Recurrent Neural Networks (RNNs) for Language Modeling with Keras
BasicSkill Level
4 sa
16.3K learners
Yinelenen sinir ağı (RNN), Apple’ın Siri’sinde ve Google’ın sesli aramasında kullanılan yapay sinir ağı (ANN) türüdür. RNN, sahip olduğu dahili bellek sayesinde geçmiş girdileri hatırlar; bu da hisse senedi fiyatı tahmini, metin üretimi, transkripsiyon ve makine çevirisi için kullanışlıdır.
Geleneksel sinir ağında girdiler ve çıktılar birbirinden bağımsızdır; oysa RNN’de çıktı, dizilim içindeki önceki öğelere bağlıdır. Yinelenen ağlar ayrıca ağın her katmanında parametreleri paylaşır. İleri beslemeli ağlarda her düğümde farklı ağırlıklar bulunur. RNN’de ise ağın her katmanında aynı ağırlıklar paylaşılır ve gradyan inişi sırasında ağırlıklar ve önyargılar (bias) kaybı azaltmak için ayrı ayrı ayarlanır.
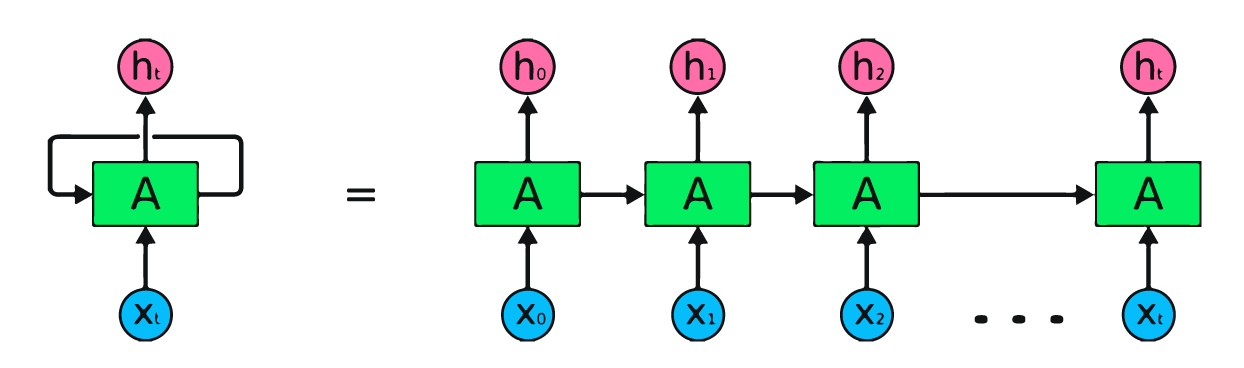
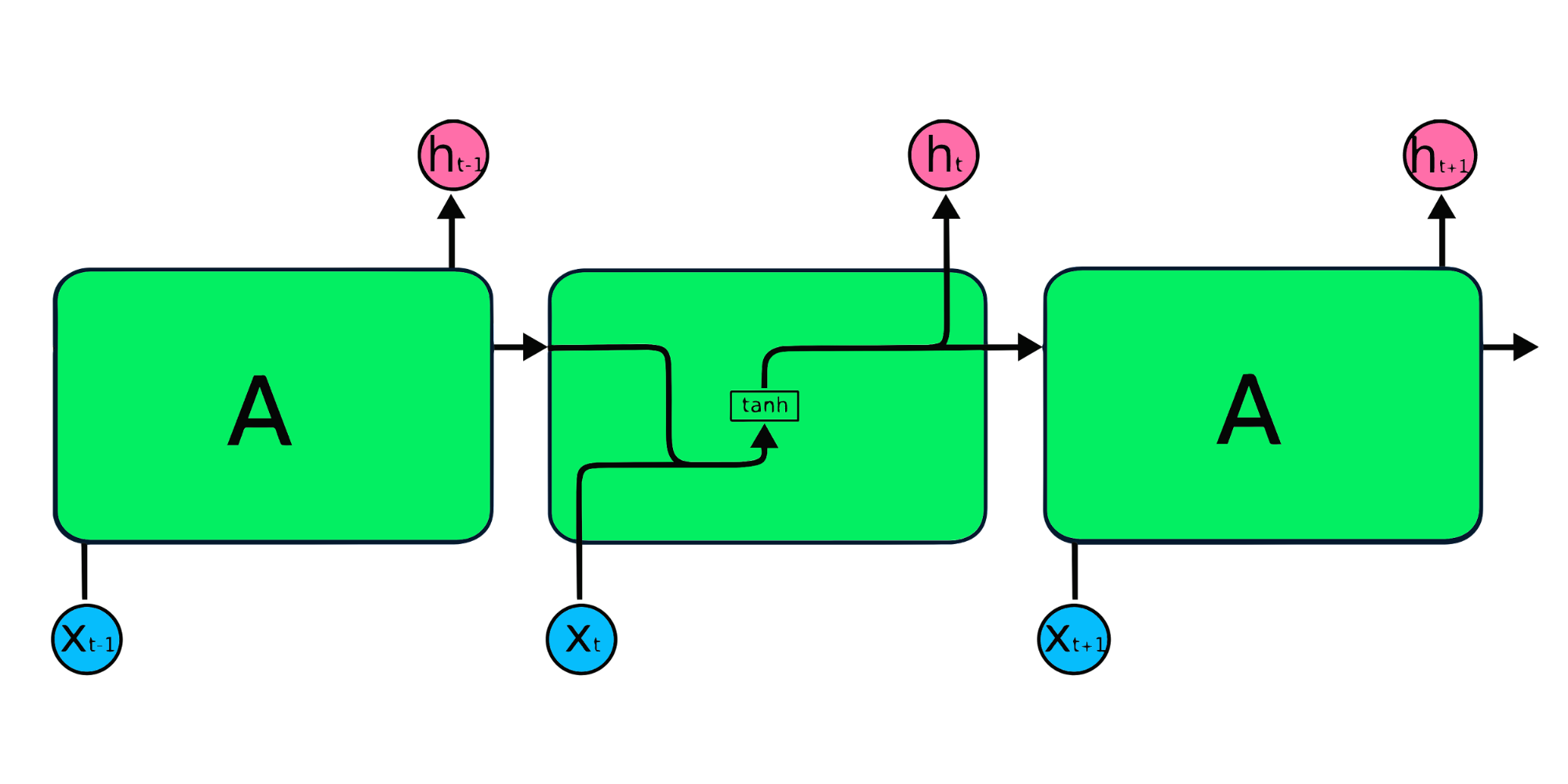
Yukarıdaki görsel yinelenen sinir ağlarının basit bir gösterimidir. Basit verilerle [45,56,45,49,50,…] hisse fiyatı tahmini yapıyorsak, X0’dan Xt’ye kadar her girdi geçmiş bir değeri içerir. Örneğin, X0 45’i, X1 56’yı alır ve bu değerler dizideki bir sonraki sayıyı tahmin etmek için kullanılır.
