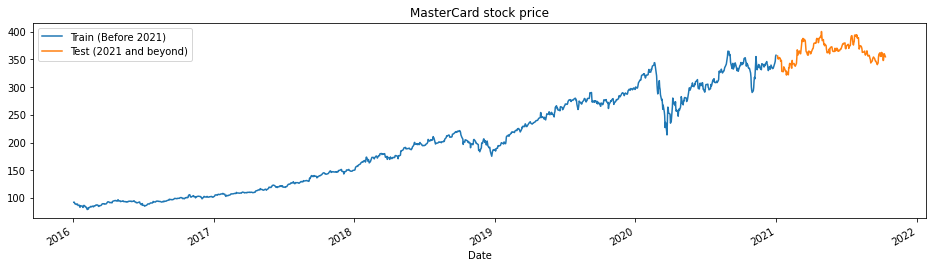
Hàm train_test_plot nhận ba đối số: dataset, tstart và tend và vẽ biểu đồ đường đơn giản. tstart và tend là giới hạn thời gian theo năm. Chúng ta có thể thay đổi các đối số này để phân tích giai đoạn cụ thể. Biểu đồ đường được chia làm hai phần: train và test. Điều này giúp quyết định cách phân bổ dữ liệu kiểm tra.
Giá cổ phiếu MasterCard tăng đều từ năm 2016. Có một đợt giảm trong quý I năm 2020 nhưng đã ổn định ở nửa cuối năm. Tập kiểm tra của chúng ta gồm một năm, từ 2021 đến 2022, và phần còn lại dùng để huấn luyện.
tstart = 2016
tend = 2020
def train_test_plot(dataset, tstart, tend):
dataset.loc[f"{tstart}":f"{tend}", "High"].plot(figsize=(16, 4), legend=True)
dataset.loc[f"{tend+1}":, "High"].plot(figsize=(16, 4), legend=True)
plt.legend([f"Train (Before {tend+1})", f"Test ({tend+1} and beyond)"])
plt.title("MasterCard stock price")
plt.show()
train_test_plot(dataset,tstart,tend)
Hàm train_test_split chia bộ dữ liệu thành hai tập con: training_set và test_set.
def train_test_split(dataset, tstart, tend):
train = dataset.loc[f"{tstart}":f"{tend}", "High"].values
test = dataset.loc[f"{tend+1}":, "High"].values
return train, test
training_set, test_set = train_test_split(dataset, tstart, tend)
Chúng ta sẽ dùng hàm MinMaxScaler để chuẩn hóa tập huấn luyện, giúp tránh ngoại lệ hay bất thường. Bạn cũng có thể thử StandardScaler hoặc các hàm chuẩn hóa khác để cải thiện hiệu năng mô hình.
sc = MinMaxScaler(feature_range=(0, 1))
training_set = training_set.reshape(-1, 1)
training_set_scaled = sc.fit_transform(training_set)
Hàm split_sequence sử dụng tập huấn luyện và chuyển đổi thành đầu vào (X_train) và đầu ra (y_train).
Ví dụ, nếu chuỗi là [1,2,3,4,5,6,7,8,9,10,11,12] và n_step là ba, thì chuỗi sẽ được chuyển thành ba mốc thời gian đầu vào và một đầu ra như dưới đây:
| X | y |
|---|---|
| 1,2,3 | 4 |
| 2,3,4 | 5 |
| 3,4,5 | 6 |
| 4,5,6 | 7 |
| … | … |
Trong dự án này, chúng ta dùng 60 n_steps. Ta cũng có thể giảm hoặc tăng số bước để tối ưu hiệu năng mô hình.
def split_sequence(sequence, n_steps):
X, y = list(), list()
for i in range(len(sequence)):
end_ix = i + n_steps
if end_ix > len(sequence) - 1:
break
seq_x, seq_y = sequence[i:end_ix], sequence[end_ix]
X.append(seq_x)
y.append(seq_y)
return np.array(X), np.array(y)
n_steps = 60
features = 1
# split into samples
X_train, y_train = split_sequence(training_set_scaled, n_steps)
Chúng ta đang làm việc với chuỗi đơn biến, nên số đặc trưng là một, và cần reshape X_train để phù hợp với mô hình LSTM. X_train hiện có dạng [mẫu, bước thời gian], và chúng ta sẽ reshape thành [mẫu, bước thời gian, đặc trưng].