RNN’de bilgi döngü içinde dolaşır; bu nedenle çıktı, mevcut girdi ve daha önce alınan girdiler tarafından belirlenir.
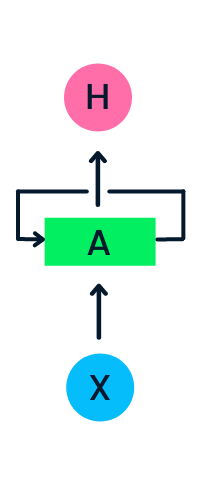
X giriş katmanı başlangıç girdisini işler ve orta katman A’ya iletir. Orta katman, her biri kendi aktivasyon fonksiyonları, ağırlıkları ve önyargıları (bias) olan birden çok gizli katmandan oluşur. Bu parametreler gizli katman genelinde standartlaştırılır; böylece çok sayıda gizli katman oluşturmak yerine tek bir katman oluşturulur ve üzerine döngü kurulur.
Geleneksel geri yayılım yerine, yinelenen sinir ağları gradyanı belirlemek için zamanda geri yayılım (BPTT) algoritmalarını kullanır. Geri yayılımda model, hatayı çıktıdan giriş katmanına hesaplayarak parametreyi ayarlar. RNN her katmanda parametreleri paylaştığı için BPTT her zaman adımındaki hatayı toplar. RNN’ler ve çalışma biçimleri hakkında daha fazla bilgi için bkz. Yinelenen Sinir Ağları nedir?.
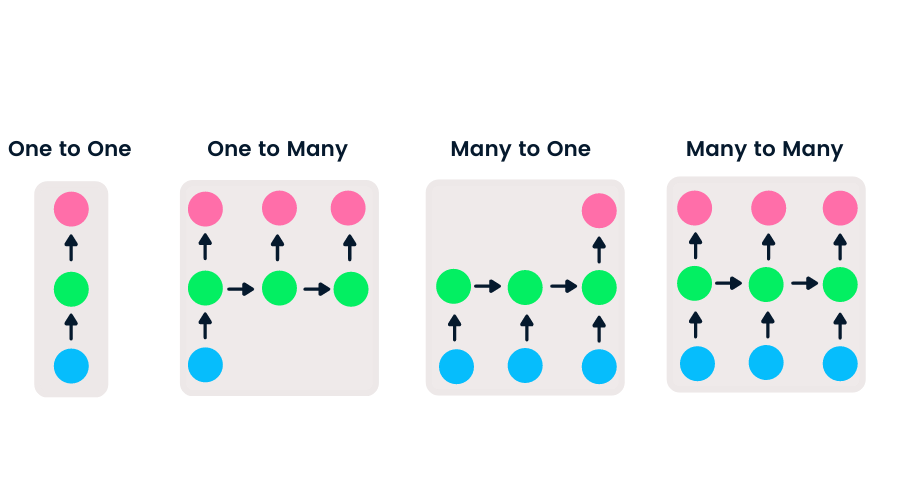
İleri beslemeli ağlarda tek giriş ve tek çıkış bulunurken, yinelenen sinir ağları esnektir; giriş ve çıkışların uzunluğu değiştirilebilir. Bu esneklik RNN’lerin müzik üretimi, duygu sınıflandırma ve makine çevirisi yapabilmesini sağlar.
Girdi ve çıktı uzunluklarına göre dört tür RNN vardır.
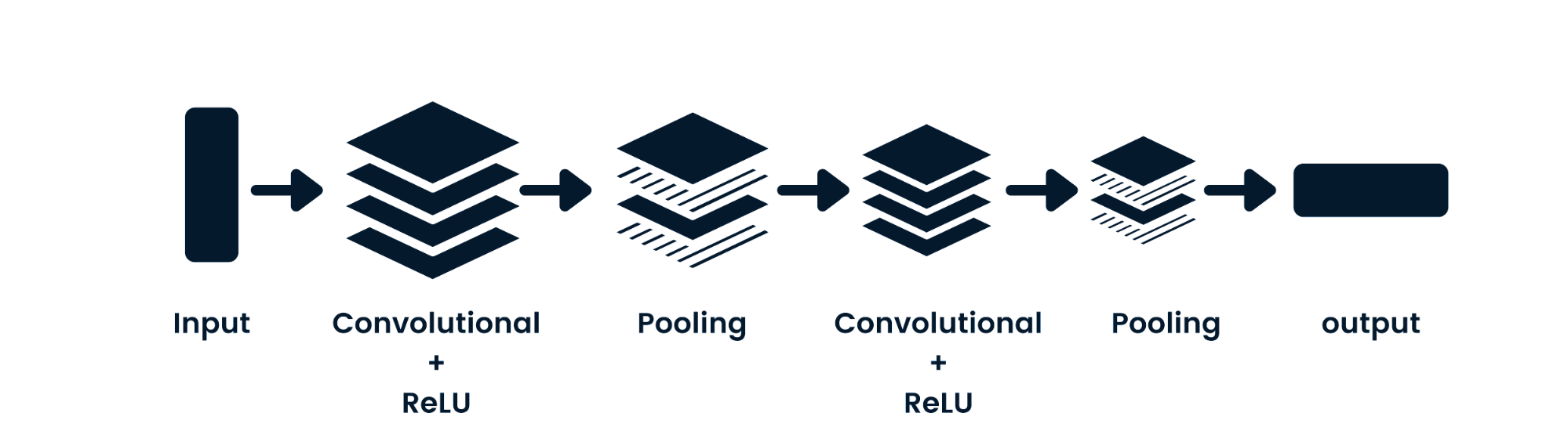
Evrişimli sinir ağı (CNN), uzamsal veriyi işleyebilen ileri beslemeli bir sinir ağıdır. Görüntü sınıflandırma gibi bilgisayarlı görü uygulamalarında yaygın olarak kullanılır. Basit sinir ağları temel ikili sınıflandırmalarda iyidir ancak piksel bağımlılıkları olan görüntüleri işleyemez. CNN model mimarisi evrişim katmanları, ReLU katmanları, havuzlama katmanları ve tam bağlı çıktı katmanlarından oluşur. Bir proje üzerinde çalışarak CNN öğrenebilirsiniz: Python’da Evrişimli Sinir Ağları.
Basit RNN modelleri genellikle iki temel sorunla karşılaşır. Bu sorunlar, hata fonksiyonu ile birlikte kayıp fonksiyonunun eğimi olan gradyanla ilgilidir.
Bu sorunlara basit bir çözüm, sinir ağındaki gizli katman sayısını azaltmaktır; bu da RNN’lerdeki bir miktar karmaşıklığı düşürür. Sorunlar ayrıca LSTM ve GRU gibi gelişmiş RNN mimarileri kullanılarak da çözülebilir.
Basit RNN tekrarlayan modülleri tek bir tanh katmanına sahip temel bir yapıdır. Basit RNN yapısı kısa bellek sorunu yaşar; daha büyük sıralı verilerde önceki zaman adımlarındaki bilgiyi tutmakta zorlanır. Bu sorunlar, uzun-kısa süreli bellek (LSTM) ve kapılı yinelenen birim (GRU) ile kolayca çözülebilir; çünkü bu yapılar uzun dönemli bilgileri hatırlayabilir.