# Reshaping X_train for model
X_train = X_train.reshape(X_train.shape[0],X_train.shape[1],features)
Mô hình gồm một lớp ẩn LSTM và một lớp đầu ra. Bạn có thể thử nghiệm số lượng đơn vị, vì càng nhiều đơn vị có thể cho kết quả tốt hơn. Trong thử nghiệm này, chúng ta đặt số đơn vị LSTM là 125, dùng tanh làm hàm kích hoạt và thiết lập kích thước đầu vào.
Lưu ý của tác giả: Thư viện TensorFlow thân thiện với người dùng, nên chúng ta không cần xây dựng LSTM hay GRU từ đầu. Chỉ cần dùng các mô-đun LSTM hoặc GRU để tạo mô hình.
Cuối cùng, chúng ta biên dịch mô hình với bộ tối ưu RMSprop và dùng sai số bình phương trung bình làm hàm mất mát.
# The LSTM architecture
model_lstm = Sequential()
model_lstm.add(LSTM(units=125, activation="tanh", input_shape=(n_steps, features)))
model_lstm.add(Dense(units=1))
# Compiling the model
model_lstm.compile(optimizer="RMSprop", loss="mse")
model_lstm.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm (LSTM) (None, 125) 63500
_________________________________________________________________
dense (Dense) (None, 1) 126
=================================================================
Total params: 63,626
Trainable params: 63,626
Non-trainable params: 0
_________________________________________________________________
Mô hình sẽ huấn luyện 50 epoch với kích thước batch là 32. Bạn có thể thay đổi siêu tham số để rút ngắn thời gian huấn luyện hoặc cải thiện kết quả. Việc huấn luyện đã hoàn tất thành công với mức mất mát tốt.
model_lstm.fit(X_train, y_train, epochs=50, batch_size=32)
Epoch 50/50
38/38 [==============================] - 1s 30ms/step - loss: 3.1642e-04
Chúng ta sẽ lặp lại tiền xử lý và chuẩn hóa tập kiểm tra. Trước hết, chúng ta sẽ biến đổi rồi chia bộ dữ liệu thành các mẫu, reshape, dự đoán và đảo chuẩn hóa các dự đoán về dạng chuẩn.
dataset_total = dataset.loc[:,"High"]
inputs = dataset_total[len(dataset_total) - len(test_set) - n_steps :].values
inputs = inputs.reshape(-1, 1)
#scaling
inputs = sc.transform(inputs)
# Split into samples
X_test, y_test = split_sequence(inputs, n_steps)
# reshape
X_test = X_test.reshape(X_test.shape[0], X_test.shape[1], features)
#prediction
predicted_stock_price = model_lstm.predict(X_test)
#inverse transform the values
predicted_stock_price = sc.inverse_transform(predicted_stock_price)
Hàm plot_predictions sẽ vẽ biểu đồ đường giữa giá trị thực và dự đoán. Điều này giúp trực quan hóa sự khác biệt giữa giá trị thực tế và dự đoán.