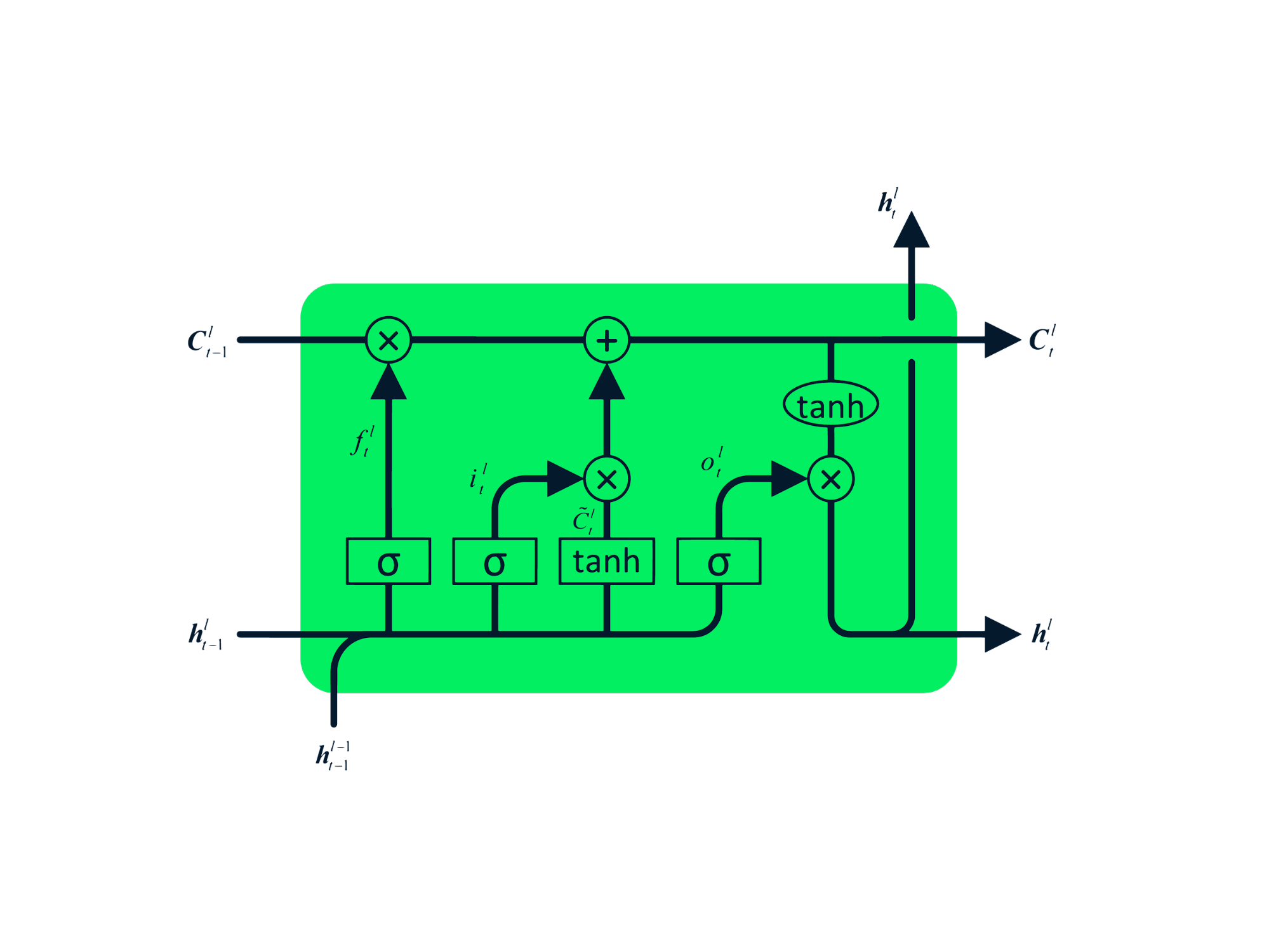
Long Short Term Memory (LSTM), hem zayıflayan hem de patlayan gradyan sorunlarını önlemek için tasarlanmış gelişmiş bir RNN türüdür. RNN gibi LSTM de tekrarlayan modüllere sahiptir, ancak yapısı farklıdır. Tek bir tanh katmanı yerine, LSTM birbirleriyle iletişim kuran dört etkileşimli katmana sahiptir. Bu dört katmanlı yapı LSTM’nin uzun süreli belleği korumasına yardımcı olur ve makine çevirisi, konuşma sentezi, konuşma tanıma ve el yazısı tanıma gibi çeşitli sıralı problemlerde kullanılabilir. LSTM’de uygulamalı deneyim kazanmak için şu rehberi izleyebilirsiniz: Hisse Senedi Tahminleri için Python LSTM.