Hàm return_rmse nhận vào hai đối số test và predicted và in ra chỉ số căn sai số bình phương trung bình (rmse).
def plot_predictions(test, predicted):
plt.plot(test, color="gray", label="Real")
plt.plot(predicted, color="red", label="Predicted")
plt.title("MasterCard Stock Price Prediction")
plt.xlabel("Time")
plt.ylabel("MasterCard Stock Price")
plt.legend()
plt.show()
def return_rmse(test, predicted):
rmse = np.sqrt(mean_squared_error(test, predicted))
print("The root mean squared error is {:.2f}.".format(rmse))
Theo biểu đồ đường dưới đây, mô hình LSTM một lớp hoạt động tốt.
plot_predictions(test_set,predicted_stock_price)
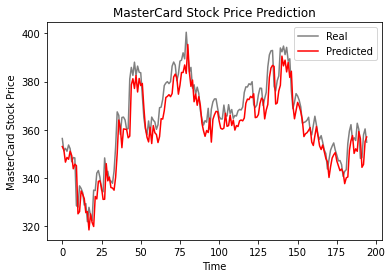
Kết quả có triển vọng khi mô hình đạt rmse 6,70 trên tập kiểm tra.
return_rmse(test_set,predicted_stock_price)
>>> The root mean squared error is 6.70.
Chúng ta sẽ giữ nguyên mọi thứ và chỉ thay lớp LSTM bằng lớp GRU để so sánh kết quả một cách đúng đắn. Cấu trúc mô hình gồm một lớp GRU với 125 đơn vị và một lớp đầu ra.
model_gru = Sequential()
model_gru.add(GRU(units=125, activation="tanh", input_shape=(n_steps, features)))
model_gru.add(Dense(units=1))
# Compiling the RNN
model_gru.compile(optimizer="RMSprop", loss="mse")
model_gru.summary()
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
gru_4 (GRU) (None, 125) 48000
_________________________________________________________________
dense_5 (Dense) (None, 1) 126
=================================================================
Total params: 48,126
Trainable params: 48,126
Non-trainable params: 0
_________________________________________________________________
Mô hình đã được huấn luyện thành công với 50 epoch và kích thước batch 32.
model_gru.fit(X_train, y_train, epochs=50, batch_size=32)
Epoch 50/50
38/38 [==============================] - 1s 29ms/step - loss: 2.6691e-04
Như ta thấy, các giá trị thực và dự đoán khá sát nhau. Đường dự đoán gần như khớp với giá trị thực tế.
GRU_predicted_stock_price = model_gru.predict(X_test)
GRU_predicted_stock_price = sc.inverse_transform(GRU_predicted_stock_price)
plot_predictions(test_set, GRU_predicted_stock_price)
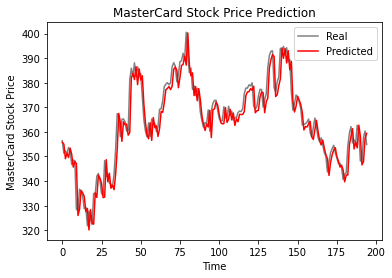
Mô hình GRU đạt rmse 5,50 trên tập kiểm tra, cải thiện so với mô hình LSTM.
return_rmse(test_set,GRU_predicted_stock_price)
>>> The root mean squared error is 5.50.
Thế giới đang hướng tới các giải pháp lai, nơi các nhà khoa học dữ liệu sử dụng mạng lai CNN-RNN trong lĩnh vực tạo chú thích ảnh, phát hiện cảm xúc, tạo phụ đề video và giải trình tự DNA. Mạng lai cung cấp cả đặc trưng thị giác và đặc trưng thời gian cho mô hình. Tìm hiểu thêm về RNN bằng cách tham gia khóa học: Recurrent Neural Networks for Language Modeling in Python.
Nửa đầu hướng dẫn trình bày những kiến thức cơ bản về RNN, các hạn chế và giải pháp dưới dạng kiến trúc nâng cao hơn. Nửa sau trình bày việc phát triển mô hình dự đoán giá cổ phiếu MasterCard bằng LSTM và GRU. Kết quả cho thấy mô hình GRU hoạt động tốt hơn LSTM với cấu trúc và siêu tham số tương tự.
Dự án này có sẵn trên không gian làm việc DataCamp.