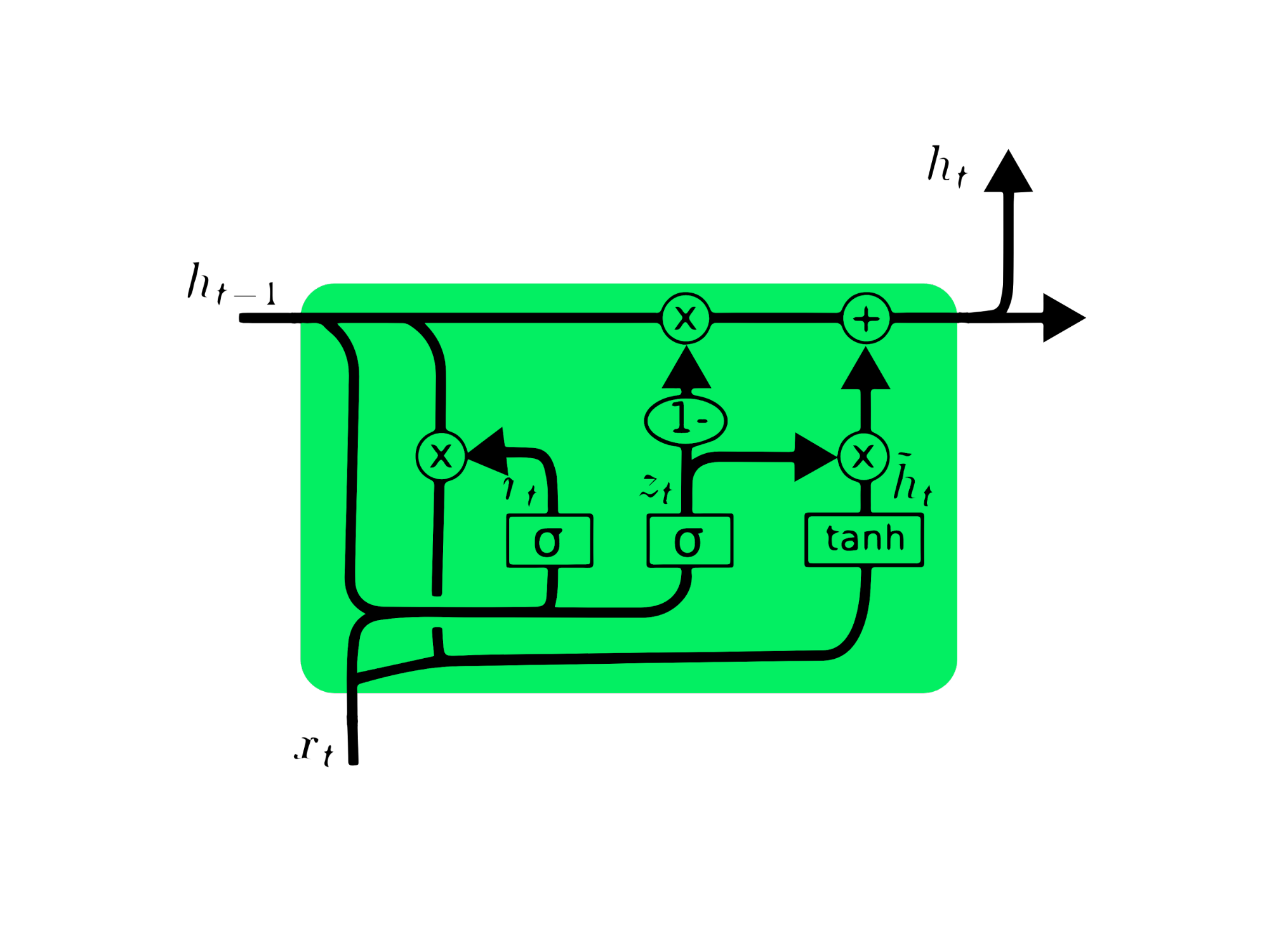
Kapılı yinelenen birim (GRU), tasarım benzerlikleri nedeniyle LSTM’in bir varyasyonudur ve bazı durumlarda benzer sonuçlar üretir. GRU, kaybolan gradyan sorununu çözmek için güncelleme kapısı ve sıfırlama kapısı kullanır. Bu kapılar hangi bilginin önemli olduğuna karar verip çıktıya aktarır. Kapılar, çok eski bilgileri zamanla kaybolmadan saklayacak ya da ilgisiz bilgileri eleyebilecek şekilde eğitilebilir.
LSTM’den farklı olarak GRU’da hücre durumu Ct yoktur. Yalnızca gizli durum ht bulunur ve daha basit mimarisi sayesinde GRU’nun eğitim süresi LSTM modellerine göre daha kısadır. GRU mimarisi anlaşılması kolaydır: girdi olarak xt ve bir önceki zaman damgasının gizli durumunu ht-1 alır ve yeni gizli durumu ht çıktılar. GRU hakkında ayrıntılı bilgi için bkz. GRU Ağlarını Anlamak.
Bu projede, 25-Mayıs-2006 ile 11-Eki-2021 arasındaki Kaggle’ın MasterCard hisse veri setini kullanarak LSTM ve GRU modellerini eğitip hisse fiyatını öngöreceğiz. Bu, veriyi analiz edeceğimiz, gelişmiş RNN modellerinde eğitmek için ön işlemeden geçireceğimiz ve sonunda sonuçları değerlendireceğimiz proje tabanlı basit bir eğitimdir.
Projede veri manipülasyonu için Pandas ve Numpy, görselleştirme için Matplotlib.pyplot, ölçekleme ve değerlendirme için scikit-learn ve modelleme için TensorFlow gereklidir. Ayrıca yeniden üretilebilirlik için tohum değerleri ayarlayacağız.
# Importing the libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Dropout, GRU, Bidirectional
from tensorflow.keras.optimizers import SGD
from tensorflow.random import set_seed
set_seed(455)
np.random.seed(455)
Bu bölümde MasterCard veri setini içe aktarırken Tarih sütununu indekse ekleyip DateTime biçimine dönüştüreceğiz. Ayrıca yalnızca hisse fiyatları, hacim ve tarih ile ilgilendiğimiz için veri setinden ilgisiz sütunları düşeceğiz.
Veri setinde indeks olarak Tarih; sütunlar olarak Açılış (Open), Yüksek (High), Düşük (Low), Kapanış (Close) ve Hacim (Volume) bulunur. Görünüşe göre temiz bir veri setini başarıyla içe aktardık.
dataset = pd.read_csv(
"data/Mastercard_stock_history.csv", index_col="Date", parse_dates=["Date"]
).drop(["Dividends", "Stock Splits"], axis=1)
print(dataset.head())
Open High Low Close Volume
Date
2006-05-25 3.748967 4.283869 3.739664 4.279217 395343000
2006-05-26 4.307126 4.348058 4.103398 4.179680 103044000
2006-05-30 4.183400 4.184330 3.986184 4.093164 49898000
2006-05-31 4.125723 4.219679 4.125723 4.180608 30002000
2006-06-01 4.179678 4.474572 4.176887 4.419686 62344000
.describe() fonksiyonu veriyi derinlemesine analiz etmemize yardımcı olur. Modeli eğitmek için High sütununu kullanacağımızdan ona odaklanalım. Model özelliği olarak Close ya da Open sütunlarını da seçebiliriz, ancak High daha mantıklıdır; çünkü bize ilgili gün içinde hissenin ne kadar yükseğe çıktığı bilgisini verir.
En düşük hisse fiyatı 4,10 $, en yüksek 400,5 $’dır. Ortalama 105,9 $ ve standart sapma 107,3 $ olup, bu da hisselerin yüksek varyansa sahip olduğunu gösterir.
print(dataset.describe())
Open High Low Close Volume
count 3872.000000 3872.000000 3872.000000 3872.000000 3.872000e+03
mean 104.896814 105.956054 103.769349 104.882714 1.232250e+07
std 106.245511 107.303589 105.050064 106.168693 1.759665e+07
min 3.748967 4.102467 3.739664 4.083861 6.411000e+05
25% 22.347203 22.637997 22.034458 22.300391 3.529475e+06
50% 70.810079 71.375896 70.224002 70.856083 5.891750e+06
75% 147.688448 148.645373 146.822013 147.688438 1.319775e+07
max 392.653890 400.521479 389.747812 394.685730 3.953430e+08
.isna().sum() kullanarak veri setindeki eksik değerleri belirleyebiliriz. Görünüşe göre veri setinde eksik değer yok.
dataset.isna().sum()
Open 0
High 0
Low 0
Close 0
Volume 0
dtype: int64
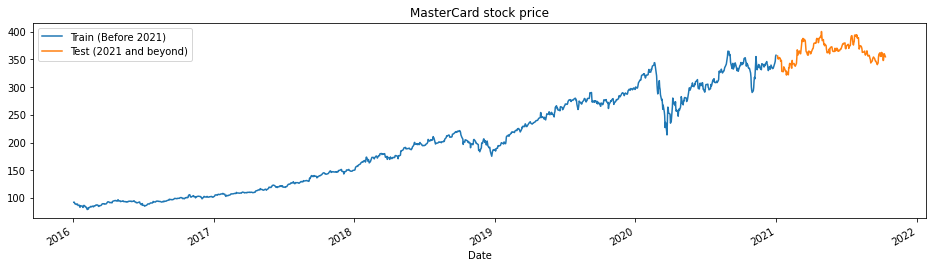
train_test_plot fonksiyonu üç argüman alır: dataset, tstart ve tend; ve basit bir çizgi grafik çizer. tstart ve tend yıl cinsinden zaman sınırlarıdır. Belirli dönemleri analiz etmek için bu argümanları değiştirebiliriz. Çizgi grafiği iki kısma ayrılmıştır: eğitim ve test. Bu, test veri setinin dağılımına karar vermemizi sağlar.
MasterCard hisse fiyatları 2016’dan beri yükseliştedir. 2020’nin ilk çeyreğinde düşüş yaşadı ancak yılın ikinci yarısında istikrarlı bir konuma geldi. Test veri setimiz bir yıldan oluşuyor: 2021’den 2022’ye; geri kalanı eğitim için kullanılıyor.
tstart = 2016
tend = 2020
def train_test_plot(dataset, tstart, tend):
dataset.loc[f"{tstart}":f"{tend}", "High"].plot(figsize=(16, 4), legend=True)
dataset.loc[f"{tend+1}":, "High"].plot(figsize=(16, 4), legend=True)
plt.legend([f"Train (Before {tend+1})", f"Test ({tend+1} and beyond)"])
plt.title("MasterCard stock price")
plt.show()
train_test_plot(dataset,tstart,tend)
train_test_split fonksiyonu veri setini iki alt kümeye ayırır: training_set ve test_set.
def train_test_split(dataset, tstart, tend):
train = dataset.loc[f"{tstart}":f"{tend}", "High"].values
test = dataset.loc[f"{tend+1}":, "High"].values
return train, test
training_set, test_set = train_test_split(dataset, tstart, tend)
Eğitim setimizi standartlaştırmak için MinMaxScaler fonksiyonunu kullanacağız; bu, aykırı değerlerden veya anormalliklerden kaçınmamıza yardımcı olur. Verinizi normalize etmek ve model performansını iyileştirmek için StandardScaler veya başka bir ölçekleyiciyi de deneyebilirsiniz.
sc = MinMaxScaler(feature_range=(0, 1))
training_set = training_set.reshape(-1, 1)
training_set_scaled = sc.fit_transform(training_set)
split_sequence fonksiyonu bir eğitim veri seti kullanır ve bunu girdilere (X_train) ve çıktılara (y_train) dönüştürür.
Örneğin, dizilim [1,2,3,4,5,6,7,8,9,10,11,12] ve n_step üç ise, dizilimi aşağıdaki gibi üç zaman damgalı girdi ve bir çıktıya dönüştürür:
| X | y |
|---|---|
| 1,2,3 | 4 |
| 2,3,4 | 5 |
| 3,4,5 | 6 |
| 4,5,6 | 7 |
| … | … |
Bu projede 60 n_steps kullanıyoruz. Model performansını optimize etmek için adım sayısını azaltıp artırabiliriz.
def split_sequence(sequence, n_steps):
X, y = list(), list()
for i in range(len(sequence)):
end_ix = i + n_steps
if end_ix > len(sequence) - 1:
break
seq_x, seq_y = sequence[i:end_ix], sequence[end_ix]
X.append(seq_x)
y.append(seq_y)
return np.array(X), np.array(y)
n_steps = 60
features = 1
# split into samples
X_train, y_train = split_sequence(training_set_scaled, n_steps)
Tek değişkenli (univariate) bir seriyle çalışıyoruz; bu nedenle özellik sayısı birdir ve X_train’i LSTM modeline uydurmak için yeniden şekillendirmemiz gerekir. X_train [örnek, zaman adımı] biçimindedir; bunu [örnek, zaman adımı, özellik] biçimine dönüştüreceğiz.
# Reshaping X_train for model
X_train = X_train.reshape(X_train.shape[0],X_train.shape[1],features)
Model, tek bir LSTM gizli katmanı ve bir çıktı katmanından oluşur. Birim sayısıyla denemeler yapabilirsiniz; daha fazla birim daha iyi sonuçlar verebilir. Bu deney için LSTM birimlerini 125, aktivasyonu tanh ve girdi boyutunu ayarlayacağız.
Yazarın Notu: TensorFlow kütüphanesi kullanıcı dostudur; bu nedenle LSTM veya GRU modellerini sıfırdan oluşturmamız gerekmez. Modeli kurmak için doğrudan LSTM veya GRU modüllerini kullanacağız.
Son olarak, modeli RMSprop optimize edicisi ve kayıp fonksiyonu olarak ortalama kare hata ile derleyeceğiz.
# The LSTM architecture
model_lstm = Sequential()
model_lstm.add(LSTM(units=125, activation="tanh", input_shape=(n_steps, features)))
model_lstm.add(Dense(units=1))
# Compiling the model
model_lstm.compile(optimizer="RMSprop", loss="mse")
model_lstm.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm (LSTM) (None, 125) 63500
_________________________________________________________________
dense (Dense) (None, 1) 126
=================================================================
Total params: 63,626
Trainable params: 63,626
Non-trainable params: 0
_________________________________________________________________
Model 50 epoch ve 32 batch boyutuyla eğitilecektir. Hiperparametreleri değiştirerek eğitim süresini azaltabilir veya sonuçları iyileştirebilirsiniz. Model eğitimi en iyi olası kayıpla başarıyla tamamlandı.
model_lstm.fit(X_train, y_train, epochs=50, batch_size=32)
Epoch 50/50
38/38 [==============================] - 1s 30ms/step - loss: 3.1642e-04
Ön işlemleri tekrarlayıp test setini normalize edeceğiz. Öncelikle veri setini dönüştürecek, ardından örneklere bölecek, yeniden şekillendirecek, tahmin edecek ve tahminleri ters dönüştürerek standart biçime geri getireceğiz.
dataset_total = dataset.loc[:,"High"]
inputs = dataset_total[len(dataset_total) - len(test_set) - n_steps :].values
inputs = inputs.reshape(-1, 1)
#scaling
inputs = sc.transform(inputs)
# Split into samples
X_test, y_test = split_sequence(inputs, n_steps)
# reshape
X_test = X_test.reshape(X_test.shape[0], X_test.shape[1], features)
#prediction
predicted_stock_price = model_lstm.predict(X_test)
#inverse transform the values
predicted_stock_price = sc.inverse_transform(predicted_stock_price)
plot_predictions fonksiyonu gerçek ve tahmini değerleri karşılaştıran bir çizgi grafiği çizer. Bu, gerçek ve tahmini değerler arasındaki farkı görselleştirmemize yardımcı olur.
return_rmse fonksiyonu test ve predicted argümanlarını alır ve kök ortalama kare hatayı (rmse) yazdırır.
def plot_predictions(test, predicted):
plt.plot(test, color="gray", label="Real")
plt.plot(predicted, color="red", label="Predicted")
plt.title("MasterCard Stock Price Prediction")
plt.xlabel("Time")
plt.ylabel("MasterCard Stock Price")
plt.legend()
plt.show()
def return_rmse(test, predicted):
rmse = np.sqrt(mean_squared_error(test, predicted))
print("The root mean squared error is {:.2f}.".format(rmse))
Aşağıdaki çizgi grafiğine göre tek katmanlı LSTM modelinin performansı iyi.
plot_predictions(test_set,predicted_stock_price)
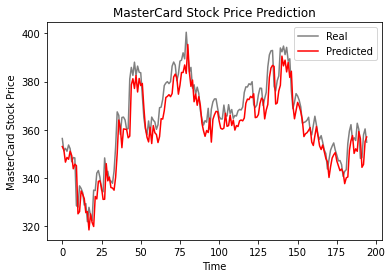
Sonuçlar umut verici; model test veri setinde 6,70 rmse elde etti.
return_rmse(test_set,predicted_stock_price)
>>> The root mean squared error is 6.70.
Her şeyi aynı tutup yalnızca LSTM katmanını GRU katmanıyla değiştirerek sonuçları doğru biçimde karşılaştıracağız. Model yapısı 125 birimli tek bir GRU katmanı ve bir çıktı katmanı içerir.
model_gru = Sequential()
model_gru.add(GRU(units=125, activation="tanh", input_shape=(n_steps, features)))
model_gru.add(Dense(units=1))
# Compiling the RNN
model_gru.compile(optimizer="RMSprop", loss="mse")
model_gru.summary()
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
gru_4 (GRU) (None, 125) 48000
_________________________________________________________________
dense_5 (Dense) (None, 1) 126
=================================================================
Total params: 48,126
Trainable params: 48,126
Non-trainable params: 0
_________________________________________________________________
Model 50 epoch ve 32 batch boyutuyla başarıyla eğitildi.
model_gru.fit(X_train, y_train, epochs=50, batch_size=32)
Epoch 50/50
38/38 [==============================] - 1s 29ms/step - loss: 2.6691e-04
Görüldüğü gibi gerçek ve tahmini değerler nispeten yakın. Tahmin edilen çizgi grafiği neredeyse gerçek değerlere oturuyor.
GRU_predicted_stock_price = model_gru.predict(X_test)
GRU_predicted_stock_price = sc.inverse_transform(GRU_predicted_stock_price)
plot_predictions(test_set, GRU_predicted_stock_price)
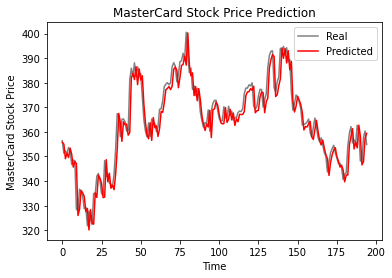
GRU modeli test veri setinde 5,50 rmse elde etti; bu da LSTM modeline göre bir iyileşme.
return_rmse(test_set,GRU_predicted_stock_price)
>>> The root mean squared error is 5.50.
Dünya, veri bilimcilerin görüntü altyazılama, duygu tespiti, video altyazılama ve DNA dizilemede CNN-RNN hibrit ağlarını kullandığı hibrit çözümlere yöneliyor. Hibrit ağlar modele hem görsel hem de zamansal özellikler kazandırır. RNN hakkında daha fazla bilgi edinmek için şu kursu alın: Python’da Dil Modellemesi için Yinelenen Sinir Ağları.
Bu eğitimin ilk yarısı yinelenen sinir ağlarının temellerini, sınırlamalarını ve daha gelişmiş mimariler şeklindeki çözümlerini kapsar. İkinci yarısı ise LSTM ve GRU modelleri kullanarak MasterCard hisse fiyatı tahmini geliştirmeye odaklanır. Sonuçlar, benzer yapı ve hiperparametrelerle GRU modelinin LSTM’den daha iyi performans gösterdiğini açıkça ortaya koymaktadır.
Bu proje DataCamp çalışma alanında mevcuttur.
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
